AI Agent开发大全第一课-AI是什么以及如何使用AI
AI的发展历程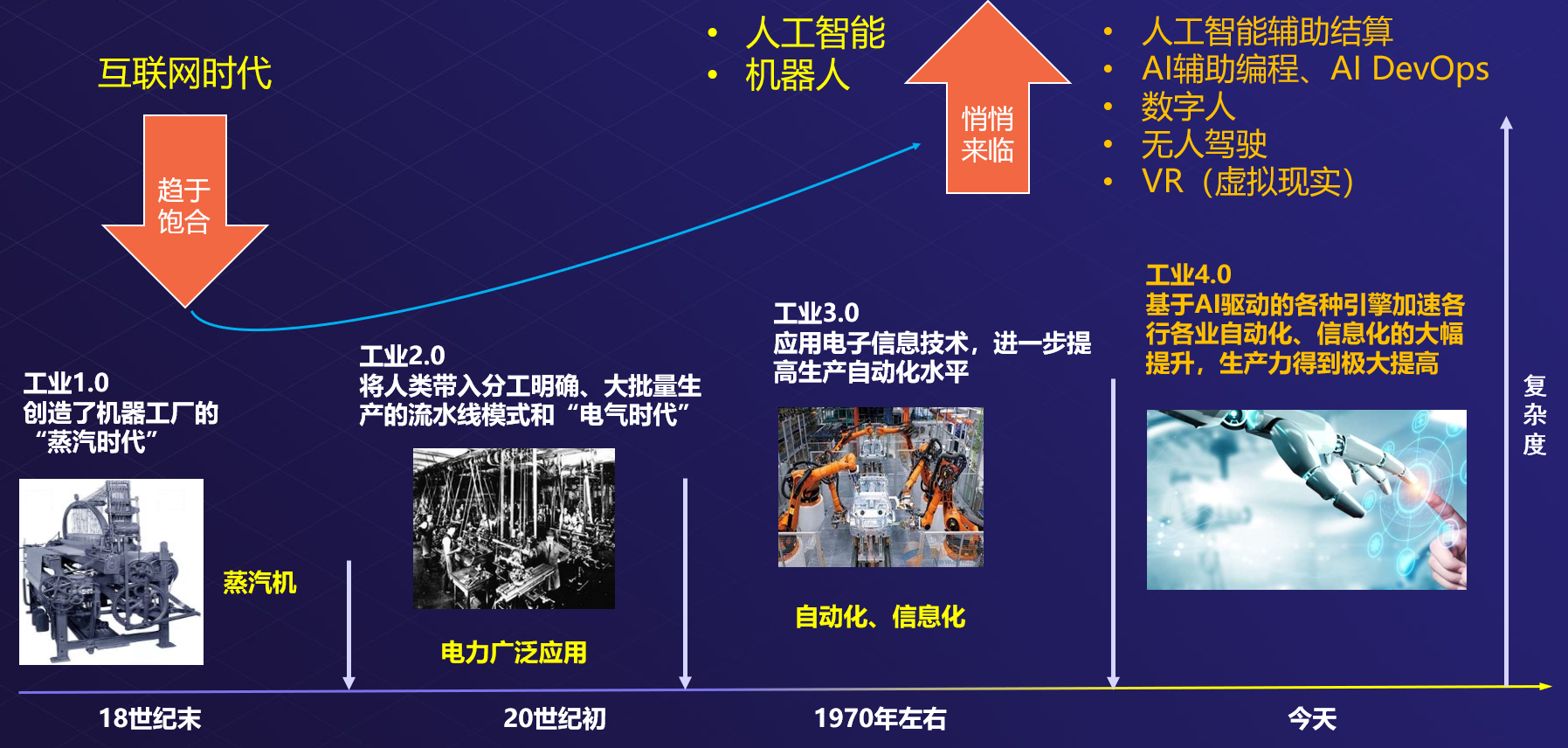
古老的起步:1950年代
人工智能的起步可以追溯到20世纪50年代。1950年,艾伦·图灵提出了“图灵测试”,奠定了检查机器智能的重要基础。1956年,达特茅斯会议被认为是人工智能的正式诞生,多个学者围绕智能机器的构想展开讨论,萌发了对AI的研究热潮。这一时期的AI以逻辑推理为核心,涌现了一系列的初步程序,如逻辑理论家和侦探程序。
繁荣与困境:1960年代
1960年代,AI研究获得了相当令人瞩目的成果。研究者们利用自然语言处理及机器学习技术,使机器能够进行简单对话和文本理解。1966年,约瑟夫·韦岑鲍姆研发的ELIZA程序,能够模拟人类心理咨询对话,震惊了整个科技界。然而,随之而来的技术瓶颈,导致研究停滞,资金逐渐枯竭,陷入所谓的“AI寒冬”。
重生的希望:1980年代
1980年代,AI领域迎来复苏,关键在于专家系统的崛起。这些系统采用大量专家知识进行决策,最著名的应用为MYCIN和XCON,它们帮助医院诊断疾病和公司管理库存。同时,神经网络的重新复兴让AI领域焕发出新的生机。人们开始重建对机器学习的信心,为后来的发展铺平了道路。
进入新时代:1990年代
1990年代见证了人工智能与计算机科学的深度交融。IBM的深蓝在1997年以棋局形式击败国际象棋世界冠军加里·卡斯帕罗夫,标志着AI在复杂推理与计算上的提升。此时,互联网的快速发展为AI提供了前所未有的数据和算力支持,开启了新的可能。
飞速发展:21世纪初
进入21世纪,人工智能的脚步日益加快。2006年,深度学习的概念得到推广,推动了AI技术的迅猛发展。2009年,谷歌开发的无人驾驶汽车开始路测,进一步推动了AI在机器人领域的探索。此时,AI在视觉识别、语音识别等诸多领域取得了突破,逐渐走入百姓生活。
智能先锋:2010年代
2010年代,AI的应用逐渐全面铺开。2011年,IBM的沃森在电视节目“危险边缘”中战胜人类选手,进一步巩固了机器智能的地位。2016年,谷歌的AlphaGo以4:1击败围棋世界冠军李世石,至此AI自信加剧,进入了一个“无所不能”的时代。此外,众多企业开始投资AI,大量初创公司纷纷涌现。
引领未来:2023年GPT-4
到2023年,OpenAI推出的GPT-4震撼世界,具备更高的语言理解和生成能力,广泛应用于教育、商业等多个领域。GPT-4的多模态能力,打破了以往单一文本处理的限制,使得AI更加灵活和智能,成为人们日常生活中不可或缺的助手。看似普通的沟通中,AI已经渗透进我们的工作、学习、娱乐等方方面面。
人工智能的历程是一段波澜壮阔的历史,各个时代的突破与瓶颈交织着推动着人类智慧的前进。未来的道路漫长而未知,随着技术的不断进步,人工智能必将以更加丰富的形态深刻影响人类生活。而在探索与实践中,AI也将持续向前,开创更广阔的可能。
