【三十七周】文献阅读:通过具有长期融合池化的双流卷积网络进行的第一人称动作识别
摘要
本论文的核心目标是解决第一人称动作识别(First Person Action Recognition, FPAR)的挑战。与传统的第三人称动作识别相比,第一人称视频(FPV)由于强烈的自我中心运动、频繁的视角变化和多样的全局运动模式,使得动作识别更加困难。为了应对这些挑战,论文提出了一种双流卷积神经网络(Two-stream ConvNet),通过长期融合池化(Long-term Fusion Pooling)操作来捕捉动作的时序结构。该网络结合了外观(appearance)和运动(motion)信息,能够有效地从视频帧中提取特征,并通过池化操作将这些特征融合为全局视频表示。实验结果表明,该方法在标准动作识别数据集上达到了最先进的性能。
Abstract
The core goal of this paper is to address the challenges of First Person Action Recognition. Compared to traditional third-person action recognition, First Person Videos are more difficult to recognize due to strong egocentric motions, frequent viewpoint changes, and diverse global motion patterns. To tackle these challenges, the paper proposes a Two-stream Convolutional Neural Network that captures the temporal structure of actions through Long-term Fusion Pooling. This network combines appearance and motion information, effectively extracting features from video frames and fusing them into a global video representation through pooling operations. Experimental results show that this method achieves state-of-the-art performance on standard action recognition datasets.
通过具有长期融合池化的双流卷积网络进行的第一人称动作识别
Title: First Person Action Recognition via Two-stream ConvNet with Long-term Fusion Pooling
Author: Heeseung Kwon a, Yeonho Kim b, Jin S. Lee a, Minsu Cho b
Source: Pattern Recognition Letters Volume 112, 1 September 2018, Pages 161-167
Link: https://www.sciencedirect.com/science/article/pii/S0167865518303027
研究背景
随着可穿戴设备的普及,第一人称视频(FPV)的应用场景越来越广泛,如生活日志、体育、监控等。第一人称视频通常包含大量的数据,动作识别可以帮助从这些视频中检索和编辑特定事件。此外,第一人称动作识别在增强现实(AR)、自动驾驶、无人机和机器人等领域也有广泛的应用前景。
然而,第一人称动作识别比传统的第三人称动作识别更具挑战性,主要原因包括:
- 强烈的自我中心运动:第一人称视频中的动作通常伴随着强烈的自我中心运动,如身体晃动、头部转动等,导致视频中出现严重的运动模糊和运动视差。
- 频繁的视角变化:第一人称视频的视角变化频繁且突然,导致难以从视频帧中提取有效的特征。
- 多样的全局运动模式:与传统的第三人称视频不同,第一人称视频中的动作通常涉及多样的全局运动模式,如行走、跑步、跳跃等,这些模式对动作识别至关重要。

如上图所示:与(B)中的常规动作相比,(a)中的第一人称动作涉及更频繁的视点改变和全局运动。
此外,现有的动作识别方法主要依赖于手与物体的交互,而第一人称视频中的动作通常不涉及物体交互,因此需要新的方法来识别这些动作。
方法论
本论文提出的方法主要包括三个部分:双流卷积神经网络、长期融合池化和特征分类器。
总体架构
