DEADiff
文章目录
- 摘要
- abstract
- DEADiff
- 摘要
- 简介
- 方法
- 风格和语义解耦
- 双解耦表示提取
- 解缠条件作用机制
- 实验
- 结论
- 总结
- 参考文献
摘要
本周学习了一种高效的风格化文本到图像生成模型DEADiff,旨在解决现有方法中参考图像引入风格信息时对文本可控性造成干扰的问题。该方法通过双重解耦表示提取机制(DDRE)从参考图像中分离提取风格和语义特征,并引入解纠缠条件作用机制,分别将风格与语义注入扩散模型中不同的交叉注意层,提升风格迁移与文本语义对齐的效果。此外,利用成对合成图像构建非重构训练范式,使模型在保持风格表达的同时强化对文本语义的响应能力。实验结果显示,DEADiff在风格相似性、图像质量、文本一致性和语义保持性方面均优于现有方法,实现了文本驱动与风格指导之间的有效平衡。
abstract
This week, we learned DEADiff, an efficient model for stylized text to image generation, which aims to solve the problem of text controllability interference caused by introducing style information to reference images in existing methods. In this method, a dual decoupling representation extraction (DDRE) mechanism is used to separate the extracted style and semantic features from the reference images, and a deentanglement conditioning mechanism is introduced to inject the style and semantics into different cross-attention layers in the diffusion model to improve the effect of style transfer and text semantic alignment. In addition, a non-reconstruction training paradigm is constructed by using pairings of composite images to enhance the model’s responsiveness to text semantics while maintaining style expression. The experimental results show that DEADiff is superior to the existing methods in terms of style similarity, image quality, text consistency and semantic retention, and achieves an effective balance between text-driven and style-directed.
DEADiff
摘要

文本可控性是文本到图像生成模型中的一个核心概念,是指模型根据输入的prompt准确生成对应图像的能力。其主要来源于两个原因:
- 编码器提取的是风格与语义相结合的信息,而非单纯的风格特征(以往的方法编码器中缺乏有效的机制来区分图像风格和图像语义),图像语义和文本条件中的语义不可避免地会冲突,导致文本可控性减弱。
- 以往地编码器的学习过程视为重建任务,其中参考图的ground-truth就是图像本身,在重建任务下,模型更倾向于关注参考图,从而忽略文本到图像模型中原始文本条件。
简介

前两周所学习的SD模型以及基于扩散的T2I生成模型效果好,但是都侧重于参考图像作为输入条件,优化模型的全部或部分参数,代价是严重过拟合导致文本提示的保真度降低。上图也说明对于参考图像过拟合而文本可控性差。
优化的方法参数高效微调为风格化图像生成提供了一种更有效的方法,如LoRA,但是需要的时间开销和额外的计算和存储阻碍了实际生产的实用性。
