LinearRAG—重新定义GraphRAG:无需关系抽取的线性图构建新范式 -香港理工

摘要
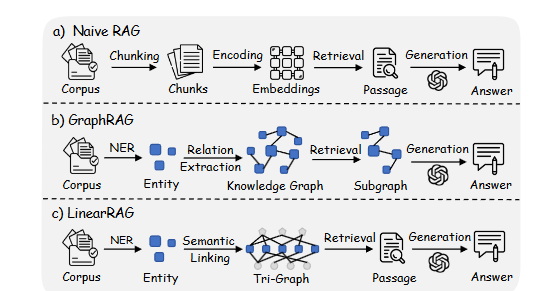
检索增强生成(RAG)被广泛用于通过利用外部知识来减轻大型语言模型(LLMs)的幻觉现象。虽然对于简单查询有效,但传统的RAG系统在处理大规模、非结构化语料库时存在困难,因为信息是分散的。最近的进展结合了知识图谱来捕捉关系结构,使得对复杂的多跳推理任务可以进行更全面的检索。然而,现有的基于图的RAG(GraphRAG)方法依赖于不稳定且成本高昂的关系提取来进行图构建,常常产生含有错误或不一致关系的噪声图,从而降低检索质量。本文重新审视现有GraphRAG系统的流程,并提出了一种高效的框架——基于线性图的检索增强生成(LinearRAG),该框架能够实现可靠的图构建和精确的段落检索。具体来说,LinearRAG仅使用轻量级的实体提取和语义链接来构建一个无关系的层次化图,称为三元图,避免了不稳定的关系建模。这种新的图构建范式与语料库大小线性扩展,并且不会产生额外的标记消耗,从而经济可靠地对原始段落进行索引。在检索方面,LinearRAG采用两阶段策略:(i)通过局部语义桥接激活相关实体,接着(ii)通过全局重要性聚合进行段落检索。在四个数据集上的广泛实验表明,LinearRAG显著优于基线模型。
论文和代码已同步开源,欢迎大家关注和Star⭐:
🔗代码:https://github.com/DEEP-PolyU/LinearRAG
📃论文:https://arxiv.org/abs/2510.10114
核心速览
研究背景
- 研究问题:这篇文章要解决的问题是现有基于图的检索增强生成(GraphRAG)系统在大规模非结构化语料库上的表现不佳。具体来说,这些系统在处理复杂的多跳推理任务时,由于依赖不稳定的关系提取,导致构建的图质量差,进而影响检索质量和生成准确性
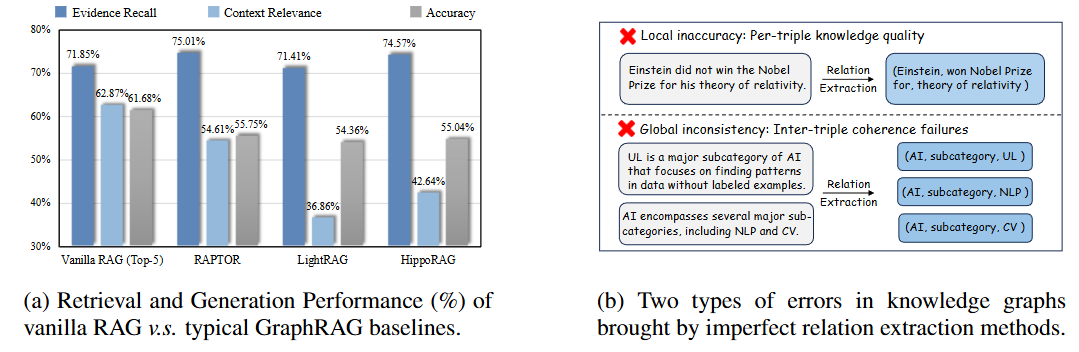
- 研究难点:该问题的研究难点包括:信息分布不均、上下文信息冗长且缺乏组织、关系提取错误率高、全局一致性不足等。
- 相关工作:该问题的研究相关工作有:传统的检索增强生成(RAG)方法、基于图的检索增强生成(GraphRAG)方法(如RAPTOR、Microsoft的GraphRAG、GFM-RAG等)。这些方法虽然在一定程度上提高了多跳查询的处理能力,但仍然存在图构建不稳定、关系提取错误等问题。
研究方法
这篇论文提出了线性基于图的检索增强生成(LinearRAG)框架,用于解决大规模非结构化语料库上的复杂多跳推理问题。具体来说,
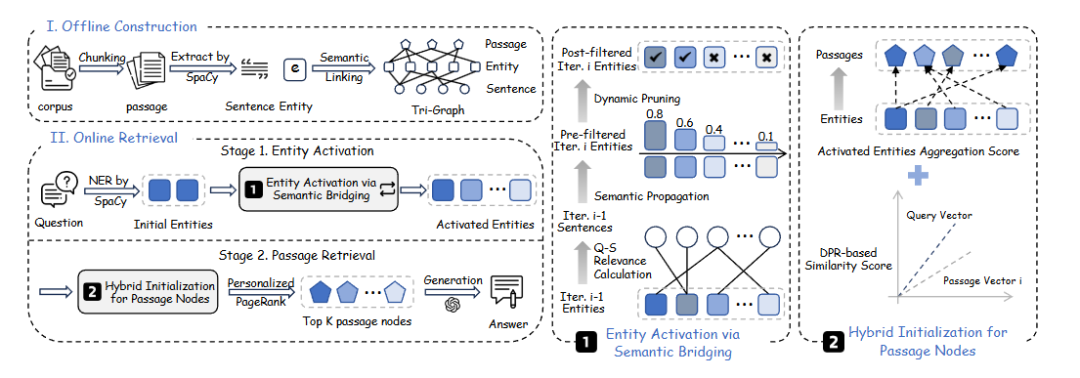
- 线性图构建:LinearRAG通过轻量级的实体提取和语义链接,构建一个无关系的层次图,称为Tri-Graph。该图避免了传统关系建模的不稳定性,并且与语料库大小线性相关,没有额外的token消耗。
- 两阶段检索机制:
- 第一阶段:通过局部语义桥接进行相关实体激活:该阶段通过传播句子中的语义相似性,识别出超越字面匹配的上下文相关实体,挖掘多跳上下文关联。
