多路转接epoll
目录
一、为什么epoll最高效?
二、epoll的三个系统调用
三、理解epoll模型
四、epoll的优点
五、epoll的使用示例
六、epoll的工作模式
ET模式和LT模式的对比
七、epoll的使用场景
总结
一、为什么epoll最高效?
按照 man 手册的说法: 是为处理大批量句柄而作了改进的 poll。
epoll是在 2.5.44 内核中被引进的,它几乎具备了之前所说的一切优点,被公认为 Linux2.6 下性能最好的多路 I/O 就绪通知方法。
epoll的性能最好,最方便使用体现在如下几个点:
(1)epoll的性能最好主要是因为:epoll内核中维护了一颗红黑树,用于管理文件描述符和其要关心的事件。而在之前的select和poll中都是每一次就绪之后,用户如果还想监测该套接字文件描述符对应的事件,则需要手动传入一个辅助数组(或者位图),select最为明显,他需要传文件描述符的集合和三个关心事件集合;poll只是在select上进步了一点,将select的输入输出型参数分成了两部分,方便管理。但是epoll并非需要每一次就绪之后还得传递文件描述符集合和关心事件到内核!只有你不想关心的时候,再调用某些接口将其从红黑树中删除,这就是性能提升最大的地方----减少了文件描述符和关心事件从用户空间到内核空间的拷贝!
(2)就绪队列:内核除了用红黑树来管理文件描述符集合之外,还有一个双链表结构,设计者在发现之前的poll和select都需要程序员手动遍历文件描述符集合,来查看是哪些文件描述符下面的事件发生了就绪,比较麻烦。所以给他设计了一个就绪队列,只要有就绪事件发生,就插入到该队列中,这样以后就不需要遍历文件描述符集合了,从内核拿就绪事件的事件复杂度减小到了O(1)。
(3)方便使用又如何谈起呢?还是和红黑树有关,他不用每一次就绪之后要重新传,而是内核自己通过这个红黑树管理,即简化了程序员的操作。
