生物信息复习笔记(2)——测序基本概念
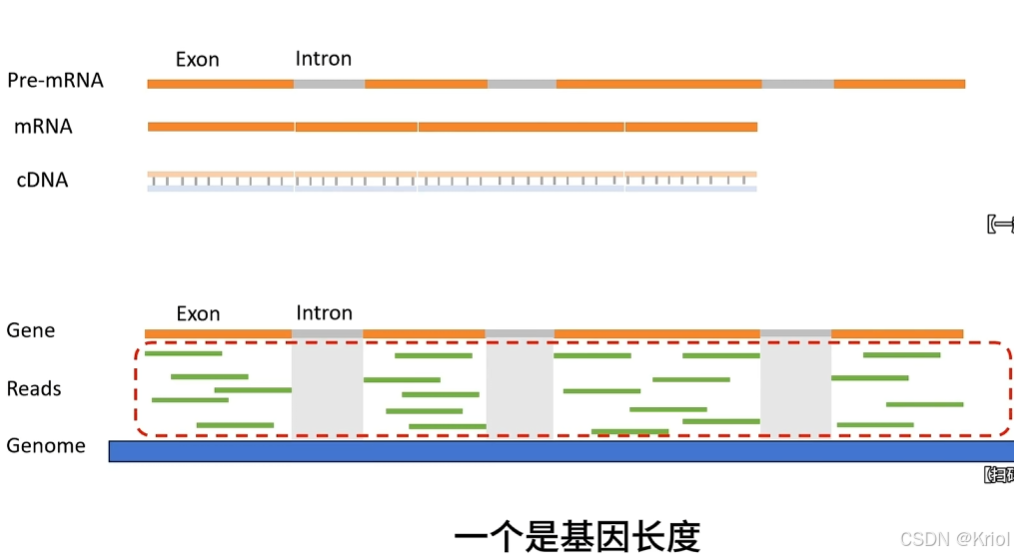
Intron:内含子,不参与编码。
Exon:外显子。
在剪切子作用下,内含子会被剪切掉,只留下外显子部分,pre-mRNA成为成熟的mRNA,参与后续多肽以及蛋白质的合成。
mRNA可逆转录成cDNA。
测序时,用于测序的打碎的cDNA片段只可能是基因外显子部分。每次对一个cDNA片段进行一次测序称之为一个测序的read。一个基因所有read的总数称为count
fpkm,tpm等是对count数值进行标准化后得到的。
为什么标准化:如基因A和基因B,基因A的count比基因B的count高不能直接说A的表达比B的高,可能只是因为基因A比较长。(基因包含的碱基越多,就越长,匹配到这个基因上面的DNA片段就越多。
如基因A在样本1和样本2中,在样本1中count比在样本2中间中高,也不能说A在样本1中的表达比在样本2中高。(在PCR扩增时如果对样本1多扩增了一些,导致样本1中的DNA片段更多)
为什么标准化:我们无法直观的通过比较counts数值的大小来知道基因表达的差异。
转录本:剪切体在剪切pre-mRNA时,有多种不同的剪切方法,不同的剪切方法产生不同的转录本。
基因长度:通常用c.非重叠外显子长度之和。
测序深度:加入到测序仪器中的DNA片段越多,测序深度越大。

标准化:
RPK(read per k)(每千个碱基的read数):基因的count值除以基因的长度。*10的3次方是为了方便计算。
基因A的RPK=4,B的RPK=6

得出结论:在该样本中基因A表达量小于基因B
RPKM:(单端测序中使用)平衡掉基因长度影响后,再平衡测序深度的影响。(即在某个样品中,某基因的counts值除以该基因长度,再除以该样本所有基因的counts值的和。)*10的9次方方便计算
测序深度的平衡,靠counts值除以所有基因的counts值的和,即表示该基因在该样本中所有基因的占比。
不能用RPKM进行组间比较(即样本1与样本2的比较)

得出结论:样本1中A的表达量高于B。
FPKM(Fragment per million)(用于双端测序):Fragment是read1和read2的连接。公式与RPKM一致。
TPM:(既能组间比较,又能组内比较)(基本都用TPM)

CPM:(用的不多)(只能用于组间比较)

总结:

生信分析很多时候只能输入counts值,因为很多R包有自己的一套标准化算法。