学习记录 6 pointnet复现
一、复现代码
然后去找相关的2d的声呐图像分类的算法
融合可以搞的,虽然有文献但是不多,感觉也是可以的
"""
Author: Benny
Date: Nov 2019
"""
import os
import sys
import torch
import numpy as np
import datetime
import logging
import provider
import importlib
import shutil
import argparse
from pathlib import Path
from tqdm import tqdm
from data_utils.ModelNetDataLoader import ModelNetDataLoader
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
ROOT_DIR = BASE_DIR
sys.path.append(os.path.join(ROOT_DIR, 'models'))
#随机种子 seed
#测试验证的时候,只跑一次结果,还是【投票跑3次取平均】
#点云分类有两个指标,一个是总体的分类准确率,另一个是类平均准确率
#是选择最好的作为结果还是【用自己的保存的最好的模型的函数(没听懂)】
def parse_args():
'''PARAMETERS'''
parser = argparse.ArgumentParser('training')
parser.add_argument('--use_cpu', action='store_true', default=False, help='use cpu mode')
parser.add_argument('--gpu', type=str, default='0', help='specify gpu device')
parser.add_argument('--batch_size', type=int, default=24, help='batch size in training')
parser.add_argument('--model', default='pointnet_cls', help='model name [default: pointnet_cls]')
parser.add_argument('--num_category', default=40, type=int, choices=[10, 40], help='training on ModelNet10/40')
parser.add_argument('--epoch', default=200, type=int, help='number of epoch in training')
parser.add_argument('--learning_rate', default=0.001, type=float, help='learning rate in training')
parser.add_argument('--num_point', type=int, default=1024, help='Point Number')
parser.add_argument('--optimizer', type=str, default='Adam', help='optimizer for training')
parser.add_argument('--log_dir', type=str, default=None, help='experiment root')
parser.add_argument('--decay_rate', type=float, default=1e-4, help='decay rate')
parser.add_argument('--use_normals', action='store_true', default=False, help='use normals')
parser.add_argument('--process_data', action='store_true', default=False, help='save data offline')
parser.add_argument('--use_uniform_sample', action='store_true', default=False, help='use uniform sampiling')
return parser.parse_args()
def inplace_relu(m):
classname = m.__class__.__name__
if classname.find('ReLU') != -1:
m.inplace=True
def test(model, loader, num_class=40):
mean_correct = []
class_acc = np.zeros((num_class, 3))
classifier = model.eval()
for j, (points, target) in tqdm(enumerate(loader), total=len(loader)):
if not args.use_cpu:
points, target = points.cuda(), target.cuda()
points = points.transpose(2, 1)
pred, _ = classifier(points)
pred_choice = pred.data.max(1)[1]
for cat in np.unique(target.cpu()):
classacc = pred_choice[target == cat].eq(target[target == cat].long().data).cpu().sum()
class_acc[cat, 0] += classacc.item() / float(points[target == cat].size()[0])
class_acc[cat, 1] += 1
correct = pred_choice.eq(target.long().data).cpu().sum()
mean_correct.append(correct.item() / float(points.size()[0]))
class_acc[:, 2] = class_acc[:, 0] / class_acc[:, 1]
class_acc = np.mean(class_acc[:, 2])
instance_acc = np.mean(mean_correct)
return instance_acc, class_acc
def main(args):
def log_string(str):
logger.info(str)
print(str)
'''HYPER PARAMETER'''
os.environ["CUDA_VISIBLE_DEVICES"] = args.gpu
'''CREATE DIR'''
timestr = str(datetime.datetime.now().strftime('%Y-%m-%d_%H-%M'))
exp_dir = Path('./log/')
exp_dir.mkdir(exist_ok=True)
exp_dir = exp_dir.joinpath('classification')
exp_dir.mkdir(exist_ok=True)
if args.log_dir is None:
exp_dir = exp_dir.joinpath(timestr)
else:
exp_dir = exp_dir.joinpath(args.log_dir)
exp_dir.mkdir(exist_ok=True)
checkpoints_dir = exp_dir.joinpath('checkpoints/')
checkpoints_dir.mkdir(exist_ok=True)
log_dir = exp_dir.joinpath('logs/')
log_dir.mkdir(exist_ok=True)
'''LOG'''
args = parse_args()
logger = logging.getLogger("Model")
logger.setLevel(logging.INFO)
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
file_handler = logging.FileHandler('%s/%s.txt' % (log_dir, args.model))
file_handler.setLevel(logging.INFO)
file_handler.setFormatter(formatter)
logger.addHandler(file_handler)
log_string('PARAMETER ...')