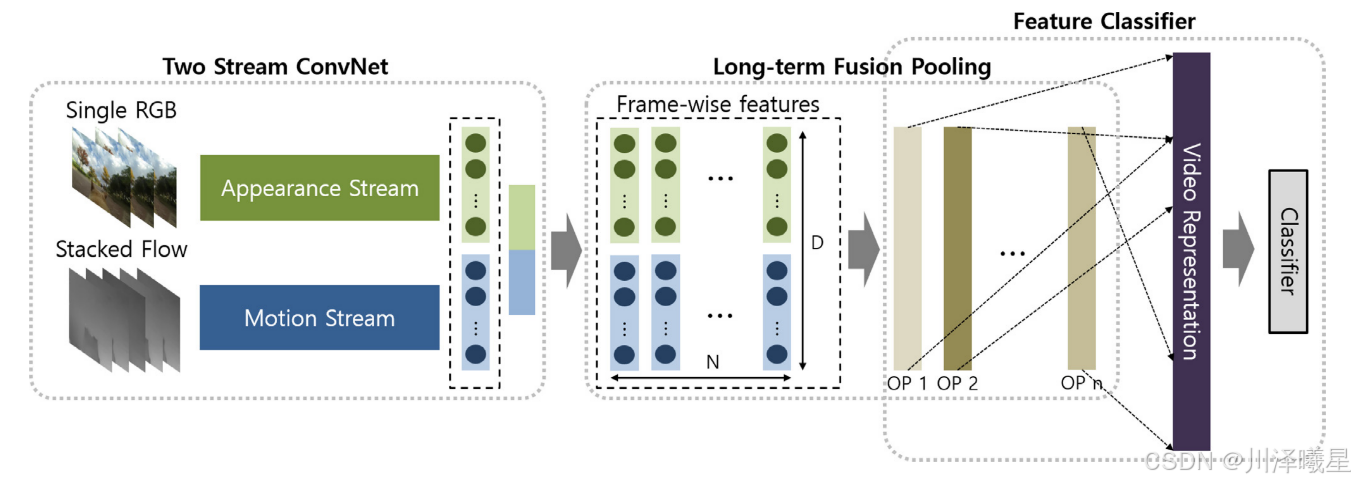
双流卷积神经网络用于从每个帧中提取外观和运动信息。针对每个视频片段堆叠所提取的逐帧特征。长期融合池化层聚合外观和运动特征,并捕获动作的时间结构。具体地,假设N是视频片段的帧号,D是逐帧特征维度,作者通过长期融合池化层将N乘D的逐帧特征聚合为D维特征。特征分类层使用结合长期融合特征的全局视频表示来执行动作分类。
双流卷积神经网络
- 外观流:处理RGB图像,提取外观特征。
class AppearanceStream(nn.Module):
def __init__(self, pretrained=True):
super(AppearanceStream, self).__init__()
# 使用预训练的BN-Inception模型作为外观流的基础网络
self.base_model = models.inception_v3(pretrained=pretrained, aux_logits=False)
# 替换最后的全连接层,以适应特定的分类任务
num_ftrs = self.base_model.fc.in_features
self.base_model.fc = nn.Linear(num_ftrs, 1024) # 假设输出特征维度为1024
def forward(self, x):
# 前向传播:输入RGB图像,输出外观特征
return self.base_model(x)
- 运动流:处理光流图像,提取运动特征。光流图像通过堆叠多个帧的光流信息生成,能够捕捉视频中的运动模式。
class MotionStream(nn.Module):
def __init__(self, pretrained=True):
super(MotionStream, self).__init__()
# 使用预训练的BN-Inception模型作为运动流的基础网络
self.base_model = models.inception_v3(pretrained=pretrained, aux_logits=False)
# 修改输入通道数,因为光流图像通常是多通道的(例如10通道)
self.base_model.Conv2d_1a_3x3.conv = nn.Conv2d(10, 32, kernel_size=3, stride=2, bias=False)
# 替换最后的全连接层,以适应特定的分类任务
num_ftrs = self.base_model.fc.in_features
self.base_model.fc = nn.Linear(num_ftrs, 1024) # 假设输出特征维度为1024
def forward(self, x):
# 前向传播:输入光流图像,输出运动特征
return self.base_model(x)
双流卷积神经网络由外观流和运动流组成。外观流如在常规网络中那样从RGB图像生成外观特征,运动流从堆叠的光流生成运动特征。运动流可以通过识别不同大小和强度的运动模式来区分第一人称动作。作者选择带有批量归一化的Inception网络(BN-Inception)作为双流卷积神经网络的骨干网络,它比原始双流模型更深并且两个流都使用交叉熵损失,softmax作为损失函数。最后一个卷积层是BN-Inception的全局平均池化层,我们可以提取这个层的特征,因为最后一个卷积层可以比全连接层更好地保留空间信息,并且包含比其他卷积层更高级别的特征信息。
class TwoStreamConvNet(nn.Module):
def __init__(self, num_classes, pretrained=True):
super(TwoStreamConvNet, self).__init__()
# 初始化外观流和运动流
self.appearance_stream = AppearanceStream(pretrained=pretrained)
self.motion_stream = MotionStream(pretrained=pretrained)
# 定义融合后的全连接层
self.fc = nn.Linear(2048, num_classes) # 假设外观流和运动流各输出1024维特征,拼接后为2048维
def forward(self, rgb_input, flow_input):
# 前向传播:分别通过外观流和运动流提取特征
appearance_features = self.appearance_stream(rgb_input)
motion_features = self.motion_stream(flow_input)
