数据结构十四、哈希表
一、哈希表的概念
哈希表(hash table),又称散列表,是根据关键字直接进行访问的数据结构。哈希表建立了一种关键字和存储地址之间的直接映射关系,使得每一个关键字与结构中的唯一存储位置相对应。

将关键字映射成对应地址的函数就是哈希函数,也称散列函数,记作Hash(key)= Addr。 哈希函数可能会把两个或两个以上的不同关键字映射到同一地址,这种情况称为哈希冲突,也叫散列冲突。起冲突的不同关键字,称它们为同义词。

由此可见, 设计一个优秀的哈希表,不仅需要设计一个好的哈希函数,也要能够处理哈希冲突。
二、哈希函数
1、直接定址法
第一个案例中,统计字符串小写字符出现的次数所用的方法就是直接定址法。直接取关键字的某个线性函数值为散列地址,散列函数是hash(key)=a×key+b,其中a和b是常数。这种方式计算比较简单,适合关键字连续分部的情况。但是如果关键字分布不连续,空位较多,则会造成存储空间的浪费。
2、除留余数法
第二个案例所用的函数的方法就是除留余数法。假设哈希表的大小为M,那么通过key除以M的余数作为映射位置的下标,hash(key) = key % M。因此,这种方法的重点就是选好模数M。(一般M取不太接近2的整数次幂的一个质数)但是要注意,key有可能是负数,取模之后会变成负数,负数补正的操作只需要加上模数即可,但是正数加上模数会变大,所以统一再取一次模。最终就是(key % M + M)% M。
三、处理哈希冲突
1、线性探测法
从发生冲突的位置开始,依次向后探测,直到寻找到下一个没有存储数据的位置为止,如果走到哈希表尾,则回到哈希表头的位置。

#include <iostream>
#include <cstring>
using namespace std;
const int N = 23, INF = 0x3f3f3f3f;
int h[N];
void init()
{
memset(h, 0x3f, sizeof h);
}
int f(int x)
{
int id = (x % N + N) % N;
while (h[id] != INF && h[id] != x)
{
id++;
if (id == N)
id = 0;
}
return id;
}
void insert(int x)
{
int idx = f(x);
h[idx] = x;
}
bool find(int x)
{
int id = f(x);
return h[id] == x;
}2、链地址法
链地址法中所有的数据不再直接存储在哈希表中,哈希表中存储一个指针,没有数据映射这个位置时,这个指针为空,有多个数据映射到这个位置时,我们把这些冲突的数据连接成一个链表,挂在哈希表这个位置下面。实现方式与树的链式前向星一模一样。
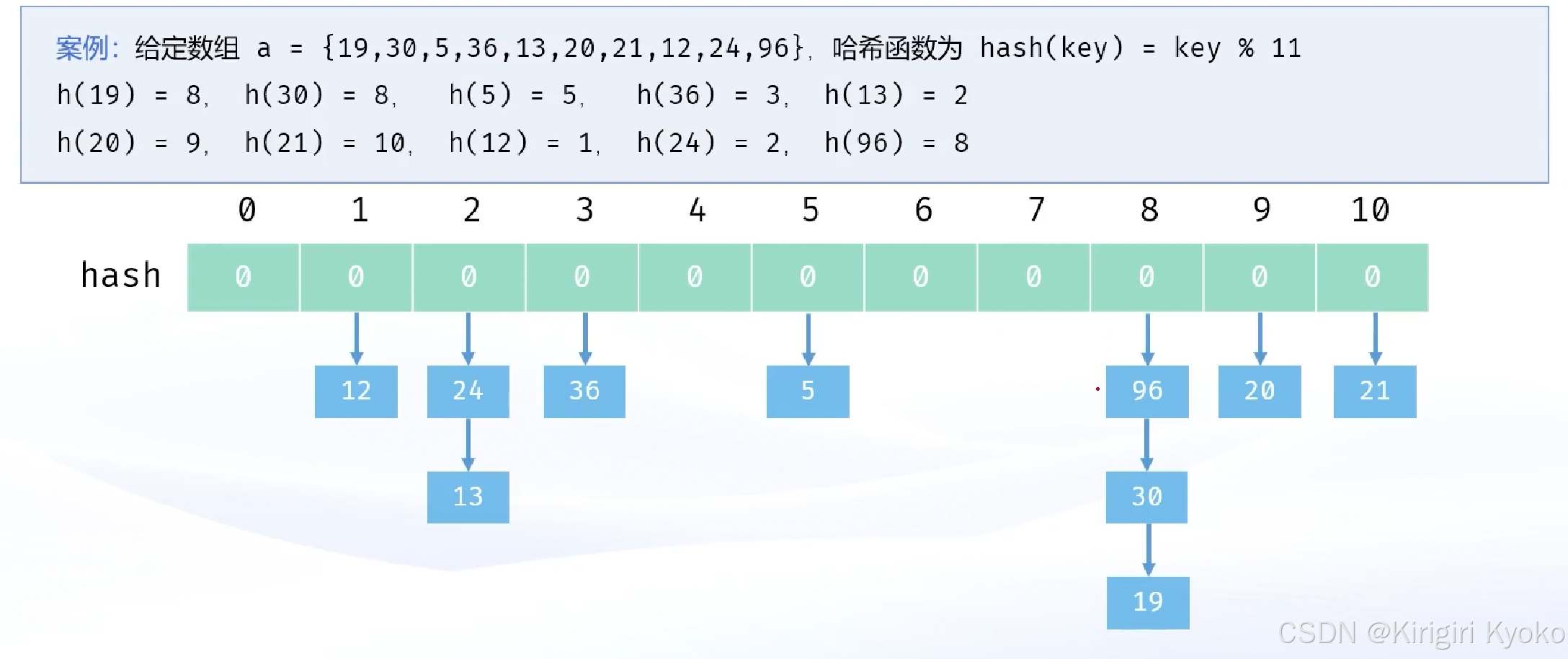
#include <iostream>
using namespace std;
const int N = 23;
int h[N];
int e[N], ne[N];
int id;
int f(int x)
{
return (x % N + N) % N;
}
void insert(int x)
{
int idx = f(x);
//把x头插到idx所在的链表中
id++;
e[id] = x;
ne[id] = h[idx];
h[idx] = id;
}
bool find(int x)
{
int idx = f(x);
for (int i = h[idx];i;i = ne[i])
{
if (e[i] == x)
return true;
}
return false;
}四、unordered_set & unordered_map
C++中的STL为我们提供了两种哈希表——unordered_set 和 unordered_map。set和unordered_set的区别就是,前者是用红黑树实现的,后者是用哈希表实现的。前者是有序的,后者是无序的。使用方式和上一章的set和map是完全一样的,这里就不做代码实现了。