【大模型】GRPO:从 PPO 到群体相对策略优化的进化之路
GRPO:从 PPO 到群体相对策略优化的进化之路
- 论文:https://arxiv.org/abs/2402.03300 (2024.02.05 DeepSeek)
- 代码: https://github.com/deepseek-ai/DeepSeek-Math
- 复现代码:
- https://github.com/songxia928/RL/blob/main/08_GRPO.py
- https://github.com/songxia928/RL/blob/main/08_GRPO%20vs%20PPO.py
文章目录
- GRPO:从 PPO 到群体相对策略优化的进化之路
- @[toc]
- @[toc]
- 一、PPO的局限性与GRPO的诞生
- 1.1 原理
- (1)目标函数
- (2)截断机制
- (3)完整优化目标**
- 1.2 痛点
- 二、GRPO核心原理:群体相对策略优化
- 2.1 GRPO的三大创新(对标痛点)
- ✨ 创新1:无Critic架构(解决显存问题)
- ✨ 创新2:相对优势估计(解决偏差问题)
- ✨ 创新3:双重约束机制(优化策略更新)
- 2.2 GRPO核心公式(对比PPO)
- 2.3 通俗比喻:考试排名 vs 绝对分数
- 2.4 关键公式图解
- 2.5 适用场景
- 三、GRPO算法实现:
- 3.1 策略网络(仅保留Actor)
- 3.2 群体采样与优势计算
- 3.3 训练流程对比
- 3.4 大语言模型 GRPO
- 四、代码运行结果
- 4.1 GRPO
- 4.2 GRPO VS PPO
文章目录
- GRPO:从 PPO 到群体相对策略优化的进化之路
- @[toc]
- @[toc]
- 一、PPO的局限性与GRPO的诞生
- 1.1 原理
- (1)目标函数
- (2)截断机制
- (3)完整优化目标**
- 1.2 痛点
- 二、GRPO核心原理:群体相对策略优化
- 2.1 GRPO的三大创新(对标痛点)
- ✨ 创新1:无Critic架构(解决显存问题)
- ✨ 创新2:相对优势估计(解决偏差问题)
- ✨ 创新3:双重约束机制(优化策略更新)
- 2.2 GRPO核心公式(对比PPO)
- 2.3 通俗比喻:考试排名 vs 绝对分数
- 2.4 关键公式图解
- 2.5 适用场景
- 三、GRPO算法实现:
- 3.1 策略网络(仅保留Actor)
- 3.2 群体采样与优势计算
- 3.3 训练流程对比
- 3.4 大语言模型 GRPO
- 四、代码运行结果
- 4.1 GRPO
- 4.2 GRPO VS PPO
在之前的文章"【强化学习】07.近端策略优化(PPO) 算法原理"中我们提到了PPO算法,这里我门进一步介绍来自DeepSeek的论文《DeepSeekMath》 的群组相对策略优化(GRPO)算法。具体关于《DeepSeekMath》 这篇论文的解读,也可以参考我这篇文章"【大模型】Deepseek-Math (GRPO)论文解读"。
在大模型(LLM)的对齐任务中,如何高效地优化模型的生成策略,同时保持训练的稳定性和高效性,一直是一个关键问题。而 GRPO(Group Relative Policy Optimization,组相对策略优化)作为一种新颖的策略优化方法,凭借其在高效性和过程监督上的表现,逐渐获得更多关注。下面,我们将深入剖析从PPO 到 GRPO 的理论原理、数学公式、实现步骤和代码示例。
文章目录
- GRPO:从 PPO 到群体相对策略优化的进化之路
- @[toc]
- @[toc]
- 一、PPO的局限性与GRPO的诞生
- 1.1 原理
- (1)目标函数
- (2)截断机制
- (3)完整优化目标**
- 1.2 痛点
- 二、GRPO核心原理:群体相对策略优化
- 2.1 GRPO的三大创新(对标痛点)
- ✨ 创新1:无Critic架构(解决显存问题)
- ✨ 创新2:相对优势估计(解决偏差问题)
- ✨ 创新3:双重约束机制(优化策略更新)
- 2.2 GRPO核心公式(对比PPO)
- 2.3 通俗比喻:考试排名 vs 绝对分数
- 2.4 关键公式图解
- 2.5 适用场景
- 三、GRPO算法实现:
- 3.1 策略网络(仅保留Actor)
- 3.2 群体采样与优势计算
- 3.3 训练流程对比
- 3.4 大语言模型 GRPO
- 四、代码运行结果
- 4.1 GRPO
- 4.2 GRPO VS PPO
文章目录
- GRPO:从 PPO 到群体相对策略优化的进化之路
- @[toc]
- @[toc]
- 一、PPO的局限性与GRPO的诞生
- 1.1 原理
- (1)目标函数
- (2)截断机制
- (3)完整优化目标**
- 1.2 痛点
- 二、GRPO核心原理:群体相对策略优化
- 2.1 GRPO的三大创新(对标痛点)
- ✨ 创新1:无Critic架构(解决显存问题)
- ✨ 创新2:相对优势估计(解决偏差问题)
- ✨ 创新3:双重约束机制(优化策略更新)
- 2.2 GRPO核心公式(对比PPO)
- 2.3 通俗比喻:考试排名 vs 绝对分数
- 2.4 关键公式图解
- 2.5 适用场景
- 三、GRPO算法实现:
- 3.1 策略网络(仅保留Actor)
- 3.2 群体采样与优势计算
- 3.3 训练流程对比
- 3.4 大语言模型 GRPO
- 四、代码运行结果
- 4.1 GRPO
- 4.2 GRPO VS PPO
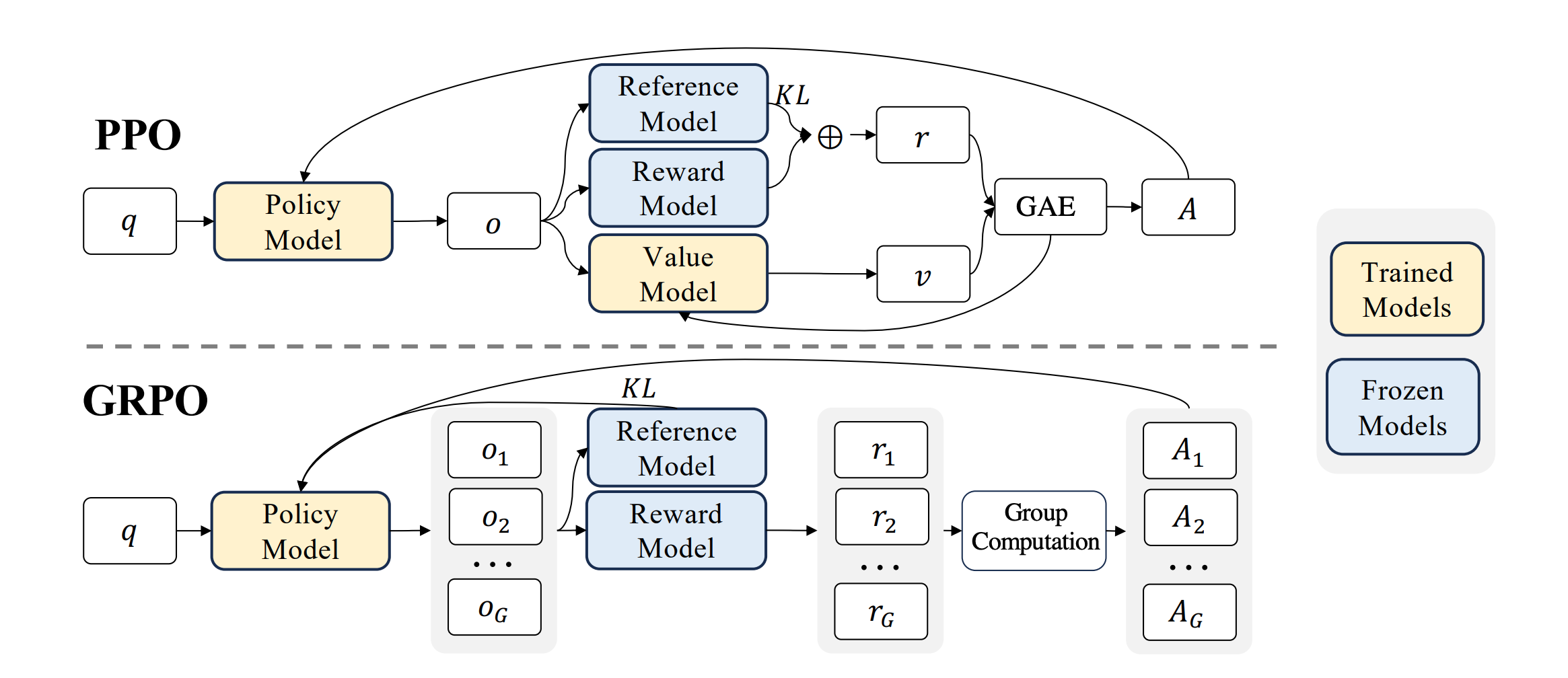
一、PPO的局限性与GRPO的诞生
我们先回顾一下PPO的相关知识。近端策略优化(PPO)通过截断机制(Clipping)约束策略更新幅度,在稳定性和样本效率上取得了突破。
1.1 原理
(1)目标函数
PPO 的核心目标函数如下:
L
C
L
I
P
(
θ
)
=
E
[
min
(
r
t
(
θ
)
A
t
,
clip
(
r
t
(
θ
)
,
1
−
ϵ
,
1
+
ϵ
)
A
t
)
]
L^{CLIP}(\theta) = \mathbb{E} \left[ \min \left( r_t(\theta)A_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon)A_t \right) \right]
