Elasticsearch各种高级文档操作3
本文来记录几种Elasticsearch的文档操作
文章目录
- 初始化文档数据
- 聚合查询文档
- 概述
- 对某个字段取最大值 max 示例
- 对某个字段取最小值 min 示例
- 对某个字段求和 sum 示例
- 对某个字段取平均值 avg 示例
- 对某个字段的值进行去重之后再取总数 示例
- State 聚合查询文档
- 概述
- 操作实例
- 桶聚合查询文档
- 概述
- terms 聚合,分组统计的示例
- 在 terms 分组下再进行聚合的示例
- 本文小结
初始化文档数据
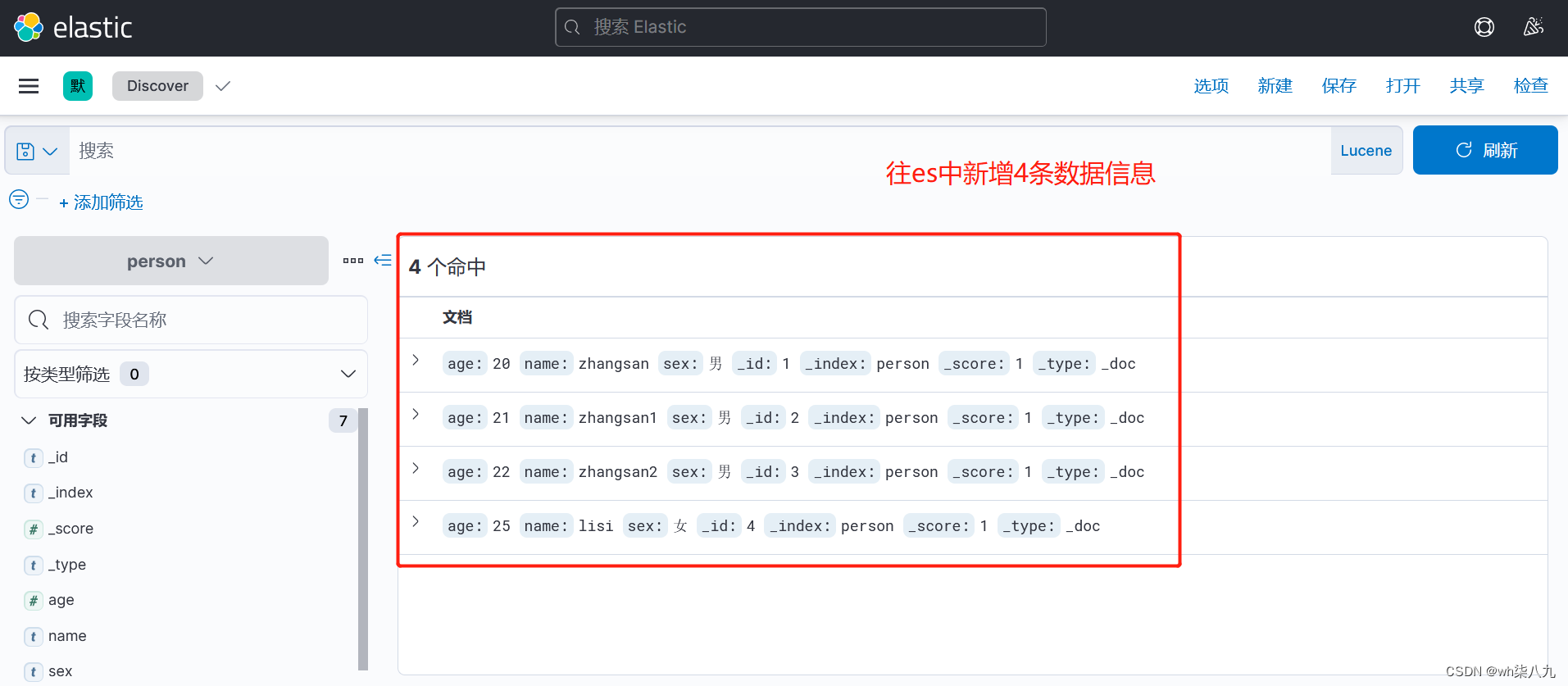
在进行各种文档操作之前,我们先进行初始化文档数据的工作
聚合查询文档
概述
聚合允许使用者对 es 文档进行统计分析,类似与关系型数据库中的 group by,当然还有很多其他的聚合,例如取最大值、平均值等等。
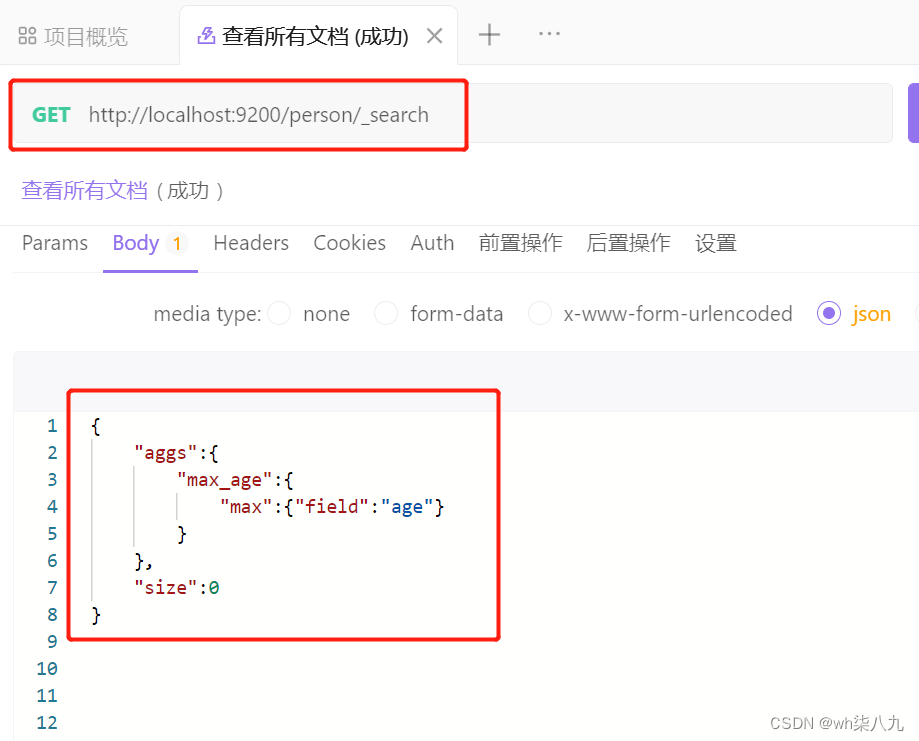
