基于word2vec 和 fast-pytorch-kmeans 的文本聚类实现,利用GPU加速提高聚类速度
文章目录
- 简介
- GPU加速
- 代码实现
- kmeans
- 聚类结果
- kmeans 绘图函数
- 相关资料参考
简介
本文使用text2vec模型,把文本转成向量。使用text2vec提供的训练好的模型权重进行文本编码,不重新训练word2vec模型。
直接用训练好的模型权重,方便又快捷
完整可运行代码如下:
https://github.com/JieShenAI/csdn/blob/main/machine_learning/kmeans_pytorch.ipynb
GPU加速
传统sklearn的TF-IDF文本转向量,在CPU上计算速度较慢。使用text2vec通过cuda加速,加快文本转向量的速度。
传统使用sklearn的kmeans聚类算法在CPU上计算,如遇到大批量的数据,计算耗时太长。
故本文使用fast-pytorch-kmeans 和 kmeans_pytorch包,基于pytorch在GPU上计算,提高聚类速度。
代码实现
装包
pip install fast-pytorch-kmeans text2vec
import torch
import numpy as np
from text2vec import SentenceModel
不使用SentenceModel模型也可以,在 text2vec 中,还有很多其他的向量编码模型供选择。
文本编码模型
embedder = SentenceModel()
异常情况说明,该模型需要从huggingface下载模型权重,目前被墙了。(请想办法解决,或者尝试其他的编码模型)
语料库如下:
# Corpus with example sentences
corpus = [
'花呗更改绑定银行卡',
'我什么时候开通了花呗',
'A man is eating food.',
'A man is eating a piece of bread.',
'The girl is carrying a baby.',
'A man is riding a horse.',
'A woman is playing violin.',
'Two men pushed carts through the woods.',
'A man is riding a white horse on an enclosed ground.',
]
corpus_embeddings = embedder.encode(corpus)
# numpy 转成 pytorch, 并转移到GPU显存中
corpus_embeddings = torch.from_numpy(corpus_embeddings).to('cuda')
如下图所示,编码的向量是768维;
type(corpus_embeddings), corpus_embeddings.shape

kmeans
kmeans_pytorch vs fast-pytorch-kmeans:
在实验过程中,利用kmeans_pytorch 针对30万个词进行聚类的时候,发现显存炸了,程序崩溃退出。30万个词的词向量,占用显存还不到2G,但是运行kmeans_pytorch后,显存就炸了。
fast-pytorch-kmeans不存在上述显存崩溃的问题。本以为词向量很多会跑很长时间,但fast-pytorch-kmeans在非常短的时间内就完成了kmeans聚类。
后来一想也理解了,先开始在CPU跑花费了很长时间,这是因为CPU并行很差,需要逐个跑完。而在GPU里大量数据拼成一个矩阵,做一个减法,就可以算出批量节点和中心点的距离。
# kmeans
# from kmeans_pytorch import kmeans
from fast_pytorch_kmeans import KMeans
num_class = 3 # 分类类别数
kmeans = KMeans(n_clusters=num_class, mode='euclidean', verbose=1)
# 模型预测结果
labels = kmeans.fit_predict(corpus_embeddings)
聚类程序运行如下:
used 2 iterations (0.3682s) to cluster 9 items into 3 clusters
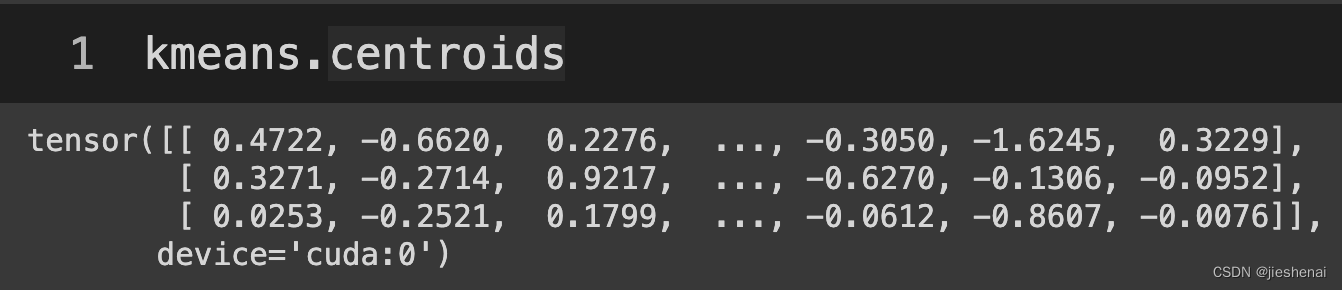
模型中心点坐标:
kmeans.centroids
聚类结果
class_data = {