LCLIP(θ)=E[min(rt(θ)At,clip(rt(θ),1−ϵ,1+ϵ)At)]
其中:
- r t ( θ ) = π θ ( a ∣ s ) π θ old ( a ∣ s ) r_t(\theta) = \frac{\pi_\theta(a|s)}{\pi_{\theta_{\text{old}}}(a|s)} rt(θ)=πθold(a∣s)πθ(a∣s) 是新旧策略概率的比值;
- A t A_t At 是优势函数;
- ϵ \epsilon ϵ 是截断范围的超参数。
(2)截断机制
- 如果 r t ( θ ) r_t(\theta) rt(θ) 超出范围 [ 1 − ϵ , 1 + ϵ ] [1-\epsilon, 1+\epsilon] [1−ϵ,1+ϵ],则对其进行截断。
- 截断的目的是限制策略更新幅度,避免策略发生过大变化。
(3)完整优化目标**
PPO 的完整目标函数包括三个部分:
L
(
θ
)
=
E
[
L
C
L
I
P
(
θ
)
−
c
1
L
critic
(
ϕ
)
+
c
2
S
[
π
θ
]
(
s
)
]
L(\theta) = \mathbb{E} \left[ L^{CLIP}(\theta) - c_1 L_{\text{critic}}(\phi) + c_2 S[\pi_\theta](s) \right]
L(θ)=E[LCLIP(θ)−c1Lcritic(ϕ)+c2S[πθ](s)]
其中:
- L C L I P ( θ ) L^{CLIP}(\theta) LCLIP(θ) 是截断后的策略目标,用于更新 Actor。
- L critic ( ϕ ) = E [ ( G t − V ϕ ( s t ) ) 2 ] L_{\text{critic}}(\phi) = \mathbb{E} \left[ (G_t - V_\phi(s_t))^2 \right] Lcritic(ϕ)=E[(Gt−Vϕ(st))2] 是 Critic 的损失,用于更新价值网络。
- S [ π θ ] ( s ) S[\pi_\theta](s) S[πθ](s) 是策略的熵正则项,用于鼓励探索性。
- c 1 c_1 c1 和 c 2 c_2 c2 是权重超参数。
1.2 痛点
然而,PPO在大规模模型训练中暴露两大痛点。首先,是显存瓶颈。需维护价值网络(Value Model),其与Actor规模相当,显存占用增加30%以上。其次,是优势偏差。基于绝对奖励的优势估计(Aₜ = 奖励 - 价值预测)易受单一样本波动影响,存在绝对优势偏差,尤其在稀疏奖励场景(如数学推理)表现不稳定。
二、GRPO核心原理:群体相对策略优化
GRPO核心原理是用群体采样替代价值网络,通过组内竞争计算相对优势,并用双重约束柔性控制策略更新,解决PPO的显存瓶颈和稀疏奖励不稳定问题。
2.1 GRPO的三大创新(对标痛点)
✨ 创新1:无Critic架构(解决显存问题)
主要是去掉价值网络,用群体采样直接计算相对优势,对每个状态采样G个动作(群体),计算组内归一化奖励。显存节省30%+(仅需维护Actor网络):
A
^
t
=
单个动作奖励
−
组内平均奖励
组内奖励标准差
+
ϵ
(自动归零中心化和归一化)
\hat{A}_t = \frac{\text{单个动作奖励} - \text{组内平均奖励}}{\text{组内奖励标准差} + \epsilon} \quad \text{(自动归零中心化和归一化)}
A^t=组内奖励标准差+ϵ单个动作奖励−组内平均奖励(自动归零中心化和归一化)
✨ 创新2:相对优势估计(解决偏差问题)
PPO用绝对优势(依赖价值网络),GRPO用相对优势(组内竞争),把专家打分改成组内内卷:
组内平均奖励
=
1
G
∑
奖励
,
组内标准差
=
1
G
∑
(
奖励
−
平均
)
2
\text{组内平均奖励} = \frac{1}{G}\sum \text{奖励}, \quad \text{组内标准差} = \sqrt{\frac{1}{G}\sum (\text{奖励}-\text{平均})^2}
组内平均奖励=G1∑奖励,组内标准差=G1∑(奖励−平均)2
✨ 创新3:双重约束机制(优化策略更新)
PPO的单一截断 → GRPO的双重约束。柔性控制策略更新(局部+全局约束):
- 截断约束(Clipping):限制单步策略更新幅度(同PPO)
- KL散度惩罚:显式约束新旧策略分布差异(避免整体剧烈变化)
对应公式:
L
(
θ
)
=
min
(
截断项
,
原始项
)
−
β
⋅
KL
(
旧策略
∣
∣
新策略
)
\mathcal{L}(\theta) = \min(\text{截断项}, \text{原始项}) - \beta \cdot \text{KL}(旧策略||新策略)
L(θ)=min(截断项,原始项)−β⋅KL(旧策略∣∣新策略)
2.2 GRPO核心公式(对比PPO)
| 组件 | PPO公式 | GRPO公式 |
|---|---|---|
| 目标函数 | L C L I P = min ( r A , clip ( r ) A ) L^{CLIP} = \min(rA, \text{clip}(r)A) LCLIP=min(rA,clip(r)A) | L G R P O = min ( r A ^ , clip ( r ) A ^ ) − β ⋅ KL L^{GRPO} = \min(r\hat{A}, \text{clip}(r)\hat{A}) - \beta \cdot \text{KL} LGRPO=min(rA^,clip(r)A^)−β⋅KL |
| 优势 | 绝对优势 A = 奖励 − V ( s ) A = \text{奖励} - V(s) A=奖励−V(s)(依赖Critic) | 相对优势 A ^ = 奖励 − 组内平均 组内标准差 \hat{A} = \frac{\text{奖励}-\text{组内平均}}{\text{组内标准差}} A^=组内标准差奖励−组内平均(无Critic) |
| 约束 | 单一截断约束 | 截断 + KL散度双重约束 |
