内存回收异常导致OOM的问题
生产环境中(Quarkus服务)偶尔出现过一次服务的其中一个pod的Old Gen持续增长直至被K8S重启,本文是对此问题分析过程的总结。
类似问题参考
阿里云开发者: JDK11升级后竟让内存利用率飙升到90%以上?
原因是升级JDK11并且将垃圾回收器由CMS更换到G1之后,非堆内存中G1的记忆集占用了比较大的内存。
G1 GC 将堆分为多个Region,当进行 Young GC 或 Mixed GC 时,G1 需要知道哪些老年代对象引用了年轻代对象。由于完整扫描整个堆的成本太高,G1 通过记忆集(RSet)记录哪些 Region 内的对象被其他 Region 引用。
记忆集本质上是一个哈希表或位图(Bitmap) 结构,用于记录跨 Region 的引用信息。根据经验,记忆集占用堆内存的5%-20%,具体取决于跨区引用的多少。
下面展示了一个16GB的堆内存的记忆集在不同JDK下占用堆外内存的大小:
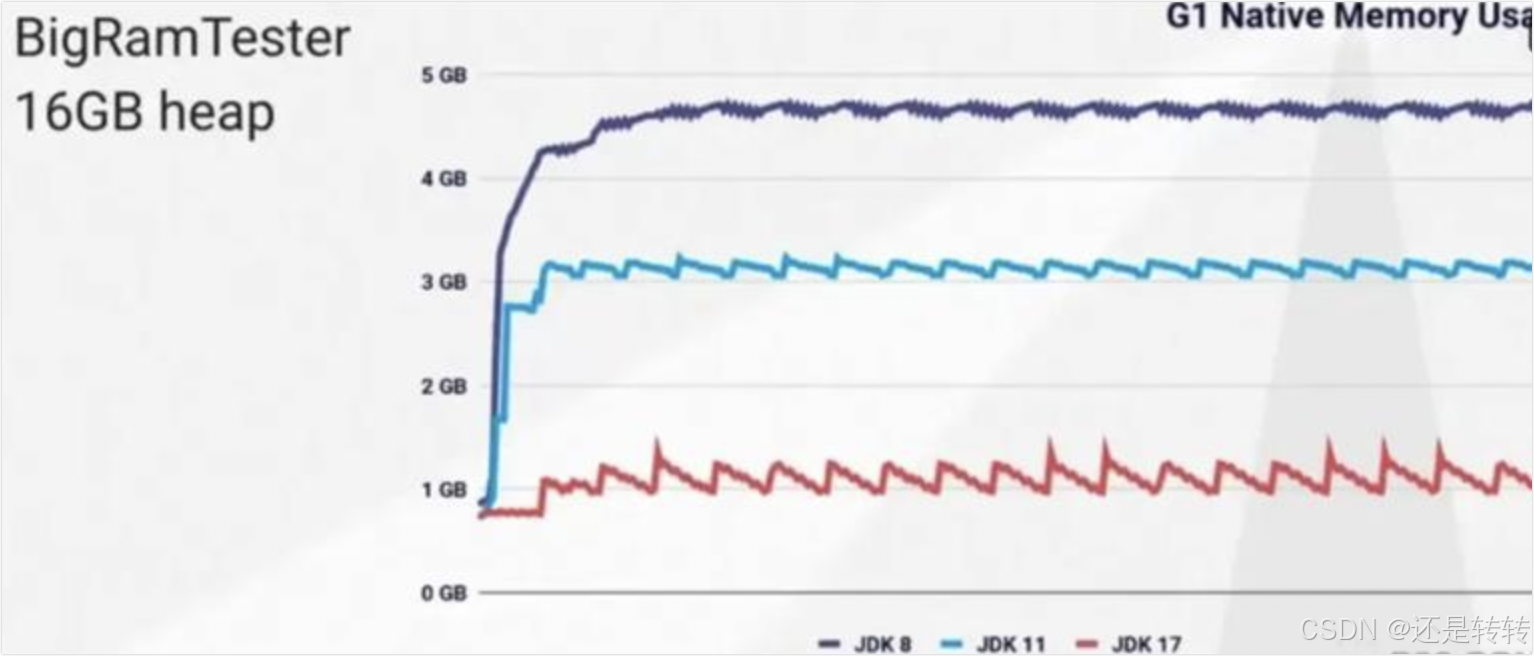
在这个案例中,对于16G内存的服务器,12g 堆内存 + 2.25g记忆集 + 700m 的全局内存 + 非堆内存 ≈ 16g,直接就把整个机器的内存占用满了。
最终选取的解决方案是缩小堆内存,降低内存利用率(代价是提高GC频率)。
阿里云开发者:记一次内存利用率问题排查
原因是升级JDK11之后,堆外内存管理策略发生了变化,会将commited的部分内存加载给应用使用。
具体来说,就是在JDK8之前,堆外内存DirectByteBuffer通过finalize()方法调用freeMemory()释放直接内存(但这种方式其实效率很低,容易引起堆外内存的OOM),在JDK9 之外进行了优化,为DirectByteBuffer分配了Cleaner,提升堆外内存回收效率。但相应地,Cleaner本身也是有内存占用的。
在本案例中,就是升级JDK之后,由于直接内存的管理方式发生了变化,导致堆外内存占用提升了400MB左右导致的。
生产环境情况
上述两个案例都是由于升级JDK到11版本,从而导致堆外内存占用升高。
而当前生产环境使用了JDK17,与上述两个问题的JDK版本是不一样的。同时根据Grafana检测指标看到,堆外内存使用一直保持在较低水平,不存在堆外内存问题。上述案例没有参考意义。
G1 GC 原理