i:[]
for i in range(3)
}
for text,cls in zip(corpus, labels):
class_data[cls.item()].append(text)
class_data
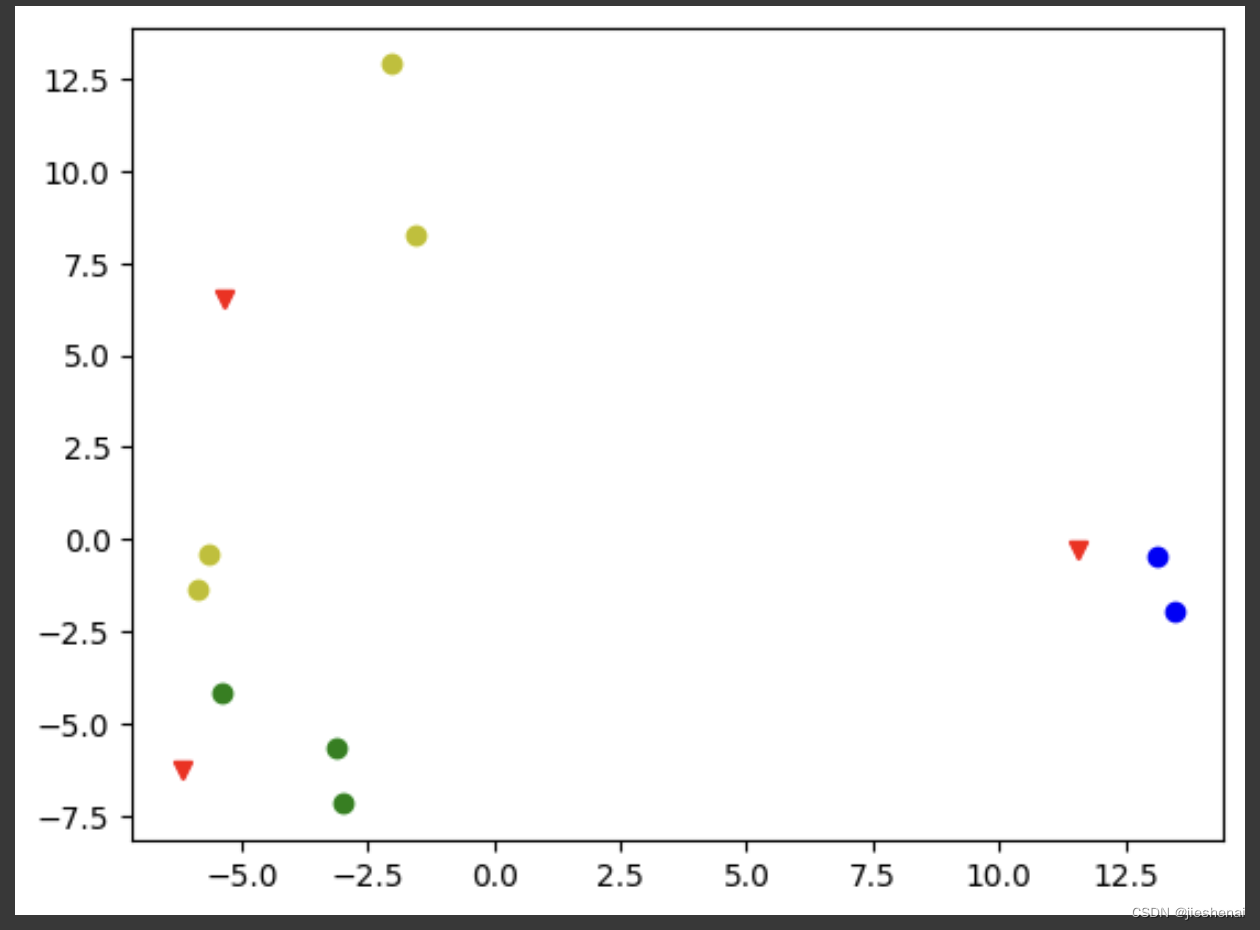
文本聚类结果如下:
0: 女
1:男
2: 花呗

kmeans 绘图函数
封装了KMeansPlot 绘图类,方便聚类结果可视化
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
class KMeansPlot:
def __init__(self, numClass=4, func_type='PCA'):
if func_type == 'PCA':
self.func_plot = PCA(n_components=2)
elif func_type == 'TSNE':
from sklearn.manifold import TSNE
self.func_plot = TSNE(2)
self.numClass = numClass
def plot_cluster(self, result, pos, cluster_centers=None):
plt.figure(2)
Lab = [[] for i in range(self.numClass)]
index = 0
for labi in result:
Lab[labi].append(index)
index += 1
color = ['oy', 'ob', 'og', 'cs', 'ms', 'bs', 'ks', 'ys', 'yv', 'mv', 'bv', 'kv', 'gv', 'y^', 'm^', 'b^', 'k^',
'g^'] * 3
for i in range(self.numClass):
x1 = []
y1 = []
for ind1 in pos[Lab[i]]:
# print ind1
try:
y1.append(ind1[1])
x1.append(ind1[0])
except:
pass
plt.plot(x1, y1, color[i])
if cluster_centers is not None:
#绘制初始中心点
x1 = []
y1 = []
for ind1 in cluster_centers:
try:
y1.append(ind1[1])
x1.append(ind1[0])
except:
pass
plt.plot(x1, y1, "rv") #绘制中心
plt.show()
def plot(self, weight, label, cluster_centers=None):
pos = self.func_plot.fit_transform(weight)
# 高维的中心点坐标,也经过降维处理
cluster_centers = self.func_plot.fit_transform(cluster_centers)
self.plot_cluster(list(label), pos, cluster_centers)
kmeans.centroids :是一个高维空间的中心点坐标,故在plot函数中,将其降维到2D平面上;
k_plot = KMeansPlot(num_class)
k_plot.plot(
corpus_embeddings.to('cpu'),
labels.to('cpu'),
kmeans.centroids.to('cpu')
)
完整可运行代码如下:
https://github.com/JieShenAI/csdn/blob/main/machine_learning/kmeans_pytorch.ipynb
相关资料参考
- 动手实战基于 ML 的中文短文本聚类
- tfidf和word2vec构建文本词向量并做文本聚类
提到训练word2vec模型,silhouette_score_show(word2vec, 'word2vec')轮廓系数,判断分几个类别最好。 - 机器学习:Kmeans聚类算法总结及GPU配置加速demo
PyTorch kmeans 加速。from scratch 实现; - KMeans算法全面解析与应用案例 通俗易懂的原理讲解
- pytorch K-means算法的实现 底层代码实现
- 【pytorch】Kmeans_pytorch用于一般聚类任务的代码模板 使用pytorch封装的kmeans包实现,包括训练和预测;
- text2vec 包