# 将外观特征和运动特征拼接
combined_features = torch.cat((appearance_features, motion_features), dim=1)
# 通过全连接层进行分类
output = self.fc(combined_features)
return output
也就是说双流卷积神经网络所实现的目标是从每个视频帧中提取帧级特征,并将这些特征堆叠为视频段的特征表示。
长期融合池化
由于第一人称动作通常涉及复杂的运动模式,如快速的身体晃动、视角的突然变化等。这些动作的特征值在时间维度上会有较大的波动,传统的池化操作无法很好地捕捉这些波动,导致时间信息丢失或表达不充分。因此,作者提出了长期融合池化(long-term fusion pooling)操作,如标准差池化(standard deviation pooling)、梯度最大池化(gradient max pooling)等,这些操作能够更好地反映特征值在时间维度上的变化,从而更有效地捕捉第一人称动作的时间结构。这些新的池化操作通过统计特征值的变化范围或峰值,能够更好地处理第一人称视频中的复杂时间动态。
现有的池化方式
- Sum Pooling(求和池化)
求和池化将视频段内所有帧的特征值相加,生成一个全局特征表示。
v k sum = ∑ t = t s t e f k ( t ) v_k^{\text{sum}} = \sum_{t=t^s}^{t^e} f_k(t) vksum=t=ts∑tefk(t)
- v k sum v_k^{\text{sum}} vksum:第 k k k个特征的求和池化结果。
- f k ( t ) f_k(t) fk(t):第 t t t帧的第 k k k个特征值。
- t s t^s ts 和 t e t^e te:视频段的起始帧和结束帧索引。
这种方法简单地将帧间特征值相加,虽然可以累积特征信息,但无法反映特征值随时间的变化情况。
- Max Pooling(最大池化)
最大池化从视频段内所有帧的特征值中选择最大值,生成一个全局特征表示。
v k max = max t ∈ T f k ( t ) v_k^{\text{max}} = \max_{t \in T} f_k(t) vkmax=t∈Tmaxfk(t)
- v k max v_k^{\text{max}} vkmax:第 k k k个特征的最大池化结果。
- f k ( t ) f_k(t) fk(t):第 t t t帧的第 k k k个特征值。
- T T T:视频段的时间跨度, T = { t s , t s + 1 , … , t e } T = \{t^s, t^s + 1, \ldots, t^e\} T={ts,ts+1,…,te}。
这种方法只选择帧间特征的最大值,忽略了其他帧的特征变化,无法捕捉到时间上的动态变化。
- Gradient Pooling(梯度池化)
梯度池化通过计算帧级特征的差分值来捕捉特征随时间的变化。
v k g + = ∑ t = t s t e h k + ( t ) , v k g − = ∑ t = t s t e h k − ( t ) v_k^{g+} = \sum_{t=t^s}^{t^e} h_k^+(t), \quad v_k^{g-} = \sum_{t=t^s}^{t^e} h_k^-(t) vkg+=t=ts∑tehk+(t),vkg−=t=ts∑tehk−(t)
其中:
h k + ( t ) = { f k ( t ) − f k ( t − 1 ) if ( f k ( t ) − f k ( t − 1 ) ) > 0 0 otherwise , h_k^+(t) = \begin{cases} f_k(t) - f_k(t-1) & \text{if } (f_k(t) - f_k(t-1)) > 0 \\ 0 & \text{otherwise}, \end{cases} hk+(t)={fk(t)−fk(t−1)0if (fk(t)−fk(t−1))>0otherwise,
h k − ( t ) = { f k ( t − 1 ) − f k ( t ) if ( f k ( t ) − f k ( t − 1 ) ) < 0 0 otherwise . h_k^-(t) = \begin{cases} f_k(t-1) - f_k(t) & \text{if } (f_k(t) - f_k(t-1)) < 0 \\ 0 & \text{otherwise}. \end{cases} hk−(t)={fk(t−1)−fk(t)0if (fk(t)−fk(t−1))<0otherwise.