G1将内存切分成一个个Region区,同时各个Region又分为新生代(Eden、Survior区)、老年代,如下图。Region的空间大小是按整个JVM内存大小计算的,G1最多可以有2048个Region,并且大小必须是2的倍数,即4G内存实际分配Region的是2M,8G内存实际分配Region的是4M。
对于最大1.75G的堆内存,每个region大小则为:1.75/2048=0.875MB~1MB。
直接在pod中查看堆内存信息(kubectl exec -it <pod_name> – jcmd GC.heap_info)如下:
garbage-first heap total 1499136K, used 1045419K [0x0000000090000000, 0x0000000100000000)
region size 1024K, 596 young (610304K), 3 survivors (3072K)
Metaspace used 116890K, committed 117440K, reserved 344064K
class space used 13522K, committed 13824K, reserved 212992K
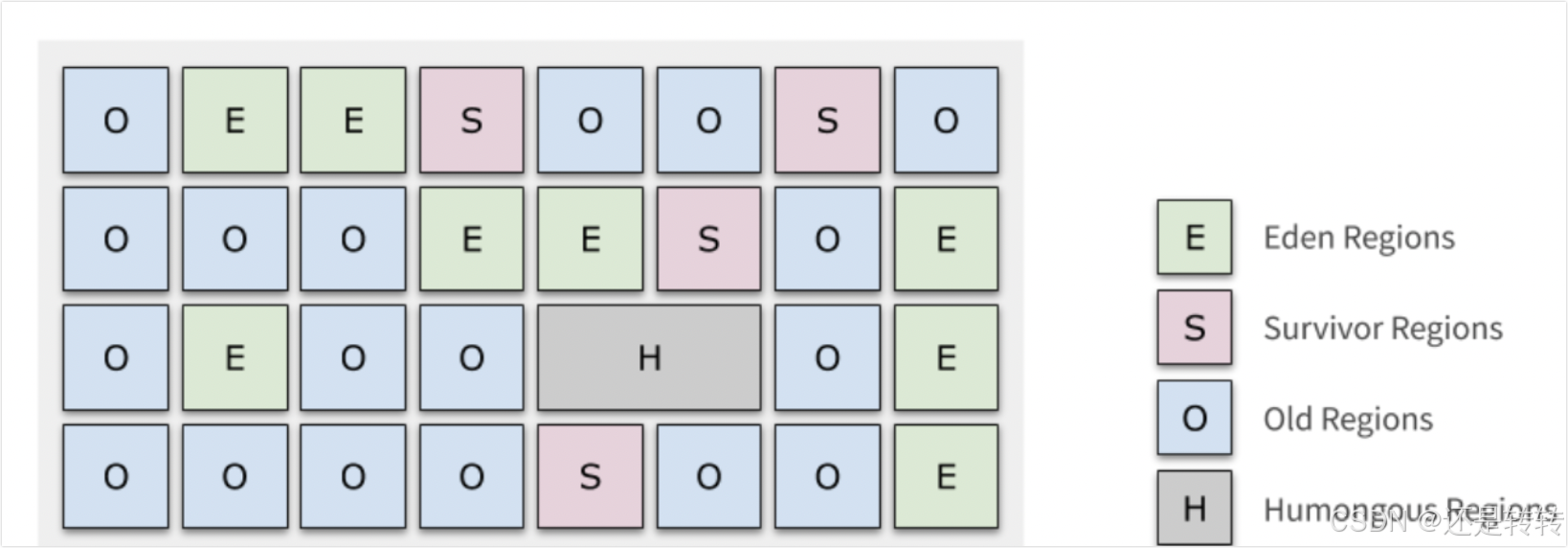
当一个对象大小超过Region的一半时,则该对象定义为大对象,大对象不会在新生代分配空间,而是直接在老年代的Humongous区存放这些大对象,且当一个Humongous区的Region放不下大对象时,则G1会分配连续的Region作为Humongous区来存储大对象。
对于G1垃圾回收器的GC,Minor GC对完整的新生代空间执行扫描和对象回收,而Mixed GC则相对复杂一些,Mixed GC除了完整的新生代以外,还会对老年区少数Region区执行对象回收。
为了让Mixed GC执行时选择老年区中垃圾回收率尽可能高的Region区从而提高GC效率,G1为此提供了并发标记。该并发标记也就是G1为人所熟知的初始标记、并发标记、最终标记、存活对象计数、收尾工作周期,并发标记本身不会执行对象回收,仅在收尾工作步骤对老年区中没有存活对象的Region执行清理释放。
通过执行并发标记,G1可以获取到老年区每个Region的存活对象的比例,从而在Mixed GC时选择其中垃圾回收率高的Region。
并发标记的触发时机受到以下条件限制:
- 并发标记结果已经使用完(默认一次并发标记后发生8次Mixed GC,参数G1MixedGCCountTarget指定)
- 老年区已使用空间/整个堆空间达到阈值(默认45%,由参数InitiatingHeapOccupancyPercent指定)
G1一个有意思的Bug JDK-8140597。当G1分配大对象前会检查当前是否满足并发标记触发条件,如果条件满足则触发并发标记周期,而该Bug导致由大对象分配引起的并发标记会中断Mixed GC操作。该场景下频繁地创建大对象会导致Mixed GC执行始终被中断,从而引起老年区空间耗尽。此bug已经在JDK9中被修复。
业务 Pod GC 分析
从 Grafana监控Prometheus指标来看,有如下结论:
- Humongous allocation 很低
- Old Gen 占用非常高。
- Major GC(Full GC)有执行,但耗时很长,且Old 区并没有回收掉。
GC日志分析
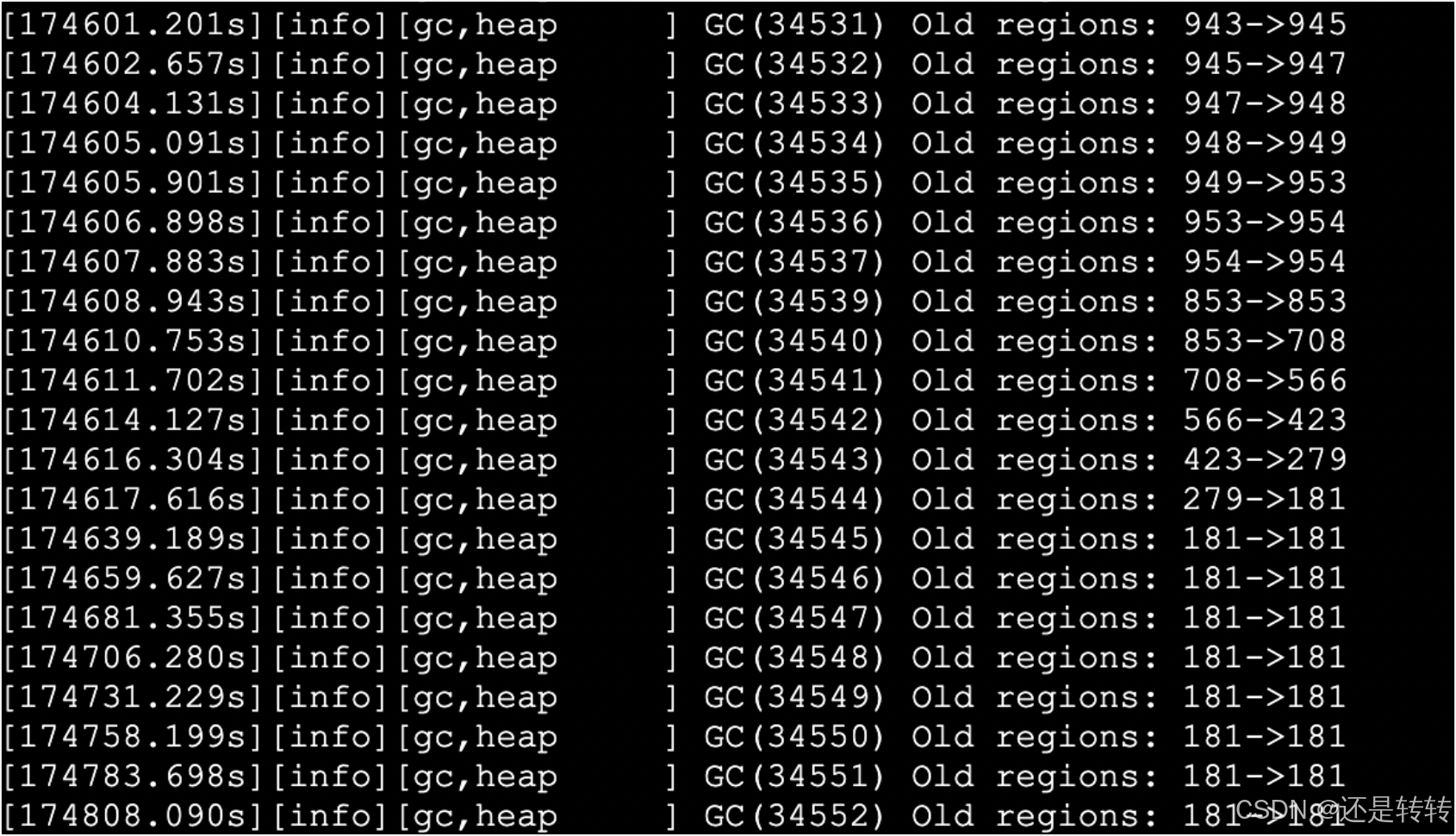
挑选一个内存使用率较高的 pod 分析,其region使用趋势如下:
[229130.619s][info][gc,heap ] GC(37634) Eden regions: 852->0(849)
[229130.619s][info][gc,heap ] GC(37634) Survivor regions: 7->9(108)
[229130.619s][info][gc,heap ] GC(37634) Old regions: 428->428
[229130.619s][info][gc,heap ] GC(37634) Archive regions: 0->0
[229130.619s][info][gc,heap ] GC(37634) Humongous regions: 14->14
[229340.161s][info][gc,heap ] GC(37661) Eden regions: 853->0(848)
[229340.161s][info][gc,heap ] GC(37661) Survivor regions: 3->8(107)
[229340.161s][info][gc,heap ] GC(37661) Old regions: 430->430
