AI如何实际应用到自动化测试-实战篇
一、思路整理
与AI如何对话?
-
清晰描述任务目标
明确告诉 AI 代码要完成的任务。例如,可以这样开头:"我需要一个 Selenium 脚本,用来测试 32 个不同 URL 页面上的搜索框功能。当鼠标移入搜索按钮时,需要验证是否悬浮展示‘AI搜索’文案。"
-
描述使用的语言和工具
描述正在使用的工具和框架,如 Python、Selenium,
比如:"请用 Python 和 Selenium 编写代码,驱动ChromeDriver的路径为'C:\\Program Files\\Google\\Chrome\\Application\\chromedriver.exe'
-
拆解功能步骤要求 将需要实现的功能分段描述:
(1)需要加载多个 URL 页面,
(2)模拟鼠标悬停操作,移动到指定按钮上,该搜索按钮在部分URL中元素相同,部分URL中元素又不相同。
(3)验证悬浮文案是否正确显示。
-
上述AI生成的代码若运行报错或者失败怎么办?
如果 AI 给出的初版代码不完全符合需求,例如存在运行失败,运行bug等,那么可以继续提问。比如:"上述生成的代码运行报错,错误码XXXX(本地报错的内容)"
二、实战演练
-
AI选择
首选必应:https://copilot.microsoft.com/chats/r4kGNaJSfnYUuTu8AMS7a,它是微软的一款实时搜索类型的AI程序,时效性,准确性高,关于使用方法可以参考之前写过的方法教程:微软bing-GPT使用方法_必应gpt-CSDN博客
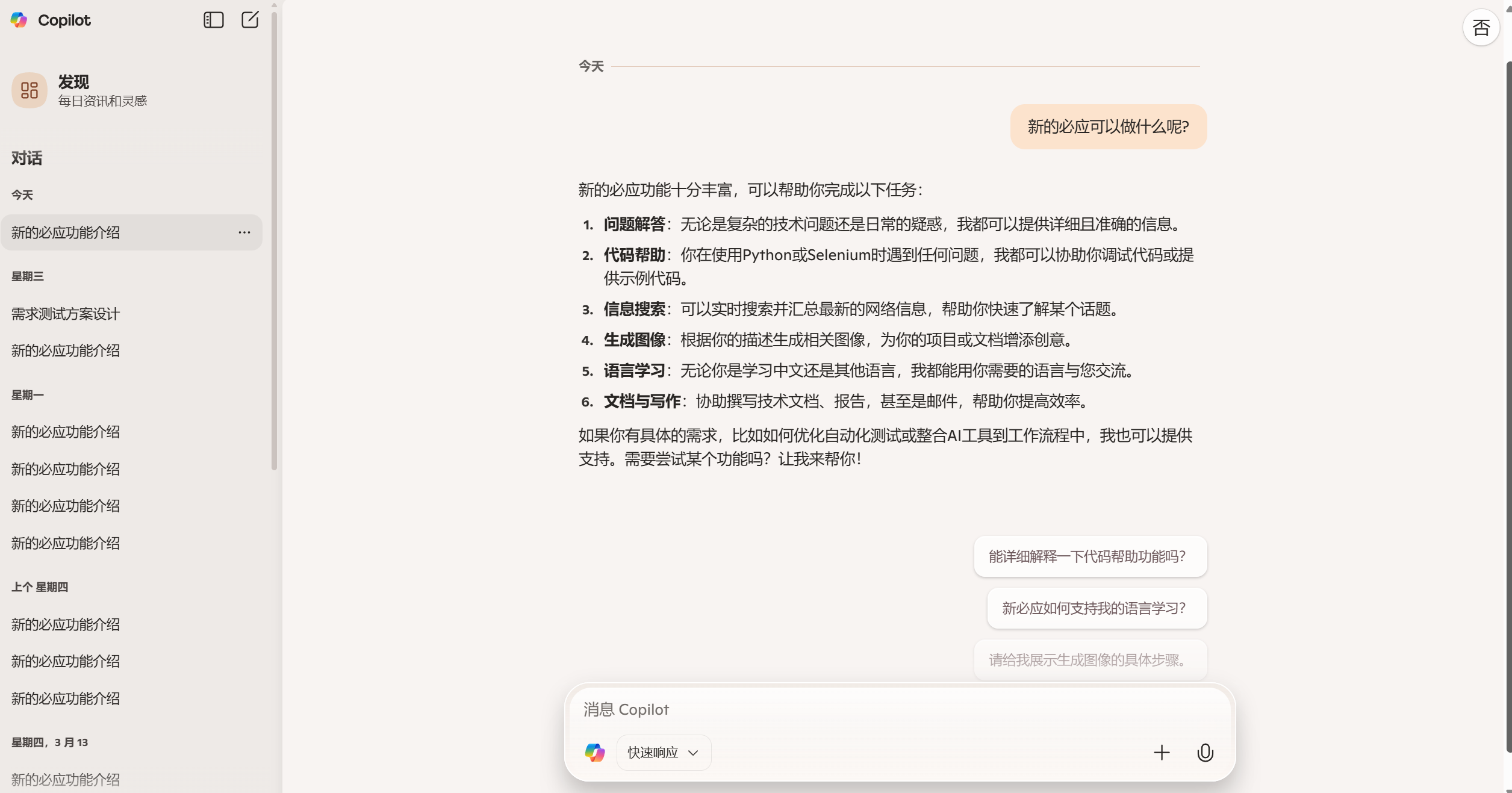
-
实战需求
-
web自动化需求
需求:检查在【收藏下载】页面-我的下载处是否可以直接下载成功
-
AI对话整理
| 需求:我需要一个 Selenium 脚本,来检查在【收藏下载】页面-我的下载处是否可以直接下载成功 1:打开【收藏下载】页面前提要登录,登录已经有现成脚本,可以直接使用,程序如下(此处省略登录脚本描述) 2:【收藏下载】页面URL是https://www.test.com/(这是假的地址),上述登录成功后需要打开该URL 3:鼠标移入第一个模型的封面处,模型元素如下 //*[contains(@class, 'components-collectHome-AllCaseContent-HomeAllCntNewCard-index__imgDiv__')] 4:点击封面处出现的下载按钮,下载按钮元素如下 //*[contains(@class, 'components-collectHome-AllCaseContent-HomeAllCntNewCard-index__downLoadIcon_')] 5:若下载成功,会有【下载成功】元素出现,元素如下,若没有下载成功,则该条测试用例失败 //*[contains(@class, 'ant-message-custom-content ant-message-success')] 请根据上述需求以及详细过程描述,使用python+selenium生成一个自动化测试程序 |
-
实际AI生成结果

(1)AI输出程序结果
import unittest
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
import time
from selenium.webdriver.chrome.service import Service
class DownloadTest(unittest.TestCase):
def setUp(self) -> None:
service = Service('C:\\Program Files\\Google\\Chrome\\Application\\chromedriver.exe')
self.driver = webdriver.Chrome(service=service)
self.driver.maximize_window()
self.time = time
