大模型后训练+微调
📕参考:大模型研讨课第一期:Why LLMs?、模型结构1(共10期)_哔哩哔哩_bilibili

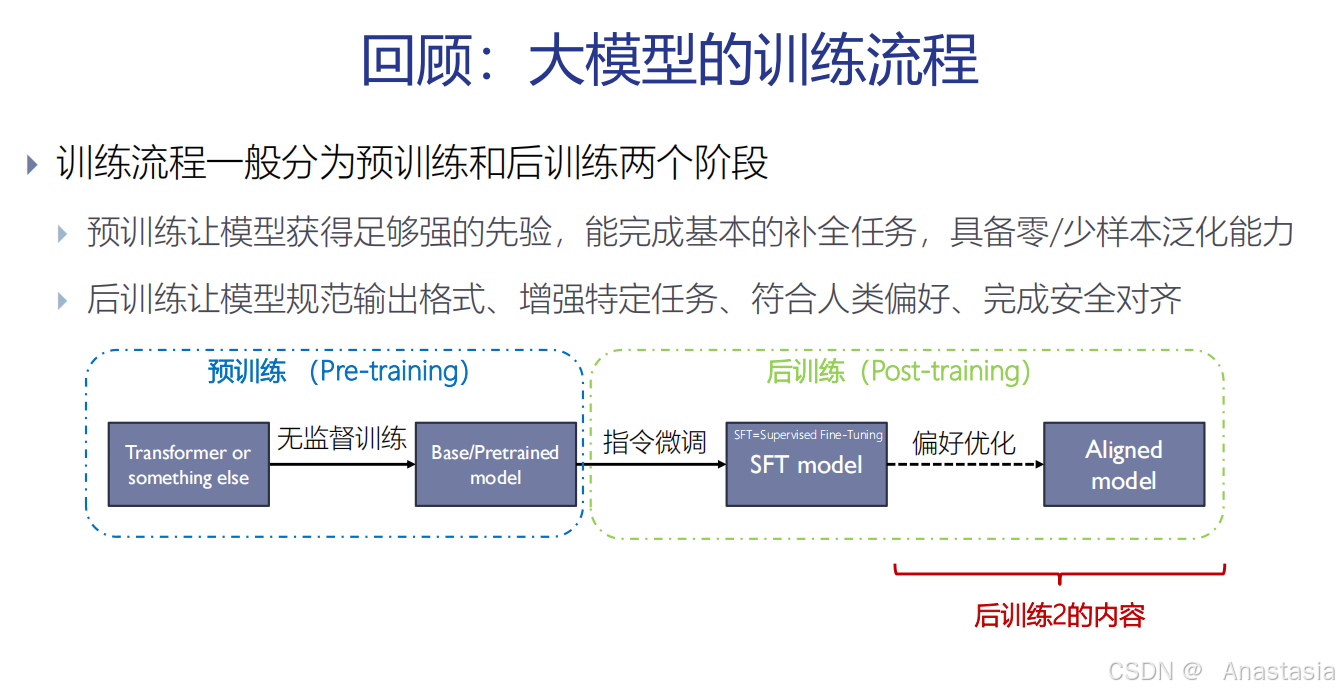
首先回顾大模型的训练流程。大模型的训练流程包括预训练和后训练。
预训练是使用大规模的训练语料训练模型,主要是让模型获得先验知识,能够完成基本的补全任务(理解:让模型读书,让它学会一些基本预测。比如:第一个字是“中” 学会预测第二个词是“国”)
后训练是经过指令微调和偏好优化,让模型的输出具有某些特定格式,能够满足人类偏好。
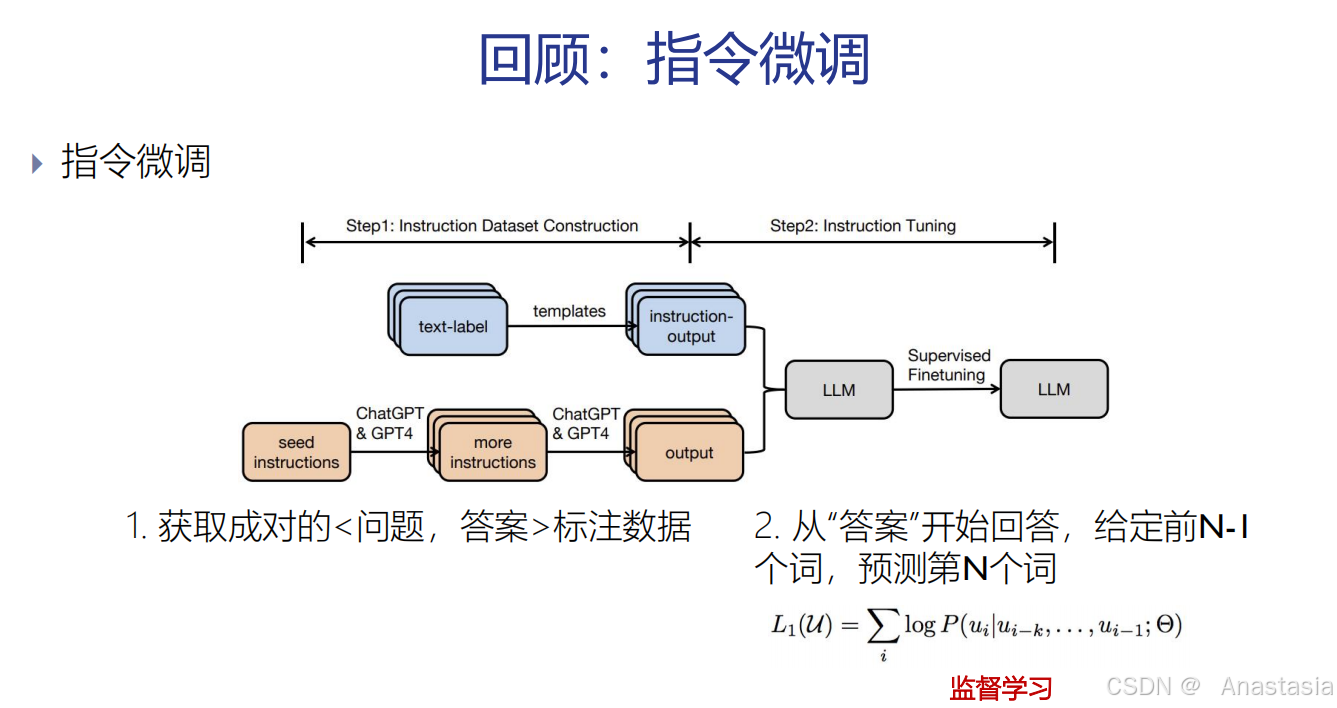
什么是指令微调?
指令微调就是用一些人工标注的数据去训练模型,让模型会做题,会根据问题输出正确的答案。
强化学习
强化学习是什么?
deepseek给出的解释是:
强化学习(Reinforcement Learning, RL)是一种机器学习方法,通过智能体(Agent)与环境(Environment)的交互来学习最优策略,以最大化累积奖励(Cumulative Reward)。
核心要素
智能体(Agent):学习并做出决策的主体。
环境(Environment):智能体交互的外部系统。
状态(State):环境在某一时刻的具体情况。
动作(Action):智能体在某个状态下采取的行动。
奖励(Reward):智能体执行动作后,环境返回的即时反馈。
策略(Policy):智能体选择动作的规则。
价值函数(Value Function):评估状态或动作的长期价值。
探索与利用(Exploration vs. Exploitation):智能体在尝试新动作和利用已知最优动作之间的权衡。
主要算法
Q学习(Q-Learning):通过更新Q值函数来学习最优策略,无需环境模型。
深度Q网络(DQN):结合Q学习和深度神经网络,适用于高维状态空间。
策略梯度方法(Policy Gradient Methods):直接优化策略,常用算法包括REINFORCE和Actor-Critic。
深度确定性策略梯度(DDPG):结合DQN和策略梯度,适用于连续动作空间。
应用领域
游戏:如AlphaGo、Atari游戏。
机器人:路径规划、抓取操作。
自动驾驶:决策与控制。
推荐系统:个性化推荐。
金融:交易策略优化。
特点
试错学习:通过不断尝试来优化策略。
延迟奖励:当前动作可能影响未来奖励。
在线学习:智能体在交互中实时学习。
挑战
探索与利用的平衡:需在尝试新动作和利用已知最优动作之间找到平衡。
稀疏奖励:奖励信号可能稀少,导致学习效率低。
高维状态和动作空间:处理复杂问题时计算量大。
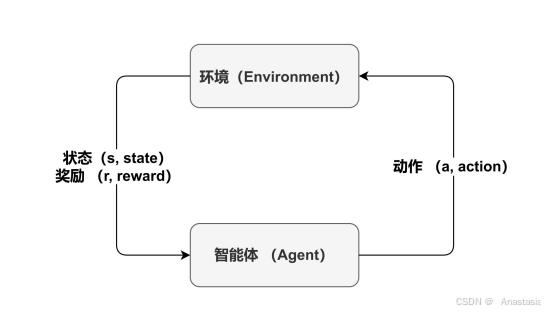
智能体给出动作,环境据此给出反馈。智能体根据环境给出的反馈来调整,以达到最后效果。
为什么后训练需要强化学习?
我们需要大模型和人类的偏好“对齐”,比如生成的回答要有用,诚实,无害等。但是指令微调不能满足“对齐”的需求。
指令微调:最大化标注回复的生成概率。就是使【人类标注的答案】的生成概率最大。