[229340.161s][info][gc,heap ] GC(37661) Archive regions: 0->0
[229340.161s][info][gc,heap ] GC(37661) Humongous regions: 14->14
[229573.134s][info][gc,heap ] GC(37691) Eden regions: 859->0(847)
[229573.134s][info][gc,heap ] GC(37691) Survivor regions: 3->10(108)
[229573.134s][info][gc,heap ] GC(37691) Old regions: 432->432
[229573.134s][info][gc,heap ] GC(37691) Archive regions: 0->0
[229573.134s][info][gc,heap ] GC(37691) Humongous regions: 14->14
[229866.218s][info][gc,heap ] GC(37727) Eden regions: 849->0(843)
[229866.218s][info][gc,heap ] GC(37727) Survivor regions: 7->10(107)
[229866.218s][info][gc,heap ] GC(37727) Old regions: 434->434
[229866.218s][info][gc,heap ] GC(37727) Archive regions: 0->0
[229866.218s][info][gc,heap ] GC(37727) Humongous regions: 14->14
[230029.281s][info][gc,heap ] GC(37748) Eden regions: 838->0(841)
[230029.281s][info][gc,heap ] GC(37748) Survivor regions: 9->8(106)
[230029.281s][info][gc,heap ] GC(37748) Old regions: 436->436
[230029.281s][info][gc,heap ] GC(37748) Archive regions: 0->0
