三个表联合查询的场景分析-场景1:a表关联了b表和c表
本场景对应情景如下:
三个数据表,一个表的两个字段分别关联了另外两个表各自的id数据,可能包含多个id(两个1对多关联)。
目录
数据表准备
需求1、查询c表的列表数据,要求获得关联的b表中的name(多个)
需求2、在需求1基础上,同时查询关联的a表的name(多个)
需求3、在需求2基础上,增加整体聚合结果按“创建时间”排序、分页
数据表准备
共三张表,a、b、c,c表中关联了a和b的id
demo_bs表

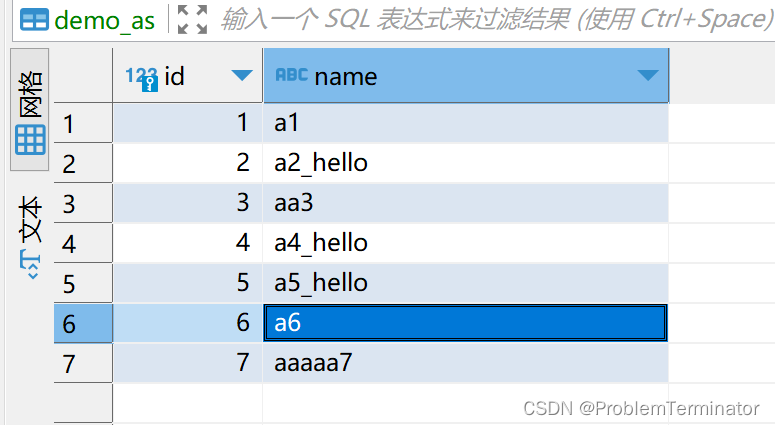
demo_as表
demo_cs表
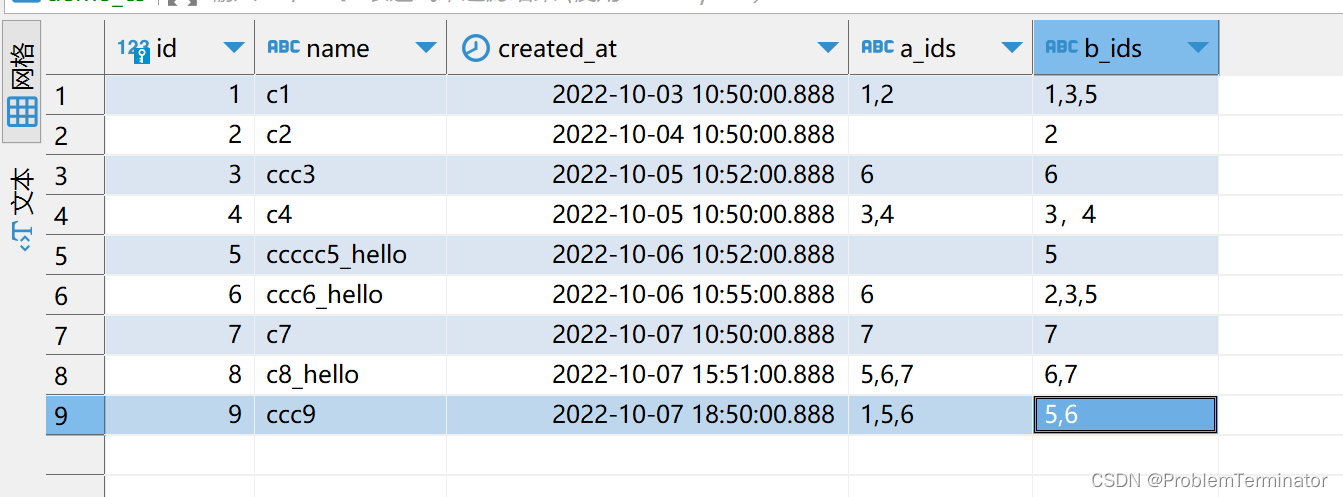
a_ids:关联的a表的id列表,使用英文逗号分隔;可不关联a,不关联时为空字符串;
b_ids:关联的b表的id列表,使用英文逗号分隔;必定关联了b中的某些id,至少关联了1个;
需求1、查询c表的列表数据,要求获得关联的b表中的name(多个)
select c.id AS id,c.name AS name,c.created_at AS createdAt,
c.b_ids as bIDs, c.a_ids as aIDs, group_concat(b.name SEPARATOR ',') as bNames
from demo_cs c
left join demo_bs b
on FIND_IN_SET(b.id, c.b_ids) > 0
where c.name like '%c%'
group by c.id查询结果
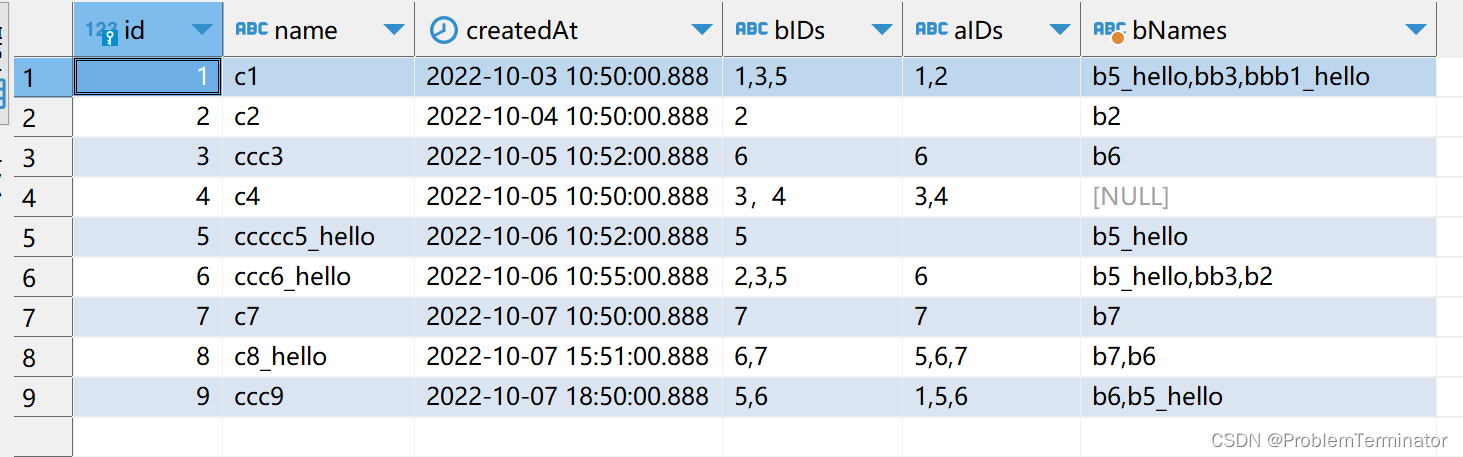
其中where c.name like '%c%'为c表本表的name字段查询条件。
FIND_IN_SET(b.id, c.b_ids) > 0表示检查b.id值在c.b_ids中的索引(且后者是以逗号拼接的字符串),索引从1开始,因此判断结果只要>0则表示前者在后者中存在。