| 网络 | Actor + Critic(双网络) | 仅Actor(群体采样) |
2.3 通俗比喻:考试排名 vs 绝对分数
- PPO:每个学生的进步(策略更新)依赖“绝对分数”(价值网络预测的基准分),容易受试卷难度(奖励稀疏性)影响。
- GRPO:每个学生的进步看“班级排名”(组内相对优势),自动抵消试卷难度差异(归一化奖励),且老师(约束机制)同时关注单题正确率(截断)和整体学习稳定性(KL散度)。
2.4 关键公式图解
PPO目标: GRPO目标:
min(新旧策略比×绝对优势, 截断后的新旧策略比×绝对优势)
↓↓↓
min(新旧策略比×相对优势, 截断后的新旧策略比×相对优势) - KL惩罚项
(无价值网络,相对优势=(个人分数-班级平均分)/班级标准差)
2.5 适用场景
- ✅ 稀疏奖励任务(数学推理、代码生成、定理证明):DeepSeek-R1在数学推理任务中,通过GRPO将解题准确率提升18%,同时将训练成本降低40%(据MobotStone分析)。
- ✅ 大模型显存受限场景(节省30%+显存):去除Critic网络,千亿参数模型训练显存占用降低约30%(参考DeepSeek实践)。
- ❌ 简单连续控制任务(PPO已足够高效):比如gym中的简单游戏以及不能体现出GRPO较PPO的优势,第四节的
GRPO vs PPO.py实验结果就有体现。
三、GRPO算法实现:
以下是基于PyTorch的GRPO核心实现:
3.1 策略网络(仅保留Actor)
class GRPOPolicyNet(torch.nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim):
super().__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
return F.softmax(self.fc2(x), dim=1)
3.2 群体采样与优势计算
class GRPO:
def __init__(self, state_dim, action_dim, hidden_dim=128,
lr=3e-4, eps=0.2, beta=0.01, gamma=0.99,
device='cpu'):
self.device = device
self.actor = GRPOPolicyNet(state_dim, hidden_dim, action_dim).to(device)
self.optimizer = optim.Adam(self.actor.parameters(), lr=lr)
self.eps = eps # 截断参数
self.beta = beta # KL惩罚系数
self.gamma = gamma # 折扣因子
self.action_dim = action_dim
self.state_dim = state_dim
def sample(self, state):
"""单动作采样"""
state = torch.tensor([state], dtype=torch.float, device=self.device)
prob = self.actor(state)
dist = Categorical(prob)
action = dist.sample()
return action.cpu().numpy()[0], prob.detach().cpu().numpy()[0]
def update(self, transitions, discounted_rewards):
"""执行策略更新(修复优势和KL计算)"""
states = torch.tensor(transitions['states'], dtype=torch.float, device=self.device)
old_probs = torch.tensor(transitions['old_probs'], dtype=torch.float, device=self.device)
actions = torch.tensor(transitions['actions'], dtype=torch.long, device=self.device).view(-1, 1)
A = torch.tensor(discounted_rewards, dtype=torch.float, device=self.device).view(-1, 1)
# 1. 计算策略比率
new_probs = self.actor(states).gather(1, actions)
ratio = torch.exp(torch.log(new_probs) - torch.log(old_probs.gather(1, actions)))
# 2. 计算损失
# 截断损失
surr1 = ratio * A
surr2 = torch.clamp(ratio, 1-self.eps, 1+self.eps) * A
clip_loss = -torch.mean(torch.min(surr1, surr2))
# KL散度惩罚(分布间精确计算)
old_dist = Categorical(old_probs)
new_dist = Categorical(self.actor(states))
kl_div = kl_divergence(old_dist, new_dist)
kl_loss = torch.mean(kl_div)
# 总损失
total_loss = clip_loss + self.beta * kl_loss
# 3. 梯度更新
self.optimizer.zero_grad()
total_loss.backward()
self.optimizer.step()
return {
'clip_loss': clip_loss.item(),
'kl_loss': kl_loss.item(),
'total_loss': total_loss.item()
}
3.3 训练流程对比
# PPO训练循环(参考原代码)
def ppo_train():
while not done:
action = agent.take_action(state)
