嵌入式人工智能应用- 第十章街景分类
嵌入式人工智能应用
`
文章目录
- 嵌入式人工智能应用
- 1 原理概述
-
- 1.1 计算机视觉介绍
- 1.2 YOLO算法
- 2 代码部署
-
- 2.1 代码运行
- 3 代码总结
1 原理概述
1.1 计算机视觉介绍
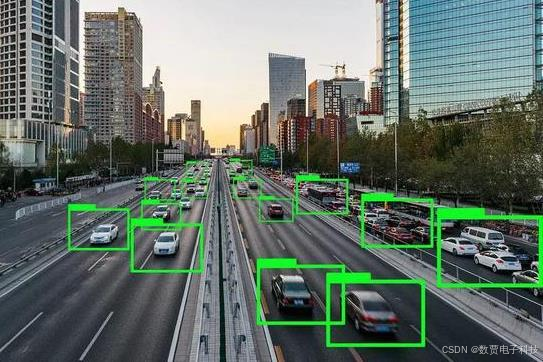
我们有时候在一些科幻电影里看到类似 所示的画面,感觉很是高端大气上档次,那么我们能不能做到类似的识别效果呢?这和我们的实验七类似,实验九是识别视野中的主要物体,这里不仅识别到了,还将识别到的物体框选出来了。如果从最开始的基础到现在,关于常用的算法、各种神经网络已经了解得够多了,这里我们再加一个 YOLO 算法。
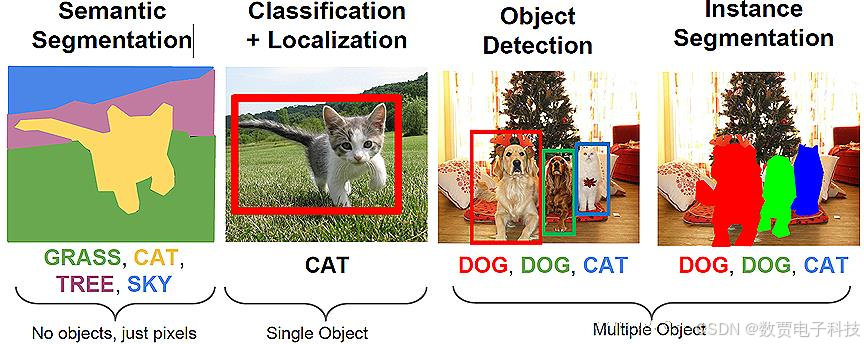
当我们谈起计算机视觉时,首先想到的就是图像分类。图像分类是计算机视觉最基本的任务之一,但是在图像分类的基础上,还有更复杂和有意思的任务,如目标检测,物体定位,图像分割等。其中目标检测是一件比较实际的且具有挑战性的计算机视觉任务,可以看成图像分类与定位的结合,给定一张图片,
目标检测系统要能够识别出图片的目标并给出其位置,由于图片中目标数是不定的,且要给出目标的精确位置,目标检测相比分类任务更复杂。目标检测的一个实际应用场景就是无人驾驶,如果能够在无人车上装载一个有效的目标检测系统,那么无人车将和人一样有了眼睛,可以快速地检测出前面的行人与车辆,从而作出实时决策。
1.2 YOLO算法
前面几个实验都用到了 xxcnn,例如 mtcnn,现在很多的人工智能实现首选了 CNN,是采用滑窗的方式实现的目标检测,将目标检测转换成图像分类问题。其基本原理就是采用不同大小和比例(宽高比)的窗口在整张图片上以一定的步长进行滑动,然后对这些窗口对应的区域做图像分类,这样就可以实现对整张图片的检测了。但是这个方法有致命的缺点,就是你并不知道要检测的目标大小是什么规模,所以你要
设置不同大小和比例的窗口去滑动,而且还要选取合适的步长。但是这样会产生很多的子区域,并且都要经过分类器去做预测,这需要很大的计算量,所以你的分类器不能太复杂,因为要保证速度。解决思路之一就是减少要分类的子区域,这就是 R-CNN 的一个改进策略,其采用了 selective search 方法来找到最有可能包含目标的子区域(Region Proposal),其实可以看成采用启发式方法过滤掉很多子区域,这会提升效率。CNN 卷积操作的特性,就是图片的空间位置信息的不变性,尽管卷积过程中图片大小减少,但是位置对应关系还是保存的。
YOLO 不再是窗口滑动了,而是直接将原始图片分割成互不重合的小方块,然后通过卷积最后生产这样大小的特征图,基于上面的分析,可以认为特征图的每个元素也是对应原始图片的一个小方块,然后用每个元素来预测那些中心点在该小方格内的目标,这就是 Yolo 算法的朴素思想。
YOLO 算法采用一个单独的 CNN 模型实现 end-to-end 的目标检测,整个系统如图 所示:首先将入图片 resize 到 448x448,然后送入 CNN 网络,最后处理网络预测结果得到检测的目标。相比 R-CNN算法,它是一个统一的框架,速度更快,而且 YOLO 的训练过程也是 end-to-end 的。

具体来说,Yolo 的 CNN 网络将输入的图片分割成 S×S 网格,然后每个单元格负责去检测那些中心点落在该格子内的目标,如图 4.10.4 所示,可以看到狗这个目标的中心落在左下角一个单元格内,那么该单元格负责预测这个狗。每个单元格会预测 B 个边界框(bounding box)以及边界框的置信度(confidence score)。