对某个字段取最大值 max 示例
在 apifox 中,向 ES 服务器发 GET请求 :http://localhost:9200/person/_search,请求体内容为:
服务器响应结果
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"max_age": {
"value": 25.0
}
}
}
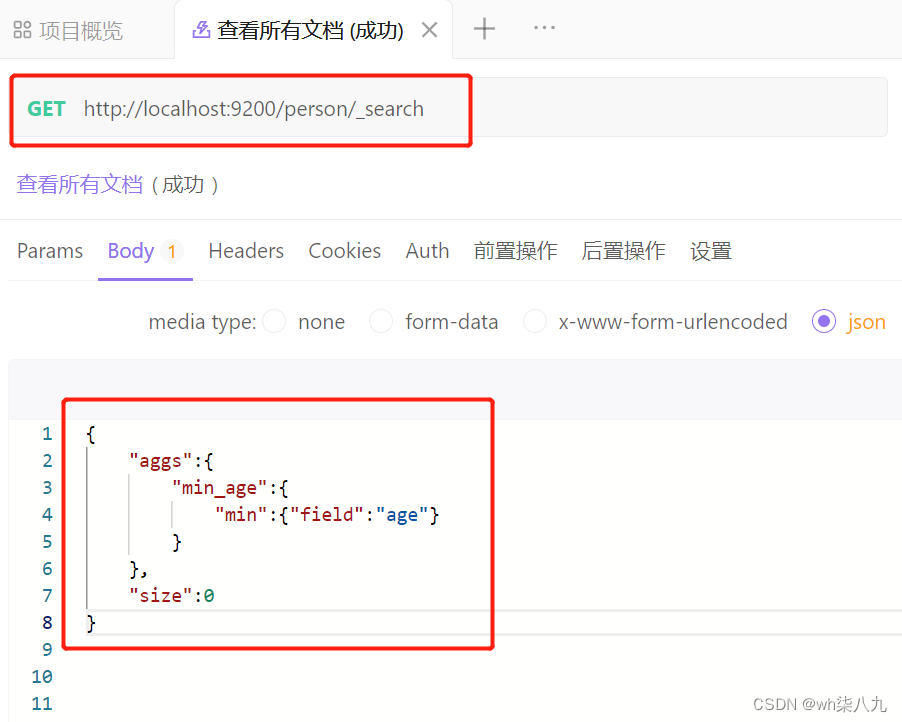
对某个字段取最小值 min 示例
在 apifox 中,向 ES 服务器发 GET请求 :http://localhost:9200/person/_search,请求体内容为:
服务器响应结果
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"min_age": {
"value": 20.0
}
}
}