- v k g + v_k^{g+} vkg+ 和 v k g − v_k^{g-} vkg−:第 k k k个特征的正向和负向梯度池化结果。
- h k + ( t ) h_k^+(t) hk+(t) 和 h k − ( t ) h_k^-(t) hk−(t):第 t t t帧的正向和负向差分值。
- f k ( t ) f_k(t) fk(t):第 t t t帧的第 k k k个特征值。
这种方式虽然通过计算帧间特征的差分来捕捉变化,但它主要关注的是相邻帧之间的瞬时变化,无法反映长时间范围内的特征波动。
论文提出的池化方式
- Standard Deviation Pooling(标准差池化)
标准差池化通过计算帧级特征的标准差来捕捉特征的时序变化。
v k std = ∑ t = t s t e ( f k ( t ) − m k ) 2 t e − t s v_k^{\text{std}} = \sqrt{\frac{\sum_{t=t^s}^{t^e} (f_k(t) - m_k)^2}{t^e - t^s}} vkstd=te−ts∑t=tste(fk(t)−mk)2
其中:
m k = ∑ t = 1 k f k ( t ) t e − t s m_k = \frac{\sum_{t=1}^k f_k(t)}{t^e - t^s} mk=te−ts∑t=1kfk(t)
- v k std v_k^{\text{std}} vkstd:第 k k k个特征的标准差池化结果。
- f k ( t ) f_k(t) fk(t):第 t t t帧的第 k k k个特征值。
- m k m_k mk:第 k k k个特征在视频段内的均值。
- Gradient Max Pooling(梯度最大池化)
梯度最大池化通过选择帧级特征差分值的最大值来捕捉特征的峰值变化。
v k g max+ = max t ∈ T h k + ( t ) , v k g max- = max t ∈ T h k − ( t ) v_k^{\text{g max+}} = \max_{t \in T} h_k^+(t), \quad v_k^{\text{g max-}} = \max_{t \in T} h_k^-(t) vkg max+=t∈Tmaxhk+(t),vkg max-=t∈Tmaxhk−(t)
其中:
h k + ( t ) = { f k ( t ) − f k ( t − 1 ) if ( f k ( t ) − f k ( t − 1 ) ) > 0 0 otherwise , h_k^+(t) = \begin{cases} f_k(t) - f_k(t-1) & \text{if } (f_k(t) - f_k(t-1)) > 0 \\ 0 & \text{otherwise}, \end{cases} hk+(t)={fk(t)−fk(t−1)0if (fk(t)−fk(t−1))>0otherwise,
h k − ( t ) = { f k ( t − 1 ) − f k ( t ) if ( f k ( t ) − f k ( t − 1 ) ) < 0 0 otherwise . h_k^-(t) = \begin{cases} f_k(t-1) - f_k(t) & \text{if } (f_k(t) - f_k(t-1)) < 0 \\ 0 & \text{otherwise}. \end{cases} hk−(t)={fk(t−1)−fk(t)0if (fk(t)−fk(t−1))<0otherwise.