group_concat(b.name SEPARATOR ',')表示将b表的name字段以逗号拼接作为新的一列,那么是b表的哪些name呢?即符合on FIND_IN_SET(b.id, c.b_ids) > 0 条件的记录的name。
需求2、在需求1基础上,同时查询关联的a表的name(多个)
select r.id,r.name,r.createdAt,r.bIDs as bIDs,r.bNames as bNames,r.aIDs as aIDs,group_concat(a.name SEPARATOR ',') as aNames
from(
select c.id AS id,c.name AS name,c.created_at AS createdAt,
c.b_ids as bIDs, c.a_ids as aIDs, group_concat(b.name SEPARATOR ',') as bNames
from demo_cs c
left join demo_bs b
on FIND_IN_SET(b.id, c.b_ids) > 0
where c.name like '%c%'
group by c.id
) r
left join demo_as a
on FIND_IN_SET(a.id, r.aIDs) > 0
where r.bNames like '%b%'
group by r.id查询结果
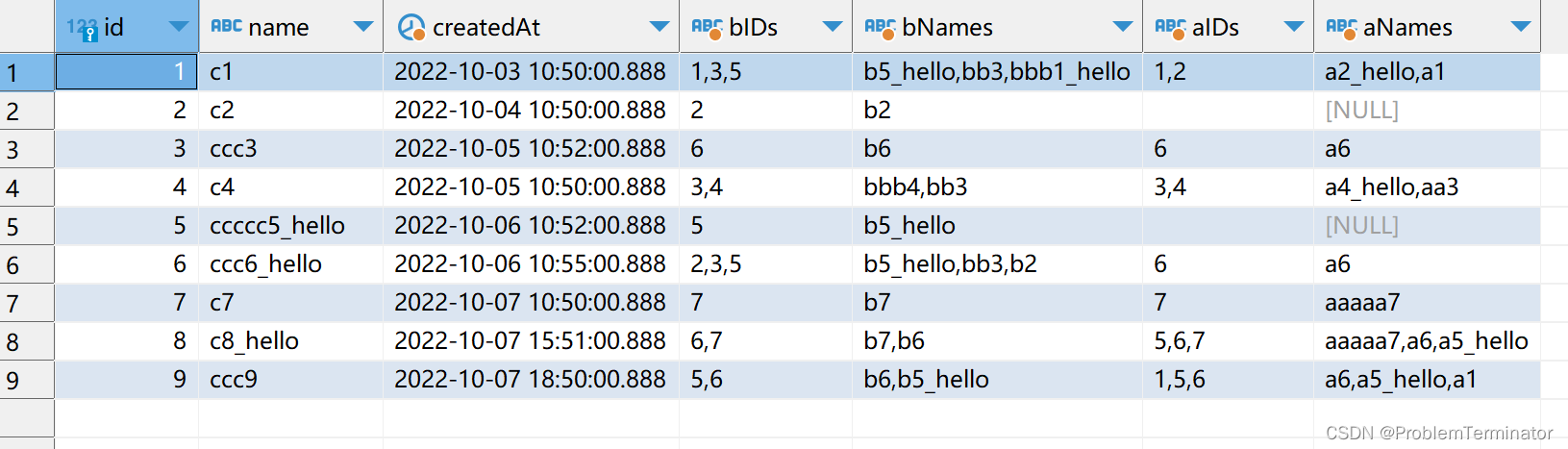
其中where r.bNames like '%b%'为聚合后数据的b的名称列表的查询条件。此时用于在内部查询基础上如
b5_hello,bb3,b2中(即bNames)判断是否包含b。如果将此条件放在子查询内部:如
where b.name like '%b%'会导致数据不准确,b.name like查询的是仅b表的name字段的模糊查询,可能会导致子查询查出的数据量减少,注意查询条件的定位,不同位置含义不同。