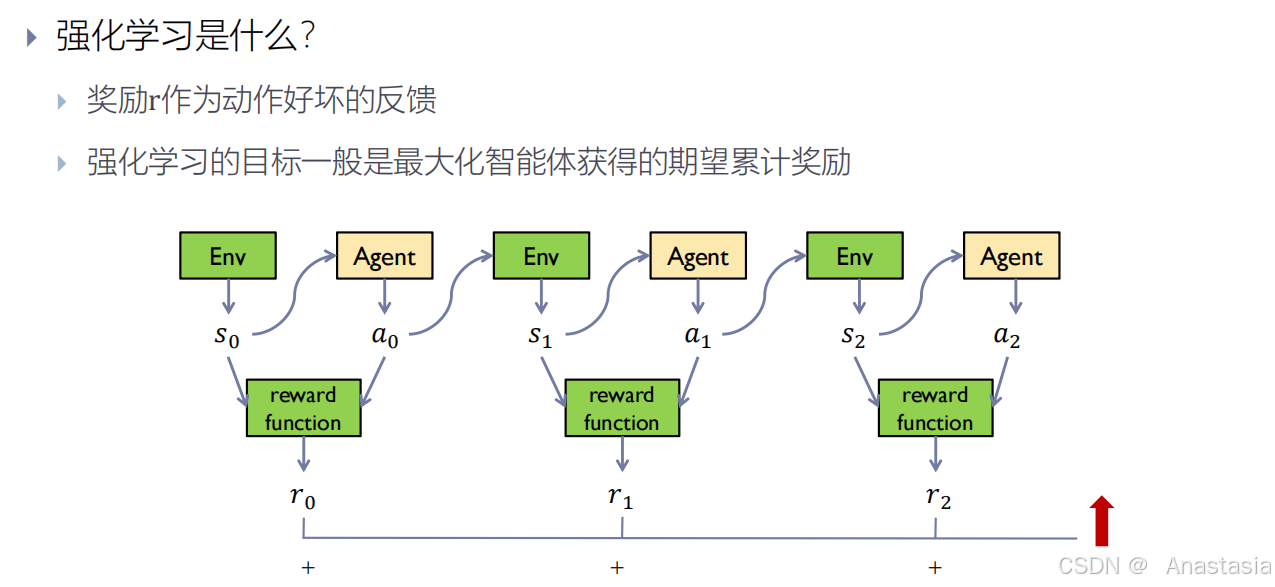
强化学习(Reinforcement Learning, RL)是一种机器学习方法,通过智能体(Agent)与环境(Environment)的交互来学习最优策略,以最大化累积奖励(Cumulative Reward)。
强化学习一般是根据奖励 r 来调整,使得最后的期望累计奖励最大。
环境给出状态s ,s传给智能体和奖励函数,智能体根据s 做出下一个动作,传给环境和奖励函数。
奖励函数根据s 和 s 进行计算。
强化学习的目标是把每个时间的奖励收集起来累加起来,最大化这个东西的和。
强化学习算法可以根据是否使用环境模型、优化策略还是价值函数、以及是在线学习还是离线学习进行分类。
基于模型(Model-based) vs. 无模型(Model-free):
基于模型:算法使用环境模型(即状态转移概率和奖励函数)来规划策略。例如,动态规划(Dynamic Programming)和蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)。
无模型:算法不依赖于环境模型,直接通过与环境交互来学习策略。例如,Q学习(Q-Learning)和策略梯度方法(Policy Gradient Methods)。
基于价值(Value-based) vs. 基于策略(Policy-based) vs. 演员-评论家(Actor-Critic):
基于价值:算法通过优化价值函数(如Q值函数或状态值函数)来间接优化策略。例如,Q学习(Q-Learning)和深度Q网络(Deep Q-Network, DQN)。
基于策略:算法直接优化策略函数,通常通过策略梯度方法。例如,REINFORCE算法。
演员-评论家:结合了基于价值和基于策略的方法,使用价值函数来指导策略优化。例如,优势演员-评论家(Advantage Actor-Critic, A2C)和异步优势演员-评论家(Asynchronous Advantage Actor-Critic, A3C)。
在线学习(On-policy) vs. 离线学习(Off-policy):
