Python的迭代器(Iterator)介绍以及实现多次使用
在 Python 中,我们希望能够对迭代器(Iterator)多次使用。
一、问题描述
有一个数据文件,tourist_data.csv,数据结构如下:
| 日期 | 九寨沟 | 张家界 | 香港 | 东部华侨城 | 上海迪士尼 |
| 2017/1/1 | 30 | 17 | 17 | 3 | 28 |
| 2017/1/2 | 12 | 21 | 8 | 3 | 9 |
| 2017/1/3 | 14 | 22 | 15 | 1 | 32 |
| 2017/1/4 | 6 | 29 | 13 | 7 | 15 |
| 2017/1/5 | 31 | 15 | 5 | 3 | 10 |
| 2017/1/6 | 26 | 23 | 17 | 6 | 25 |
| 2017/1/7 | 9 | 18 | 12 | 7 | 28 |
| 2017/1/8 | 9 | 19 | 12 | 4 | 15 |
| 2017/1/9 | 22 | 24 | 11 | 10 | 14 |
| 2017/1/10 | 32 | 9 | 6 | 3 | 20 |
| 2017/1/11 | 10 | 19 | 16 | 3 | 26 |
| 2017/1/12 | 17 | 17 | 17 | 7 | 31 |
| 2017/1/13 | 21 | 25 | 12 | 10 | 6 |
| 2017/1/14 | 17 | 27 | 15 | 1 | 32 |
现在想统计每一个旅游景点的游客访问量,代码如下:
import csv
def getTotalTourist(place):
total = 0
for dayTourist in place:
total += dayTourist
return total
data_file = open('C:/Users/Admin/Desktop/chapter3/tourist_data.csv','r')
all_data = csv.reader(data_file)
jzg_data = [row[1] for row in all_data] #第二列
#print(jzg_data)
jzg_data_str = jzg_data[1:]
jzg_data = list( map(int, jzg_data_str) )
#print(jzg_data)
jzg_total = getTotalTourist(jzg_data)
print("这段时期到九寨沟旅游的总人数是:",jzg_total)
zjj_data = [row[2] for row in all_data] #第三列
#print(zjj_data)
zjj_data_str = zjj_data[1:]
zjj_data = list( map(int, zjj_data_str) )
#print(zjj_data)
zjj_total = getTotalTourist(zjj_data)
print("这段时期到张家界旅游的总人数是:",zjj_total)
dbhqc_data = [row[3] for row in all_data] #第四列
#print(dbhqc_data)
dbhqc_data_str = dbhqc_data[1:]
dbhqc_data = list( map(int, dbhqc_data_str) )
#print(dbhqc_data)
dbhqc_total = getTotalTourist(dbhqc_data)
print("这段时期到东部华侨城旅游的总人数是:",dbhqc_total)
shdisney_data = [row[4] for row in all_data] #第五列
#print(shdisney_data)
shdisney_data_str = shdisney_data[1:]
shdisney_data = list( map(int, shdisney_data_str) )
#print(shdisney_data)
shdisney_total = getTotalTourist(shdisney_data)
print("这段时期到上海迪士尼旅游的总人数是:",shdisney_total)
data_file.close()
如上代码,得到的结果如下:
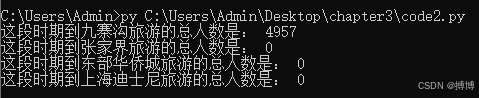
以上代码文件读取没有问题,但是只能输出第一个jzg_total,即九寨沟的旅游人数,其他几个旅游点输出都是0,这是什么问题呢?
二、问题所在
问题出在 csv.reader 的使用上。csv.reader 返回的是一个迭代器,一旦迭代器被遍历一次后,它会被耗尽,无法再次使用。因此,当你第一次从 all_data 中提取 jzg_data 时,all_data 已经被完全迭代,后续再尝试从 all_data 中提取其他列数据时,迭代器已经为空,导致 zjj_data、dbhqc_data 和 shdisney_data 都是空列表,进而导致它们的总数为 0。
三、解决方法
需要在第一次读取 all_data 时,将其存储为一个列表,这样就可以多次访问数据。以下是修改后的代码:
import csv
def getTotalTourist(place):
total = 0
for dayTourist in place:
total += dayTourist
return total
data_file = open('C:/Users/Admin/Desktop/chapter3/tourist_data.csv', 'r')
all_data = list(csv.reader(data_file)) # 将 csv.reader 的结果存储为列表
# 提取九寨沟的数据(第二列)
jzg_data = [int(row[1]) for row in all_data[1:]] # 直接转换为整数
jzg_total = getTotalTourist(jzg_data)
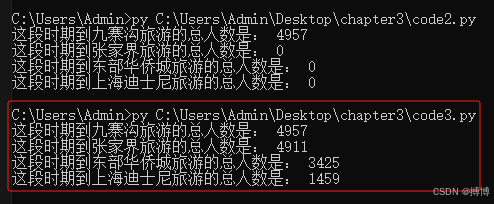
print("这段时期到九寨沟旅游的总人数是:", jzg_total)
# 提取张家界的数据(第三列)
zjj_data = [int(row[2]) for row in all_data[1:]] # 直接转换为整数
zjj_total = getTotalTourist(zjj_data)
