模型蒸馏实战qwen2.5系列模型
一.知识蒸馏的两种方式
1.黑盒知识蒸馏
使用大模型生成数据,通过这些数据去微调更小的模型,来达到蒸馏的目的。缺点是蒸馏效率低,优点是实现简单。例如论文Distilling the Knowledge in a Neural Network大概步骤以及架构请点击
2.白盒知识蒸馏
获取学生模型和教师模型的输出概率分布(或者中间隐藏层的概率分布),通过kl散度(相对熵)将学生模型的概率分布向教师模型对齐。
为什么使用kl散度:
KL散度专门用于衡量两个概率分布之间的差异,能够细致地捕捉到分布的每一个部分的差异,在知识蒸馏中,我们更关心的是两个概率分布(教师模型和学生模型的输出)之间的相似度。而交叉熵损失主要用于衡量预测分布与真实标签之间的差异。
前向kl散度:
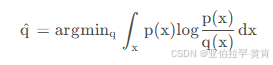
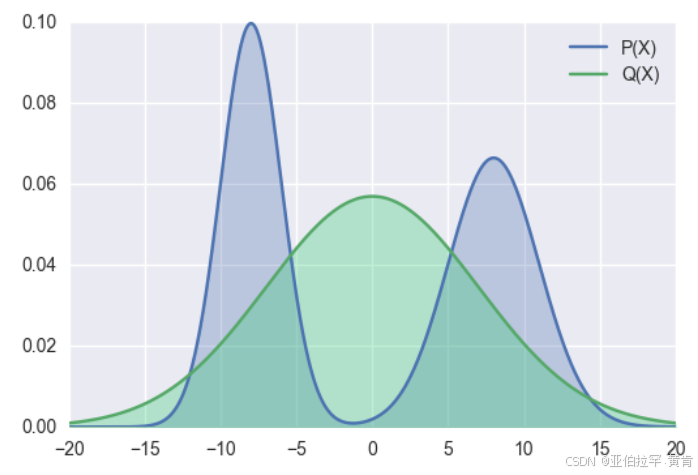
p为教师模型的概率分布,q为学生模型的概率分布,Minillm论文中提到前向kl散度可能会使学生模型高估教师模型中概率比较低的位置,结合公式来看,当p增大时,为了使得kl散度小,则q也需要增大,但是当p趋于0时,无论q取任何值,kl散度都比较小,因为此时p(x)log((p(x)/q(x)))的大小主要受p(x)控制,这样起不到优化q分布的效果,可能会使q分布高估p分布中概率低的位置。 下图展示了前向kl散度的拟合情况:
反向kl散度:
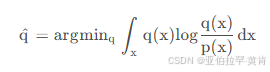
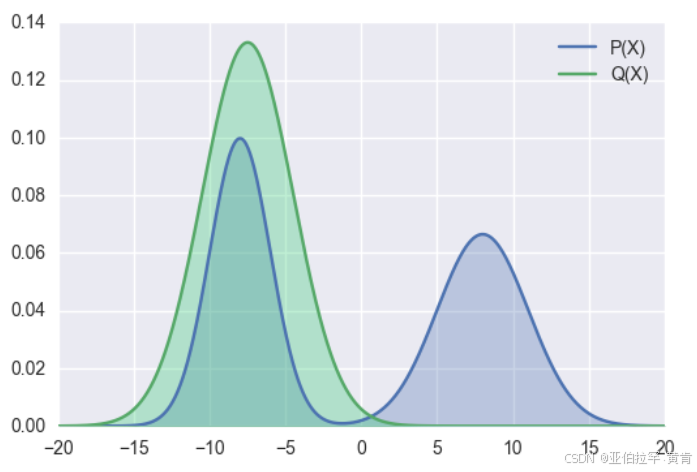
p为教师模型的概率分布,q为学生模型的概率分布,当p趋于零时,为了使kl散度小,q也需趋于0。 Minillm论文中说对于大模型的知识蒸馏,反向kl散度优于前向kl散度,但是也有其他论文说反向kl散度不一定比前向kl散度更优。以实际选择为准。
二.实操
参考链接中使用的是私密数据集,并且试验结果表明:不微调模型并且使用前向KL散度的效果最好。
我为了复现找了开源的数据集进行尝试:
参考链接:https://github.com/wyf3/llm_related/tree/main/knowledge_distillation_llm
https://www.bilibili.com/video/BV1kQcoetEFM/?spm_id_from=333.1387.upload.video_card.click&vd_source=5cd9b442f08018f3dc856d0a91e9cab0