Cross-Silo Prototypical Calibration for Federated Learning with Non-IID Data

ACMMM 2023, 针对数据异构问题,提出一种跨孤岛原型校准方法 FedCSPC,通过聚类对数据模式进行建模,通过正样本混合和硬负样本挖掘增加样本多样性,对比学习实现跨源特征对齐。
建议先读《No Fear of Heterogeneity: Classifier Calibration for Federated Learning with Non-IID Data》,是在这基础上改的。
论文:arxiv
代码:github
贡献
-
提出了一种新颖的跨孤岛原型校准方法,以缓解不同客户端之间数据分布异质性的问题。据我们所知,这是第一种能够将来自不同源的异构特征映射到统一空间的方法。
-
提出的 CSPC 模块是对基于客户端方法的正交改进。其即插即用的设计使其易于集成到现有基础设施中,并且在不改变核心组件的情况下增强了泛化能力。
-
本研究揭示了客户端之间不一致的特征空间对联邦模型有效适应所有客户端提出了挑战。我们验证了 FedCSPC 能够有效解决这一问题。
总结一下就是:(1)第一个将多客户端特征映射到同一空间,(2)多中心聚类(kmeas)得到多个原型特征,采样出更多原型,(3)特征内推和外插,生成正样本难样本,对比算法校准,(4)生成知识原型,用最近距离判断类别
动机
这篇文章的动机分析不是很明确,就说是数据异构,写的很泛。
算法流程
分成客户端和服务端两部分。具体流程和NIPS2021的那篇CCVR一样。客户端用全局原型和标签计算损失,将聚类原型和模型传到server。服务端呢(默认结合FedAvg,聚合全局模型)插值原型得到更多的原型,经过投影层映射到同一空间,用伪标签对比学习对齐特征(仅更新投映+分类层),将更新后的全局模型(特征提取层,单纯靠聚合得到)和全局原型(重复采样再平均得到)发送客户端。
PS:这里需要注意的是,模型分成特征提取器和分类器(投影层+预测层)两部分。全局更新时其中特征提取器单纯靠聚合实现(结合fedavg的时候),用原型来训练分类器。
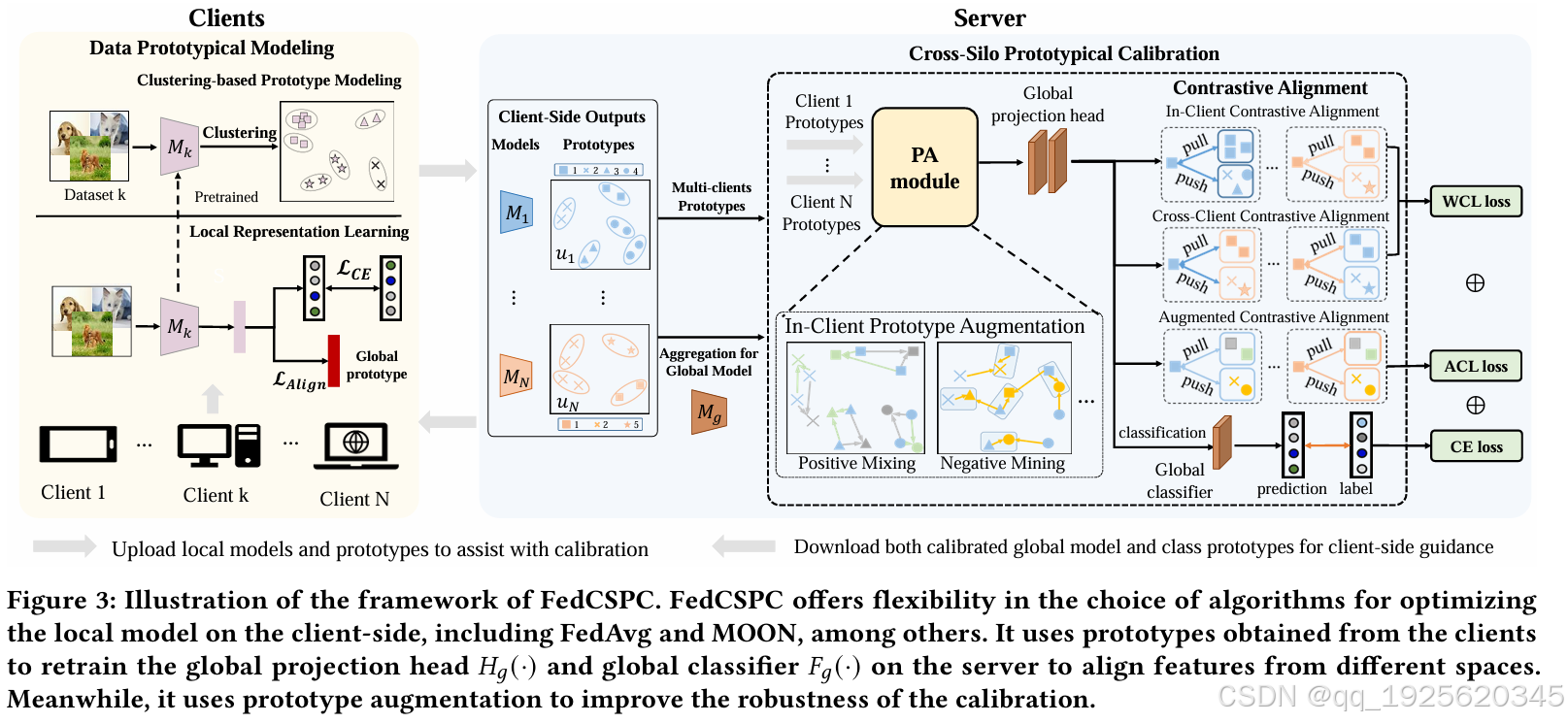
DataPrototypical Modeling (DPM) module
数据原型建模(DPM)模块。如下图所示,本地阶段改进有两个方面,一个是和原型的损失定义为点、角、线三个,其中 点损失用的是对比学习的方法(类似三元组损失),角和线损失则是和全局原型对应的L1\L2损失。这里公式中, f f f 表示本地提取的原型特征, u g + u_g^+ ug+ 和