print("这段时期到张家界旅游的总人数是:", zjj_total)
# 提取东部华侨城的数据(第四列)
dbhqc_data = [int(row[3]) for row in all_data[1:]] # 直接转换为整数
dbhqc_total = getTotalTourist(dbhqc_data)
print("这段时期到东部华侨城旅游的总人数是:", dbhqc_total)
# 提取上海迪士尼的数据(第五列)
shdisney_data = [int(row[4]) for row in all_data[1:]] # 直接转换为整数
shdisney_total = getTotalTourist(shdisney_data)
print("这段时期到上海迪士尼旅游的总人数是:", shdisney_total)
data_file.close()修改点说明
-
将
csv.reader的结果存储为列表:all_data = list(csv.reader(data_file))这样可以多次访问
all_data,而不会因为迭代器耗尽而无法读取数据。 -
直接在列表解析中转换为整数:
jzg_data = [int(row[1]) for row in all_data[1:]]这样可以避免额外的字符串到整数的转换步骤,代码更简洁。
-
跳过表头: 使用
all_data[1:]跳过表头行,确保只处理数据行。
通过这些修改,代码可以正确读取并处理所有列的数据,输出每个景区的总人数。
实现的效果
四、迭代器(Iterator)介绍
在 Python 中,迭代器(Iterator)是一种容器对象,它实现了迭代器协议(Iterator Protocol),允许用户通过循环或迭代的方式逐个访问容器中的元素,而无需暴露容器的底层实现细节。迭代器是 Python 中实现迭代功能的核心机制,广泛应用于各种数据结构和场景。
1. 迭代器协议
迭代器协议包括两个方法:
-
__iter__():返回迭代器对象本身。这个方法使得对象可以被用于for循环或其他需要迭代的场景。 -
__next__():返回迭代器的下一个元素。如果迭代器已经到达末尾,没有更多元素可供返回,则抛出StopIteration异常。
2. 创建迭代器
在 Python 中,可以通过以下几种方式创建迭代器:
2.1 使用内置的可迭代对象
许多内置数据类型(如列表、元组、字典、集合、字符串等)都支持迭代器协议,可以直接使用 iter() 函数将其转换为迭代器。例如:
my_list = [1, 2, 3, 4]
my_iterator = iter(my_list)
print(next(my_iterator)) # 输出 1
print(next(my_iterator)) # 输出 2
print(next(my_iterator)) # 输出 3
print(next(my_iterator)) # 输出 4
# print(next(my_iterator)) # 抛出 StopIteration 异常2.2 自定义迭代器
可以通过定义一个类并实现 __iter__() 和 __next__() 方法来创建自定义迭代器。例如:
class MyIterator:
def __init__(self, max_value):
self.max_value = max_value
self.current = 0
def __iter__(self):
return self
def __next__(self):
if self.current < self.max_value:
value = self.current
self.current += 1
return value
else:
raise StopIteration
# 使用自定义迭代器
my_iterator = MyIterator(5)
for value in my_iterator:
print(value) # 输出 0, 1, 2, 3, 42.3 使用生成器
生成器是一种特殊的迭代器,通过 yield 关键字实现。生成器函数在每次调用时会返回一个值,并在下次调用时从上次返回的位置继续执行。生成器是实现迭代器的简洁方式。例如:
def my_generator(max_value):
current = 0
while current < max_value:
yield current
current += 1
# 使用生成器
for value in my_generator(5):
print(value) # 输出 0, 1, 2, 3, 43. 迭代器的特点
-
惰性计算:迭代器不会一次性加载所有数据,而是按需生成数据,节省内存。
-
一次性使用:迭代器在被完全迭代后,会耗尽,无法再次使用。如果需要重新迭代,需要重新创建迭代器。
-
支持无限序列:生成器可以用于生成无限序列,因为它们不需要预先存储所有数据。例如:
def infinite_generator(): current = 0 while True: yield current current += 1 # 使用无限生成器(需要小心避免无限循环) gen = infinite_generator() for _ in range(10): print(next(gen)) # 输出 0, 1, 2, ..., 9
4. 迭代器的应用场景
-
循环遍历:
for循环会自动调用iter()和next()方法来迭代对象。 -
函数式编程:许多函数式编程工具(如
map()、filter()、zip()等)返回迭代器,便于高效处理数据。 -
文件读取:文件对象本身是一个迭代器,可以逐行读取文件内容,节省内存。
with open('file.txt', 'r') as file: for line in file: print(line.strip())
5. 迭代器与可迭代对象的区别
-
可迭代对象(Iterable):实现了
__iter__()方法或__getitem__()方法的对象,可以通过iter()转换为迭代器。例如:列表、元组、字典、集合、字符串等。 -
迭代器(Iterator):实现了
__iter__()和__next__()方法的对象,可以直接用于迭代。
6. 总结
迭代器是 Python 中实现迭代功能的核心机制,具有惰性计算、节省内存、支持无限序列等特点。通过内置的可迭代对象、自定义迭代器或生成器,可以灵活地实现各种迭代需求。理解迭代器的原理和使用方法,可以帮助你更高效地处理数据和编写代码。