【学习笔记】大模型架构设计与长上下文能力的实现
大模型架构
Encoder-Decoder
继承自传统的Transformer架构,包含一个编码器encoder,以及一个解码器decoder,这个在之前介绍过
其中,编码器采用的是双向注意力,即每一个元素的attention可以关注所有元素;而解码器采用的是单项注意力,即每一个元素只能关注之前元素以及自己,这一点通过对参数矩阵进行mask可以快速实现
代表模型:Transformer,flan-T5
Casual Decoder
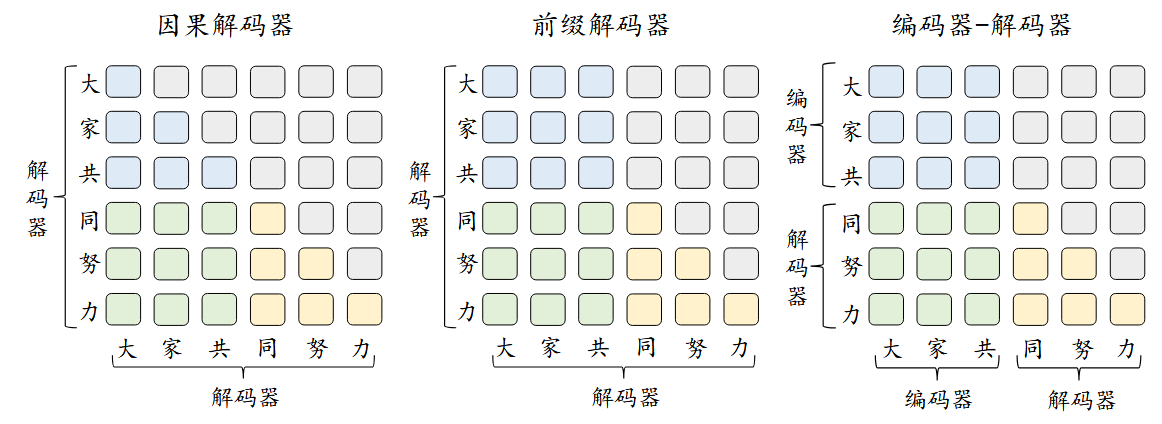
目前的LLM大部分采用Decoder Only架构,而Decoder架构又可以分为Casual Decoder以及Prefix Decoder,两者的主要区别就在于前后文的注意力差别。
Casual Decoder ,也称为因果编码器,输入和输出均为单向注意力,即每个token只能看到并依赖其之前的token
适合文本续写、问答系统、创意写作等需要保持文本连贯性的任务
代表模型: GPT系列,LLamA
Prefix Decoder
Prefix Decoder,也称为前缀编码器,输入部分使用双向注意力,输出部分使用单向注意力。在生成新的输出时,会考虑到所有之前生成的输出。
适合机器翻译、文本摘要等需要同时理解全文上下文并生成相关文本的任务
代表模型: GLM,ChatGLM
可以通过下图对三种架构有一个直观了解
长上下文能力的实现
在实际应用中,大语言模型对于长文本数据的处理需求日益凸显,尤其在长 文档分析、多轮对话、故事创作等场景下,这些文本的长度往往大于训练时数据的最大长度
m
x
K
mxK
mxK,事实上预训练时就使用超长文本也是不划算的,因为attention的平方复杂度,这会导致巨大开销。
而上下文长度超过训练时分布限制时,模型的位置编码往往无法得到充分训练,自然会导致处理能力下降。
因此,给定一个预训练后的大语言模型,如何有效拓展其上下文窗口以应对更长的文本数据?