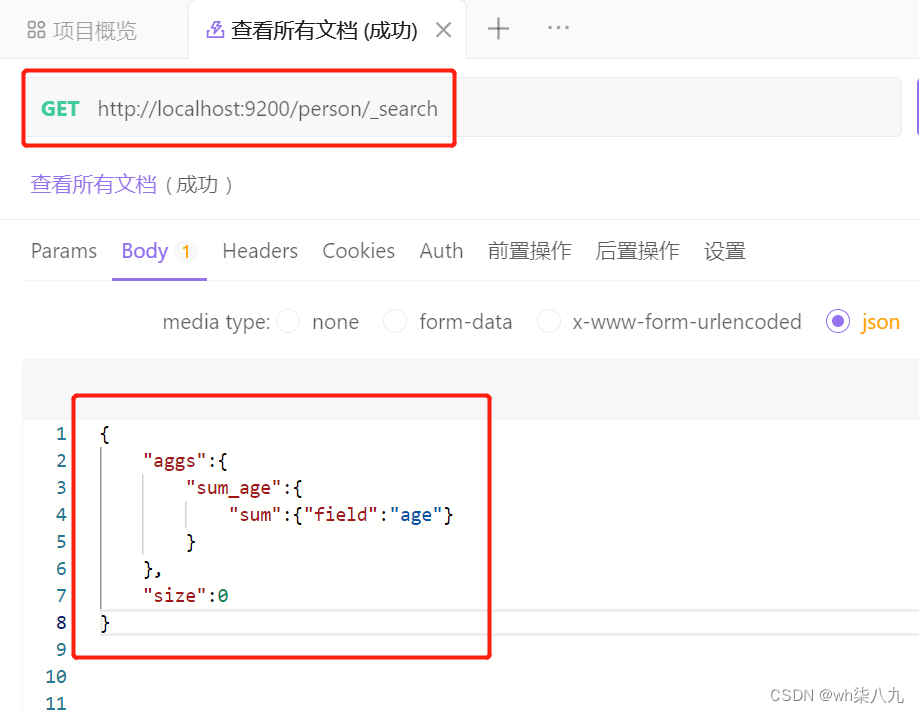
对某个字段求和 sum 示例
在 apifox 中,向 ES 服务器发 GET请求 :http://localhost:9200/person/_search,请求体内容为:
服务器响应结果
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"sum_age": {
"value": 88.0
}
}
}
对某个字段取平均值 avg 示例
在 apifox 中,向 ES 服务器发 GET请求 :http://localhost:9200/person/_search,请求体内容为:
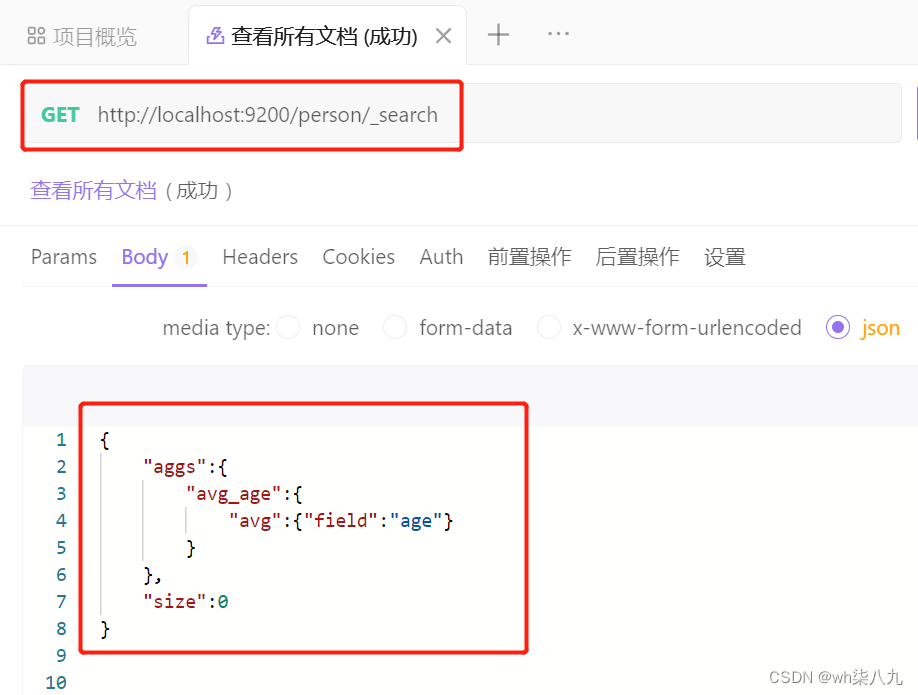
服务器响应结果
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"avg_age": {
"value": 22.0
}
}
}
对某个字段的值进行去重之后再取总数 示例