# 单一样本采集...
agent.update(transition_dict) # 含Critic更新
# GRPO训练循环(群体采样)
def grpo_train():
for episode in range(num_episodes):
transitions = {'states': [], 'actions': [], 'old_probs': [], 'rewards': []}
state = env.reset()
while not done:
# 群体采样(G=16)
actions, probs = agent.sample_group(state, group_size=16)
for a, p in zip(actions, probs):
next_state, reward, done, _ = env.step(a)
transitions['states'].append(state)
transitions['actions'].append(a)
transitions['old_probs'].append(p)
transitions['rewards'].append(reward)
state = next_state
agent.update(transitions) # 仅更新Actor
3.4 大语言模型 GRPO
随着群体采样规模(N从16到128+)的动态优化,以及与FlashAttention等加速技术的深度整合,GRPO已成为大模型强化学习的标配算法,推动AGI在推理、创作等领域的持续突破。
# 大语言模型 GRPO训练示例(伪代码)
class GRPOAgent:
def __init__(self, model, group_size=16, beta=0.01, eps=0.2):
self.model = model # 大语言模型作为策略网络
self.group_size = group_size
self.beta = beta
self.eps = eps
def train(self, dataset):
for batch in dataset:
prompts = batch['questions']
# 群体采样:同一问题生成G个回答
completions = self.model.generate(prompts, num_samples=self.group_size)
# 奖励计算(规则/模型驱动)
rewards = compute_rewards(completions) # 如数学题正确性评分
# 组内归一化
rewards = (rewards - rewards.mean()) / (rewards.std() + 1e-8)
# 策略更新
loss = self.calculate_loss(completions, rewards)
self.model.backward(loss)
self.model.step()
def calculate_loss(self, completions, rewards):
# 计算新旧策略概率比
log_probs = self.model.log_prob(completions)
old_log_probs = self.model_old.log_prob(completions).detach()
ratio = torch.exp(log_probs - old_log_probs)
# 截断目标+KL惩罚
surr = torch.min(ratio*rewards, torch.clamp(ratio, 1-self.eps, 1+self.eps)*rewards)
kl_div = torch.mean(torch.sum(old_log_probs - log_probs, dim=-1))
return -torch.mean(surr) + self.beta * kl_div
代码说明:结合Hugging Face Transformers与vLLM,可实现分布式群体采样。实际应用中需注意:
- 采样组大小(group_size)权衡稳定性与计算成本(大N需更高并行能力);
- KL系数(beta)动态调整(如使用Trust Region策略);
- 奖励函数设计(规则/模型驱动)需匹配任务特性(如数学题的步骤正确性评分)。
通过GRPO,强化学习正从“单一个体试错”迈向“群体智慧进化”,这种范式转变不仅提升了训练效率,更打开了大模型在复杂推理领域的潜力。正如DeepSeek的实践所示,GRPO不仅是算法创新,更是工程与理论结合的典范,为大模型时代的RLHF(基于人类反馈的强化学习)提供了可扩展的新路径。
四、代码运行结果
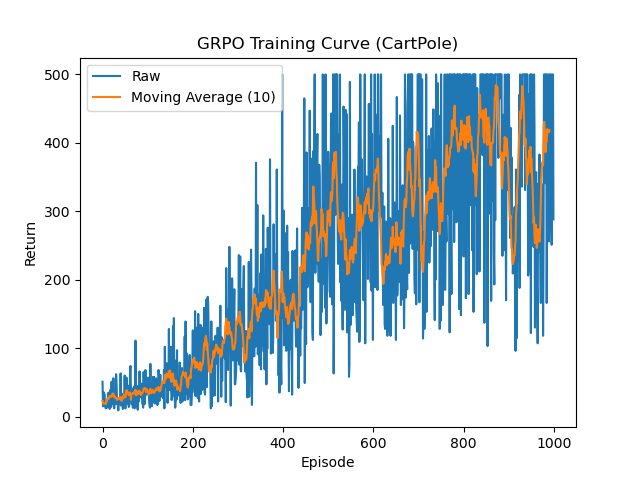
4.1 GRPO
A.代码:
import gym
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical, kl_divergence
import numpy as np
from tqdm import tqdm
import collections
import random
# -------------------------
# 1. 策略网络定义
# -------------------------
class GRPOPolicyNet(nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim):
super(GRPOPolicyNet, self).__init__()
self.layers = nn.Sequential(
nn.Linear(state_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, action_dim)
)
def forward(self, x):
logits = self.layers(x)
return F.softmax(logits, dim=-1)
# -------------------------
# 2. GRPO算法实现(核心修复)
# -------------------------
class GRPO:
def __init__(self, state_dim, action_dim, hidden_dim=128,
lr=3e-4, eps=0.2, beta=0.01, gamma=0.99,
device='cpu'):
self.device = device
self.actor = GRPOPolicyNet(state_dim, hidden_dim, action_dim).to(device)
self.optimizer = optim.Adam(self.actor.parameters(), lr=lr)
self.eps = eps # 截断参数
self.beta = beta # KL惩罚系数
self.gamma = gamma # 折扣因子
self.action_dim = action_dim
self.state_dim = state_dim
def sample(self, state):
"""单动作采样"""
state = torch.tensor([state], dtype=torch.float, device=self.device)
prob = self.actor(state)
dist = Categorical(prob)
action = dist.sample()
return action.cpu().numpy()[0], prob.detach().cpu().numpy()[0]
def update(self, transitions, discounted_rewards):
"""执行策略更新(修复优势和KL计算)"""
states = torch.tensor(transitions['states'], dtype=torch.float, device=self.device)
old_probs = torch.tensor(transitions['old_probs'], dtype=torch.float, device=self.device)
actions = torch.tensor(transitions['actions'], dtype=torch.long, device=self.device).view(-1, 1)
A = torch.tensor(discounted_rewards, dtype=torch.float, device=self.device).view(-1, 1)
# 1. 计算策略比率
new_probs = self.actor(states).gather(1, actions)
ratio = torch.exp(torch.log(new_probs) - torch.log(old_probs.gather(1, actions)))
# 2. 计算损失
# 截断损失
surr1 = ratio * A
surr2 = torch.clamp(ratio, 1-self.eps, 1+self.eps) * A
clip_loss = -torch.mean(torch.min(surr1, surr2))