- v k g max+ v_k^{\text{g max+}} vkg max+ 和 v k g max- v_k^{\text{g max-}} vkg max-:第 k k k个特征的正向和负向梯度最大池化结果。
- h k + ( t ) h_k^+(t) hk+(t) 和 h k − ( t ) h_k^-(t) hk−(t):第 t t t帧的正向和负向差分值。
本文作者结合了标准差池化和梯度池化之后提出了第三种池化方式:
- Gradient Standard Deviation Pooling(梯度标准差池化)
梯度标准差池化通过计算帧级特征差分值的标准差来捕捉特征的时序变化。
v k g std = ∑ t = t s t e ( h k ( t ) − n k ) 2 t e − t s v_k^{\text{g std}} = \sqrt{\frac{\sum_{t=t^s}^{t^e} (h_k(t) - n_k)^2}{t^e - t^s}} vkg std=te−ts∑t=tste(hk(t)−nk)2
其中:
h k ( t ) = f k ( t ) − f k ( t − 1 ) , n k = ∑ t = 1 k h k ( t ) t e − t s h_k(t) = f_k(t) - f_k(t-1), \quad n_k = \frac{\sum_{t=1}^k h_k(t)}{t^e - t^s} hk(t)=fk(t)−fk(t−1),nk=te−ts∑t=1khk(t)
- v k g std v_k^{\text{g std}} vkg std:第 k k k个特征的梯度标准差池化结果。
- h k ( t ) h_k(t) hk(t):第 t t t帧的差分值。
- n k n_k nk:第 k k k个特征差分值在视频段内的均值。
特征分类器
在长期融合池化之后,每个特征向量可能具有不同的尺度和分布。为了确保分类器的性能,需要对特征进行归一化。将每个特征向量归一化为零均值和单位方差。具体来说,对每个特征维度,减去其均值并除以其标准差。接下来将所有帧的特征向量(经过长期融合池化和归一化后)拼接成一个高维向量。这个向量代表了整个视频段的全局特征。
为了捕捉更细粒度的时间信息,可以使用时间金字塔(Temporal Pyramid)技术。具体来说,将视频分成多个时间片段(如1段、2段、4段等),对每个片段分别进行长期融合池化,然后将所有片段的特征拼接起来。
本文作者在尝试了多层感知器(MLP)和非线性SVM之后发现这些方法并没有显著提升性能,因此最终选择了线性SVM作为分类器。关于支持向量机在之前的机器学习周报里也有过相应的学习,因此在这便不再赘述。
实验结果
论文在两个标准动作识别数据集上进行了实验:Dogcentric数据集和UCF101数据集。
- Dogcentric数据集:Dogcentric数据集是最受欢迎的第一人称视角数据集之一,包含209个视频(102个训练视频和107个测试视频),涵盖了10个动作类别,包括多种第一人称动作(如玩球、开车、喝水、喂食、左转、右转、抚摸、身体摇晃、嗅闻和行走)。Dogcentric数据集中的视频平均时长为4秒,作者在提取视频帧之前将其转换为24帧每秒。