在线学习:算法在优化策略时使用当前策略生成的数据。例如,SARSA和REINFORCE。
离线学习:算法可以使用历史数据(由不同策略生成)来优化当前策略。例如,Q学习和深度Q网络(DQN)。
具体算法示例
Q学习(Q-Learning):
类型:无模型、基于价值、离线学习。
描述:通过更新Q值函数来学习最优策略,使用贝尔曼方程进行更新。
深度Q网络(Deep Q-Network, DQN):
类型:无模型、基于价值、离线学习。
描述:使用深度神经网络来近似Q值函数,结合经验回放和目标网络来提高稳定性。
REINFORCE:
类型:无模型、基于策略、在线学习。
描述:通过策略梯度方法直接优化策略,使用蒙特卡洛方法来估计回报。
优势演员-评论家(Advantage Actor-Critic, A2C):
类型:无模型、演员-评论家、在线学习。
描述:结合策略梯度方法和价值函数,使用优势函数来减少方差。
深度确定性策略梯度(Deep Deterministic Policy Gradient, DDPG):
类型:无模型、演员-评论家、离线学习。
描述:适用于连续动作空间,结合DQN和策略梯度方法。
近端策略优化(Proximal Policy Optimization, PPO):
类型:无模型、演员-评论家、在线学习。
描述:通过限制策略更新的幅度来提高稳定性和样本效率
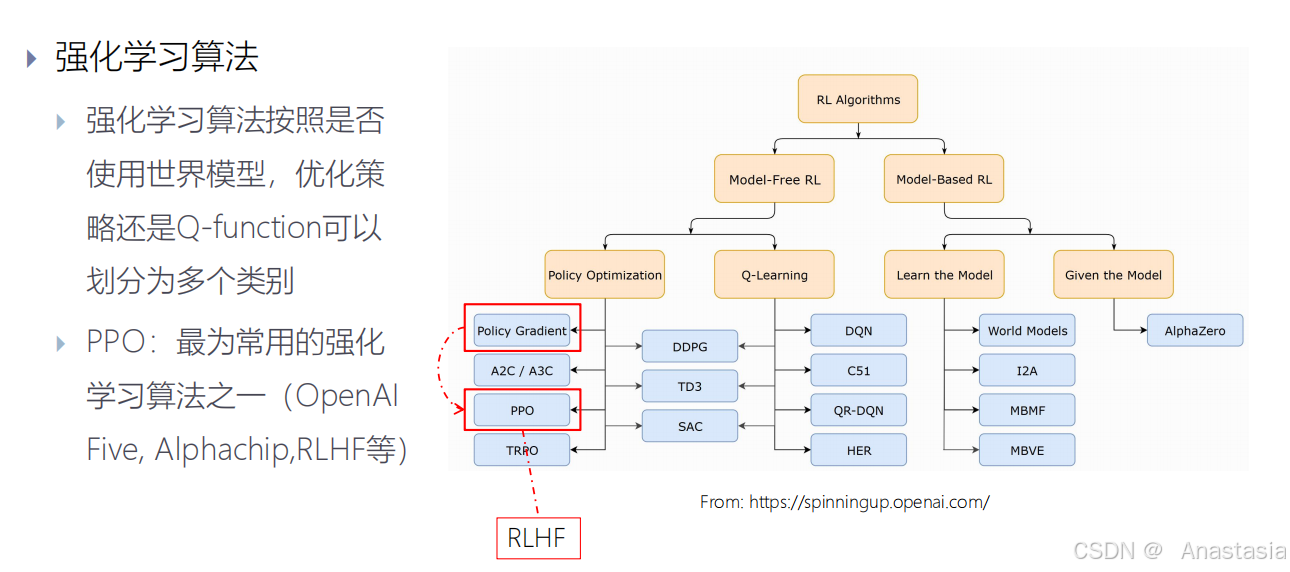
近端策略优化(Proximal Policy Optimization, PPO),是目前最常用的强化学习算法之一。
策略梯度算法
基于策略:算法直接优化策略函数,通常通过策略梯度方法。例如,REINFORCE算法。
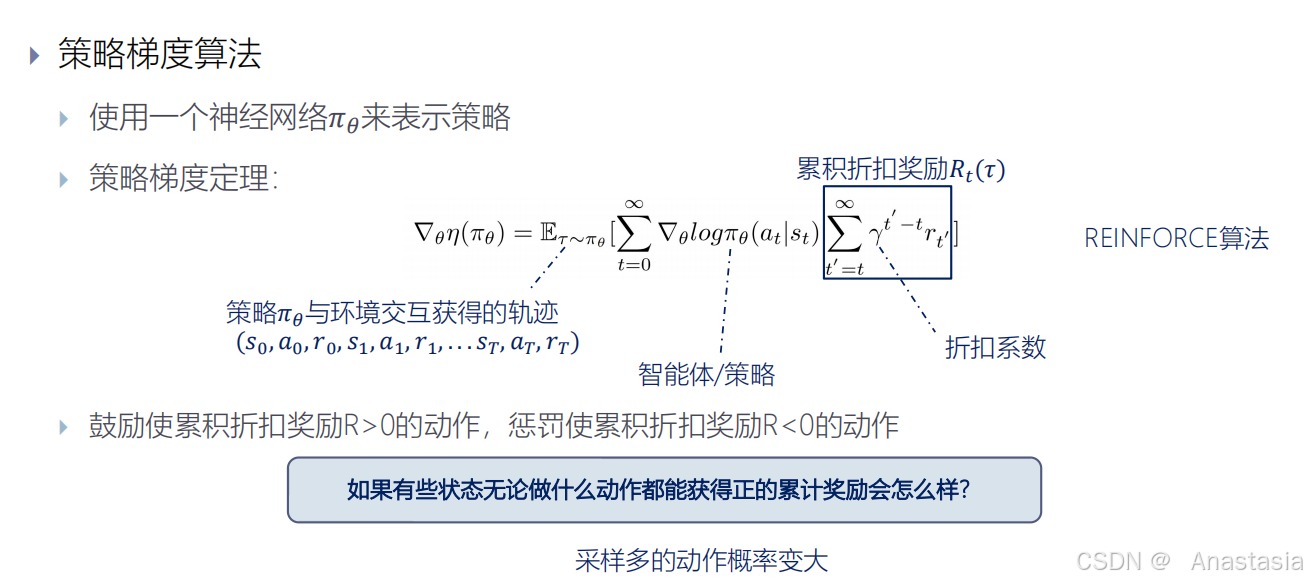
![]() :策略与环境交互获得的轨迹,包括 s a r
:策略与环境交互获得的轨迹,包括 s a r
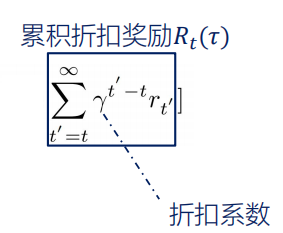 理解折扣奖励:折扣系数和这个时间折扣函数的乘积,然后累加起来。
理解折扣奖励:折扣系数和这个时间折扣函数的乘积,然后累加起来。
折扣系数:接近1的数值,代表整个奖励和未来的关系。