二、epoll的三个系统调用
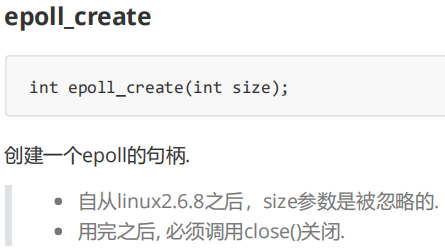
epoll_create, 用于创建epoll模型,他就是创建底层内核中的红黑树,就绪队列等等的系统调用。
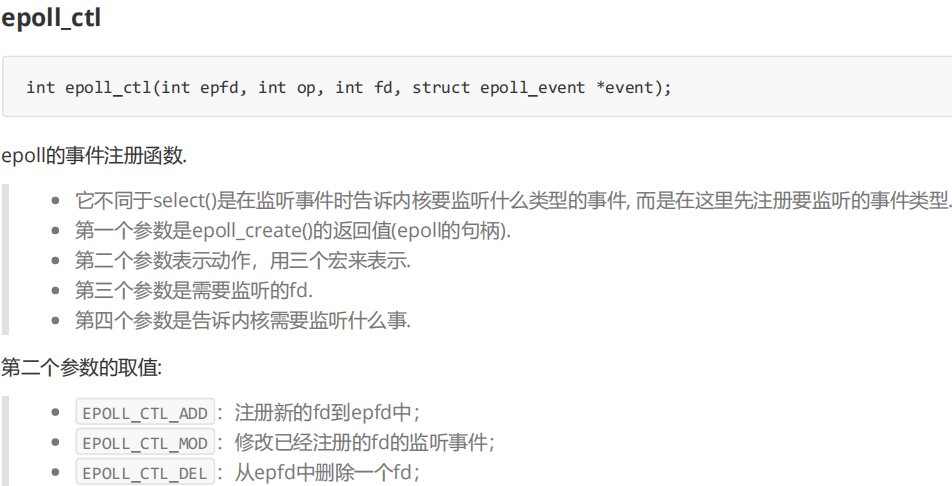
epoll_ctl,用于设置关心的文件描述符和关心的事件。即将一个文件描述符插入到红黑树的节点中去(也可以是修改/删除)

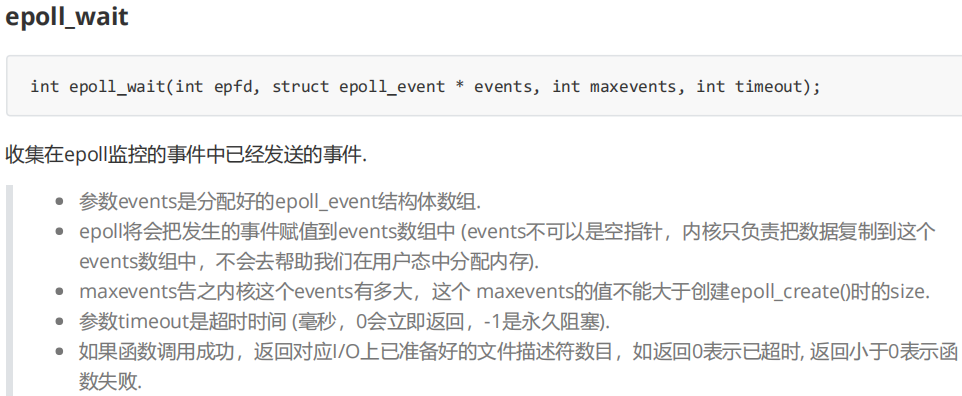
当有就绪事件发生的时候,linux内核会把刚刚红黑树中的节点,链入就绪队列,调用epoll_wait即从就绪队列中拿节点,不需要像之前一样遍历文件描述符集合。
三、理解epoll模型
这是一张关于流程的草图。
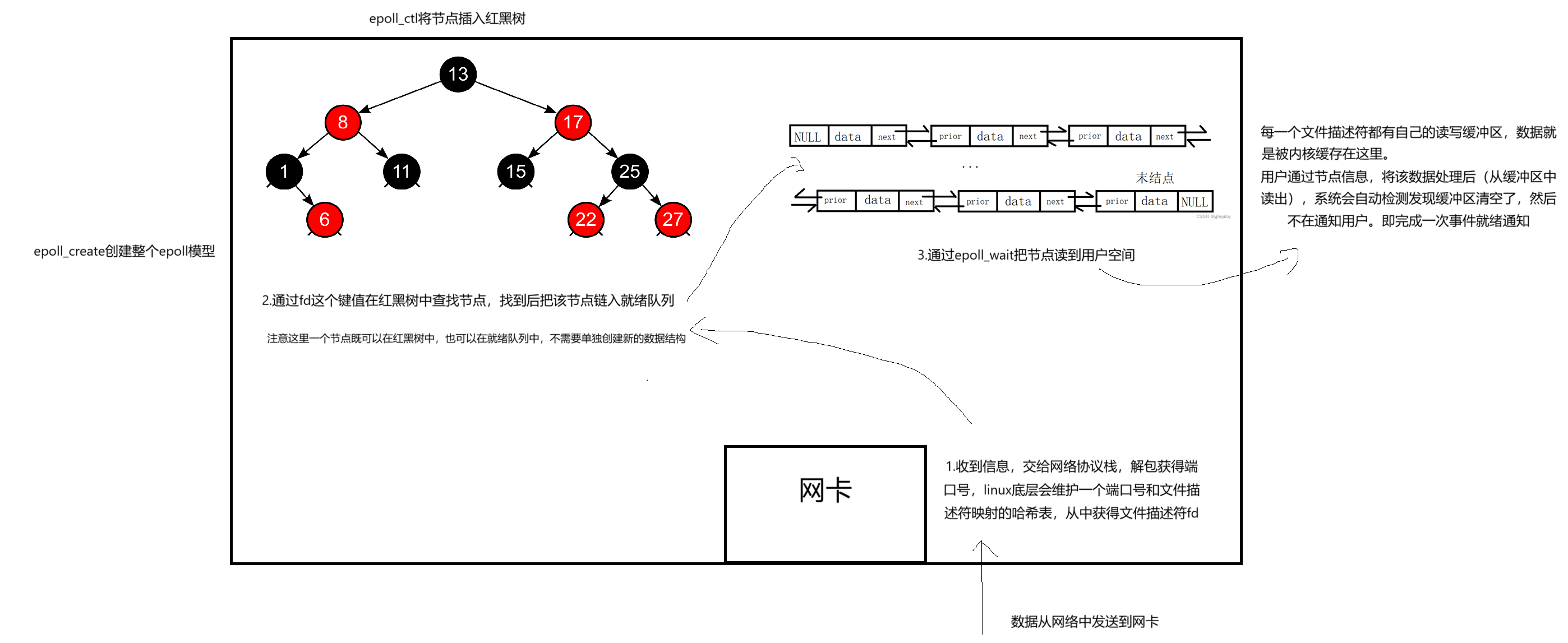
里面提到了一个节点可以既在红黑树又在就绪队列中是为什么呢?我们不妨看看节点的定义。
其实就是一个struct结构体中,包含了两个数据结构信息,一个指向红黑树,另一个指向就绪队列。这个和pcb是不是有异曲同工之妙啊!

struct epitem{
struct rb_node rbn;//红黑树节点
struct list_head rdllink;//双向链表节点
struct epoll_filefd ffd; //事件句柄信息
struct eventpoll *ep; //指向其所属的eventpoll对象
struct epoll_event event; //期待发生的事件类型
}epoll的工作原理
当程序中调用epoll_create时, 会在底层创建一个eventpoll结构体, 此结构体中有两个非常重要的字段:
一颗红黑树的根节点指针