[230029.281s][info][gc,heap ] GC(37748) Humongous regions: 14->14
...
[231947.644s][info][gc,heap ] GC(37987) Eden regions: 839->0(840)
[231947.644s][info][gc,heap ] GC(37987) Survivor regions: 3->3(106)
[231947.644s][info][gc,heap ] GC(37987) Old regions: 452->452
[231947.644s][info][gc,heap ] GC(37987) Archive regions: 0->0
[231947.644s][info][gc,heap ] GC(37987) Humongous regions: 14->14
另一台内存占用稍低的GC日志情况如下:
[232545.325s][info][gc,heap ] GC(42599) Eden regions: 453->0(462)
[232545.325s][info][gc,heap ] GC(42599) Survivor regions: 11->4(58)
[232545.325s][info][gc,heap ] GC(42599) Old regions: 377->377
[232545.325s][info][gc,heap ] GC(42599) Archive regions: 0->0
[232545.325s][info][gc,heap ] GC(42599) Humongous regions: 14->14
从以上gc日志中可以看到:
- 两个pod内存占用不一样主要是 Eden regions 导致的
- Eden region 每次GC后被清空
- Old regions 一直在增长,几乎每分钟增长1个region,且不会被回收掉。
- Humongous regions 数量很少且保持不变
说明以下几个问题:
- 业务pod内存的增长主要是因为 Eden regions一直在增长。
- Minor GC 很正常,但 Eden region 被清空后,Old region 达不到 IHOP 45%的标准, Mixed GC一直未触发,导致Old region没有被GC。
是否老年代在pod的整个生命周期内都不会被回收呢?