def tearDown(self) -> None:
self.time.sleep(2)
self.driver.quit()
def test_download(self):
# 1. 登录页面
self.driver.get('https://www.test.com/')
self.driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
self.time.sleep(2)
self.driver.refresh()
# 执行登录
self.driver.find_element(By.ID, 'loginsucces').click()
self.time.sleep(1)
self.driver.find_element(By.XPATH, "//div[@class='ant-modal-content']//div[2]//div[1]//span[1]").click()
self.time.sleep(1)
self.driver.find_element(By.XPATH, "/html[1]/body[1]/div[3]/div[1]/div[2]/div[1]/div[2]/div[1]/div[1]/div[1]/div[1]/div[2]/div[1]").click()
self.time.sleep(1)
self.driver.find_element(By.XPATH, "//input[@placeholder='请输入手机号']").send_keys('19580887901')
self.driver.find_element(By.XPATH, "//input[@placeholder='请输入密码']").send_keys('123456')
self.time.sleep(1)
self.driver.find_element(By.XPATH, '/html[1]/body[1]/div[3]/div[1]/div[2]/div[1]/div[2]/div[1]/div[1]/div[1]/div[3]').click()
self.time.sleep(2)
self.driver.find_element(By.ID, 'rectBottom').click()
self.time.sleep(4)
# 2. 打开【收藏下载】页面
self.driver.get('https://www.test.com/')
self.time.sleep(2)
# 3. 鼠标移入第一个模型的封面处
first_model_cover = self.driver.find_element(By.XPATH, "//*[contains(@class, 'components-collectHome-AllCaseContent-HomeAllCntNewCard-index__imgDiv__')]")
ActionChains(self.driver).move_to_element(first_model_cover).perform()
self.time.sleep(2)
# 4. 点击下载按钮
download_button = self.driver.find_element(By.XPATH, "//*[contains(@class, 'components-collectHome-AllCaseContent-HomeAllCntNewCard-index__downLoadIcon_')]")
download_button.click()
self.time.sleep(3)
# 5. 验证下载成功
try:
success_message = self.driver.find_element(By.XPATH, "//*[contains(@class, 'ant-message-custom-content ant-message-success')]")
self.assertTrue(success_message.is_displayed(), "下载成功!")