观察整个函数:当累积折扣奖励大于0的时候就会增大这个智能体策略【时间t 下的动作a_t】的贡献。
但是如果每个时间的累积折扣奖励大于0那么最后就会持续增大,要改变这种情况。
就有了以下的策略:
不是看它的正负,而是看看它比平均好多少来调整。
引入一个baseline,这个baseline通常使用状态价值函数V。
状态价值函数V:当前这个状态以及现在这个策略,对它未来奖励的期望的预估。(期望的平均奖励)

状态价值函数(State Value Function)用于评估智能体在某个状态下的长期期望回报。





PPO算法
PO是一种策略优化算法,它通过计算状态或动作的预期回报来更新模型策略,以进一步优化模型。然而,PPO作为on-policy算法,每次更新都需要收集新样本,这可能导致效率低下和稳定性差。

但实际上优化上述函数的计算量比较大,所以有了新的算法。
ppo-clip形式:

PPO-Clip(Proximal Policy Optimization with Clipped Objective)是一种强化学习算法,由OpenAI提出,旨在提高策略优化过程的稳定性和样本效率。
PPO-Clip通过引入一个剪切(clip)机制来限制策略更新的幅度,从而避免过大的策略更新,确保训练过程的稳定性。




我们的优化目标是使整个式子的数值变大,当A>0时,

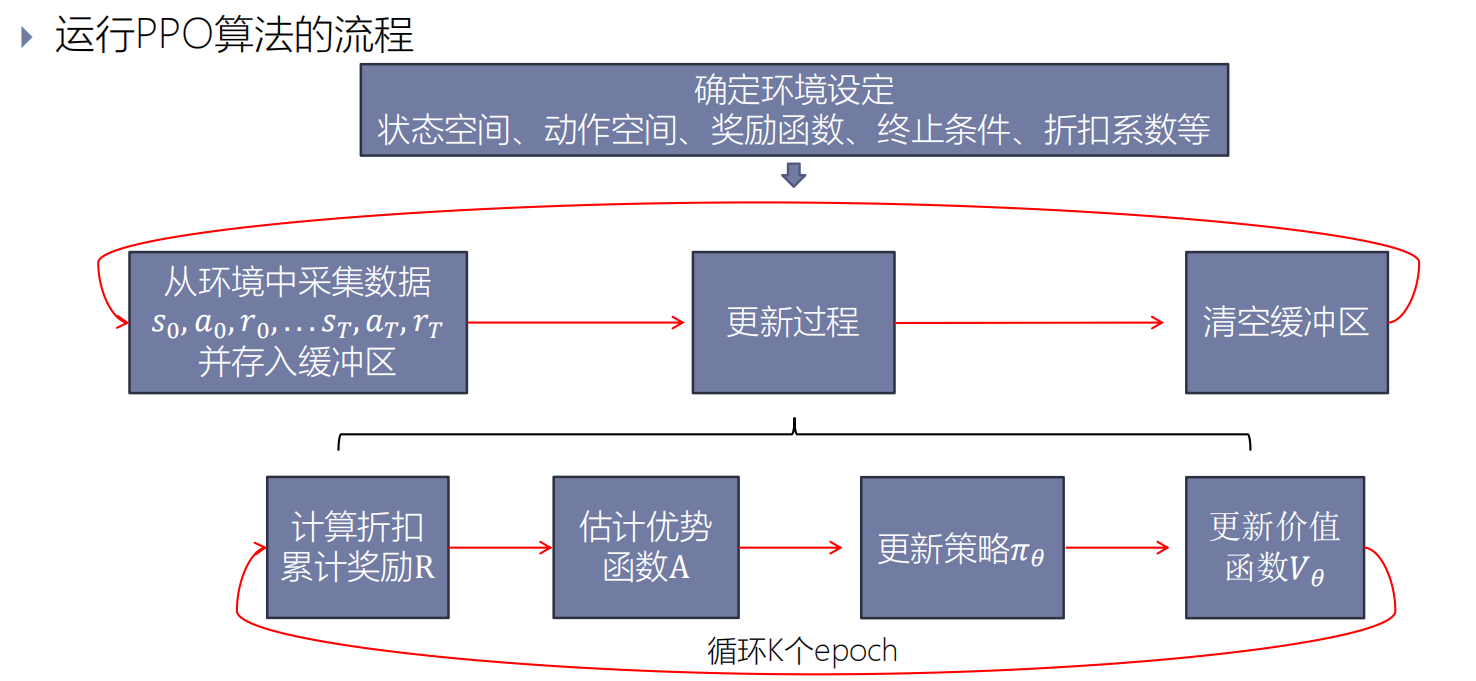
1.初始化:
确定环境设定,初始化状态空间、动作空间、奖励函数、终止条件、折扣系数等。

2.收集数据:
从环境中收集数据,并存入缓冲区。

3.更新
(1)计算折扣累积奖励R
(2)估计优势函数A

(3)更新策略:





![]()
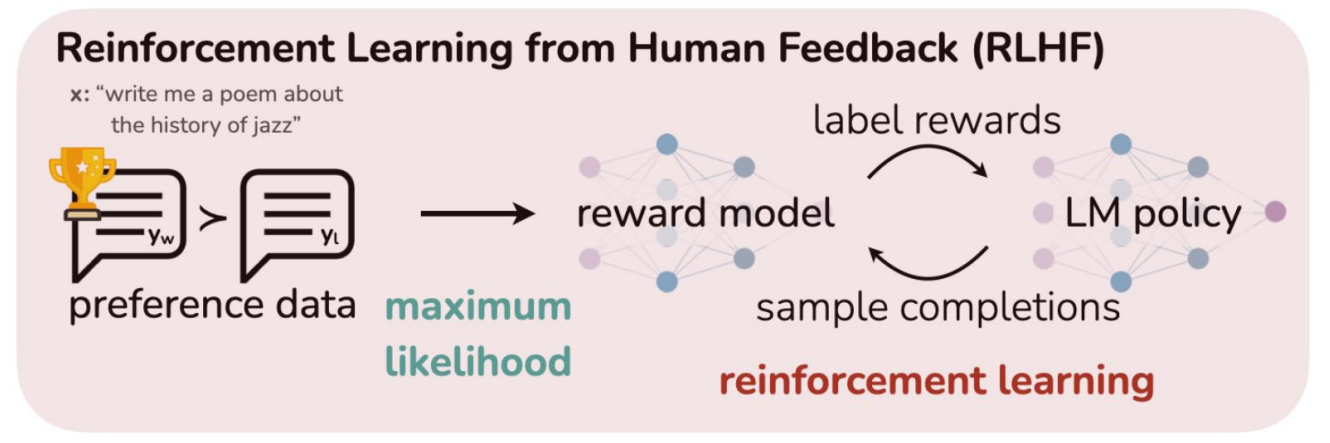
Reinforcement learning from human feedback (RLHF)
基于人类反馈的强化学习
RLAIF(Reinforcement Learning with Artificial Intelligence Feedback)从采样方式和生成训练奖励模型的评分角度对RLHF进行改进,旨在提高训练效率和模型质量。