本周所读的《DEADiff: An Efficient Stylization Diffusion Model with Disentangled Representations》贡献有三个方面:
- 提出了一种双重解耦表示提取机制,分别获得参考图像的风格和语义表示,从学习任务的角度缓解了文本和参考图像语义冲突问题。
- 引入一种解纠缠的条件反射机制,允许跨注意层的不同部分分贝负责图像样式/语义表示的注入,从模型结构的角度进一步见笑了语义冲突。
- 构建了两个成对的数据集,咦帮助使用非重构训练范式得DDRE机制(解耦域表示增强,保持风格的同时,不损害文本语义的表达)。
方法
风格和语义解耦
DEADiff由两个组件组成,首先从特征提取和特征注入两个方面对参考图像的风格和语义进行解耦。
1.在特征提取方面,提出了一种双解耦表示提取机制(dual decoupling representation extraction mechanism, DDRE),该机制利用QFormer从参考图像中获取风格和语义表示。Q-Former通过“风格”和“内容”条件来选择性地提取与给定指令一致的特征。
2. 对于特征注入,引入了一种解纠缠的条件作用机制,将解耦的表示注入到交叉注意层的互斥子集中,以实现更好的解纠缠,其灵感来自于Diffusion U-Net中不同的交叉注意层对风格和语义表达不同的响应。
3. 最后提出了一种从配对合成图像中学习的非重构训练范式(不在要求模型重构原始图像,而是引导模型对内容与风格的解耦和迁移能力进行学习与优化),在“风格”条件的指导下,Q-Former分别使用与参考图像和ground-truth图像具有相同风格的配对图像进行训练,在“内容”条件指导下的Q-Former用语义相同但风格不同的图像进行训练。
双解耦表示提取
受BLIP-Diffusion的启发,通过不同背景的合成图像对来学习主题表示,整合了两个辅助任务,它们利用Q-Formers作为非重构范式内嵌套的表示过滤器,能够含蓄地辨别出图像中风格和内容的分离表示。
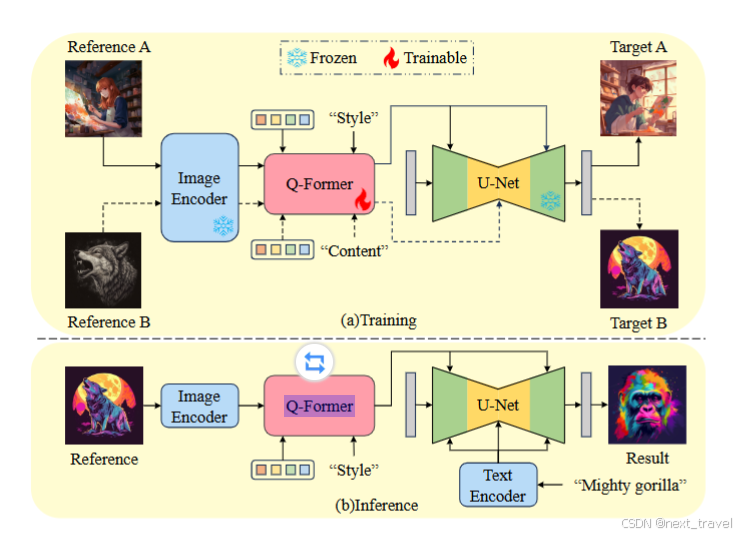
一方面,采样一对不同的图像,她们都保持相同的风格,但分别作为SD生成过程的参考和目标。如上图的a部分。将参考图像输入CLIP图像编码器,其输出通过交叉注意与QFormer的可学习查询令牌及其输入文本进行交互。在这个过程中,将单词“style”作为输入文本,期望生成与文本对齐的图像特征作为输出,该输出封装了样式信息,然后与详细描述目标图像内容的标题相结合,并为去噪U-Net提供条件。
另一方面,合并了一个相对应的对称内容表示图区任务,如上图b所示,选择两幅题材相同但风格不同的图像,分别作为参考图像和目标图像,将Q-Former的输入文本替换为单词“content”,以提取相关的特定于内容的表示,为了获得纯粹的内容表示,我们同时提供Q-Former的查询令牌输出和目标图像的文本样式词,作为去噪U-Net的条件,Q-Former将在生成目标图像时筛除嵌套在CLIP图像嵌入中的与内容无关的信息。同时,将重建任务合并到整个管道中,条件反射提示符由“风格”Q-Former和“内容”Q-Former为这个学习任务处理的查询令牌组成,保证Q-Formers不会忽视本质的图像信息,同时考虑到内容和风格之间的互补关系。
解缠条件作用机制
受去噪U-Net中不同的交叉注意层支配着合成图像的不同属性的启发,引入了一种创新的解纠缠调节机制(Disentangled Conditioning Mechanism, DCM),DCM采用的策略是对空间分辨率较低的粗层进行语义约束,对空间分辨率较高的细层进行风格约束。如上图(a)所示,只将带有“style”条件的Q-Former的输出查询注入到精细层,这些层响应局部特征而不是全局语义。这种结构调整促使Q-Former在输入“风格”条件时提取更多面向风格的特征,同时减少对全局语义的关注。
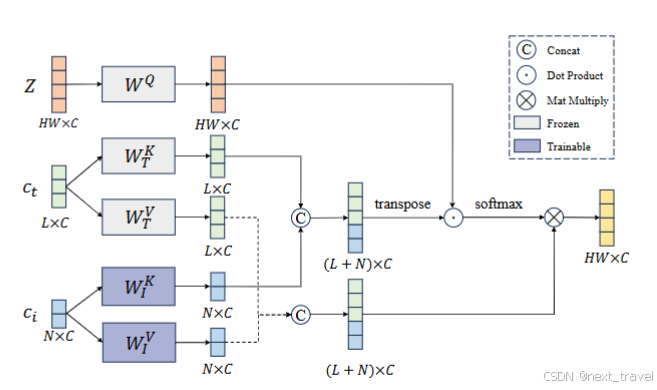
为了使去噪的U-Net支持图像特征作为条件,设计了一个联合文本-图像交叉注意层
Q
=
Z
W
Q
,
(
2
)
I
C
o
n
c
a
t
(
c
t
W
T
K
,
c
i
W
I
K
)
,
(
3
)
V
=
C
o
n
c
a
t
(
c
t
W
T
V
,
c
i
W
I
V
)
,
(
4
)
Z
n
e
w
=
S
o
f
t
m
a
x
(
Q
K
T
d
)
V
.