- CF101数据集:UCF101数据集是一个流行的动作识别数据集,包含13,320个视频(9.5K训练视频和3.7K测试视频),涵盖了101个动作类别,包含各种类型的动作。UCF101数据集中的视频平均时长为7秒,所有视频的帧率为25 fps。
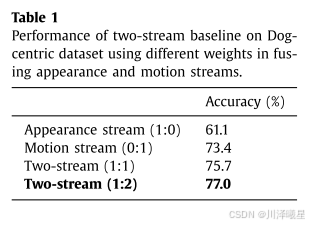
通过表1可以看出,运动流(Motion Stream)的表现优于外观流(Appearance Stream),识别准确率分别为73.4%和61.1%。而将外观流和运动流的结果融合后,识别准确率提高到77.0%。
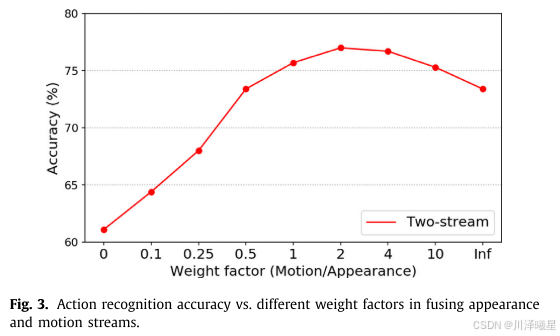
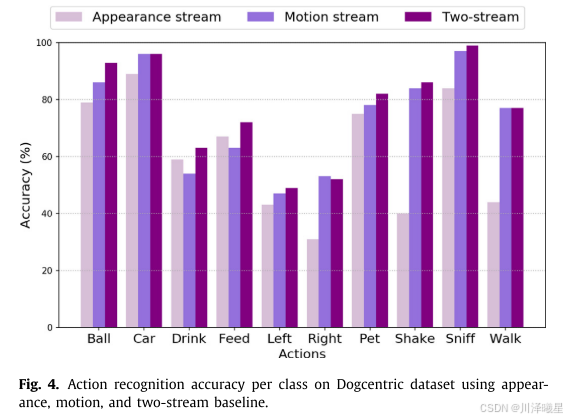
图3可以看出当双流的权重参数设置为2的时候可以获得最高的准确率,图4可以看出采用双流法之后的识别精度普遍高于只使用外观流或者运动流。
实验表明,运动流在融合中起到了更重要的作用。因此我们可以看出双流卷积神经网络在第一人称动作识别任务中表现良好,尤其是运动流能够有效捕捉动作的动态信息。
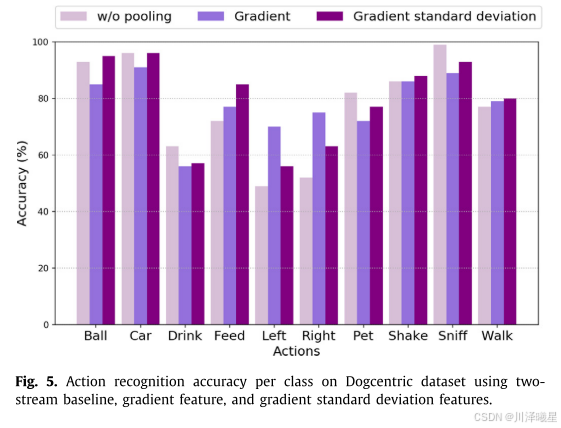
在比较单个特征时,识别第一人称动作时存在一些性能权衡。例如,梯度特征在识别包含强烈自我中心运动的动作(如左转、右转、身体摇晃)时表现更好,而梯度标准差特征在识别包含频繁视角变化的动作(如玩球、喂食)和重复运动模式(如开车、喝水、嗅闻)时表现更好。
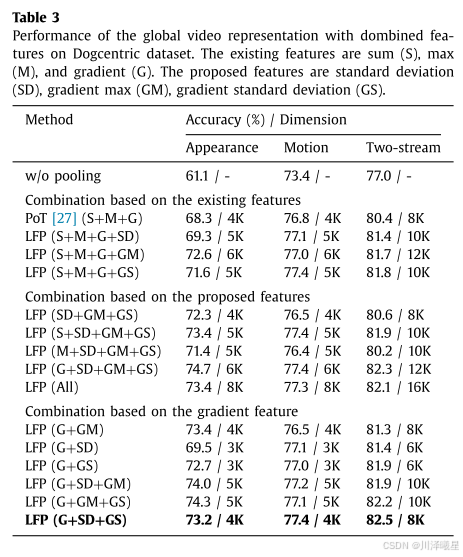
通过长期融合池化,系统的性能显著提升。使用**梯度标准差池化(Gradient Standard Deviation Pooling)和标准差池化(Standard Deviation Pooling)**的组合,系统的准确率达到了82.5%。
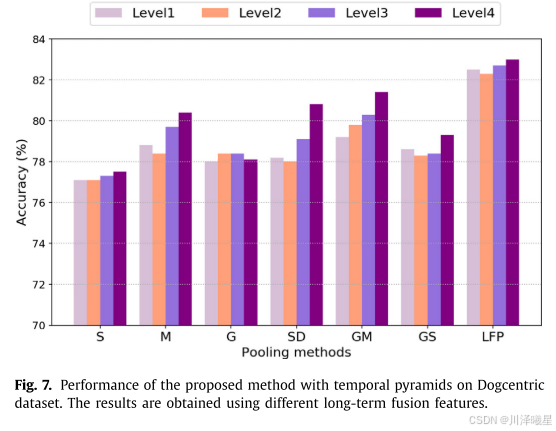
作者进一步使用了时间金字塔技术来捕捉更细粒度的时间信息。为了构建时间金字塔,视频在池化之前被分成多个片段,并对每个片段分别应用长期融合池化。具体来说,时间金字塔的层级表示将视频分成若干段,因此对于4级时间金字塔,长期融合池化将应用15次(即1+2+4+8)。所有池化特征被拼接成一个全局视频表示。通过引入时间金字塔技术,系统的性能进一步提升,达到了83.0%的准确率。
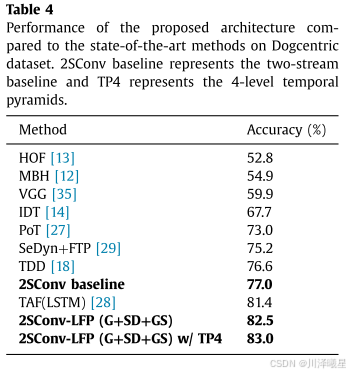
表4总结了本论文方法与当时的SOTA方法在Dogcentric数据集上的性能对比。HOF、MBH、IDT和TDD方法使用IFV进行特征编码,并使用
x
2
x^2
x2核SVM进行分类。需要注意的是,本文的双流卷积神经网络模型优于使用手工特征的方法(HOF、MBH、IDT)。通过将长期融合池化应用于双流卷积神经网络,提出的方法优于所有其他竞争方法,包括使用多种特征(如MBH、IDT、TDD)进行特征编码的方法。此外,结合4级时间金字塔,提出的方法达到了83.0%的准确率。