策略:要训练的大模型,这里选经过指令微调的大模型
动作:以词表为动作空间,策略从词表中选出词元作为时刻t的动作。
状态:prompt和之前所有策略选择过的词元的组合
终止条件:策略输出句子的结束符EOS,或者序列到达预定义的最大长度
奖励函数:大模型没有办法手写奖励函数,所以需要写一个奖励模型。

(1)收集偏好数据
对于一个prompt大模型给出两个或多个回答 ,人类按照有用性(Helpfulness)或安全性 (Safety)等标准给出排序或者比较。
比如问大模型如何向6岁的孩子解释月球着陆,大模型会给出四个回答ABCD,然后雇佣一些人按照有用性或安全性等标准给出排序或者比较。
(2)奖励模型训练
如何使用偏好数据训练 输出标量奖励数值的 奖励模型?


为什么需要KL散度约束
奖励函数只是真实人类偏好的一个代理,过度追求奖励可能导致策略发现奖励函数的漏洞得
到高奖励,但并不符合人类偏好。

RL from AI Feedback (RLAIF)
RLHF需要人类根据偏好对答案进行比较排序,收集数据的成本很高。
研究发明出来了基于AI的标注方法。
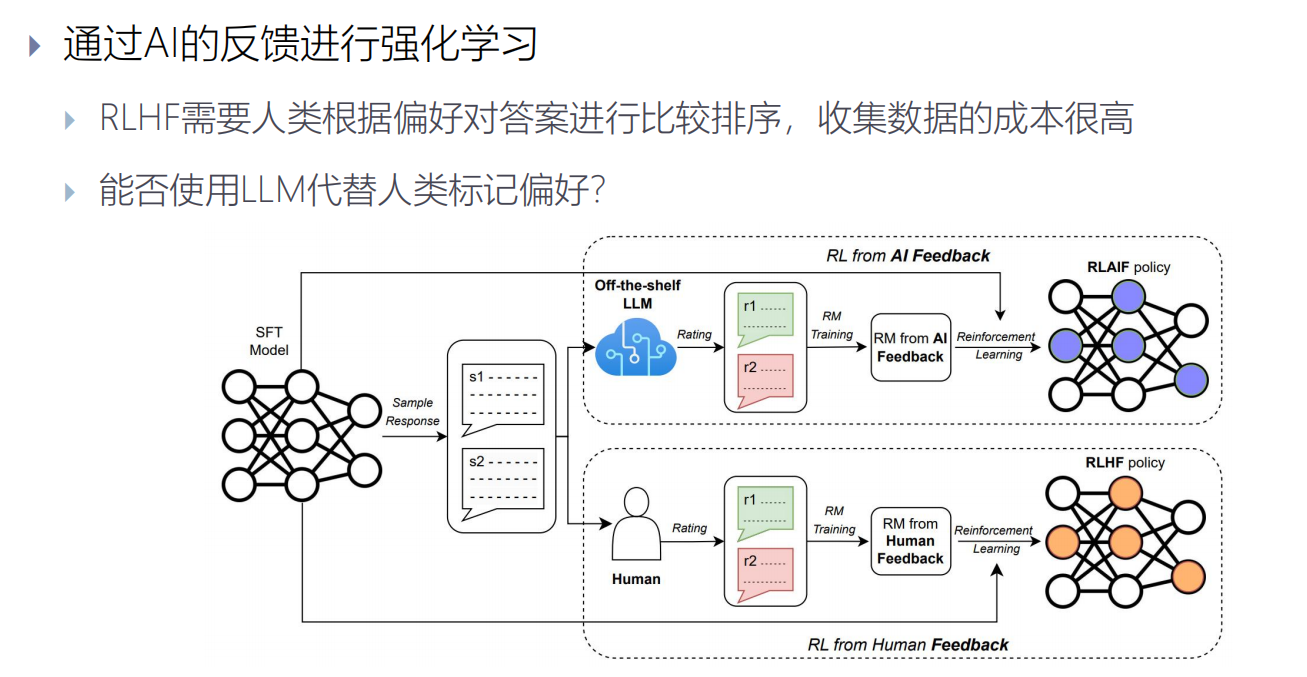
如何使用大模型进行偏好标记?
1.避免位置偏差
(1)问题:LLM的偏好可能和位置相关,比如总是偏向于第一个输入的<问题,答案>对
(2)解决方法:双重推理(交换输入的顺序)和平均处理(平均标记的结果)