在 apifox 中,向 ES 服务器发 GET请求 :http://localhost:9200/person/_search,请求体内容为:
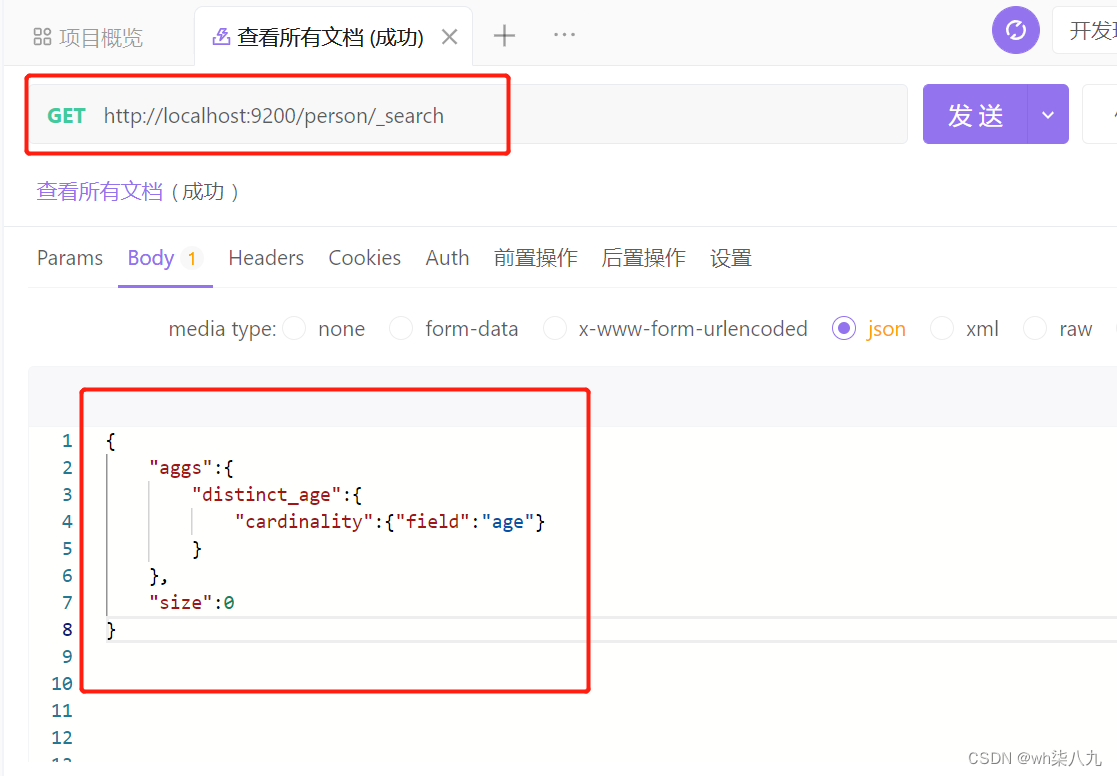
State 聚合查询文档
概述
stats 聚合,对某个字段一次性返回 count,max,min,avg 和 sum 五个指标。
操作实例
在 apifox 中,向 ES 服务器发 GET请求 :http://localhost:9200/person/_search,请求体内容为:
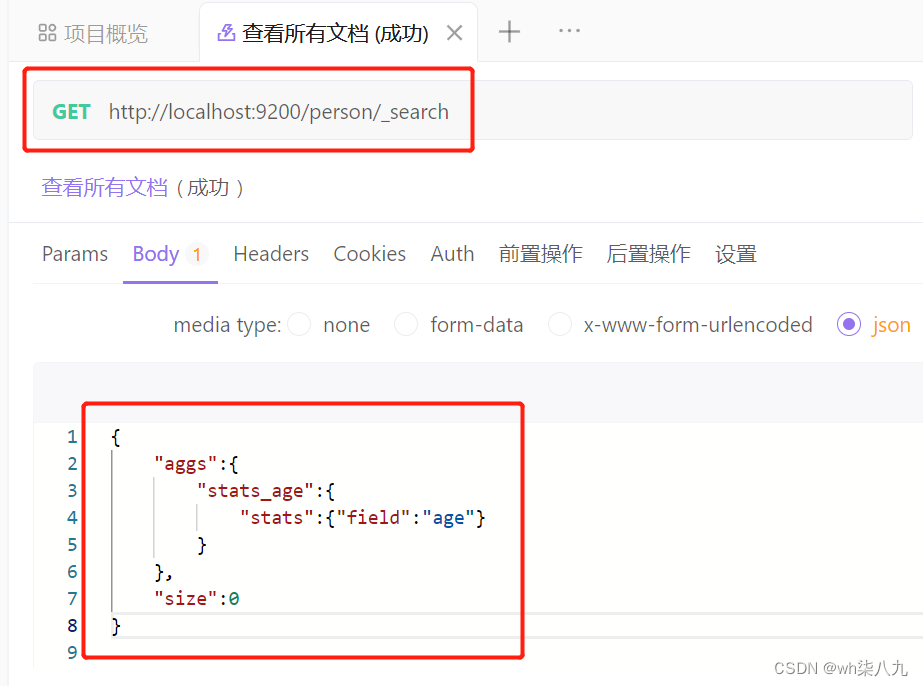
服务器响应结果
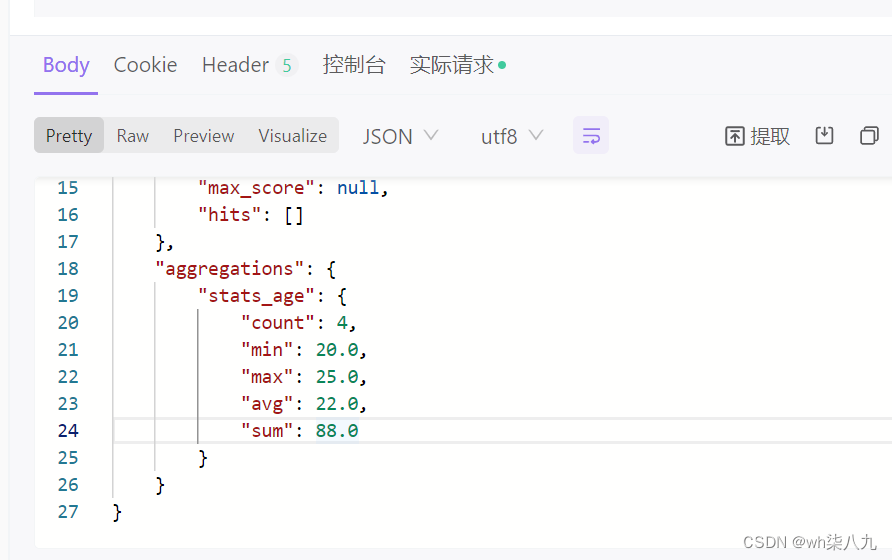
桶聚合查询文档
概述
桶聚和相当于 sql 中的 group by 语句。
terms 聚合,分组统计的示例