一个队列的头指针
红黑树的用处:
红黑树中存放着所有正在关心的文件描述符, 当我们调用epoll_ctl设置关心事件时, 实际上会在底层的这颗红黑树中添加/删除/修改节点
队列的用处:
队列中存放的是所有存在就绪事件的文件描述符, 当我们调用epoll_wait时, 实际上就是在等待此队列中是否有就绪的文件描述符到来
关于epoll的几个细节:
(1)红黑树的节点是需要key值的, 而文件描述符恰好可以充当这一值
(2)用户只需要设置关心, 获取结果即可, 不用再关心任何对fd和event的管理
(3)底层只要有fd就绪, OS会自动给我构建节点(即从红黑树中查找节点,并非重新构建新的节点), 并且插入到就绪队列中, 上层只需不断从就绪队列中将数据拿走, 就完成了获取就绪事件的任务(生产者消费者模型)

总结一下, epoll的使用过程就是三部曲:
1.调用epoll_create创建一个epoll句柄;
2.调用epoll_ctl, 将要监控的文件描述符注册到红黑树;
3.调用epoll_wait, 等待文件描述符就绪后, 去队列中拿;
四、epoll的优点
对比select的优点:
(1)接口使用方便: 虽然拆分成了三个函数, 但是反而使用起来更方便高效. 不需要每次循环都设置关注的文件描述符, 也做到了输入输出参数分离开
(2)数据拷贝轻量: 只在合适的时候调用 EPOLL_CTL_ADD 将文件描述符结构拷贝到内核中, 这个操作并不频繁(而select/poll都是每次循环都要进行拷贝)
(3)事件回调机制: 避免使用遍历, 而是使用回调函数的方式, 将就绪的文件描述符结构加入到就绪队列中,epoll_wait 返回直接访问就绪队列就知道哪些文件描述符就绪. 这个操作时间复杂度O(1). 即使文件描述符数目很多, 效率也不会受到影响.
(4)没有数量限制: 文件描述符数目无上限.
