RocketMQ 4.x、5.x 性能对比
1.背景
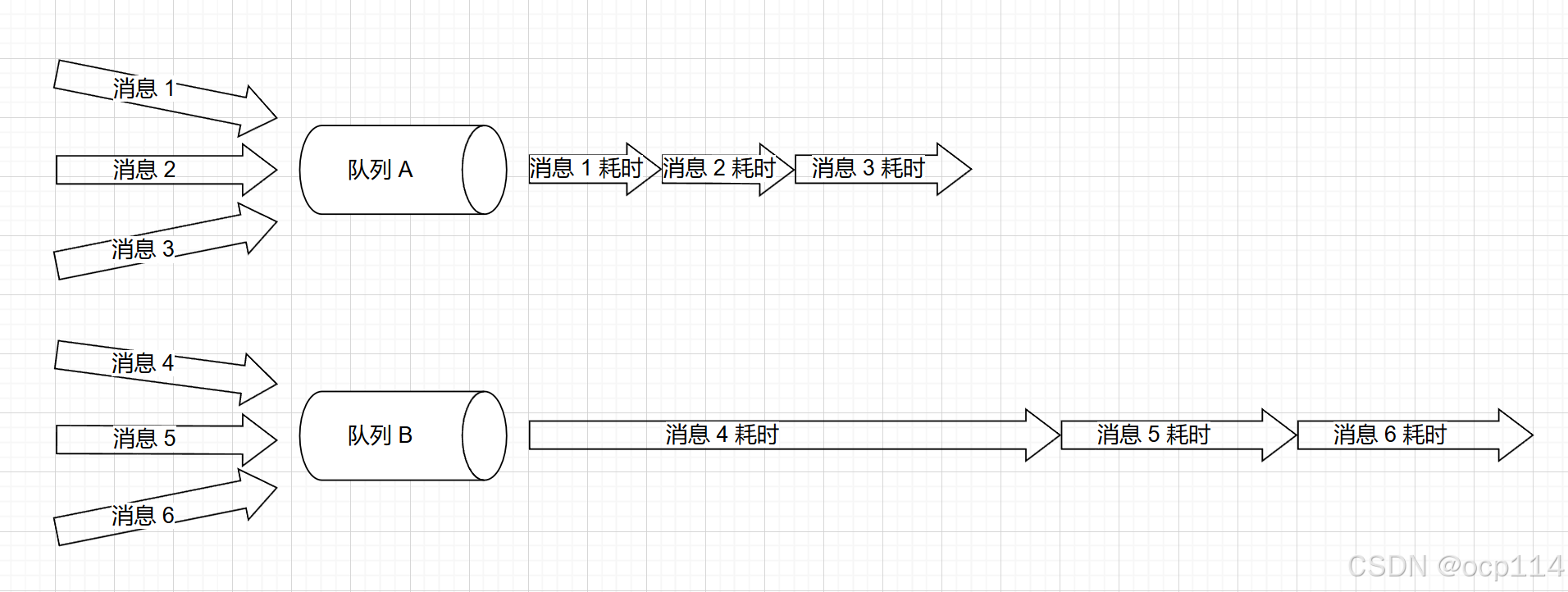
目前我们生产环境使用的是 RocketMQ 4.7.1 版本,刚好最近遇到了一个消费阻塞的问题,如下图所示,假如 MQ 只有 2 个队列 A、B,当提交消息 1~6 时,按照 MQ 的默认分配策略,消息会被平均分配到两个队列中,而处理结果可能会出现下图这样,消息 4 的处理耗时非常长,队列 A 中三个消息都被处理完了,队列 B 中的批次 5、6 还在等待处理;针对这个问题, Rocket MQ 5 的 pop 消费模式看上去是很好地解决了这个问题;再且没有找到官方的性能对比报告,于是这里针对 RockMQ 4 和 5 做个性能测试对比;
2.POP 消费模式验证
具体步骤这里不详细描述,结果从下图日志可以看到 queue-0 一直都被 blockConsumer 消费,但是到了下方箭头部分 queue-0 的数据也能够被 normal 消费到了,说明 pop 模式起作用了,初步观察是 queue-0 有消息积压时才会被其他消费者消费到该队列的数据。

3.性能测试前磁盘 IO 测试
以下三份表格分别对四台机器做了不同场景的磁盘 IO 压测得到的吞吐量,根据 RocketMQ 的读写特性,写数据时属于顺序写,读属于随机读,如果只是简单根据下面的报告来看,那么 RocketMQ 的消息消费性能远远小于生产性能,而由于 RocketMQ 使用了 mmap 机制把磁盘文件和内存做映射,以及利用了磁盘的 page cache,大部分时候消息在内存中就已经被转发给了消费者,少量的会从磁盘 page cache 查出来转发给消费者,只有在生产速度大于消费速度时,数据被持久化到磁盘并且 page cache 已经被清除的情况下,RocketMQ 的消费性能才会出现明显下降。
| 机器 | CPU | 内存 | 顺序读 | 顺序写 | 随机读 | 随机写 | 混合随机读写,70%读 30%写 | |
|---|---|---|---|---|---|---|---|---|
| A | 16核2000MHz | 64G 2500 MHz | 673MB/s | 174MB/s | 12.1MB/s | 13.8MB/s | 读:7.9MB/s | 写:3.4MB/s |
| B | 16核2600MHz | 16G 2600 MHz | 955MB/s | 238MB/s | 38.6MB/s | 19.9MB/s | 读:20.1MB/s | 写:8.6MB/s |
| C | 8核2500MHz | 16G 2000 MHz | 1201MB/s | 456MB/s | 50.8MB/s | 14.0MB/s | 读:22.3MB/s | 写:9.6MB/s |
| D | 32核2600MHz | 32G 2600 MHz | 1099.4MB/s | 254.3MB/s | 33.5MB/s | 16.0MB/s | 读:18.0MB/s | 写:7.7MB/s |
| 测试工具 fio,文件大小30G,线程16,数据块16k,测试时长100秒,同步 IO,不经过文件系统 | ||||||||
| 机器 | CPU | 内存 | 顺序读 | 顺序写 | 随机读 | 随机写 | 混合随机读写,70%读 30%写 | |
|---|---|---|---|---|---|---|---|---|
| A | 16核2000MHz | 64G 2500 MHz | 71.9MB/s | 12.1MB/s | 1.2MB/s | 1MB/s | 读:0.65MB/s | 写:0.28MB/s |
| B | 16核2600MHz | 16G 2600 MHz | 88.9MB/s | 15.2MB/s | 2.6MB/s | 1.2MB/s | 读:1.18MB/s | 写:0.51MB/s |
| C | 8核2500MHz | 16G 2000 MHz | 54.2MB/s | 5.8MB/s | 3.3MB/s | 1.2MB/s | 读:0.41MB/s | 写:0.18MB/s |
| D | 32核2600MHz | 32G 2600 MHz | 84.7MB/s | 17.7MB/s | 2.1MB/s | 1.1MB/s | 读:1.16MB/s | 写:0.50MB/s |
| 测试工具 fio,文件大小30G,线程16,数据块1k,测试时长100秒,同步 IO,不经过文件系统 | ||||||||
| 机器 | CPU | 内存 | 顺序读 | 顺序写 | 随机读 | 随机写 | 混合随机读写,70%读 30%写 | |
|---|---|---|---|---|---|---|---|---|