log_string(args)
'''DATA LOADING'''
log_string('Load dataset ...')
data_path = 'data/modelnet40_normal_resampled/'
train_dataset = ModelNetDataLoader(root=data_path, args=args, split='train', process_data=args.process_data)
test_dataset = ModelNetDataLoader(root=data_path, args=args, split='test', process_data=args.process_data)
trainDataLoader = torch.utils.data.DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True, num_workers=10, drop_last=True)
testDataLoader = torch.utils.data.DataLoader(test_dataset, batch_size=args.batch_size, shuffle=False, num_workers=10)
'''MODEL LOADING'''
num_class = args.num_category
model = importlib.import_module(args.model)
shutil.copy('./models/%s.py' % args.model, str(exp_dir))
shutil.copy('models/pointnet2_utils.py', str(exp_dir))
shutil.copy('./train_classification.py', str(exp_dir))
classifier = model.get_model(num_class, normal_channel=args.use_normals)
criterion = model.get_loss()
classifier.apply(inplace_relu)
if not args.use_cpu:
classifier = classifier.cuda()
criterion = criterion.cuda()
try:
checkpoint = torch.load(str(exp_dir) + '/checkpoints/best_model.pth')
start_epoch = checkpoint['epoch']
classifier.load_state_dict(checkpoint['model_state_dict'])
log_string('Use pretrain model')
except:
log_string('No existing model, starting training from scratch...')
start_epoch = 0
if args.optimizer == 'Adam':
optimizer = torch.optim.Adam(
classifier.parameters(),
lr=args.learning_rate,
betas=(0.9, 0.999),
eps=1e-08,
weight_decay=args.decay_rate
)
else:
optimizer = torch.optim.SGD(classifier.parameters(), lr=0.01, momentum=0.9)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=20, gamma=0.7)
global_epoch = 0
global_step = 0
best_instance_acc = 0.0
best_class_acc = 0.0
'''TRANING'''
logger.info('Start training...')
for epoch in range(start_epoch, args.epoch):
log_string('Epoch %d (%d/%s):' % (global_epoch + 1, epoch + 1, args.epoch))
mean_correct = []
classifier = classifier.train()
scheduler.step()
for batch_id, (points, target) in tqdm(enumerate(trainDataLoader, 0), total=len(trainDataLoader), smoothing=0.9):
optimizer.zero_grad()
points = points.data.numpy()
points = provider.random_point_dropout(points)
points[:, :, 0:3] = provider.random_scale_point_cloud(points[:, :, 0:3])
points[:, :, 0:3] = provider.shift_point_cloud(points[:, :, 0:3])
points = torch.Tensor(points)
points = points.transpose(2, 1)
if not args.use_cpu:
points, target = points.cuda(), target.cuda()
pred, trans_feat = classifier(points)
loss = criterion(pred, target.long(), trans_feat)
pred_choice = pred.data.max(1)[1]
correct = pred_choice.eq(target.long().data).cpu().sum()
mean_correct.append(correct.item() / float(points.size()[0]))
loss.backward()
optimizer.step()
global_step += 1
train_instance_acc = np.mean(mean_correct)
log_string('Train Instance Accuracy: %f' % train_instance_acc)
with torch.no_grad():
instance_acc, class_acc = test(classifier.eval(), testDataLoader, num_class=num_class)
if (instance_acc >= best_instance_acc):
best_instance_acc = instance_acc
best_epoch = epoch + 1
if (class_acc >= best_class_acc):
best_class_acc = class_acc
log_string('Test Instance Accuracy: %f, Class Accuracy: %f' % (instance_acc, class_acc))
log_string('Best Instance Accuracy: %f, Class Accuracy: %f' % (best_instance_acc, best_class_acc))
if (instance_acc >= best_instance_acc):
logger.info('Save model...')
