模板计算(Stencil Computation)简介
模板计算(Stencil Computation)详解
基本概念
模板计算(Stencil Computation)是一种广泛应用于科学计算、图像处理和数值分析等领域的计算模式。其核心思想是:对规则网格数据结构中的每个元素,应用相同的计算模式,且该计算仅依赖于该元素及其固定模式的邻居元素。
简单来说,模板计算就像是在数据网格上"滑动"一个固定形状的"模板"(或称"窗口"),对每个位置应用相同的计算规则,从而生成新的数据值。
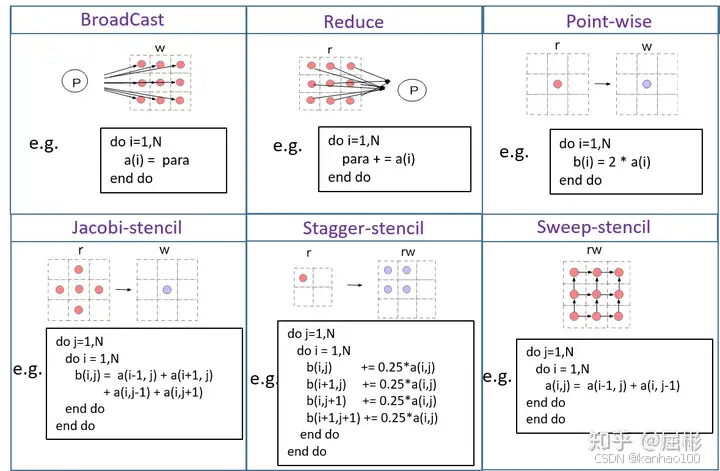
核心组成部分
-
数据网格(Data Grid):
- 数据通常被组织在规则的一维、二维或三维网格中
- 每个网格点代表一个数据值,如温度、压力或像素值等
-
模板(Stencil):
- 模板定义了计算每个网格点的新值时所需的邻域形状和大小
- 通常以一个固定的几何形状表示,如十字形、方形或更复杂的形状
- 包含一组权重,用于计算邻域内数据点的加权组合
-
更新规则:
- 每个网格点的新值通过对其邻域内的点应用某种计算规则来确定
- 计算规则可以是简单的线性组合,也可以是更复杂的非线性函数
数学表示
对于二维模板计算,可以形式化表示为:
O u t p u t [ i , j ] = ∑ m = − r r ∑ n = − r r K e r n e l [ m + r , n + r ] × I n p u t [ i + m , j + n ] Output[i,j] = \sum_{m=-r}^{r} \sum_{n=-r}^{r} Kernel[m+r,n+r] \times Input[i+m,j+n] Output[i,j]=m=−r∑rn=−r∑rKernel[m+r,n+r]×Input[i+m,j+n]
其中:
- O u t p u t [ i , j ] Output[i,j] Output[i,j] 是输出网格在位置 ( i , j ) (i,j) (i,j) 的值
- I n p u t [ i + m , j + n ] Input[i+m,j+n] Input[i+m,j+n] 是输入网格在邻居位置的值
- K e r n e l [ m + r , n + r ] Kernel[m+r,n+r] Kernel[m+r,n+r] 是模板权重
- r r r 是模板半径(模板大小为 2 r + 1 2r+1 2r+1)
模板计算的特点
-
局部性:
- 模板计算只依赖于邻域内的数据点
- 具有良好的数据局部性,有利于缓存优化
- 相邻输出元素的计算依赖于大量重叠的输入元素
-
规则性:
- 对所有元素应用相同的计算规则
- 计算模式固定,易于编译器优化和硬件加速
- 数据访问模式可预测
-
并行性:
- 不同网格点之间的计算通常是独立的
- 非常适合并行化处理(多核CPU、GPU或分布式计算)
- 提供了大量的数据并行机会
-
迭代性:
- 模板计算常常是迭代进行的
- 需要多次应用模板来逐步逼近问题的解
- 迭代过程通常在达到某种收敛条件后停止
-
可扩展性:
- 可以扩展到不同的维度和不同的模板形状
- 适应不同的应用场景和计算需求
常见示例和应用
1. 图像处理
图像模糊(高斯模糊):
使用3×3高斯模糊卷积核:
1/16 2/16 1/16
2/16 4/16 2/16
1/16 2/16 1/16
对于图像中的每个像素,计算其周围3×3邻域内像素值的加权平均,作为该像素的新值。这样可以平滑图像,减少噪声。
边缘检测(Sobel算子):
水平方向Sobel算子:
-1 0 1
-2 0 2
-1 0 1
垂直方向Sobel算子:
-1 -2 -1
0 0 0
1 2 1
应用这些算子可以检测图像中的水平和垂直边缘。
2. 科学计算
热传导模拟:
在二维网格上,可以使用五点模板来模拟热量扩散:
0.25
0.25 0.0 0.25
0.25
每个点的新温度是其上下左右四个相邻点当前温度的平均值。通过多次迭代,可以模拟热量从高温区域向低温区域扩散的过程。
有限差分法:
在求解偏微分方程时,常用有限差分法近似微分算子:
// 二维拉普拉斯算子的五点模板
output[i,j] = (input[i+1,j] + input[i-1,j] +
input[i,j+1] + input[i,j-1] -
4*input[i,j]) / h²
其中h是网格间距。这用于求解热传导方程、波动方程等。
3. 元胞自动机
康威生命游戏:
每个单元格的下一状态取决于它和周围八个邻居的当前状态:
// 对于每个单元格(i,j)
neighbors = count_alive(input[i-1:i+2, j-1:j+2])
if input[i,j] is alive:
output[i,j] = alive if neighbors in [2,3] else dead
else:
output[i,j] = alive if neighbors == 3 else dead
MLIR中的模板计算表示
MLIR(Multi-Level IR)提供了多种方式来表示和优化模板计算,从高层抽象到底层实现。

1. 高级表示(专用Stencil Dialect)
一些MLIR实现提供了专门的Stencil Dialect,直接表达模板计算语义:
// 假设的Stencil Dialect示例
%output = stencil.apply(%input : memref<100x100xf32>) -> memref<98x98xf32> {
%result = stencil.access %input[0, 0] * 0.25 +
%input[-1, 0] * 0.125 +