# KL散度惩罚(分布间精确计算)
old_dist = Categorical(old_probs)
new_dist = Categorical(self.actor(states))
kl_div = kl_divergence(old_dist, new_dist)
kl_loss = torch.mean(kl_div)
# 总损失
total_loss = clip_loss + self.beta * kl_loss
# 3. 梯度更新
self.optimizer.zero_grad()
total_loss.backward()
self.optimizer.step()
return {
'clip_loss': clip_loss.item(),
'kl_loss': kl_loss.item(),
'total_loss': total_loss.item()
}
# -------------------------
# 3. 训练辅助工具
# -------------------------
class EpisodeBuffer:
def __init__(self):
self.states = []
self.actions = []
self.old_probs = []
self.rewards = []
def add(self, state, action, old_prob, reward):
self.states.append(state)
self.actions.append(action)
self.old_probs.append(old_prob)
self.rewards.append(reward)
def clear(self):
self.states.clear()
self.actions.clear()
self.old_probs.clear()
self.rewards.clear()
def to_dict(self):
return {
'states': np.array(self.states),
'actions': np.array(self.actions),
'old_probs': np.array(self.old_probs),
'rewards': np.array(self.rewards)
}
def moving_average(a, window=5):
ret = np.cumsum(a, dtype=float)
ret[window:] = ret[window:] - ret[:-window]
return ret[window - 1:] / window
# -------------------------
# 4. 训练主循环(关键修复)
# -------------------------
def train(env_name='CartPole-v1', num_episodes=1000, render=False):
env = gym.make(env_name)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
# 超参数配置
config = {
'hidden_dim': 128,
'lr': 3e-4,
'eps': 0.2,
'beta': 0.01,
'gamma': 0.99,
'device': 'cuda' if torch.cuda.is_available() else 'cpu'
}
agent = GRPO(state_dim, action_dim, **config)
buffer = EpisodeBuffer()
returns = []
for episode in tqdm(range(1, num_episodes+1), desc='Training'):
state, _ = env.reset() # 正确获取初始状态
episode_return = 0
buffer.clear()
done = False
while not done:
if render and episode % 100 == 0:
env.render()
# 单动作采样(修复)
action, old_prob = agent.sample(state)
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
buffer.add(
state=state,
action=action,
old_prob=old_prob,
reward=reward
)
state = next_state
episode_return += reward
# 计算折扣累积奖励(修复优势估计)
rewards = buffer.rewards
discounted_rewards = []
running_reward = 0
for r in reversed(rewards):
running_reward = r + agent.gamma * running_reward
discounted_rewards.insert(0, running_reward)
discounted_rewards = (discounted_rewards - np.mean(discounted_rewards)) / (np.std(discounted_rewards) + 1e-8)
# 执行策略更新
transitions = buffer.to_dict()
loss_info = agent.update(transitions, discounted_rewards)
returns.append(episode_return)
# 进度显示
if episode % 10 == 0:
avg_return = np.mean(returns[-10:])
tqdm.write(f"Episode: {episode}, Return: {avg_return:.2f}, "
f"Loss: {loss_info['total_loss']:.4f}, KL: {loss_info['kl_loss']:.4f}")
env.close()
return returns
# -------------------------
# 5. 运行入口
# -------------------------
if __name__ == '__main__':
returns = train(num_episodes=1000)
# 绘制训练曲线
import matplotlib.pyplot as plt
plt.plot(returns)
plt.plot(moving_average(returns, window=10))
plt.title('GRPO Training Curve (CartPole)')
plt.xlabel('Episode')
plt.ylabel('Return')
plt.legend(['Raw', 'Moving Average (10)'])
plt.show()
B.训练过程:
Episode: 10, Return: 22.90, Loss: -0.0000, KL: 0.0000
Episode: 20, Return: 22.80, Loss: -0.0000, KL: -0.0000
Episode: 30, Return: 29.30, Loss: -0.0000, KL: 0.0000
Episode: 40, Return: 27.60, Loss: 0.0000, KL: 0.0000
Episode: 50, Return: 29.00, Loss: 0.0000, KL: -0.0000
Episode: 60, Return: 27.70, Loss: 0.0000, KL: 0.0000
Episode: 70, Return: 32.90, Loss: 0.0000, KL: 0.0000
Episode: 80, Return: 35.80, Loss: 0.0000, KL: -0.0000
Episode: 90, Return: 34.40, Loss: -0.0000, KL: 0.0000
Episode: 100, Return: 38.00, Loss: -0.0000, KL: -0.0000
Episode: 110, Return: 36.60, Loss: 0.0000, KL: 0.0000
Episode: 120, Return: 38.70, Loss: 0.0000, KL: 0.0000
Episode: 130, Return: 39.10, Loss: 0.0000, KL: -0.0000
Episode: 140, Return: 43.40, Loss: 0.0000, KL: 0.0000
Episode: 150, Return: 55.60, Loss: 0.0000, KL: 0.0000
Episode: 160, Return: 66.60, Loss: 0.0000, KL: -0.0000
Episode: 170, Return: 45.10, Loss: -0.0000, KL: -0.0000
Episode: 180, Return: 40.30, Loss: 0.0000, KL: 0.0000