savepath = str(checkpoints_dir) + '/best_model.pth'
log_string('Saving at %s' % savepath)
state = {
'epoch': best_epoch,
'instance_acc': instance_acc,
'class_acc': class_acc,
'model_state_dict': classifier.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
}
torch.save(state, savepath)
global_epoch += 1
logger.info('End of training...')
if __name__ == '__main__':
args = parse_args()
main(args)
具体进程:
1、虚拟环境
anaconda prompt :
---conda create -n pointnet python=3.7
---conda install pytorch==1.6.0 cudatoolkit=10.1 -c pytorch
2、pycharm
设置环境
3、数据
在pointnet文件夹下新建data文件,将40数据放到data文件夹下
4、代码
修改代码参数运行
5、运行结果
训练
C:\Users\229\anaconda3\envs\pointnet\python.exe D:\pycharm\Pointnet_Pointnet2_pytorch-master\train_classification.py
PARAMETER ...
Namespace(batch_size=8, decay_rate=0.0001, epoch=1, gpu='0', learning_rate=0.001, log_dir='pointnet2_cls_ssg', model='pointnet2_cls_ssg', num_category=40, num_point=1024, optimizer='Adam', process_data=False, use_cpu=False, use_normals=False, use_uniform_sample=False)
Load dataset ...
The size of train data is 9843
The size of test data is 2468
No existing model, starting training from scratch...
Epoch 1 (1/1):
100%|██████████| 1230/1230 [09:21<00:00, 2.19it/s]
Train Instance Accuracy: 0.448069
100%|██████████| 309/309 [02:12<00:00, 2.34it/s]
Test Instance Accuracy: 0.652508, Class Accuracy: 0.532580
Best Instance Accuracy: 0.652508, Class Accuracy: 0.532580
Saving at log\classification\pointnet2_cls_ssg\checkpoints/best_model.pth测试
PARAMETER ...
Namespace(batch_size=24, gpu='0', log_dir='pointnet2_cls_ssg', num_category=40, num_point=1024, num_votes=3, use_cpu=False, use_normals=False, use_uniform_sample=False)
Load dataset ...
The size of test data is 2468
100%|██████████| 103/103 [02:39<00:00, 1.55s/it]
Test Instance Accuracy: 0.650485, Class Accuracy: 0.527661
二、论文
基于深度学习的点云配准的最新进展改进了泛化,但大多数方法仍然需要针对每个新环境进行重新训练或手动参数调整。
在实践中,大多数现有方法仍然要求用户在未知数据集环境的情况下提供最佳参数->所以要针对不同的场景(室内和室外)进行泛化
限制泛化的三个关键因素:
(a) 依赖于特定于环境的体素大小和搜索半径