在这里要着重说明一下事件回调机制,我们在调用epoll_ctl插入一个红黑树节点的时候,实际上还会在内核中注册一个回调函数,告诉内核只有被注册过的fd才需要内核关注。当有一个信息来到内核,内核一看发现该信息对应的fd并没有注册,那我就不管了,由用户自己处理。但是如果这个fd曾经被注册过,内核就会通过这个fd去红黑树中查找节点,然后才将节点插入就绪队列中。
所以这里的回调机制指的是,epoll模型到底要不要对这个信息进行监管!即选择性监管。
而对比select和poll他们都没有这种回调机制,而是有一个数据来临的时候,内核并不会主动通知select模型哪一个就绪了(没有就绪队列),需要内核遍历所有被监管的fd看是不是当前新来消息的这个,如果不是则忽略,如果有大量的新消息都没有被监管,但是内核都需要遍历,这就造成了大量的资源消耗。
正是上诉的优点,使得epoll成为了现代高并发服务器中, 使用的最多的方法, 没有之一!
五、epoll的使用示例
#pragma once
#include <iostream>
#include "socket.hpp"
#include <memory>
#include<sys/epoll.h>
#include<string>
#include "InetAddr.hpp"
using namespace socket_ns;
class EpollServer
{
const static int size=128;//只需要大于0即可,因为epoll已经弃用他了
const static int num=128;
public:
EpollServer(uint16_t port)
:_port(port)
,_listensock(std::make_unique<TcpSocket>())
{
//设置监听套接字为监听状态
_listensock->BuildListenSocket(port);
//创建epoll模型
_epfd=::epoll_create(size);
if(_epfd<0)
{
LOG(FATAL,"epoll_create error!\n");
exit(1);
}
LOG(INFO,"epoll_create success,epfd:%d,you can go on!\n",_epfd);
}
~EpollServer()
{
if(_epfd>=0)
{
::close(_epfd);
}
_listensock->Close();
}
void InitServer()
{
//将_listensock给epoll模型管理起来(往红黑树中插入一个节点)
struct epoll_event ev;
ev.events|=EPOLLIN|EPOLLET;
// ev.events|=EPOLLIN;
ev.data.fd=_listensock->sockfd();
int n=epoll_ctl(_epfd,EPOLL_CTL_ADD,_listensock->sockfd(),&ev);
if(n<0)
{
LOG(FATAL,"epoll_ctl error!\n");
exit(2);
}
LOG(INFO,"epoll_ctl success,add a new sockfd:%d\n",_listensock->sockfd());
}
void Loop()
{
int timeout=1000;
while(1)
{
int n=::epoll_wait(_epfd,_revs,num,1000);
switch (n)
{
case 0:
LOG(INFO,"epoll time out...\n");
break;
case -1:
LOG(ERROR,"epoll error\n");
default:
LOG(INFO,"have enent happend!,n\n:%d",n);
//告诉handler要处理几个就绪事件
// HandlerEvent(n);
break;
}
}
}
void Accepter()
{
InetAddr addr;
SockPtr sock= _listensock->Accepter(&addr); // 肯定不会被阻塞
if (sock->sockfd() < 0)
{
LOG(ERROR, "获取连接失败\n");
return;
}
LOG(INFO, "得到一个新的连接: %d, 客户端信息: %s:%d\n", sock->sockfd(), addr.Ip().c_str(), addr.Port());
// 得到了一个新的sockfd,我们能不能要进行read、recv?不能.
// 等底层有数据(读事件就绪), read/recv才不会被阻塞
// 底层有数据 谁最清楚呢?epoll!
// 将新的sockfd添加到epoll中!怎么做呢?
struct epoll_event ev;
ev.data.fd = sock->sockfd();
ev.events = EPOLLIN;
::epoll_ctl(_epfd, EPOLL_CTL_ADD, sock->sockfd(), &ev);
LOG(INFO, "epoll_ctl success, add new sockfd : %d\n", sock->sockfd());
}
void HandlerIO(int fd)
{
char buffer[4096];
// 你怎么保证buffer就是一个完整的请求?或者有多个请求??