Episode: 190, Return: 61.70, Loss: -0.0000, KL: 0.0000
Episode: 200, Return: 47.20, Loss: -0.0000, KL: 0.0000
Episode: 210, Return: 83.00, Loss: -0.0000, KL: -0.0000
Episode: 220, Return: 73.20, Loss: -0.0000, KL: 0.0000
Episode: 230, Return: 73.00, Loss: 0.0000, KL: 0.0000
Episode: 240, Return: 113.30, Loss: -0.0000, KL: -0.0000
Episode: 250, Return: 64.40, Loss: 0.0000, KL: 0.0000
Episode: 260, Return: 100.10, Loss: 0.0000, KL: 0.0000
Episode: 270, Return: 97.50, Loss: -0.0000, KL: 0.0000
Episode: 280, Return: 113.00, Loss: 0.0000, KL: 0.0000
Episode: 290, Return: 131.10, Loss: -0.0000, KL: -0.0000
Episode: 300, Return: 98.00, Loss: 0.0000, KL: -0.0000
Episode: 310, Return: 146.20, Loss: -0.0000, KL: -0.0000
Episode: 320, Return: 122.10, Loss: -0.0000, KL: -0.0000
Episode: 330, Return: 103.90, Loss: -0.0000, KL: 0.0000
Episode: 340, Return: 124.60, Loss: 0.0000, KL: 0.0000
Episode: 350, Return: 172.20, Loss: -0.0000, KL: 0.0000
Episode: 360, Return: 154.90, Loss: 0.0000, KL: 0.0000
Episode: 370, Return: 172.70, Loss: 0.0000, KL: -0.0000
Episode: 380, Return: 170.40, Loss: -0.0000, KL: -0.0000
Episode: 390, Return: 198.40, Loss: -0.0000, KL: 0.0000
Episode: 400, Return: 148.60, Loss: 0.0000, KL: -0.0000
Episode: 410, Return: 180.70, Loss: 0.0000, KL: 0.0000
Episode: 420, Return: 145.90, Loss: 0.0000, KL: -0.0000
Episode: 430, Return: 157.00, Loss: 0.0000, KL: -0.0000
Episode: 440, Return: 145.60, Loss: 0.0000, KL: -0.0000
Episode: 450, Return: 218.50, Loss: 0.0000, KL: 0.0000
Episode: 460, Return: 254.30, Loss: -0.0000, KL: 0.0000
Episode: 470, Return: 253.60, Loss: -0.0000, KL: -0.0000
Episode: 480, Return: 295.60, Loss: 0.0000, KL: 0.0000
Episode: 490, Return: 254.20, Loss: 0.0000, KL: -0.0000
Episode: 500, Return: 270.70, Loss: -0.0000, KL: -0.0000
Episode: 510, Return: 290.30, Loss: -0.0000, KL: 0.0000
Episode: 520, Return: 356.80, Loss: 0.0000, KL: 0.0000
Episode: 530, Return: 316.30, Loss: -0.0000, KL: 0.0000
Episode: 540, Return: 286.60, Loss: -0.0000, KL: -0.0000
Episode: 550, Return: 237.70, Loss: 0.0000, KL: -0.0000
Episode: 560, Return: 236.50, Loss: 0.0000, KL: -0.0000
Episode: 570, Return: 241.80, Loss: 0.0000, KL: -0.0000
Episode: 580, Return: 287.20, Loss: 0.0000, KL: 0.0000
Episode: 590, Return: 302.70, Loss: -0.0000, KL: 0.0000
Episode: 600, Return: 312.90, Loss: -0.0000, KL: -0.0000
Episode: 610, Return: 308.60, Loss: 0.0000, KL: -0.0000
Episode: 620, Return: 376.90, Loss: 0.0000, KL: 0.0000
Episode: 630, Return: 211.00, Loss: 0.0000, KL: 0.0000
Episode: 640, Return: 229.80, Loss: -0.0000, KL: 0.0000
Episode: 650, Return: 253.00, Loss: -0.0000, KL: -0.0000
Episode: 660, Return: 263.60, Loss: -0.0000, KL: -0.0000
Episode: 670, Return: 223.30, Loss: 0.0000, KL: 0.0000
Episode: 680, Return: 317.90, Loss: 0.0000, KL: -0.0000
Episode: 690, Return: 391.40, Loss: 0.0000, KL: 0.0000
Episode: 700, Return: 313.70, Loss: 0.0000, KL: 0.0000
Episode: 710, Return: 394.90, Loss: -0.0000, KL: 0.0000
Episode: 720, Return: 211.60, Loss: 0.0000, KL: 0.0000
Episode: 730, Return: 325.70, Loss: -0.0000, KL: 0.0000
Episode: 740, Return: 326.90, Loss: -0.0000, KL: 0.0000
Episode: 750, Return: 328.20, Loss: 0.0000, KL: 0.0000
Episode: 760, Return: 311.80, Loss: -0.0000, KL: -0.0000
Episode: 770, Return: 351.70, Loss: 0.0000, KL: -0.0000
Episode: 780, Return: 392.90, Loss: -0.0000, KL: 0.0000
Episode: 790, Return: 454.40, Loss: -0.0000, KL: -0.0000
Episode: 800, Return: 392.70, Loss: -0.0000, KL: 0.0000
Episode: 810, Return: 405.10, Loss: 0.0000, KL: 0.0000
Episode: 820, Return: 401.00, Loss: 0.0000, KL: -0.0000
Episode: 830, Return: 386.60, Loss: 0.0000, KL: -0.0000
Episode: 840, Return: 381.60, Loss: 0.0000, KL: 0.0000
Episode: 850, Return: 437.00, Loss: 0.0000, KL: 0.0000
Episode: 860, Return: 429.30, Loss: -0.0000, KL: -0.0000
Episode: 870, Return: 388.20, Loss: 0.0000, KL: -0.0000
Episode: 880, Return: 462.90, Loss: -0.0000, KL: 0.0000
Episode: 890, Return: 397.20, Loss: 0.0000, KL: 0.0000
Episode: 900, Return: 394.50, Loss: -0.0000, KL: -0.0000
Episode: 910, Return: 340.10, Loss: 0.0000, KL: 0.0000
Episode: 920, Return: 225.30, Loss: 0.0000, KL: -0.0000