从GC日志可以看出,当Old regions使用达到954MB之后,IHOP 45%的阈值触发,mixed gc开始执行:
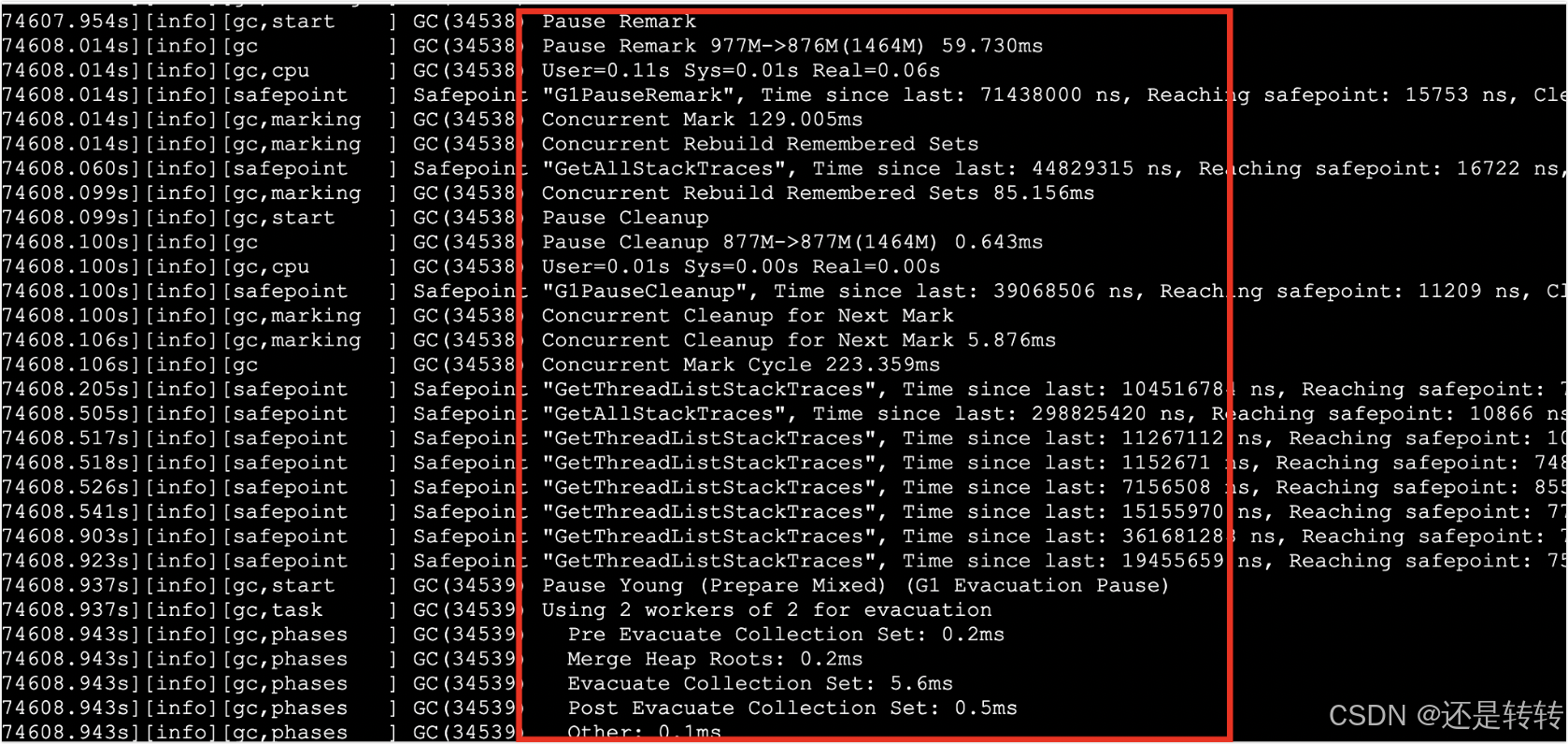
也就是说,老年代是可以回收的,但回收的时间点有点晚。
GC本身可能存在的原因
G1 老年代碎片化,影响回收效率
G1 GC 采用 Region 方式管理堆内存,如果老年代的 Region 变得高度碎片化,G1 可能 无法有效合并和回收,导致老年代持续增长,即使对象已经被标记为可回收。老年代碎片化还会导致 Full GC(Major GC)时 无法高效移动对象,拖慢 GC 速度。
G1 的碎片率默认值为 5%,正常情况下无须调整。
G1 Mixed GC 触发太晚,老年代累积
G1 的 Mixed GC 负责回收老年代,但如果 Mixed GC 触发太晚,老年代会 持续积累,最终触发 Major GC。
InitiatingHeapOccupancyPercent 默认值为45。从GC日志分析看,Old Gen 使用达到了900M的时候才触发 GC,确实比较晚。
GC 线程竞争,影响 GC 效率
G1 需要大量线程来处理 并发标记、Mixed GC 和老年代回收,负载较高的系统,GC 线程可能和应用线程竞争 CPU 资源,导致 GC 耗时变长,GC运行速度跟不上对象分配。
出现问题的时间是凌晨期间而非高峰期,正常情况下不存在线程不足或CPU资源竞争问题,除非 node 节点有问题。
Old Region 里对象存活率过高
G1 Mixed GC 只会回收存活率低的 Old Regions,如果老年代对象存活率高,G1 可能无法回收足够的内存,最终导致 Full GC。
从GC看,只要Mixed GC触发,老年代就能被回收掉,不是此原因导致的。
业务方面其他可能的原因
Metric指标
在 Micrometer 监控库中,可以使用 Counter 记录指标,如:
metrics.counter(
"XX_COUNTER",
"status_code", String.valueOf(statusCode),
"method", method,
"path", path,
"xx_Tag", xx
).inc();
每个counter指标由指标名称和标签组合唯一确定。标签组合不同时,会创建独立的counter实例。
所有counter实例由 MeterRegistry 管理,通常存储在ConcurrentHashMap中。其中,key为"指标名称 + 标签"键值对的哈希,值为Counter对象,内存维护一个double类型的计数值。
Counter对象在应用运行期间常驻内存。Prometheus通过HTTP端点周期性拉取数据。
内存消耗分析
每个Counter对象约占用32-64字节(取决于JVM实现和对象头压缩)。每个标签键值对约占用20~40字节。单个Counter实例占用内存为100~200字节。占用的总内存约为:Counter实例数 x 单个实例内存 + 标签哈希表开销。