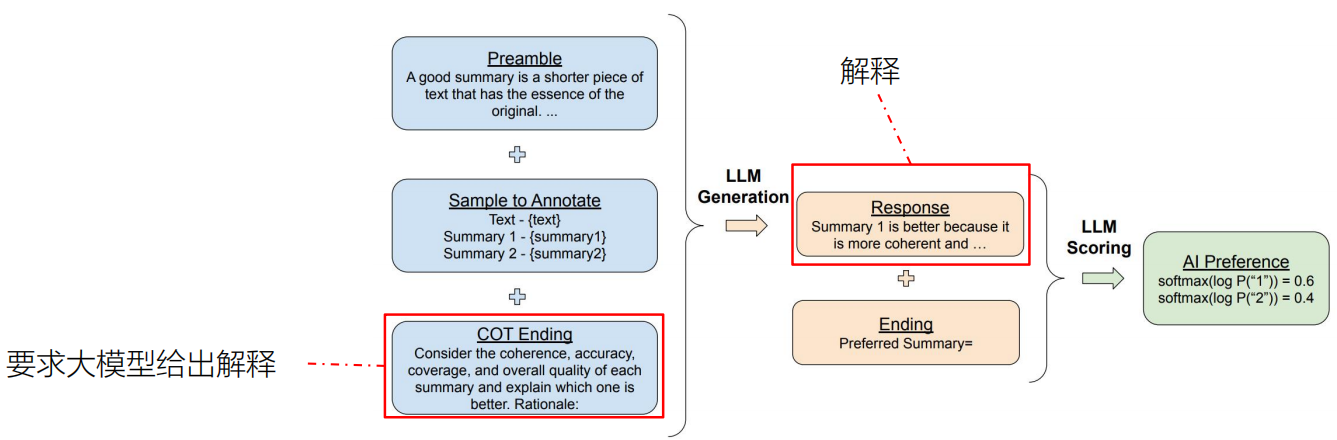
2.增加思维链
要求LLM在偏好标记前给出解释(思维链,Chain of Thought)
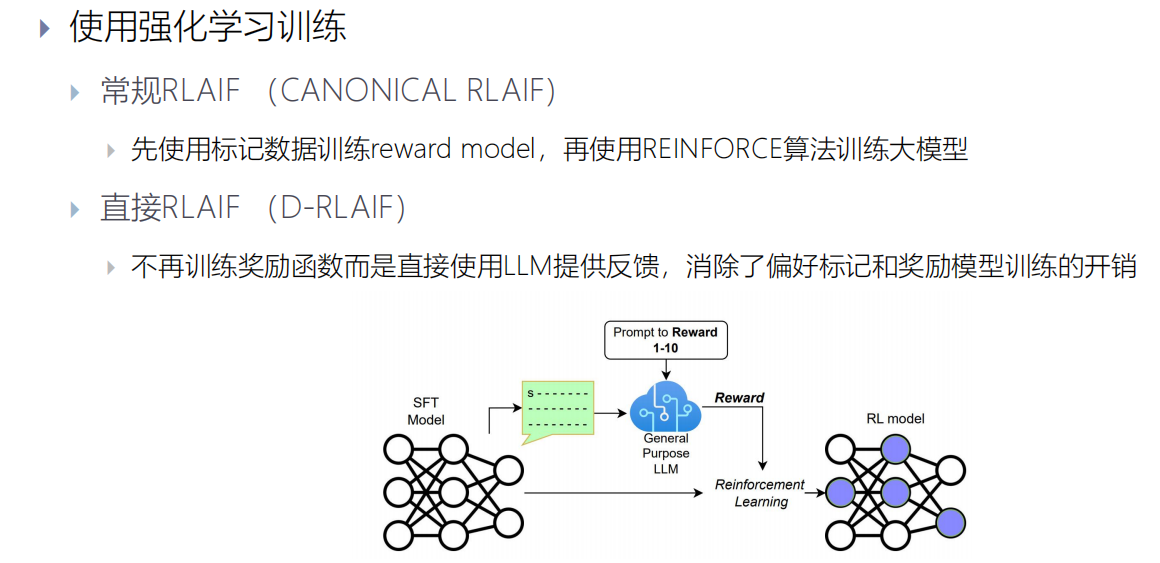
RLHF可以成功的将大模型和人类偏好对齐,但是步骤较为复杂,有额外的计算和存储开销。能否省去奖励模型的训练过程和RL训练过程,直接从偏好数据中学习?
直接偏好优化 Direct Preference Optimization (DPO)
直接从偏好数据中监督学习
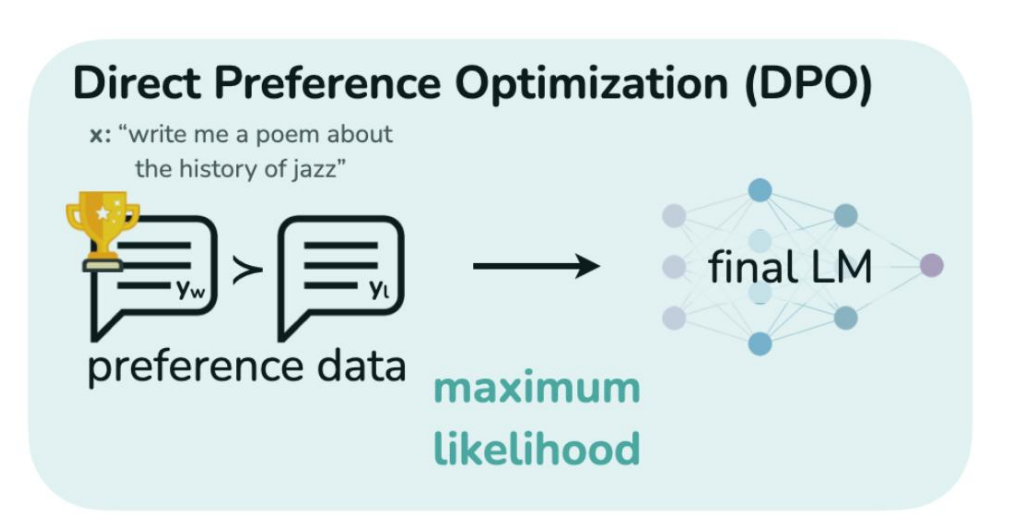


DPO vs PPO
直接从偏好数据中学习 vs 利用偏好数据使用RL更新规则学习
自提升
上面的强化学习是 如何从人类标注的偏好数据中进行学习,但是如果没有较好的标注的偏好数据呢?就需要模型进行自提升了。
Self-Play Fine-Tuning (SPIN)
什么是self-play?
在多智能体强化学习中,通过训练智能体自己和自己的副本对抗提高性能。
在AlphaGo Zero, AlphaStar等工作中都展现了良好的效果。
self-play用于训练大模型
目的:在不需要获取额外的人工标注数据的情况下,从弱LLM中训练出强LLM。
方法:使用LLM做对抗游戏
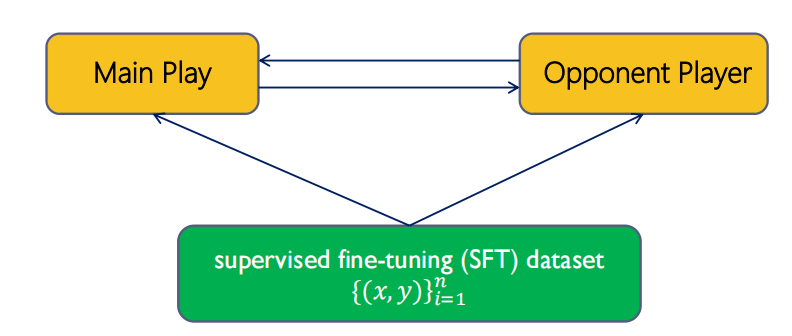