Episode: 930, Return: 347.60, Loss: 0.0000, KL: -0.0000
Episode: 940, Return: 483.10, Loss: 0.0000, KL: 0.0000
Episode: 950, Return: 339.50, Loss: 0.0000, KL: -0.0000
Episode: 960, Return: 377.50, Loss: -0.0000, KL: 0.0000
Episode: 970, Return: 280.30, Loss: 0.0000, KL: -0.0000
Episode: 980, Return: 283.30, Loss: -0.0000, KL: -0.0000
Episode: 990, Return: 406.00, Loss: -0.0000, KL: -0.0000
Episode: 1000, Return: 418.60, Loss: 0.0000, KL: -0.0000
Training: 100%|██████████████████████████████████████████████████████████████████| 1000/1000 [02:04<00:00, 8.01it/s]
C.训练结果:
4.2 GRPO VS PPO
A.代码:
import gym
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical, kl_divergence
import numpy as np
from tqdm import tqdm
import matplotlib.pyplot as plt
import rl_utils
import PPO
# ===========================
# 0. 统一配置与工具
# ===========================
class Config:
ENV_NAME = 'CartPole-v1'
NUM_EPISODES = 1000
HIDDEN_DIM = 128
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
SEED = 0
# PPO专属配置
PPO_CFG = {
'actor_lr': 1e-3,
'critic_lr': 1e-2,
'lmbda': 0.95,
'epochs': 10,
'eps': 0.2,
'gamma': 0.98,
}
# GRPO专属配置
GRPO_CFG = {
'lr': 3e-4,
'eps': 0.2,
'beta': 0.01,
'gamma': 0.99,
}
def set_seed(seed):
torch.manual_seed(seed)
np.random.seed(seed)
# ===========================
# 1. PPO训练函数
# ===========================
def train_ppo():
set_seed(Config.SEED)
env = gym.make(Config.ENV_NAME)
env.reset(seed=Config.SEED)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
agent = PPO.PPO(
state_dim=state_dim,
hidden_dim=Config.HIDDEN_DIM,
action_dim=action_dim,
actor_lr=Config.PPO_CFG['actor_lr'],
critic_lr=Config.PPO_CFG['critic_lr'],
lmbda=Config.PPO_CFG['lmbda'],
epochs=Config.PPO_CFG['epochs'],
eps=Config.PPO_CFG['eps'],
gamma=Config.PPO_CFG['gamma'],
device=Config.DEVICE
)
return rl_utils.train_on_policy_agent(
env=env,
agent=agent,
num_episodes=Config.NUM_EPISODES
)
# ===========================
# 2. GRPO训练函数
# ===========================
class GRPO:
def __init__(self, state_dim, action_dim, hidden_dim=128, **kwargs):
self.device = kwargs['device']
self.actor = nn.Sequential(
nn.Linear(state_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, action_dim),
nn.Softmax(dim=-1)
).to(self.device)
self.optimizer = optim.Adam(self.actor.parameters(), lr=kwargs['lr'])
self.eps = kwargs['eps']
self.beta = kwargs['beta']
self.gamma = kwargs['gamma']
def sample(self, state):
state = torch.tensor([state], dtype=torch.float, device=self.device)
probs = self.actor(state)
dist = Categorical(probs)
action = dist.sample()
return action.cpu().numpy()[0], probs.detach().cpu().numpy()[0]
def update(self, transitions, discounted_rewards):
states = torch.tensor(transitions['states'], dtype=torch.float, device=self.device)
old_probs = torch.tensor(transitions['old_probs'], dtype=torch.float, device=self.device)
actions = torch.tensor(transitions['actions'], dtype=torch.long, device=self.device).view(-1, 1)
A = torch.tensor(discounted_rewards, dtype=torch.float, device=self.device).view(-1, 1)
new_probs = self.actor(states).gather(1, actions)
ratio = torch.exp(torch.log(new_probs) - torch.log(old_probs.gather(1, actions)))
surr1 = ratio * A
surr2 = torch.clamp(ratio, 1-self.eps, 1+self.eps) * A
clip_loss = -torch.mean(torch.min(surr1, surr2))
old_dist = Categorical(old_probs)
new_dist = Categorical(self.actor(states))
kl_div = kl_divergence(old_dist, new_dist)
kl_loss = torch.mean(kl_div)
total_loss = clip_loss + self.beta * kl_loss
self.optimizer.zero_grad()
total_loss.backward()
self.optimizer.step()
return {
'clip_loss': clip_loss.item(),
'kl_loss': kl_loss.item(),
'total_loss': total_loss.item()
}
class EpisodeBuffer:
def __init__(self):
self.states = []
self.actions = []
self.old_probs = []
self.rewards = []
def add(self, state, action, old_prob, reward):
self.states.append(state)
self.actions.append(action)
self.old_probs.append(old_prob)
self.rewards.append(reward)
def clear(self):
self.states.clear()
self.actions.clear()
self.old_probs.clear()
self.rewards.clear()
def to_dict(self):
return {
'states': np.array(self.states),