因为查询的主表是c表,因此from内部的子查询为数据基本盘,from内部的子查询的数据准确则整体数据准确。
需求3、在需求2基础上,增加整体聚合结果按“创建时间”排序、分页
select r.id,r.name,r.createdAt,r.bIDs as bIDs,r.bNames as bNames,r.aIDs as aIDs,group_concat(a.name SEPARATOR ',') as aNames
from(
select c.id AS id,c.name AS name,c.created_at AS createdAt,
c.b_ids as bIDs, c.a_ids as aIDs, group_concat(b.name SEPARATOR ',') as bNames
from demo_cs c
left join demo_bs b
on FIND_IN_SET(b.id, c.b_ids) > 0
where c.name like '%c%'
group by c.id
) r
left join demo_as a
on FIND_IN_SET(a.id, r.aIDs) > 0
where r.bNames like '%b%'
group by r.id
order by r.createdAt desc
limit 10 offset 0查询结果
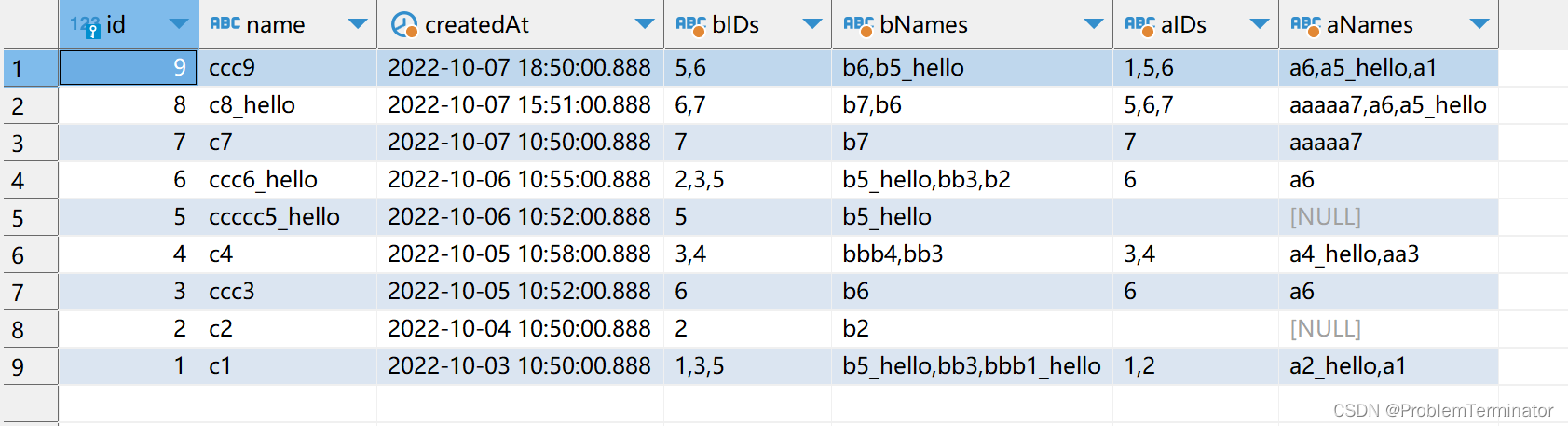
注意,外层的on FIND_IN_SET(a.id, r.aIDs) > 0 条件是作用在a表和查询出来的r结果之上,因此aIDs即使为空字符串,也不会导致最终结果的数量减少,而是对应的aNames查出来为空而已(aIDs没有id,对应的aNames为空正常)。
如果需要第二页,则将最后面的limit 10 offset 0 换为 limit 10 offset 10即可。