(b)基于学习的关键点检测器在域外情况的鲁棒性较差
(c) 原始坐标使用
目标:估计两个无序的三维点云 P 和 Q 之间的相对三维旋转矩阵 R和平移向量 t
BUFFER-X方法
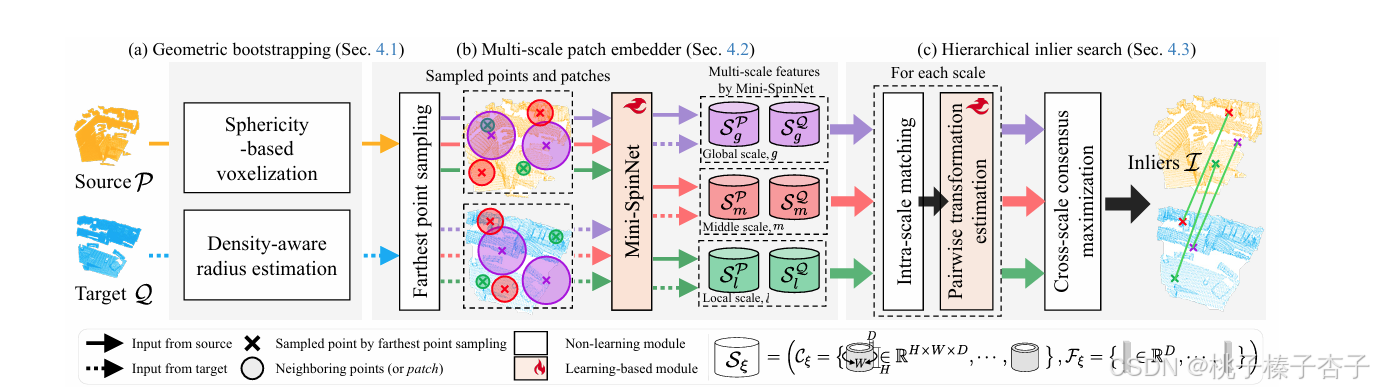
(a) 自适应地确定体素大小和搜索半径
1)基于球形度的体素化——v
h(P,Q)根据点的数量选择较大点云
g(P,δ) 是一个从点云 P 中随机采样 δ% 点的函数
C是 g(h(P,Q),δv) 的协方差矩阵,δv是定义的采样率
然后使用PCA计算三个特征值和对应的特征向量:Cva=λava
假设λ1≥λ2≥λ3,则球形度为λ3/λ1
通常来讲雷达的球形度低于rgb-d相机的
所以有:
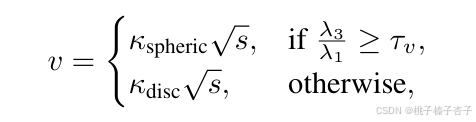
其中s 表示点云沿最小特征值 v3 对应的特征向量方向的分布范围
2)基于密度感知的半径估计
搜索半径在local、中间和全局三个尺度上分别进行估计,以捕捉不同尺度下的特征信息
设 N(pq,P,r) 为点 pq 在点云 P 中,以 r 为半径的邻域内的点集,定义为:
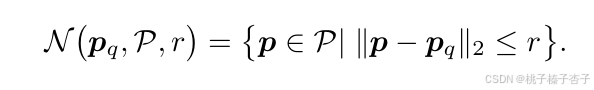
半径的计算,τξ 是用户定义的阈值,表示期望的邻域密度(即邻域点相对于总点数的平均比例)
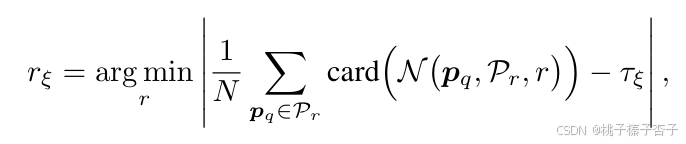
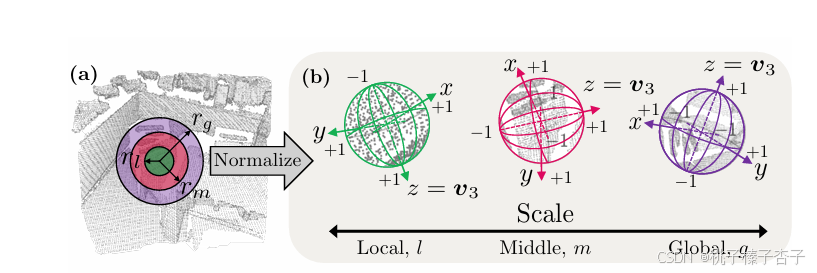
τl ≤ τm ≤ τg,相应地,rl ≤ rm ≤ rg(半径和期望密度的关系
(b) 多尺度
1)最远点采样
我们在每个尺度上使用最远点采样(FPS)从 P 中采样 Pξ(分别从 Q 中采样 Qξ),以避免使用基于学习的关键点检测器。需要注意的是,我们为每个尺度独立采样不同的点,这是因为不同区域可能需要不同的尺度来进行最佳特征提取。
2)基于Mini-SpinNet的描述符生成
我们通过除以 rξ 将每个块中的点的尺度归一化到有界范围 [−1,1]来确保尺度的一致性,然后
将块的大小固定为 Npatch,将这些归一化的块作为输入,Mini-SpinNet输出一个超集 SPξ,包含 D 维特征向量 FPξ 和圆柱形特征图 CPξ,对应于 Pξ(分别地,SQξ 包含 FQξ 和 CQξ 来自 Qξ)
BUFFER使用学习到的参考轴来提取圆柱坐标,我们的方法通过将PCA应用于块内点的协方差来定义每个块的参考轴,将 z 方向设置为 v3(协方差对应的特征向量)
(c) 分层内点搜索
1)在 FPξ 和 FQξ 之间进行基于最近邻的双向匹配,得到每个尺度上的匹配对应关系 Aξ
2)成对变换估计
计算R和t
3)使用所有尺度上的每对 (R,t) 估计值,选择具有最大基数的3D点对,确保跨尺度一致性,通过共识最大化问题来选择最终的内点对应关系
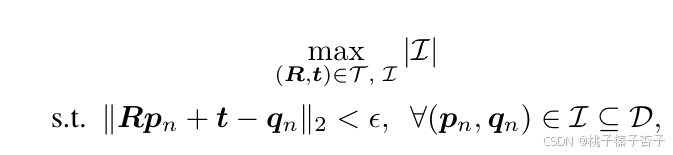
4)最终,将 I 作为输入,使用求解器(如 RANSAC)估计最终的相对旋转 R^ 和平移 t^
三、
正则化层——加快神经网络的训练速度
线性层——
torch.reshape是什么东西捏,感觉只能理解一个大概
神经网络搭建:
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2)
self.maxpool1 = MaxPool2d(kernel_size=2)
self.conv2 = Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2)
self.maxpool2 = MaxPool2d(kernel_size=2)
self.conv3 = Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2)
self.maxpool3 = MaxPool2d(kernel_size=2)
self.flatten = Flatten()
self.linear1 = Linear(in_features=1024, out_features=64)
self.linear2 = Linear(in_features=64, out_features=10)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.linear2(x)
return x
tudui = Tudui()
print(tudui)损失函数loss function
现有网络模型的使用与修改:
要多看官方文档)