except Exception as e:
self.fail(f"测试失败,未能下载成功: {str(e)}")
if __name__ == '__main__':
unittest.main()(2)本地运行结果
运行成功,功能正确
假设上述脚本报错怎么办?
此处我们来将代码修改成一个错误的地方运行,将下载按钮元素填写错误,运行后报错,我们将报错信息发送给AI,然后根据报错解释进行修改相关地方即可(一般这种元素未加载成功的原因要么是元素错误,要么就是层级关系导致)
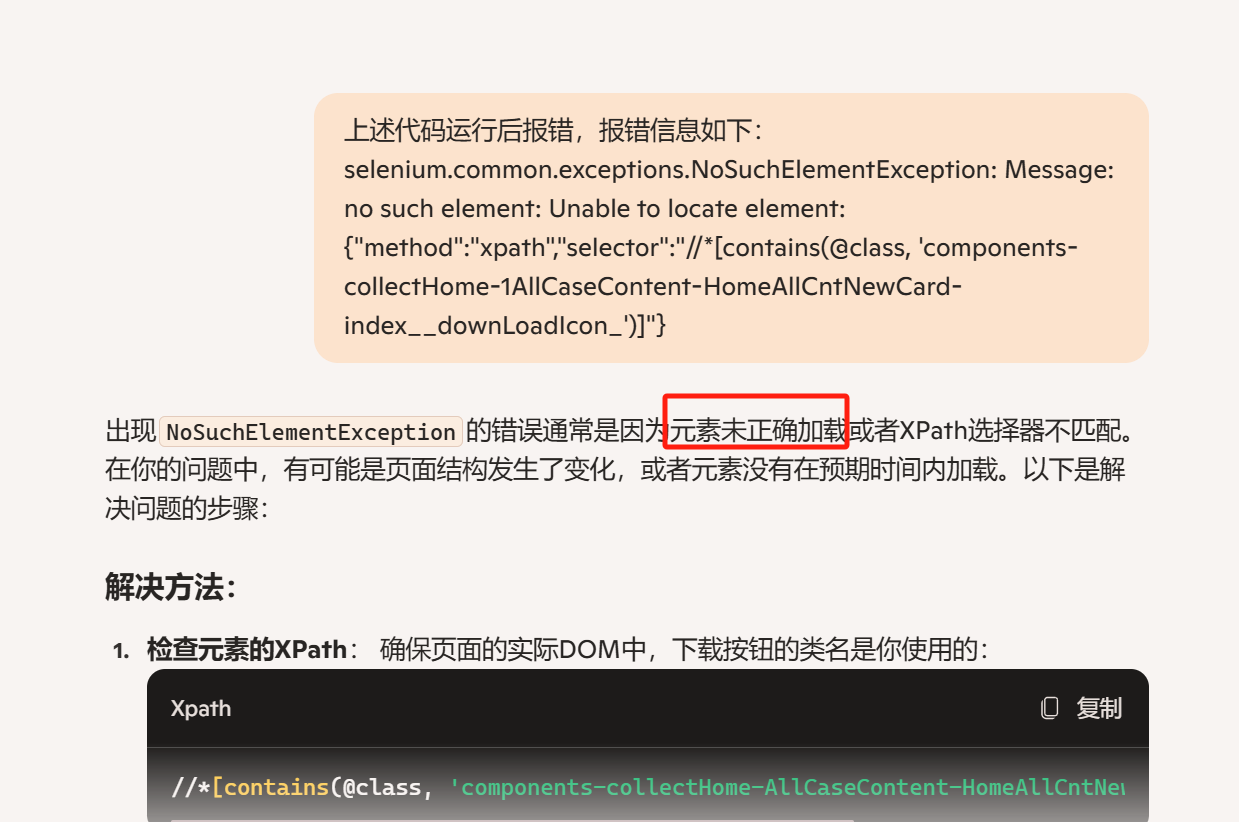
-
接口自动化需求
需求:检查【我的收藏列表接口】返回值是否正确
-
AI对话整理
| 需求:检查【我的收藏列表接口】返回值是否正确 1:接口URL:https://ug.baidu.com/mcp/pc/pcsearch 2:接口请求方式:POST 3:接口需要传参,传参格式为json,传参明细如下 {"invoke_info":{"pos_1":[{}],"pos_2":[{}],"pos_3":[{}]}} 4:调取该接口需要登录状态,所以需要先读取SESSION,然后再调取接口,SESSION值为SESSION=MjcyN2RlMDQtNjc2NS00ZTc0LWFkOGMtYmE5MjAwN2Q5ZDdk;Path=/;Domain=api.baidu.com;Expires=2025-04-27T01:42:26.934Z 5:成功调取后,校验接口返回值,正确的返回值应如下,若返回值错误则该条测试用例失败 { 6:请根据上述需求以及详细过程描述,使用python+selenium生成一个自动化测试程序 |
-
实际AI生成结果
import unittest import requests import json class CollectListTest(unittest.TestCase): def setUp(self) -> None: # 设置基本信息 self.session_cookie = "SESSION=MjcyN2RlMDQtNjc2NS00ZTc0LWFkOGMtYmE5MjAwN2Q5ZDdk;Path=/;Domain=api.baidu.com;Expires=2025-04-27T01:42:26.934Z" self.base_url = "https://ug.baidu.com/mcp/pc/pcsearch" self.headers = { "Content-Type": "application/json", "Cookie": self.session_cookie } self.payload = {"invoke_info":{"pos_1":[{}],"pos_2":[{}],"pos_3":[{}]}} self.expected_response = { "error": { "errorCode": "0", "errorMsg": "成功" }, "data": { "list": [ { "errno": 0, "errmsg": "ok", "data": { "log_id": "24020223", "action_rule": { "pos_1": [], "pos_2": [], "pos_3": [] } } } ], "pageNum": None, "pageSize": None, "total": "1" } } def test_collect_list_api(self): # 调用接口 response = requests.post(self.base_url, headers=self.headers, data=json.dumps(self.payload)) self.assertEqual(response.status_code, 200, "接口调用失败,状态码非200") # 校验返回值 response_data = response.json() self.assertEqual( response_data["error"]["errorCode"], self.expected_response["error"]["errorCode"], f"错误码不匹配:{response_data['error']['errorCode']}" ) self.assertEqual( response_data["error"]["errorMsg"], self.expected_response["error"]["errorMsg"], f"错误信息不匹配:{response_data['error']['errorMsg']}" ) self.assertEqual( response_data["data"]["list"], self.expected_response["data"]["list"], f"返回数据列表不匹配:{response_data['data']['list']}" ) def tearDown(self) -> None: print("测试完成,清理环境") if __name__ == '__main__': unittest.main()
(1)AI输出程序结果
暂时无法在飞书文档外展示此内容
(2)本地运行结果
运行成功,接口正常返回
我们将预期返回值改成错误的,程序会报错,并且指出与预期不符合的地方