| A | 16核2000MHz | 64G 2500 MHz | 79.7MB/s | 12.1MB/s | 1.5MB/s | 0.9MB/s | 读:0.79MB/s | 写:0.34MB/s |
| B | 16核2600MHz | 16G 2600 MHz | 120MB/s | 15.9MB/s | 4.6MB/s | 1.1MB/s | 读:1.41MB/s | 写:0.60MB/s |
| C | 8核2500MHz | 16G 2000 MHz | 60.9MB/s | 5.8MB/s | 18.3MB/s | 1.2MB/s | 读:0.41MB/s | 写:0.18MB/s |
| D | 32核2600MHz | 32G 2600 MHz | 83.8MB/s | 18MB/s | 3.9MB/s | 0.9MB/s | 读:1.40MB/s | 写:0.56MB/s |
| 测试工具 fio,文件大小30G,线程64,数据块1k,测试时长100秒,同步 IO,不经过文件系统 | ||||||||
4.测试场景及结果
注意事项:该压测在于对 RocketMQ 4 和 5 在同样场景同样配置下的性能差异,而非性能摸高;
关键配置:这里保持和生产环境的 MQ 配置一致;
# 限制的消息大小 改为128M
maxMessageSize=134217728
# 发送消息的最大线程数
sendMessageThreadPoolNums=32
# 发送消息是否使用可重入锁
useReentrantLockWhenPutMessage=true
# 一次拉取允许的最大条数,默认是32
maxTransferCountOnMessageInMemory=2048
# 一次HA主从同步传输的最大字节长度,默认为32K
haTransferBatchSize=134217728
useEpollNativeSelector=true
flushCommitLogLeastPages=4
flushConsumeQueueLeastPages=2
flushCommitLogThoroughInterval=10000
flushConsumeQueueThoroughInterval=60000
maxTransferCountOnMessageInMemory=1000
transientStorePoolEnable=false
warmMapedFileEnable=false
pullMessageThreadPoolNums=128
transferMsgByHeap=true
mapedFileSizeConsumeQueue=50000000
测试工具:RocketMQ 官方自带 benchmark;
测试版本:RocketMQ 4.7.1、RocketMQ 5.3.0
机器用途:B 为主节点,A 为从节点以及 NameServer 节点,C 为生产者,D 为消费者;
指标解释
- B2C:born2Consumer,表示从这个消息出生到消费间隔的时间;
- S2C:store2Consumer,表示从这个消息保存在broker到消费的时间间隔;
压测命令
- producer:sh producer.sh -t topic_benchmark_test -w <线程数> -s <消息大小> -n NameServer:9876
- consumer:sh consumer.sh -t topic_benchmark_test -n NameServer:9876 -g group_benchmark_test
部署模式:1 主 1 从、8G 内存、存算一体、同步刷盘、异步写从
| 测试场景 | 版本 | 失败数 | 发送最大 TPS | 最大 RT(发送) | 平均 RT(发送) | 平均 RT(B2C) | 平均 RT(S2C) | 最大 RT(B2C) | 最大 RT(S2C) |
| 60 线程 1K 消息 16 队列 | 4 | 0 | 23379 | 336 | 2.565 | 4.555 | 3.527 | 72 | 71 |
| 5 | 0 | 20389 | 683 | 2.941 | 4.372 | 3.600 | 56 | 54 | |
| 60 线程 2K 消息 16 队列 | 4 | 0 | 17722 | 470 | 3.384 | 4.862 | 3.436 | 32 | 31 |
| 5 | 0 | 17508 | 361 | 3.425 | 6.270 | 5.094 | 51 | 50 | |
| 80 线程 1K 消息 16 队列 | 4 | 0 | 22963 | 637 | 3.482 | 3.899 | 2.206 | 128 | 127 |