为什么现在的AI又叫大模型呢?
大模型的定义
近年来,人工智能的迅猛发展引发了广泛的关注,尤其是“大模型”这一概念越来越深入人心。大模型,顾名思义,通常指的是那些拥有大量参数、能够处理复杂任务的机器学习模型。与传统小模型相比,大模型在数据处理、信息理解和生成等方面表现更加出色。为了理解为什么现在的AI被称为大模型,我们需要深入探讨几个关键因素。
参数的数量与模型的能力
大模型的核心特征在于其巨大的参数量。以GPT-3为例,它拥有1750亿个参数,这是一个令人惊讶的数字。这些参数的数量直接影响模型的表现。大型模型能够从海量数据中学习、提取更复杂的特征,从而在自然语言处理、图像识别等领域展现出超出预期的能力。相比之下,小模型往往只能处理简单的任务,缺乏应对复杂情况的能力。大模型将人类的语言、视觉、思维等特性进行了极大程度的模拟,其应用范围之广,性能之优越,正是其被称为“大”模型的重要原因。
数据与模型训练
另一个驱动大模型发展的因素是数据量的激增。互联网的普及使得生成的数据量呈现指数级增长。大模型在训练过程中需要大量的数据进行学习。模型通过分析和学习这些数据中的模式,进而能够更准确地进行预测和生成。以图像识别为例,大型数据集如ImageNet为大模型提供了丰富的样本,使其在图像分类、物体检测等任务中表现优异。
计算资源的飞跃
大模型的训练和应用离不开强大的计算资源。随着计算能力的提升,尤其是GPU和TPU的广泛应用,大型神经网络的训练变得更加可行。过去,训练一个复杂的模型可能需要几个月的时间,而现在,凭借高效的计算架构及分布式训练技术,大模型的训练时间大大缩短。这种技术进步为大模型的普及铺平了道路,让更多的企业和研究机构能够运用这一技术,推动了人工智能的快速发展。
复杂任务的执行能力
大模型能够处理复杂、灵活的任务。以自然语言处理为例,用户可以通过简短的文本指令生成诗歌、编写代码,甚至与模型进行对话。这一切都得益于模型的设计使其具备了理解上下文、推理以及知识生成的能力。这种跨领域的应用能力是传统模型无法比拟的。人们开始意识到,无论是在医疗领域的疾病预测,还是在金融领域的风险评估,大模型都成为不可或缺的工具。
未来的发展趋势
大模型的崛起并不止于此。随着技术的不断演进,未来可能会出现更为强大的模型,不仅在规模上更加庞大,能力上也将更为强劲。模型的可解释性、训练方法的创新等都是未来研究的重要方向。大模型给我们带来了更多的可能性,但同时也带来了对资源消耗、安全性、伦理等问题的思考和挑战。
大模型的出现是人工智能发展的重要里程碑。它不仅代表了技术的飞跃,更是对人类思维、学习和表达方式的深刻影响。通过对大模型概念的探讨,可以看出,它并非仅仅是一个简单的名词,而是现代科技、数据及计算能力结合的产物。理解这一点,有助于我们打破固有观念,更加全面地看待未来人工智能的发展。
如何和大模型交互?