在 apifox 中,向 ES 服务器发 POST 请求 :http://localhost:9200/person/_search,请求体内容为:
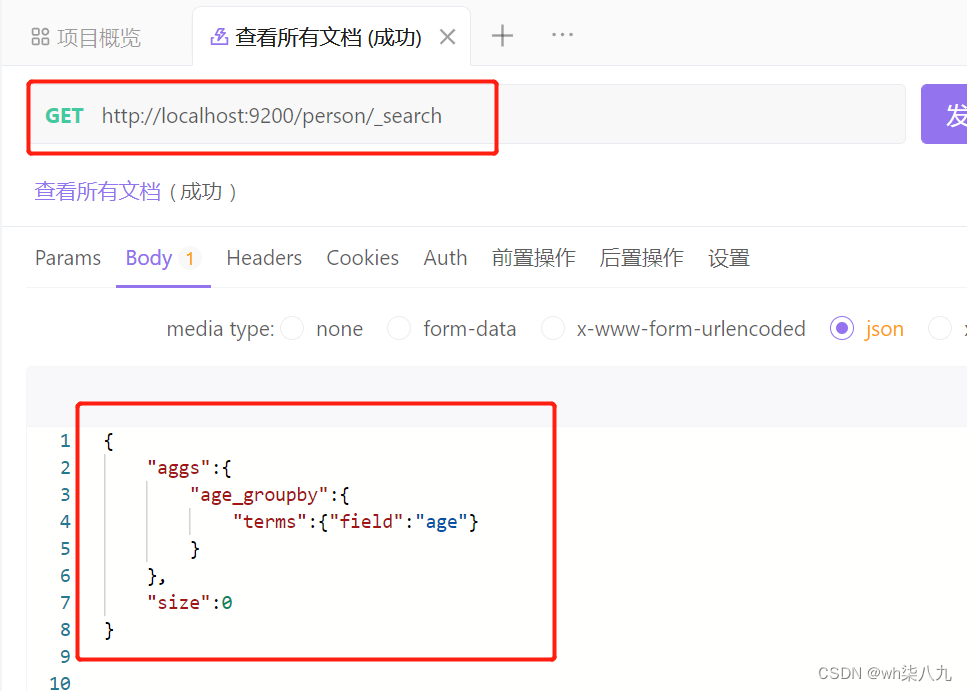
查询成功后,服务器响应结果
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"age_groupby": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 20,
"doc_count": 1
},
{
"key": 21,
"doc_count": 1
},
{
"key": 22,
"doc_count": 1
},
{
"key": 25,
"doc_count": 1
}
]
}
}
}
在 terms 分组下再进行聚合的示例
在 apifox 中,向 ES 服务器发 POST 请求 :http://localhost:9200/person/_search,请求体内容为:
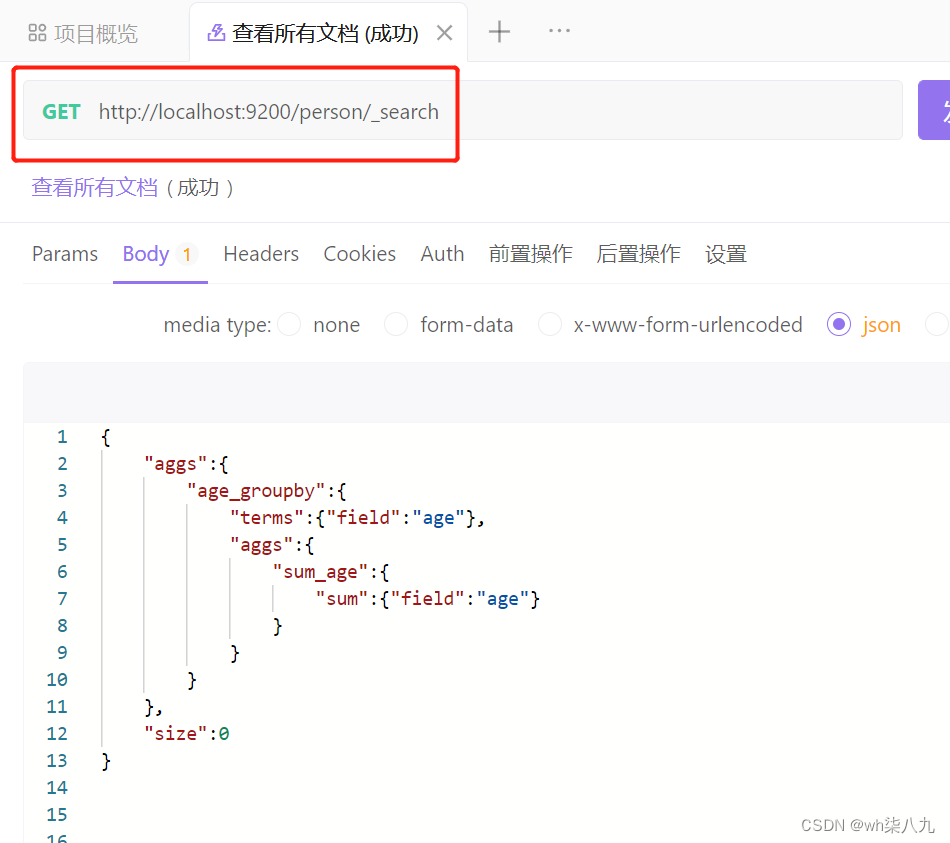
查询成功后,服务器响应结果
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"age_groupby": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 20,
"doc_count": 1,
"sum_age": {
"value": 20.0
}
},
{
"key": 21,
"doc_count": 1,
"sum_age": {
"value": 21.0
}
},
{
"key": 22,
"doc_count": 1,
"sum_age": {
"value": 22.0
}
},
{
"key": 25,
"doc_count": 1,
"sum_age": {
"value": 25.0
}
}
]
}
}
}
本文小结
本文记录了Elasticsearch几种常见的文档操作