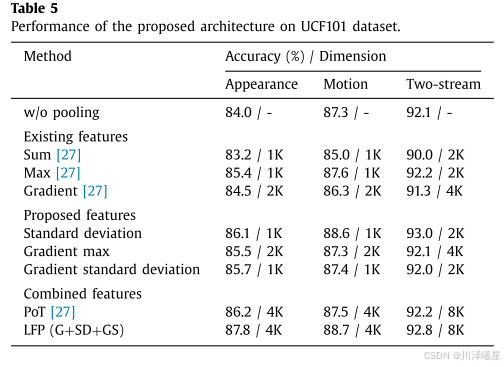
提出的架构还可以通过捕捉动作的时间结构来提升传统动作识别的性能。作者在传统动作数据集UCF101数据集上评估了本文提出的架构。与之前的实验类似,架构在ImageNet上进行了预训练,并在UCF101数据集上进行了微调。结果总结在表5中。标准差(SD)作为单个特征在提出的特征中表现最佳。其他提出的特征(GM、GS)在外观流和运动流中也提供了一些性能提升,但在双流情况下提升不明显。LFP(G+SD+GS)在外观流和运动流中均达到了最佳性能,但在双流情况下没有带来显著提升。与之前的实验相比,长期融合池化在UCF101数据集上的提升不如在Dogcentric数据集上显著,但仍有一定的性能提升。这可能是由于传统动作中帧间的时间变化较小(例如相机运动)。而使用**标准差池化(Standard Deviation Pooling)和梯度标准差池化(Gradient Standard Deviation Pooling)**的组合,系统的准确率达到了92.8%。
创新点
论文的创新点主要体现在以下几个方面:
双流卷积神经网络:论文采用了双流卷积神经网络,分别处理RGB图像和光流图像,能够同时捕捉外观和运动信息。
长期融合池化:论文提出了几种新的池化操作,包括标准差池化、梯度最大池化和梯度标准差池化,能够有效地捕捉帧级特征的时序变化,从而更好地反映动作的时序结构。
时间金字塔:通过引入时间金字塔技术,系统能够捕捉更细粒度的时序信息,进一步提升动作识别的性能。
局限性
尽管论文提出的方法在第一人称动作识别中表现出色,但仍存在一些局限性:
数据集的局限性:虽然论文在Dogcentric和UCF101数据集上进行了实验,但这些数据集的规模和多样性仍然有限。未来的研究可以在更大规模和更多样化的数据集上进行验证。
计算资源的消耗:双流卷积神经网络和长期融合池化操作需要大量的计算资源,尤其是在处理长视频时。未来的研究可以探索更高效的算法,以减少计算资源的消耗。
泛化能力:论文的方法在Dogcentric数据集上表现优异,但在UCF101数据集上的提升不如预期。这表明该方法在处理不同类型的动作时可能存在泛化能力不足的问题。未来的研究可以进一步优化算法,以提高其在不同数据集上的泛化能力。
总结
这篇论文提出了一种基于双流卷积神经网络和长期融合池化的第一人称动作识别方法。通过结合外观和运动信息,并引入新的池化操作,该方法能够有效地捕捉动作的时序结构,从而提升动作识别的性能。实验结果表明,该方法在Dogcentric数据集上达到了最先进的性能,并在UCF101数据集上也有一定的提升。尽管存在一些局限性,如数据集的规模和计算资源的消耗,但该方法为第一人称动作识别提供了一个有效的解决方案,并为未来的研究提供了重要的参考。总的来说,这篇论文通过创新的池化操作和双流卷积神经网络,成功地解决了第一人称动作识别中的一些关键挑战,展示了其在现实应用中的潜力。未来的研究可以进一步扩展该方法的应用场景,并探索更高效的算法,以提高其在实际应用中的性能。