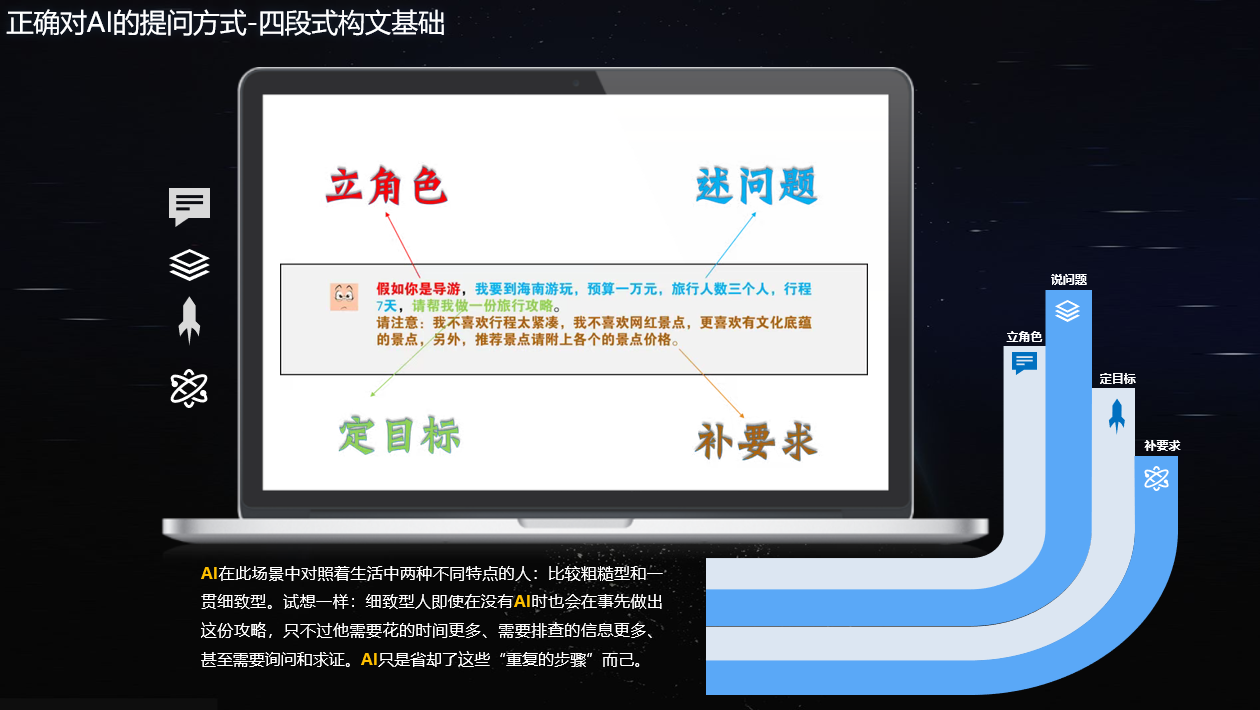
要让大模型能够处理复杂、灵活的任务。以自然语言处理为例,用户可以通过简短的文本指令生成诗歌、编写代码,甚至与模型进行对话。这一切的实现依赖于提示词(prompt)的构建。提示词是与大模型进行交互的桥梁,用户通过合理的提示词,引导模型理解意图,从而产生期望的输出。编写高效的提示词并非易事,需要遵循一定的步骤。在这里,我将通过立角色、定目标、述问题、补一刀四个方面,来详细阐述如何写好一个提示词。
立角色:定义交互主体
立角色是指在提示词中清晰地界定交互双方的身份。明确用户希望模型扮演的角色,可以帮助模型更准确地理解上下文和用户需求。例如,如果用户希望模型作为一位诗人,那么提示词可以是:“作为一位现代诗人,请为我写一首关于秋天的诗。”这样的表述让模型明确了角色定位,使输出的内容更符合期待。
角色的设定不仅影响语气和内容,也决定了模型可以采取的思考角度。不同的角色会带来不同的思维模式与语言风格。特别是在需要模型提供专业知识或独特见解的任务中,赋予模型合适的角色尤为重要。
定目标:明确任务方向
一旦角色设定完毕,接下来需要明确目标。目标是用户希望模型完成的具体任务。清晰的目标可以帮助模型聚焦于准确输出,避免偏离用户意图。例如,用户如果希望模型编写一段代码,则应用简洁明了的提示词,如:“请为我编写一个Python函数,实现计算阶乘的功能。”这样的提示词明确指出了功能需求,模型能迅速理解任务。
缺乏清晰目标的提示词会导致无的放矢,输出结果往往不符合用户预期。由于大模型是基于预训练知识进行生成,而非创新性创造,因此目标的明确性直接影响到模型的表现。
述问题:详细描述上下文
问题的描述是构建有效提示词过程中不可或缺的一环。用户需将问题的背景、前因后果详细地呈现给模型。比如,当用户希望了解量子计算的优势时,单纯的提问“量子计算有什么优势?”可能会得到模糊的回答。而如果这样提问:“在当前技术条件下,量子计算相较于经典计算在解决复杂问题时的优势是什么?”则能确保模型理解并针对性地提供更深入的分析。