在业务metrics中,只有业务标签和状态标签是变化的,其他标签值基本固定。因此Counter实例总个数与(xx_Tag, status)数量相当。
业务标签xx_Tag数量约为3000,statusCode数量基本为1。因此Counter实例数量大约为3000左右。按 200 字节 x 3000 算,占用内存约 600KB。忽略不计。
关于netty相关的JVM参数设置
对于下列参数:
-Dio.netty.tryReflectionSetAccessible=true --add-opens=java.base/jdk.internal.misc-ALL-UNNAMED --add-opens=java.base/java.nio=ALL-UNNAMED
主要用于解决 Java 9 及更高版本中模块化带来的封装限制,确保 Netty 能够通过反射访问 JDK 内部 API。
具体来说是跟Netty的两个特性有关。
第一个是默认情况下,JDK 在分配直接 ByteBuffer 时,会为每个 ByteBuffer 关联一个 Cleaner 对象,以便在缓冲区不再使用时自动释放内存。但 Cleaner 本身会占用额外内存,并且在垃圾回收时会带来额外的开销。通过启用 -Dio.netty.tryReflectionSetAccessible=true 和 --add-opens=java.base/java.nio=ALL-UNNAMED 参数,Netty 能够直接访问 JDK 内部的 API,从而分配直接缓冲区而不依赖 Cleaner,这样可以节省内存并降低垃圾回收压力。
上文中第二个内存利用率问题排查就是涉及到这个点。
第二个是为了安全性,JDK 在分配 byte[] 数组时会将其初始化为零,这会带来一定的性能开销。当数组足够大(默认大于 1024 字节)时,这种初始化成本会变得明显。通过启用隐藏特性(依赖于 --add-opens=java.base/jdk.internal.misc=ALL-UNNAMED),Netty 可以绕过这个零初始化的过程,从而提高性能。但这同时意味着你必须确保数据安全,因为数组中原本的内存内容可能会残留。
没有额外配置时:JVM 的直接内存限制默认与堆内存大小相同,因此容器需要预留 2 倍于最大堆的内存(堆内存 + 直接内存)。
使用上述配置后:Netty 使用 Unsafe 直接分配内存,并自行管理和限制这些内存;同时 JDK 内部的 NIO 直接内存分配则单独被 OpenJDK 追踪。这样,理论上容器需要预留的总内存可能会达到最大堆的 3 倍(堆内存 + NIO 直接内存 + Netty 直接内存),但 Netty 提供了内存指标监控,使得你可以跟踪其分配情况。
优缺点的权衡:
- 优点:绕过 Cleaner 后,NIO ByteBuffers 的分配更加高效,节省内存;同时,绕过零初始化可以提高大数组的分配性能。