%input[1, 0] * 0.125 +
%input[0, -1] * 0.125 +
%input[0, 1] * 0.125 +
%input[-1, -1] * 0.0625 +
%input[-1, 1] * 0.0625 +
%input[1, -1] * 0.0625 +
%input[1, 1] * 0.0625
stencil.return %result : f32
}
这种表示直接捕捉了模板计算的语义,使优化更加直观。
2. Linalg Dialect表示
Linalg Dialect是对结构化数据进行结构化处理的通用表示,可以用来表示模板计算:
// 使用Linalg表示3x3卷积
%output = linalg.generic {
indexing_maps = [
affine_map<(i, j, k, l) -> (i + k - 1, j + l - 1)>, // 输入
affine_map<(i, j, k, l) -> (k, l)>, // 卷积核
affine_map<(i, j, k, l) -> (i, j)> // 输出
],
iterator_types = ["parallel", "parallel", "reduction", "reduction"]
} ins(%input, %kernel : memref<100x100xf32>, memref<3x3xf32>)
outs(%output : memref<98x98xf32>) {
^bb0(%in: f32, %k: f32, %out: f32):
%mul = arith.mulf %in, %k : f32
%add = arith.addf %out, %mul : f32
linalg.yield %add : f32
}
Linalg Dialect的特点:
- 既可以将tensor作为操作数,也可以将buffer作为操作数
- 包含payload操作(执行具体运算)和struct操作(表示如何进行运算)
- 在实际应用中,外部Dialect很多情况下会先转换到Linalg Dialect再执行后续优化
3. Affine Dialect表示
Affine Dialect对多面体编译(polyhedral compilation)提供了支持,特别适合表示模板计算中的循环结构:
// 使用Affine表示3x3卷积
affine.for %i = 0 to 98 {
affine.for %j = 0 to 98 {
%acc = arith.constant 0.0 : f32
// 3x3卷积核循环
affine.for %k = 0 to 3 {
affine.for %l = 0 to 3 {
%in_val = affine.load %input[%i + %k - 1, %j + %l - 1] : memref<100x100xf32>
%kernel_val = affine.load %kernel[%k, %l] : memref<3x3xf32>
%prod = arith.mulf %in_val, %kernel_val : f32
%acc_new = arith.addf %acc, %prod : f32
// 更新累加器
%acc = %acc_new
}
}
affine.store %acc, %output[%i, %j] : memref<98x98xf32>
}
}
Affine Dialect的特点:
- 包含多维数据结构的控制流操作
- 支持多维数据的循环和条件控制,存储映射操作等
- 目标是实现多面体变换,如自动并行化、循环融合和平铺
4. Vector Dialect表示
Vector Dialect提供了对SIMD(单指令多数据)或SIMT(单指令多线程)模型的抽象:
// 向量化处理示例
affine.for %i = 0 to 98 {
affine.for %j = 0 to 98 step 4 {
// 加载输入向量
%in_vec_center = vector.transfer_read %input[%i, %j] :
memref<100x100xf32>, vector<4xf32>
%in_vec_north = vector.transfer_read %input[%i-1, %j] :
memref<100x100xf32>, vector<4xf32>
// ... 加载其他方向
// 向量化计算
%result = vector.fma %in_vec_center, %center_weight, %acc : vector<4xf32>
%result = vector.fma %in_vec_north, %north_weight, %result : vector<4xf32>
// ... 其他方向
// 存储结果
vector.transfer_write %result, %output[%i, %j] :
vector<4xf32>, memref<98x98xf32>
}
}
Vector Dialect的特点:
- 作为向量的中间表示,可以被转换到不同目标平台的底层表示
- 实现Tensor在不同平台的支持
- 包含向量化操作,如向量加载/存储、向量计算等
5. SCF Dialect表示
SCF(Structured Control Flow)Dialect提供了比控制流图CFG更高层的抽象:
// 使用SCF表示模板计算
scf.for %i = %c0 to %c98 step %c1 {
scf.for %j = %c0 to %c98 step %c1 {