详尽的问题描述不仅为模型提供必要的上下文信息,还能引导其从用户的需求出发,更精准地生成符合期望的内容。上下文的丰富性有助于增强模型回答的准确性与相关性。
补一刀:追问与深入
补一刀是指在得到初步反馈后,继续追问、深入探讨。随着交互的深入,用户可根据模型的回答逐步调整问题,强化对话的深度与广度。例如,用户在获得了模型对量子计算优势的初步理解后,可以追问:“那么在实际应用中,量子计算遇到的主要挑战是什么?”这种方式不仅能够激发对话的延续性,也使得信息获取变得更加全面、深入。
大模型通过上下文的记忆能力,可以跟踪与用户的交互,进而调整自己的回答方向。用户的追问能够使模型在特定领域展开更深层次的分析与讨论,弥补初始回答的不足,达到更好的交流效果。
总结而言,提示词的构建是一个系统性过程,涉及到角色设定、目标明确、问题详述与反馈追问等多个层面。通过合理地撰写提示词,用户能够高效地与大模型互动,最大限度地发挥其在自然语言处理中的潜力。作为一种新兴技术,正确理解并运用提示词的写法将帮助用户更好地驾驭大模型,享受科技进步带来的便利与创新。
下面来看两个例子来看如何写好一个提示词
什么是写得不好的提示词?
去杭州旅游,写一份4天的攻略吧?当然,您是可以这样问!但是您所取得回答总觉得。。。。。。似乎这个回答即说了又没说。


来看上面AI的回答。
你说它回答了没?它回答了。
你说它回答得有用吗?实际一点没有用。
这就是通常人们经常在刚开始使用AI时的通病。
- 以为这是真的AI!
- 以为AI是钢铁侠里的贾维斯!
- 拿AI当搜索引擎了!
什么是写得好的提示词?
这也从侧面说明了AI为什么只能是大模型的原因,因此要用好大模型,必须我们首先要通过前面说得4个点才能取得良好的效果,要不然你始终都会觉得AI不过是一个“智障”。
那么我们来看一个写得好的提示词长什么样
去杭州4天
你是一个专业的中国旅行社的策划。
我从上海坐高铁出发
主要是休闲,因此不想一早动身,下午13:00,14:00出发最好。
到了后我希望住在离西湖不超过2.1公里路程
4天里主要是游玩,全程我打滴滴不坐公交不要累,爬山也不要爬危险的,以美食和美景为主。
当中有一天要去著名的林荫寺。
所以请你给我排一下这4天行程。看到没!