- 第二阶段:通过全局重要性聚合进行段落检索:在该阶段,对激活的子图应用个性化PageRank算法,从全局角度聚合段落的重要性。
实验设计
- 数据集:实验在四个基准数据集上进行,包括HotpotQA、2WikiMultiHopQA、MuSiQue和GraphRAG-Bench中的Medical数据集。
- 基线方法:比较了多种基线方法,包括零样本LLM推理、传统的RAG方法和现有的GraphRAG方法(如KGP、G-Retriever、RAPTOR等)。
- 评估指标:使用四个指标进行评估,包括端到端QA性能的 Contain-Match准确率(Contain-Acc.)和GPT评估准确率(GPT-ACC.),以及检索质量的上下文相关性和证据召回率。
结果与分析
- 生成准确性:LinearRAG在所有数据集上均优于现有的GraphRAG方法,显著提高了生成准确性和推理能力。例如,在2Wiki数据集上,LinearRAG的GPT评估准确率为63.70%,比第二好的基线高出约3.80%。
效率分析:LinearRAG在索引和检索阶段的时间复杂度和内存消耗均为线性,显著优于复杂的图构建方法(如LightRAG)。例如,LightRAG的索引时间为4,933.22秒,检索时间为10.963秒,而LinearRAG在这些方面几乎没有开销。
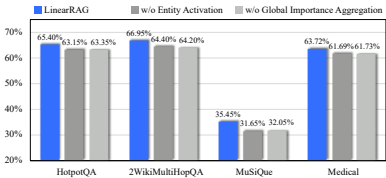
- 消融研究:通过系统性消融研究,验证了LinearRAG中每个组件的贡献。结果表明,相关实体激活和全局重要性聚合两个阶段均对最终性能有显著贡献。
总体结论
这篇论文提出了LinearRAG框架,通过简化图构建过程,利用轻量级实体提取和语义链接,构建了一个高质量的层次图。LinearRAG采用两阶段检索机制,显著提高了复杂多跳查询的检索精度和生成准确性。实验结果表明,LinearRAG在大规模非结构化语料库上具有优越的性能和效率,为实际应用提供了稳健且高效的解决方案。
论文评价
优点与创新
- 线性图构建:提出了LinearRAG框架,通过轻量级的实体提取和语义链接构建无关系的层次图(Tri-Graph),避免了传统关系建模的不稳定性,减少了索引时间超过77%。
- 两级检索机制:设计了结合局部语义桥接和全局重要性聚合的两阶段检索机制,实现了更准确、噪声鲁棒且单次多跳检索。
- 显著性能提升:在四个基准数据集上的广泛实验表明,LinearRAG在检索质量、生成准确性和可扩展性方面一致优于最先进的基线模型。
- 零令牌使用:LinearRAG在整个管道中引入了零令牌使用,避免了LLM在索引和检索阶段的调用,最小化了延迟并消除了令牌成本。
- 高质量图的构建:通过简单的实体提取和语义链接,构建了高质量的图,确保了最小冗余连接,从而提高了检索精度并保留了全面的信息覆盖。
不足与反思
- 局限性:论文中提到,尽管LinearRAG在大多数情况下表现出色,但在某些复杂任务中,如创意生成任务,仍需进一步优化以提高召回率和相关性。
- 下一步工作:未来的研究可以进一步探索如何在不增加计算复杂度的情况下,进一步提高LinearRAG在复杂任务中的性能,例如通过引入更先进的实体提取和语义链接技术。
关键问题及回答
问题1:LinearRAG是如何构建其无关系的层次图(Tri-Graph)的?