(
5
)
\begin{gathered} \mathrm{Q}=ZW^{Q},\mathrm{(2)} \\ \mathrm{I}Concat(c_{t}W_{T}^{K},c_{i}W_{I}^{K}),\mathrm{(3)} \\ \mathrm{V}=Concat(c_tW_T^V,c_iW_I^V),\mathrm{(4)} \\ Z^{new}=Softmax(\frac{QK^T}{\sqrt{d}})V.\mathrm{(5)} \end{gathered}
Q=ZWQ,(2)IConcat(ctWTK,ciWIK),(3)V=Concat(ctWTV,ciWIV),(4)Znew=Softmax(dQKT)V.(5)
分别将文本和图像特征的键矩阵和值矩阵连接起来,然后使用U-Net查询特征z启动单个交叉注意操作.
实验
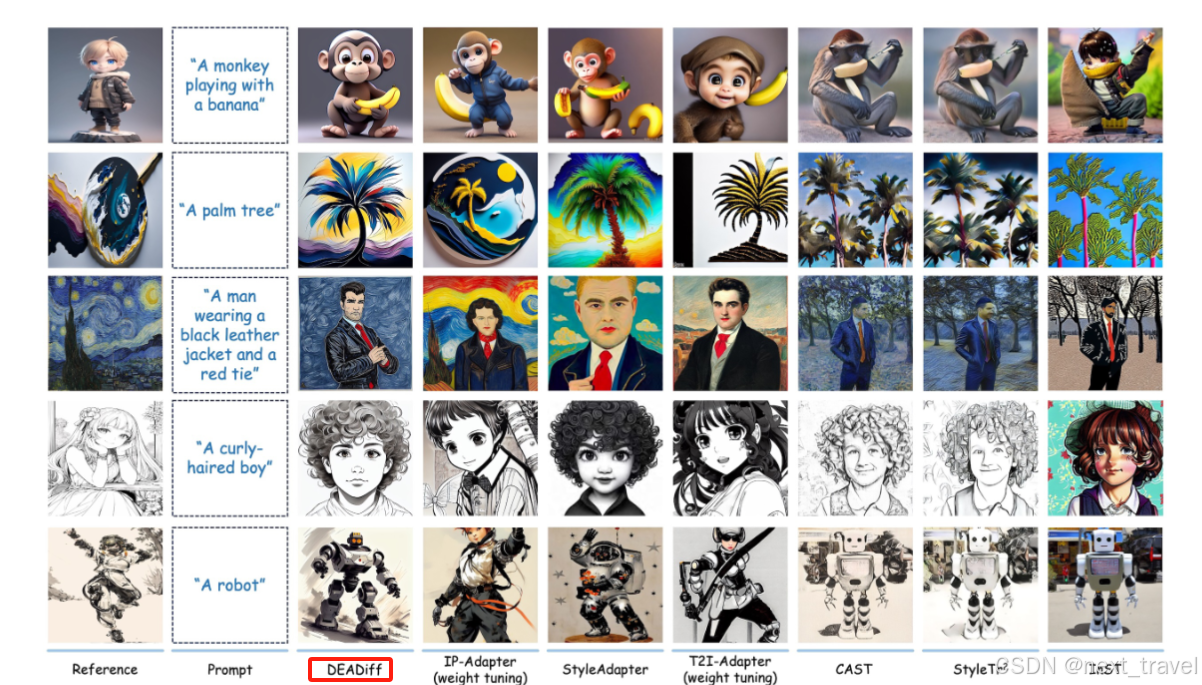
与先进方法定性比较:
各项指标对比:
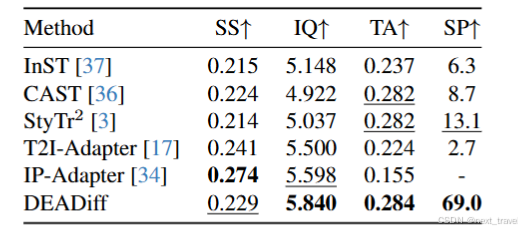
SS (Style Similarity) ↑:衡量生成图像与参考风格图像在风格上的一致程度。
IQ (Image Quality) ↑:衡量生成图像的清晰度、自然度、美观度等整体视觉质量。
TA (Text Alignment) ↑:文本对齐度 / 文本一致性:衡量生成图像是否与输入文本描述语义一致。
SP (Semantic Preservation) ↑:在风格迁移或风格指导的图像生成中,衡量生成图是否保留了原始图像的语义内容。
关键代码:
if opt.laion400m:
print("Falling back to LAION 400M model...")