- 缺点:总内存需求会增加,因为 JDK 和 Netty 分别对直接内存进行管理,且 JVM 自身不再报告全部内存分配情况(需要依赖 Netty 的指标);如果不仔细监控,可能导致容器内存超限,进而引发 OutOfDirectMemoryError 或应用变得无响应。
这几个参数涉及的是堆外内存的管理和使用,但在GC异常的pod中,异常原因是 Old Gen 没有回收的问题,属于堆内存异常。
静态代码分析
常用的静态代码分析工具有 FindBugs、SonarQube、Infer (Facebook,静态分析内存泄漏和资源泄漏)。
不幸的是,Infer对于maven项目似乎有很多bug导致在业务项目中不可用。
SonarQube检测结果无异常,FindBugs 静态代码检测结果无异常。
分析总结
GC异常是在业务基本没流量的凌晨时间发生,且在此期间其他pod均正常运行,不存在是临时高负载或特定场景触发内存峰值。
GC异常的pod在重启后正常运行。这种GC异常的现象是偶然的,不可复现的。
如果上述任意一个可能的原因导致了GC异常,那么这种情况应该是非偶然的,可持续观测的。
由于异常pod很快被重启,没有日志,也没有更完善的监控方式,因此无法进一步分析问题。不排除是云服务商机器本身的硬件异常导致的。
从上文分析来看,业务本身没有明显的问题,唯一可能会有影响的是Mixed GC触发时间太晚,但理论上来讲也不会导致老年代GC不掉的情况。
后续优化方案
后续可能的优化方案:
固定现场
当pod内存异常时,手动隔离pod、持久化gc日志以便后续分析,或者生成持久化 Heap Dump 文件以便分析。
jvm参数优化
- 调小
InitiatingHeapOccupancyPercent参数值(45->30),以提升Old GC的频率。 - 调大
InitialRAMPercentage参数值(25->50),因为pod扩容时负载通常较高,较小的初始内存会导致初始频繁的Minor GC,并且很快就要扩展堆内存。
使用ZGC
ZGC可以让JVM将不使用的内存归还给操作系统,降低内存使用率。但可能并不使用堆内存较小的应用。
ZGC适合的场景:
- 低延迟应用(要求GC停顿时间 < 1 ms)
- 大内存应用(推荐用于 >8GB 堆内存的应用)
- 云环境,需要更快释放未使用内存
G1 更适合的场景:
- 中小型堆( < 8GB),G1 仍然表现良好
- 长时间运行的后台服务,G1 的吞吐量更好
参考资料
[1].https://www.zhaohuabing.com/istio-guide/docs/common-problem/envoy-stats-memory/
[2].https://developer.aliyun.com/article/1653000
[3].https://developer.aliyun.com/article/1654331
[4].DeepSeek && ChatGPT