//因为每一个fd共用一个缓冲区,则会要求报文最多4096个字节,如果一次读完发现报文不完整,我上层也不敢处理,
//只能等待下一次通知,但是ET模式只会通知一次,下一次通知之前,可能有别的fd就绪了,就会进入该函数,将buffer覆盖,
//这样只要我>4096个字节就永远不会读到正确的报文了!
//为什么不能使用内核的缓冲区呢?因为内核的缓冲区虽然是可以正确保存数据的,但是我们要读出来,读到哪里呢?必须是用户自定义的一个缓冲区,将内核拷贝过来
//才能被程序读到,所以为了保证数据不会丢失,每一个fd都要有自己的缓冲区
//还需要引入协议确保报文的完整性
int n = ::recv(fd, buffer, sizeof(buffer) - 1, 0); // 会阻塞吗?不会
if (n > 0)
{
//不能保证读完了,要循环读+非阻塞
//1.一个fd要有自己的一个缓冲区,否则不同的fd会造成数据混淆
//2.因为recv不知道读完没有,必须要引入协议才能区分各个报文
buffer[n] = 0;
std::cout << buffer;
std::string response = "HTTP/1.0 200 OK\r\n";
std::string content = "<html><body><h1>dong yi fan is shabi</h1></body></html>";
response += "Content-Type: text/html\r\n";
response += "Content-Length: " + std::to_string(content.size()) + "\r\n";
response += "\r\n";
response += content;
::send(fd, response.c_str(), response.size(), 0);
}
else if (n == 0)
{
LOG(INFO, "client quit, close fd: %d\n", fd);
// 1. 从epoll中移除, 从epoll中移除fd,这个fd必须是健康&&合法的fd. 否则会移除出错
::epoll_ctl(_epfd, EPOLL_CTL_DEL, fd, nullptr);
// 2. 关闭fd
::close(fd);
}
else
{
LOG(ERROR, "recv error, close fd: %d\n", fd);
// 1. 从epoll中移除, 从epoll中移除fd,这个fd必须是健康&&合法的fd. 否则会移除出错
::epoll_ctl(_epfd, EPOLL_CTL_DEL, fd, nullptr);
// 2. 关闭fd
::close(fd);
}
}
void HandlerEvent(int n)
{
//遍历就绪列表n次把所有的就绪事件都处理完
for(int i=0;i<n;i++)
{
//把内核的就绪队列中的节点,读到我自己的缓存区中
int fd=_revs[i].data.fd;
uint32_t revents=_revs[i].events;
LOG(INFO,"%d 上面有事件就绪了,具体事件是:%s\n",fd,EventsToString(revents).c_str());
if (revents & EPOLLIN)
{
// listensock 读事件就绪, 新连接到来了
if (fd == _listensock->sockfd())
Accepter();
else
HandlerIO(fd);
}
}
}
std::string EventsToString(uint32_t events)
{
std::string eventstr;
if(events&EPOLLIN)
{
eventstr="EPOLLIN";
}
if(events&EPOLLOUT)
{
eventstr+="EPOLLOUT";
}
return eventstr;
}
private:
uint16_t _port;
std::unique_ptr<Socket> _listensock;
int _epfd;
struct epoll_event _revs[num];//管理各个节点的数组
};六、epoll的工作模式
epoll有两种工作方式:
(1)水平触发(LT模式)
(2)边缘触发(ET模式)
水平触发模式:
想象一下你一次性买了5个快递, 快递员张三把快递送到你家楼下了, 打电话让你下来拿快递, 但是这个时候你正在和室友开黑, 你就对快递员说: 你等等我, 我打完这把就下来取, 张三也没说什么, 就在楼下等你. 你终于打完了这把游戏, 现在你下去取快递, 但是你一次性只能拿4个快递, 还剩一个在下面, 你给快递员张三说: 你能不能再等我一下, 我上楼后再下来取剩下的一个快递, 张三也没说什么, 就在楼下等你. 你不下来取, 张三就一直等你, 一直给你打电话.