Self-rewarding

构建一个迭代优化的过程,模型自己为自己提供奖励,在优化过程中同时优化模型指令遵循的
能力和提供奖励的能力。

指令微调数据集 Instruction Fine-Tuning (IFT) data: Open Assistant dataset 中3200个高质量样本。 这个只有问题和答案对,没有打分排序。
评估微调数据集 Evaluation Fine-Tuning (EFT) data: Open Assistant dataset 中 1,630个排序样本。这个有打分排序。
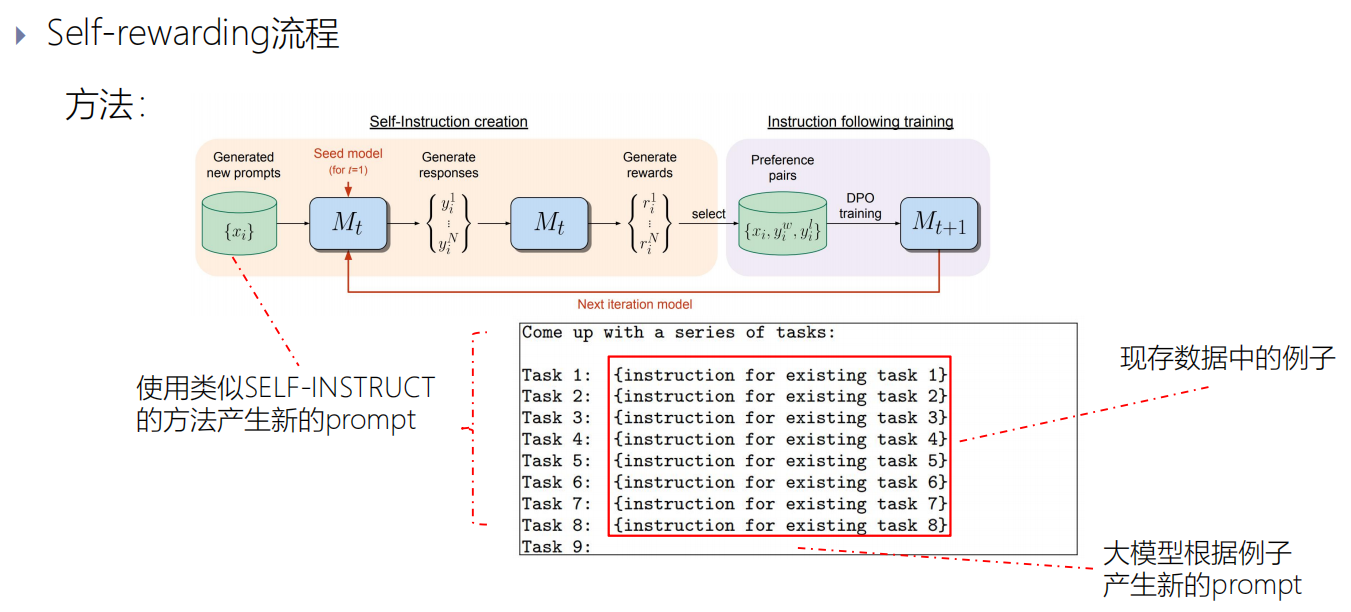
种子数据集是高质量的少量数据集,它的数量比较少,还要指挥大模型再生成一些数据集。
即:大模型根据例子产生新的prompt。
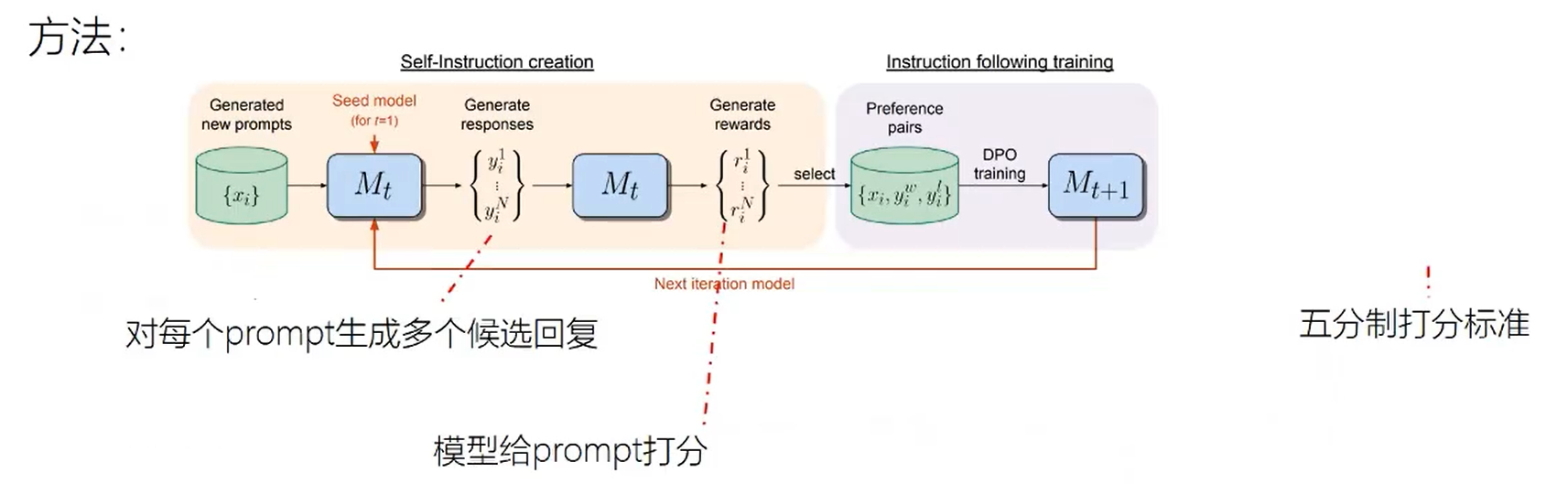
从池子里拿出一些prompt让模型对这些prompt产生回复,然后对每个prompt生成的多个候选回复进行打分,采用五分制打分标准。
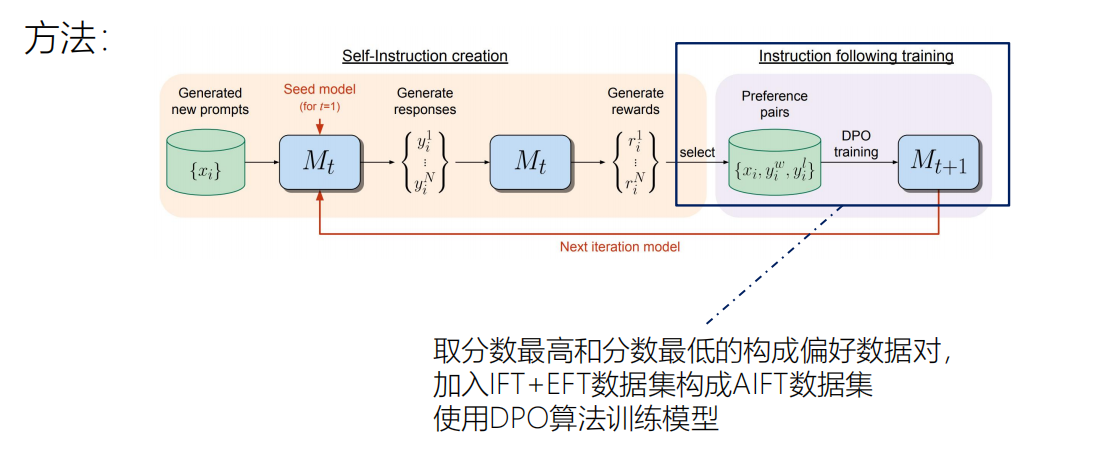
利用分数最高和分数最低的构成偏好数据对,加入IFT+EFT数据集构成AIFT数据集 ,使用DPO算法训练模型
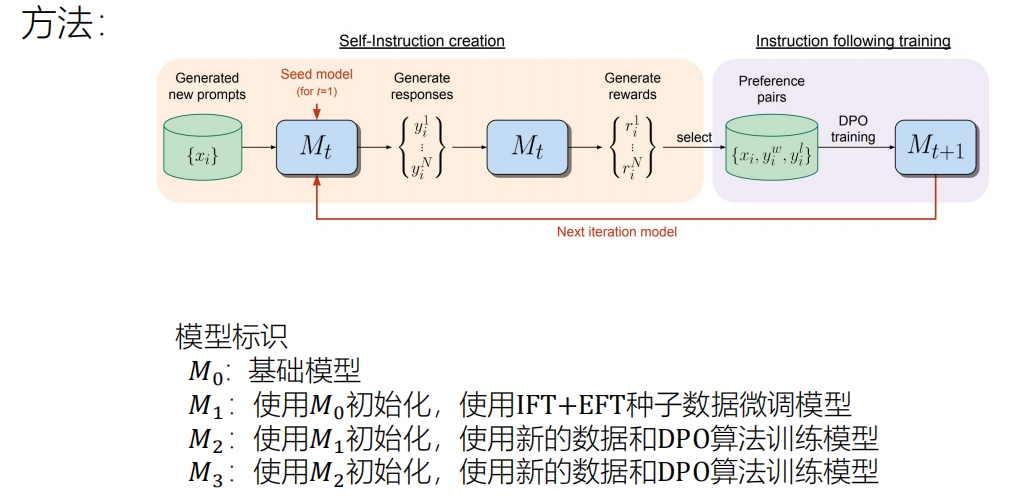
迭代,更新模型。
微调大模型