目前的解决方法包括:扩展位置编码,调整上下文窗口
扩展位置编码
目前位置编码常用的是RoPE,也就是对参数矩阵施加旋转变换。过长的上下文长度,在RoPE中就反映为旋转角度的范围超过训练时的上限。所以一种措施就是对旋转角度加以限制
考虑RoPE中的旋转角度主要由token的位置索引
t
t
t以及子空间序号
i
i
i决定
f
(
t
,
i
)
=
t
⋅
θ
i
f(t, i) = t\cdot \theta_{i}
f(t,i)=t⋅θi
现在将其扩展为
f
(
t
,
i
)
=
g
(
t
)
h
(
i
)
f(t, i) = g(t)h(i)
f(t,i)=g(t)h(i)
此时对角度的限制就有两个方向,限制
g
(
t
)
g(t)
g(t)或者
h
(
i
)
h(i)
h(i)。
位置索引修改
一个非常直接的思路就是让
g
(
t
)
g(t)
g(t)对
t
t
t进行放缩,上限为
T
m
a
x
′
T_{max}'
Tmax′代表扩展后的上下文窗口长度即可。此时就有
g
(
t
)
=
T
m
a
x
T
m
a
x
′
t
g(t) = \frac{T_{max}}{T_{max}'}t
g(t)=Tmax′Tmaxt
通过线性变换对距离信息进行放缩,就实现了角度的限制。但是这种做法在处理较短的文本时,由于位置索引的缩放,可能会对模型的性 能产生一定的负面影响
另一种做法为了兼顾短文本的性能,对放缩区域进行限制:对模型中近距离敏感的位置索引进行保 留,同时截断或插值处理远距离的位置索引,确保其不超出预设的最大旋转角度。得到
g
(
t
)
=
{
t
t
≤
w
,
w
t
>
w
(
ReRoPE
)
w
+
(
T
m
a
x
−
w
)
(
t
−
w
)
T
m
a
x
′
−
w
t
>
w
(
LeakyReRoPE
)
g(t) = \left\{\begin{matrix} t &t\leq w, \\ w & t>w(\text{ReRoPE})\\ w + \frac{(T_{max}-w)(t-w)}{T_{max}'-w} &t>w(\text{LeakyReRoPE}) \end{matrix}\right.
g(t)=⎩
⎨
⎧tww+Tmax′−w(Tmax−w)(t−w)t≤w,t>w(ReRoPE)t>w(LeakyReRoPE)
基修改
与上述修改的思路类似,我们希望上下文窗口达到
T
m
a
x
′
T_{max}'
Tmax′的时候,旋转角度依然在训练时的上限内,即
f
(
T
m
a
x
′
,
i
)
=
T
m
a
x
′
h
(
i
)
≤
T
m
a
x
θ
i
f(T_{max}',i) = T_{max}'h(i)\leq T_{max}\theta_{i}
f(Tmax′,i)=Tmax′h(i)≤Tmaxθi
注意到
θ
i
=
b
−
2
(
i
−
1
)
/
H
(
b
=
1e4
)
\theta_{i} = b^{-2(i-1)/H}(b=\text{1e4})
θi=b−2(i−1)/H(b=1e4),一种做法就是对底数
b
b
b进行缩小,从而缩小旋转的角度,得到
h
(
i
)
=
θ
i
=
(
α
⋅
b
)
−
2
(
i
−
1
)
/
H
h(i) = \theta_{i} = (\alpha \cdot b)^{-2(i-1)/H}
h(i)=θi=(α⋅b)−2(i−1)/H
α
\alpha
α可以取
(
T
m
a
x
′
T
m
a
x
)
H
/
(
H
−
2
)
(\frac{T_{max}'}{T_{max}})^{H/(H-2)}
(TmaxTmax′)H/(H−2)
还有一种做法是直接对
h
(
i
)
=
θ
i
h(i) = \theta_{i}
h(i)=θi进行截断,类似上文中
g
(
t
)
g(t)
g(t)的操作 link
调整上下文窗口
上述方法是对位置编码进行修改,使得旋转角度能够落在训练时上限内。另一种方法是采用受限的注意力机制来调整原始的上下文窗口,从而实现对更长文本的有效建模。方法包括并行上下文窗口,
Λ
\Lambda
Λ形上下文窗口,词元选择