'actions': np.array(self.actions),
'old_probs': np.array(self.old_probs),
'rewards': np.array(self.rewards)
}
def train_grpo():
set_seed(Config.SEED)
env = gym.make(Config.ENV_NAME)
env.reset(seed=Config.SEED)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
config = {
'hidden_dim': Config.HIDDEN_DIM,
'lr': Config.GRPO_CFG['lr'],
'eps': Config.GRPO_CFG['eps'],
'beta': Config.GRPO_CFG['beta'],
'gamma': Config.GRPO_CFG['gamma'],
'device': Config.DEVICE
}
agent = GRPO(state_dim, action_dim, **config)
buffer = EpisodeBuffer()
returns = []
for episode in tqdm(range(1, Config.NUM_EPISODES+1), desc='GRPO Training'):
state, _ = env.reset()
episode_return = 0
buffer.clear()
done = False
while not done:
action, old_prob = agent.sample(state)
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
buffer.add(state, action, old_prob, reward)
state = next_state
episode_return += reward
rewards = buffer.rewards
discounted_rewards = []
running_reward = 0
for r in reversed(rewards):
running_reward = r + agent.gamma * running_reward
discounted_rewards.insert(0, running_reward)
discounted_rewards = (discounted_rewards - np.mean(discounted_rewards)) / (np.std(discounted_rewards) + 1e-8)
transitions = buffer.to_dict()
agent.update(transitions, discounted_rewards)
returns.append(episode_return)
env.close()
return returns
# ===========================
# 3. 对比实验主流程
# ===========================
if __name__ == '__main__':
ppo_returns = train_ppo()
grpo_returns = train_grpo()
min_len = min(len(ppo_returns), len(grpo_returns))
ppo_returns = ppo_returns[:min_len]
grpo_returns = grpo_returns[:min_len]
window = 10
ppo_ma = rl_utils.moving_average(np.array(ppo_returns), window_size=window)
grpo_ma = rl_utils.moving_average(np.array(grpo_returns), window_size=window)
plt.figure(figsize=(12, 6))
plt.plot(ppo_returns, alpha=0.3, color='#1f77b4', label='PPO (Raw)')
plt.plot(range(window-1, len(ppo_ma)+window-1), ppo_ma, color='#1f77b4', label=f'PPO (MA-{window})')
plt.plot(grpo_returns, alpha=0.3, color='#ff7f0e', label='GRPO (Raw)')
plt.plot(range(window-1, len(grpo_ma)+window-1), grpo_ma, color='#ff7f0e', label=f'GRPO (MA-{window})')
plt.title(f'PPO vs GRPO: {Config.ENV_NAME} Training Comparison')
plt.xlabel('Episode')
plt.ylabel('Episode Return')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
print("\n=== Final Performance ===")
print(f"PPO: Last 10 episodes avg: {np.mean(ppo_returns[-10:]):.2f}")
print(f"GRPO: Last 10 episodes avg: {np.mean(grpo_returns[-10:]):.2f}")
B.训练过程:
Iteration 0: 100%|████████████████████████████████████| 100/100 [00:29<00:00, 3.41it/s, episode=100, return=327.800]
Iteration 1: 100%|████████████████████████████████████| 100/100 [00:30<00:00, 3.33it/s, episode=200, return=500.000]
Iteration 2: 100%|████████████████████████████████████| 100/100 [00:36<00:00, 2.74it/s, episode=300, return=500.000]
Iteration 3: 100%|████████████████████████████████████| 100/100 [00:32<00:00, 3.03it/s, episode=400, return=500.000]
Iteration 4: 100%|████████████████████████████████████| 100/100 [00:33<00:00, 2.96it/s, episode=500, return=500.000]
Iteration 5: 100%|████████████████████████████████████| 100/100 [00:39<00:00, 2.51it/s, episode=600, return=451.300]
Iteration 6: 100%|████████████████████████████████████| 100/100 [00:45<00:00, 2.19it/s, episode=700, return=500.000]
Iteration 7: 100%|████████████████████████████████████| 100/100 [00:38<00:00, 2.62it/s, episode=800, return=500.000]
Iteration 8: 100%|████████████████████████████████████| 100/100 [00:36<00:00, 2.75it/s, episode=900, return=500.000]
Iteration 9: 100%|███████████████████████████████████| 100/100 [00:37<00:00, 2.70it/s, episode=1000, return=500.000]
GRPO Training: 100%|█████████████████████████████████████████████████████████████| 1000/1000 [02:47<00:00, 5.97it/s]
2025-03-28 13:55:26.493 python[24487:1970108] +[CATransaction synchronize] called within transaction
=== Final Performance ===
PPO: Last 10 episodes avg: 500.00
GRPO: Last 10 episodes avg: 417.80
C.训练结果:
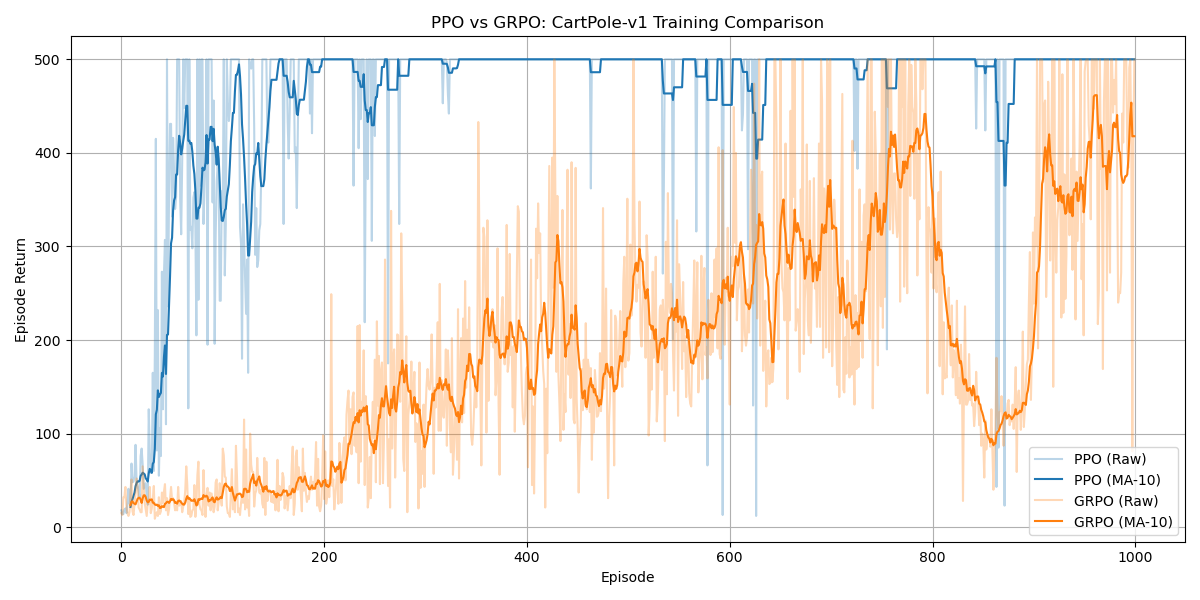
从上面看,在gym的CartPole游戏上,GRPO训练的收敛速度没有PPO快。