这就是水平触发模式:

通常水平触发模型下, 效率会很低, 因为快递员张三一直在楼下等你, 不能做其他事, 所以有了边缘触发来替代它
边缘触发模式:
想象一下, 假设是李四给你送外卖, 他和张三不一样, 他脾气非常火爆, 你快递到来后他给你打了个电话说: 你快递到了, 我只等你十分钟, 如果你不下楼取快递, 我就把你的快递放在路边了, 并且我只给你打一次电话. 这个时候你会怎么办? 当然你会选择挂机坑队友, 直接跑下楼取快递, 因为你不去你的快递可能就丢失了!
这就是边缘触发模型:

ET模式和LT模式的对比
LT 是 epoll 的默认行为.
使用 ET 能够减少 epoll 触发的次数. 但是代价就是强逼着程序猿一次响应就绪过程中
就把所有的数据都处理完.相当于一个文件描述符就绪之后, 不会反复被提示就绪, 看起来就比 LT 更高效一些. 但是在 LT 情况下如果也能做到每次就绪的文件描述符都立刻处理, 不让这个就绪被重复提示的话, 其实性能也是一样的.另一方面, ET 的代码复杂程度更高了.(1)ET模式通知用户的次数变少, 减少了从内核态到用户态的转换, 提高了效率
(2)ET模式会倒逼程序员尽快将接收缓冲区的数据取走, 那么就可以给对方发送一个更大的接受窗口(TCP协议), 对方就可以有一个更大的滑动窗口, 一次性给我们发送更多数据, 提高IO吞吐。
理解 ET 模式和非阻塞文件描述符
使用 ET 模式的 epoll, 需要将文件描述设置为非阻塞. 这个不是接口上的要求, 而是 "工
程实践" 上的要求.
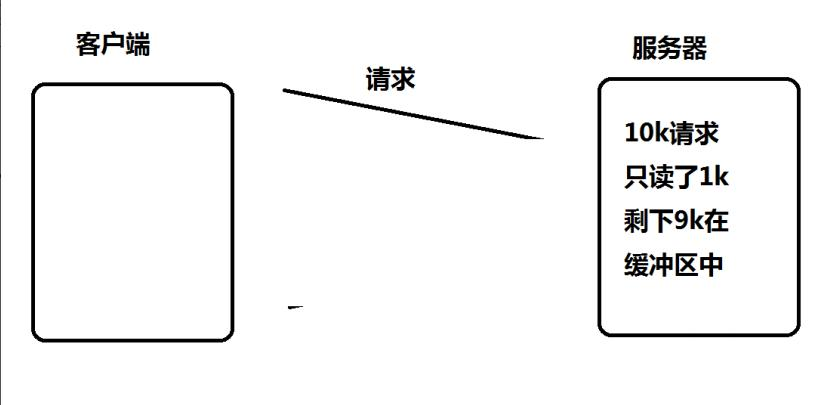
假设这样的场景: 服务器接收到一个 10k 的请求, 会向客户端返回一个应答数据. 如果客
户端收不到应答, 不会发送第二个 10k 请求.