opt.config = "configs/latent-diffusion/txt2img-1p4B-eval.yaml"
opt.ckpt = "models/ldm/text2img-large/model.ckpt"
opt.outdir = "outputs/txt2img-samples-laion400m"
# seed_everything(opt.seed)
config = OmegaConf.load(f"{opt.config}")
model = load_model_from_config(config, f"{opt.ckpt}")
if opt.plms:
sampler = PLMSSampler(model)
else:
sampler = DDIMSampler(model)
os.makedirs(opt.outdir, exist_ok=True)
outpath = opt.outdir
batch_size = opt.n_samples
n_rows = opt.n_rows if opt.n_rows > 0 else batch_size
if not opt.from_file:
prompt = opt.prompt
assert prompt is not None
data = [batch_size * [prompt]]
else:
print(f"reading prompts from {opt.from_file}")
with open(opt.from_file, "r") as f:
data = f.read().splitlines()
prompts = [p.split('_')[0] for p in data for i in range(batch_size)]
seeds = [int(p.split('_')[1]) for p in data]
prompts = list(chunk(prompts, batch_size))
grid_count = len(os.listdir(outpath))
precision_scope = autocast if opt.precision=="autocast" else nullcontext
with torch.no_grad():
with precision_scope("cuda"):
with model.ema_scope():
tic = time.time()
for ref_image, prompt, seed in zip(sorted(os.listdir(opt.ref_images)), prompts, seeds):
ref_image = os.path.join(opt.ref_images, ref_image)
for n in trange(opt.n_iter, desc="Sampling", disable =not accelerator.is_main_process):
seed_everything(seed)
sample_path = os.path.join(outpath, ref_image.split('/')[-1].split('.')[0], prompt[0])
os.makedirs(sample_path, exist_ok=True)
base_count = len(os.listdir(sample_path))
all_samples = list()
uc = None
if opt.scale != 1.0:
uc = model.get_learned_conditioning({'target_text':batch_size * ["over-exposure, under-exposure, saturated, duplicate, out of frame, lowres, cropped, worst quality, low quality, jpeg artifacts, morbid, mutilated, out of frame, ugly, bad anatomy, bad proportions, deformed, blurry, duplicate"]})
if isinstance(prompt, tuple):
prompt = list(prompt)
c = model.get_learned_conditioning({
'target_text':prompt,
'inp_image': 2*(T.ToTensor()(Image.open(ref_image).convert('RGB').resize((224, 224)))-0.5).unsqueeze(0).repeat(batch_size, 1,1,1).to('cuda'),
'subject_text': [opt.subject_text]*batch_size,
})
shape = [opt.C, opt.H // opt.f, opt.W // opt.f]
samples_ddim, _ = sampler.sample(S=opt.ddim_steps,
conditioning=c,
batch_size=batch_size,
shape=shape,
verbose=False,
unconditional_guidance_scale=opt.scale,
unconditional_conditioning=[uc, uc])
x_samples_ddim = model.decode_first_stage(samples_ddim)
x_samples_ddim = torch.clamp((x_samples_ddim + 1.0) / 2.0, min=0.0, max=1.0)
x_samples_ddim = accelerator.gather(x_samples_ddim)
if accelerator.is_main_process and not opt.skip_save:
for x_sample in x_samples_ddim:
x_sample = 255. * rearrange(x_sample.cpu().numpy(), 'c h w -> h w c')
Image.fromarray(x_sample.astype(np.uint8)).save(
os.path.join(sample_path, f"{base_count:05}.png"))
base_count += 21
if accelerator.is_main_process and not opt.skip_grid:
all_samples.append(x_samples_ddim)
grid = torch.stack(all_samples, 0)
grid = rearrange(grid, 'n b c h w -> (n b) c h w')
grid = make_grid(grid, nrow=n_rows)
# to image
grid = 255. * rearrange(grid, 'c h w -> h w c').cpu().numpy()
Image.fromarray(grid.astype(np.uint8)).save(os.path.join(outpath, ref_image.split('/')[-1].split('.')[0], f'grid-{grid_count:04}.png'))
grid_count += 1
toc = time.time()
结论
本文深入探讨了现有基于编码器的风格化扩散模型文本控制能力下降的原因,并随后提出了针对性设计的DEADiff。它包括双重解耦表示提取机制和解耦的条件机制。实证证据表明,DEADiff能够在风格化能力和文本控制之间实现最佳平衡。未来的工作可以致力于进一步提高风格相似度和解耦实例级语义信息。
总结
DEADiff模型通过结构设计与训练范式的创新,成功缓解了风格图像注入对文本语义的干扰问题,实现了风格与内容的有效解耦。其核心在于结合Q-Former与非重构训练策略,分别抽取和引导风格及语义特征流入扩散模型的不同层级,确保生成图像既能保留参考图的风格,又能精准响应文本描述。实验评估显示,DEADiff在多个主观与客观指标上表现优越,证明其在风格化文本图像生成任务中的潜力。
参考文献
[1] DEADiff: An Efficient Stylization Diffusion Model with Disentangled Representations