此时我们再来看这个AI的回答
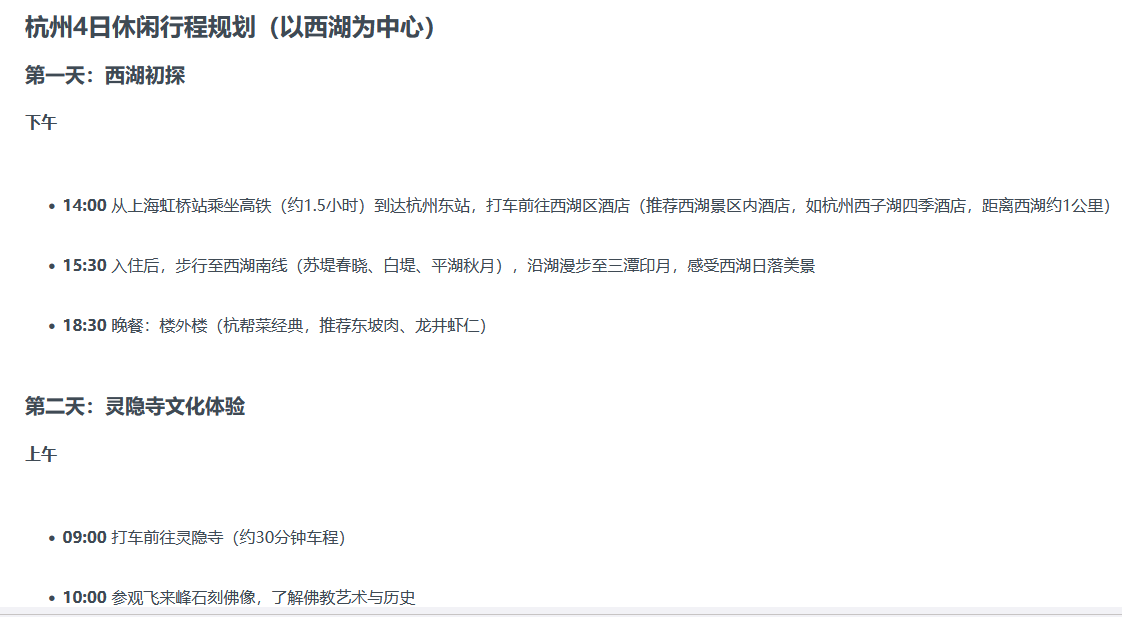



其中没去过杭州的人可能不知道:
- 1. 西溪湿地
- 2. 外婆家
- 3. 湖宾商圈
此时我打开大众点评就可以完全用这份指导手册做4天杭州游了,信息都是对得上的!
这就是提示词写得好与不好的区别。
总结一下提示词为什么写好这么重要
- 现在的AI是大模型,它的数据不是像百度,GOOGLE那种实时的,它是预训练的;
- 预训练的数据有一个“延时”,可能有一些延时1个月,有得延时4-5个月;
- 预训练的数据要让大模型组织好了输出给到你并取得最佳回答效果,你需要和搜索一样写好搜索关键词,只不过因为它是一个更高级一点的搜索可以理解语义,或者又叫基于语义搜索因此你的提示词写得越详细,大模型的回答越有质量;
要知道,很大程度上2个大模型可能没有太多本质上的“质的区别”,而完全在于使用的“人”自身。这就好比:
一个新人进公司,有的人就可以带好新人,会告诉他什么该做,什么不该做,怎么做,为什么,注意什么,甚至还会给到“课后习题”。而有的人就带不好新人。
这正是现在的AI被称为大模型的终极原因,因为它不会创造,它只能重复!那么要重复了好使用的人就要引导的好。
当前的AI是“鹦鹉学舌”,并没有“自我创新、更新”的能力。
当然,现在的AI有一种是可以取代搜索引擎的如:perplexity,它就是把搜索引擎里实时的信息和AI本身相结合,可以做到1分钟内信息得同步!
因此,如果你的问题是“实时性相关”如:铁血战士最新一集何时上映?此时你不能使用“预训练的大模型”如:GPT、CLAUDE、DEEPSEEK,而要使用类似:perplexity、豆包联网一类的带有搜索功能的AI。
另外要多说一句:AI联网不是AI搜索引擎,AI联网只是AI在用自身预训练的知识回答问题不足时用搜索来补充。这和专业的AI搜索引擎有着巨大的差别。
你可以这样来理解AI搜索引擎和带有联网功能的AI。
- AI搜索引擎是:互联网;
- 可以联网的AI:是一台电脑;
好了,结束今天的课程。