如果服务端写的代码是阻塞式的 read, 并且一次只 read 1k 数据的话(read 不能保证一次就把所有的数据都读出来, 参考 man 手册的说明, 可能被信号打断), 剩下的 9k 数据就会待在缓冲区中。
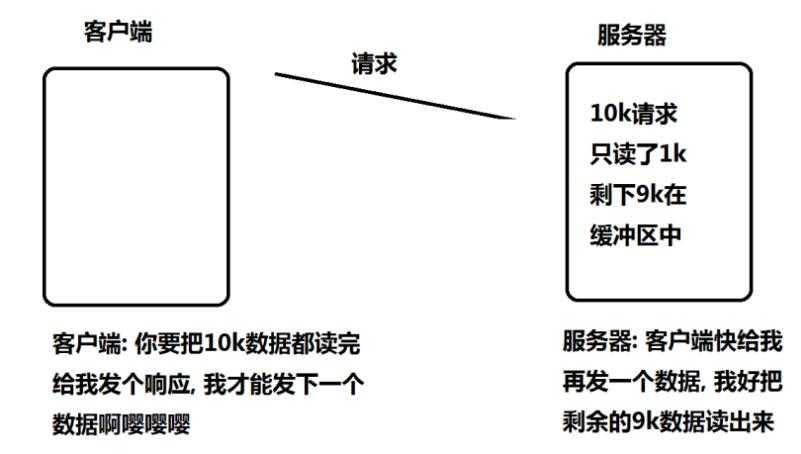
此时由于 epoll 是 ET 模式, 并不会认为文件描述符读就绪. epoll_wait 就不会再次返回. 剩下的 9k 数据会一直在缓冲区中. 直到下一次客户端再给服务器写数据.epoll_wait 才能返回。万一你服务器是单进程单线程的,那就更糟糕了,服务器由于在这里一直等客户端第二次回复(即使客户端触发丢包重传,服务器仍然一次只读1K数据,读不完),触发epoll_wait的第二次通知,但是此时我客户端不知道啊,他再也没有发送过消息。然后服务器就在这里卡死。
多线程同样也会因为这个而导致服务器挂掉,但是他是一个线程一个线程慢慢挂掉,而非单线程这般迅速。

所以, 为了解决上述问题(阻塞 read 不一定能一下把完整的请求读完), 于是就可以使用非阻塞轮训的方式来读缓冲区, 保证一定能把完整的请求都读出来。
总结一下:
(1)ET模式因为只会通知一次,所以需要来到一个通知的时候,就把数据读完。
(2)怎么读完呢?用户缓冲区可能没有数据报文大,所以需要循环读。
(3)循环读读完了呢?如果阻塞式read,读完了就卡在这里了,所以需要设置非阻塞,读到没有数据了不要阻塞,而是直接跳过他去做其他操作。
我们之前是不是写过一个将文件描述符设置为非阻塞的代码?
//对指定的fd设置非阻塞
void SetNonBlock(int fd) {
int fl = fcntl(fd, F_GETFL);
if (fl < 0) {
cerr << "fcntl error" << endl;
exit(1);
}
fcntl(fd, F_SETFL, fl | O_NONBLOCK);
}
如果你曾封装了socket类,你只需要在创建listensocket的时候调用一下这个函数,在每一次通过listensocket得到新连接的时候,把新连接也调用一下即可。反正就是只要创建一个新的socket,都要设置为非阻塞模式。
七、epoll的使用场景
epoll 的高性能, 是有一定的特定场景的. 如果场景选择的不适宜, epoll 的性能可能适得其反.
epoll是专为高并发、大规模连接设计的I/O多路复用机制,其核心优势在于:
- 事件驱动:通过回调机制避免无效轮询。
- 高效数据结构:红黑树和就绪队列实现O(1)复杂度。
- 扩展性:轻松处理百万级连接。
这些优势在连接数较少时(如几个到几十个),可能无法充分体现。
- 复杂性开销:
epoll需要维护红黑树和就绪队列,这些数据结构在连接数少时可能带来额外开销。- 相比简单的
select或poll,epoll的初始化和管理更复杂。- 性能差异小:
- 当连接数少时,
select或poll的线性遍历开销可能并不显著。epoll的事件驱动优势在低频事件场景中不明显。甚至连接数极小的时候,可以直接使用多线程多进程,效率反而更高。因为所有的多路转接都是为了在有大量客户端进行通信,而把等待时间重合的策略。
总结
在连接数较少的场景下,epoll的复杂性和开销可能超过其带来的性能优势。此时,选择更简单的I/O多路复用机制(如select)或直接使用多线程/多进程,可能是更合理的选择。