%sum = arith.constant 0.0 : f32
// 3x3邻域循环
scf.for %di = %c_neg1 to %c2 step %c1 {
scf.for %dj = %c_neg1 to %c2 step %c1 {
%ni = arith.addi %i, %di : index
%nj = arith.addi %j, %dj : index
%val = memref.load %input[%ni, %nj] : memref<100x100xf32>
%weight = memref.load %kernel[%di+1, %dj+1] : memref<3x3xf32>
%prod = arith.mulf %val, %weight : f32
%sum_new = arith.addf %sum, %prod : f32
%sum = %sum_new
}
}
memref.store %sum, %output[%i, %j] : memref<98x98xf32>
}
}
SCF Dialect的特点:
- 提供结构化控制流操作,如并行的for和while循环以及条件判断
- 通常Affine和Linalg会降低到SCF
- SCF也可以降低为Standard中的基本控制流图(CFG)操作
模板计算的优化技术
1. 循环优化
循环平铺(Tiling):
将大型计算分解为缓存友好的块,减少缓存未命中:
// 使用循环平铺
affine.for %i0 = 0 to 98 step 16 {
affine.for %j0 = 0 to 98 step 16 {
// 处理16x16块
affine.for %i1 = 0 to min(16, 98-%i0) {
affine.for %j1 = 0 to min(16, 98-%j0) {
%i = affine.apply affine_map<(i0,i1)->(i0+i1)>(%i0, %i1)
%j = affine.apply affine_map<(j0,j1)->(j0+j1)>(%j0, %j1)
// 模板计算...
}
}
}
}
循环融合(Loop Fusion):
将多个循环合并,减少循环开销并提高数据局部性。
循环重排(Loop Reordering):
改变循环嵌套顺序,优化内存访问模式。
2. 时间平铺(Temporal Tiling)
对于多时间步的模板计算,可以融合多个时间步以减少内存访问:
// 融合两个时间步的示例
affine.for %i = 1 to 97 {
affine.for %j = 1 to 97 {
// 计算第一个时间步
%temp = compute_stencil(%input, %i, %j)
// 直接使用临时结果计算第二个时间步
%result = compute_stencil_with_temp(%input, %temp, %i, %j)
affine.store %result, %output[%i, %j]
}
}
3. 向量化(Vectorization)
利用SIMD指令加速模板计算:
// 向量化处理
%a_vec = vector.load %A[%i, %j] : memref<100x100xf32>, vector<4xf32>
%b_vec = vector.load %B[%i, %j] : memref<100x100xf32>, vector<4xf32>
%result = vector.add %a_vec, %b_vec : vector<4xf32>
vector.store %result, %C[%i, %j] : vector<4xf32>, memref<100x100xf32>
4. 并行化(Parallelization)
模板计算天然适合并行处理:
// 使用SCF并行循环
scf.parallel (%i, %j) = (%c0, %c0) to (%c98, %c98) step (%c1, %c1) {
// 计算单个输出点
// ...
}
5. 内存优化
- 数据布局优化:调整数据存储方式,提高内存访问效率
- 缓存阻塞:调整计算顺序,最大化缓存利用率
- 预取:提前加载数据到缓存,减少等待时间
实际应用领域
1. 图像处理
- 图像滤波(模糊、锐化、边缘检测)
- 图像降噪(中值滤波、双边滤波)
- 形态学操作(膨胀、腐蚀)
- 图像增强和修复
2. 科学计算
- 偏微分方程求解(热传导、流体动力学)
- 天气预报和气候模拟
- 地震波传播模拟
- 电磁场计算
3. 深度学习
- 卷积神经网络的卷积层
- 池化操作
- 图像预处理
4. 物理模拟
- 格点玻尔兹曼方法
- 分子动力学模拟
- 电磁场模拟
- 结构分析
总结
模板计算是一种强大的计算模式,在多个领域有着广泛应用。它的规则性和局部性使其特别适合并行处理和硬件加速。在MLIR中,可以通过多种抽象层次表示模板计算,从高级语义表示到低级硬件特定实现,并应用各种专门的优化技术来提高性能。
MLIR的多层次表示和转换能力为模板计算提供了强大的编译优化框架,使得从高级表示到高效实现的过程更加灵活和高效。通过理解模板计算的核心概念和优化方法,可以更好地利用MLIR来构建高性能的科学计算和图像处理应用。
资料
建议仔细学习,本文都是垃圾,下面才是干货
https://lab.cs.tsinghua.edu.cn/hpc/doc/exp/2.stencil/
https://fancyerii.github.io/pmpp/ch8/
https://www.cnblogs.com/wujianming-110117/p/17297847.html