LinearRAG通过轻量级的实体提取和语义链接来构建其无关系的层次图(Tri-Graph)。具体步骤如下:
- 句子分割和实体识别:首先,将每个段落分割成句子,并使用命名实体识别(NER)技术提取出实体。
- 构建邻接矩阵:根据实体和句子的关系,构建两个邻接矩阵:
- 包含矩阵C:如果段落包含某个实体,则对应位置为1,否则为0。
- 提及矩阵M:如果句子提到某个实体,则对应位置为1,否则为0。
- 图的构建:通过这两个邻接矩阵,形成一个包含实体节点、句子节点和段落节点的层次图。这种图结构避免了传统关系建模的不稳定性,并且与语料库大小线性相关,没有额外的token消耗。
问题2:LinearRAG的两阶段检索机制是如何设计的?各阶段的详细流程是什么?
LinearRAG的两阶段检索机制包括以下两个阶段:
- 第一阶段:通过局部语义桥接进行相关实体激活
- 初始实体激活:识别查询中包含的实体,并将其在知识图中表示为二进制向量。
- 查询-句子相关性分布:计算查询与每个句子之间的上下文关联,形成相似性向量。
- 语义传播:通过语义相似性提取,传播查询的相似性,激活相关的中间实体,挖掘多跳上下文关联。激活向量通过加权聚合其邻居更新。
- 动态剪枝:为了防止搜索空间过度扩展,引入阈值δ,只有相关性分数超过δ的实体才会被保留,否则被剪枝。
- 第二阶段:通过全局重要性聚合进行段落检索
- 初始化重要性分数:在通道-实体图中,为实体节点和段落节点初始化重要性分数。
- 个性化PageRank:对激活的子图应用个性化PageRank算法,从全局角度聚合段落的重要性。
- 选择top-k段落:根据计算的重要性分数,选择得分最高的top-k段落进行检索。
问题3:LinearRAG在实验中表现如何?与其他基线方法相比有哪些优势?
- 生成准确性:LinearRAG在所有数据集上均优于现有的GraphRAG方法,显著提高了生成准确性和推理能力。例如,在2Wiki数据集上,LinearRAG的GPT评估准确率为63.70%,比第二好的基线高出约3.80%。
- 效率分析:LinearRAG在索引和检索阶段的时间复杂度和内存消耗均为线性,显著优于复杂的图构建方法(如LightRAG)。例如,LightRAG的索引时间为4,933.22秒,检索时间为10.963秒,而LinearRAG在这些方面几乎没有开销。
- 消融研究:通过系统性消融研究,验证了LinearRAG中每个组件的贡献。结果表明,相关实体激活和全局重要性聚合两个阶段均对最终性能有显著贡献。
- 检索质量:LinearRAG在高难度任务(如复杂推理和创造性生成)中表现出色,能够在保持高召回率的同时,显著提高相关性指标。
总体而言,LinearRAG通过简化图构建过程,利用轻量级实体提取和语义链接,构建了一个高质量的层次图,并采用两阶段检索机制,显著提高了复杂多跳查询的检索精度和生成准确性。实验结果表明,LinearRAG在大规模非结构化语料库上具有优越的性能和效率,为实际应用提供了稳健且高效的解决方案。