import torchvision
from torch import nn
# train_data = torchvision.datasets.ImageNet("./data_image_net",spilt='train', download=Ture, transform=trocvision.transforms.ToTensor())
vgg16_false = torchvision.models.vgg16(pretrained=False)
vgg16_true = torchvision.models.vgg16(pretrained=True)
print(vgg16_true)
train_data = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=torchvision.transforms.ToTensor())
#数据集是CIFAR10,然后通过vgg16的模型
#但是vgg16的输出是1000层,所以还要进一步搞成10层的才符合原数据集的分类要求
vgg16_true.add_module('add_linear',nn.Linear(1000,10))
print(vgg16_true)输出结果:
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
(add_linear): Linear(in_features=1000, out_features=10, bias=True)
)
vgg16_true.classifier.add_module('add_linear',nn.Linear(1000,10))通过这个classifier的操作可以把这一步添加到classifier层中而不是单独放出来
直接修改最后一个线性层:
vgg16_false.classifier[6] = nn.Linear(1000,10)
print(vgg16_false)结果:
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=1000, out_features=10, bias=True)
)
)
模型的保存
模型的加载
准确率:

import torch
outputs = torch.tensor([[0.1,0.2],
[0.3,0.4]])
#argmax(1)是横向比较一行,argmax(0)是纵向比较一列
print(outputs.argmax(1))
preds = outputs.argmax(1)
targets = torch.tensor([0, 1])
print(preds == targets)
print((preds == targets).sum())
GPU训练
完整的模型验证套路-》利用已经训练好的模型,然后给他提供输入
注意这里可能的报错,如果记录的是用gpu训练过的,那么在运行的时候要加入cuda的相关内容,
import torch
import torchvision
from PIL import Image
from torch import nn
image_path= "images/dog.png"
image = Image.open(image_path)
print(image)
image = image.convert('RGB')
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),
torchvision.transforms.ToTensor()])
image = transform(image)
print(image.shape)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(in_features=64*4*4, out_features=64),
nn.Linear(in_features=64, out_features=10)
)
def forward(self, x):
x = self.model(x)
return x
model = torch.load("tudui_9.pth",weights_only=False)
print(model)
image = torch.reshape(image,(1,3,32,32))
model.eval()
with torch.no_grad():
output = model(image)
print(output)
也算是学完了,最后开源代码的部分也看一下把