| 5 | 0 | 22375 | 801 | 3.575 | 4.855 | 3.590 | 43 | 41 | |
| 80 线程 2K 消息 16 队列 | 4 | 0 | 19014 | 396 | 4.206 | 5.025 | 2.976 | 96 | 89 |
| 5 | 0 | 19027 | 719 | 4.203 | 5.465 | 3.797 | 31 | 29 | |
| 120 线程 1K 消息 16 队列 | 4 | 0 | 26878 | 941 | 4.462 | 4.691 | 2.425 | 32 | 29 |
| 5 | 0 | 25545 | 492 | 4.695 | 6.516 | 4.655 | 39 | 37 | |
| 120 线程 2K 消息 16 队列 | 4 | 0 | 20663 | 692 | 5.806 | 22.516 | 19.358 | 199 | 197 |
| 5 | 0 | 21797 | 1020 | 5.504 | 25.931 | 23.634 | 134 | 131 | |
| 120 线程 100K 消息 16 队列 | 4 | 0 | 5076 | 710 | 23.640 | 66.480 | 44.567 | 433 | 411 |
| 5 | 0 | 7039 | 1443 | 17.050 | 27683.212 | 27665.113 | 29849 | 29833 |
部署模式:1 主 1 从、8G 内存、存算一体、异步刷盘、同步写从
| 测试场景 | 版本 | 失败数 | 发送最大 TPS | 最大 RT(发送) | 平均 RT(发送) | 平均 RT(B2C) | 平均 RT(S2C) | 最大 RT(B2C) | 最大 RT(S2C) |
| 60 线程 1K 消息 16 队列 | 4 | 0 | 23013 | 708 | 2.606 | 4.232 | 2.349 | 34 | 32 |
| 5 | 0 | 22496 | 533 | 2.666 | 3.921 | 3.136 | 33 | 31 | |
| 60 线程 2K 消息 16 队列 | 4 | 0 | 19712 | 754 | 3.042 | 147.402 | 145.381 | 329 | 327 |
| 5 | 0 | 18309 | 361 | 3.275 | 5.110 | 4.228 | 44 | 36 | |
| 80 线程 1K 消息 16 队列 | 4 | 0 | 24767 | 395 | 3.229 | 5.107 | 2.751 | 128 | 126 |
| 5 | 0 | 25166 | 492 | 3.182 | 4.317 | 3.243 | 35 | 34 | |
| 80 线程 2K 消息 16 队列 | 4 | 0 | 22628 | 373 | 3.534 | 1077.760 | 1075.040 | 1279 | 1277 |
| 5 | 0 | 21656 | 876 | 3.693 | 11.420 | 10.126 | 79 | 78 | |
| 120 线程 1K 消息 16 队列 | 4 | 0 | 28613 | 687 | 4.192 | 8.392 | 5.622 | 59 | 57 |
| 5 | 0 | 34602 | 847 | 3.467 | 6.738 | 5.507 | 42 | 41 | |
| 120 线程 2K 消息 16 队列 | 4 | 0 | 23563 | 1131 | 5.091 | 21670.387 | 21666.443 | 22220 | 22217 |
| 5 | 0 | 21467 | 904 | 5.588 | 217.787 | 215.584 | 637 | 635 | |
| 120 线程 100K 消息 16 队列 | 4 | 0 | 5942 | 776 | 20.187 | 41077.356 | 41055.976 | 41804 | 41786 |
| 5 | 0 | 6546 | 847 | 19.131 | 18479.365 | 18461.694 | 18811 | 18793 |
5.总结
- 总体上看性能差不多,但是对于消息体不大的我们常用的场景 RocketMQ 4 比 5 要好一丢丢;
- RocketMQ 5 在需要主从同步的场景稳定性会比 4 更好;
- 对于其他性能相关的参数配置暂未调整,可能会有不一样的表现但应该差距不会大;
- 存算分离模式因为从架构上看多了一层网络交互,所以从理论上性能会比主从模式更低,但是在大规模集群情况下会有明显的性能优势,我们系统暂时用不到所以这里没有测试;
- Dledger 模式和 Controller 模式属于高可用部署模式,也不在这探索;