微调大模型:全参数微调、参数高效微调、增加参数微调、选择性微调、重参数化微调
什么是微调?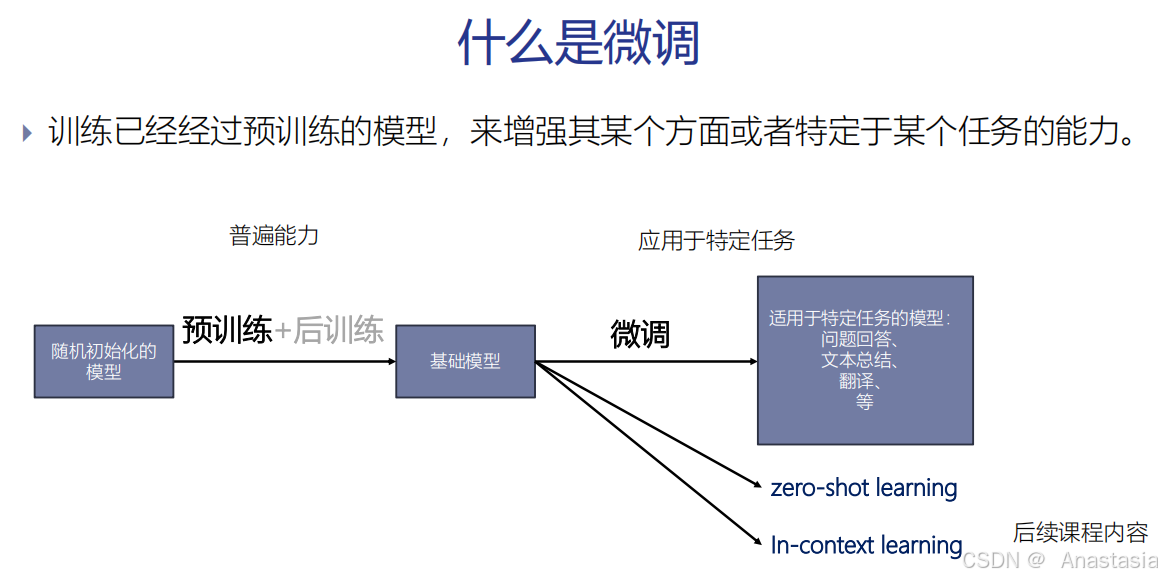
训练已经经过预训练的模型,来增强其某个方面或者特定于某个任务的能力。
全参数微调
使用特定任务的数据集训练并优化模型的所有参数。
问题:
-
训练时的计算开销大
-
需要为每个任务保存所有参数,存储开销大
-
小数据集全参数微调容易导致过拟合
-
如果需要同时支持多个任务,需要加载多个完整模型

参数高效微调 Parameter-Efficient Finetuning (PEFT)
参数高效微调 Parameter-Efficient Finetuning (PEFT):通过只优化一小部分参数实现高效的微调。比如:增加参数微调、选择性微调、重参数化微调。
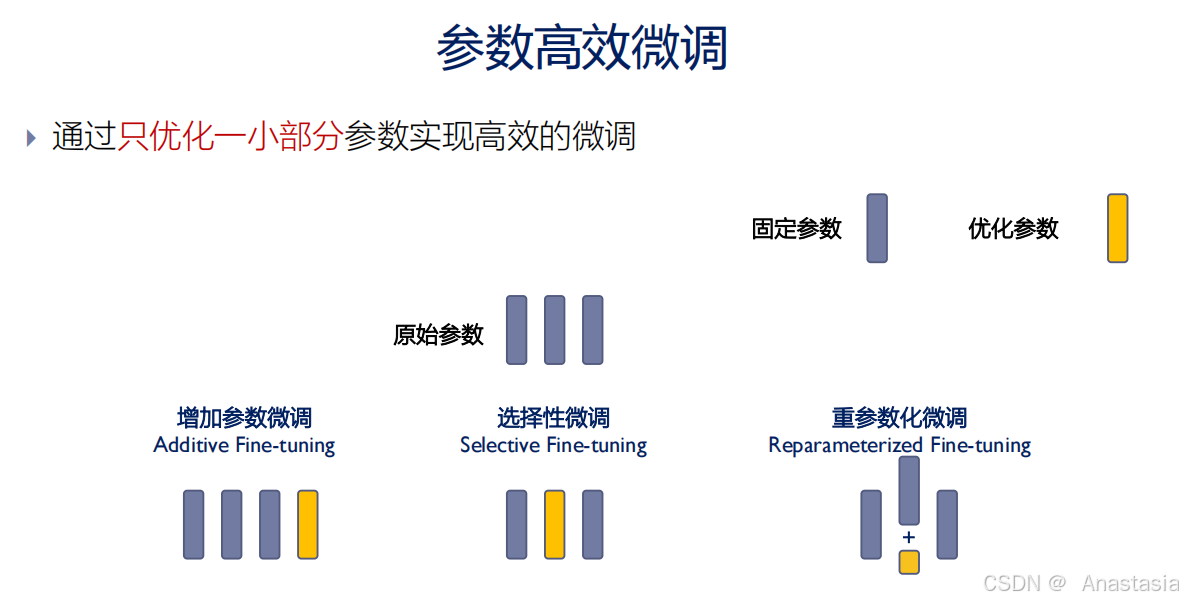
增加参数微调 Additive Fine-tuning
增加参数微调 Additive Fine-tuning: 在模型特定位置增加少量参数 ,在微调时只更新增加的这部分参数。

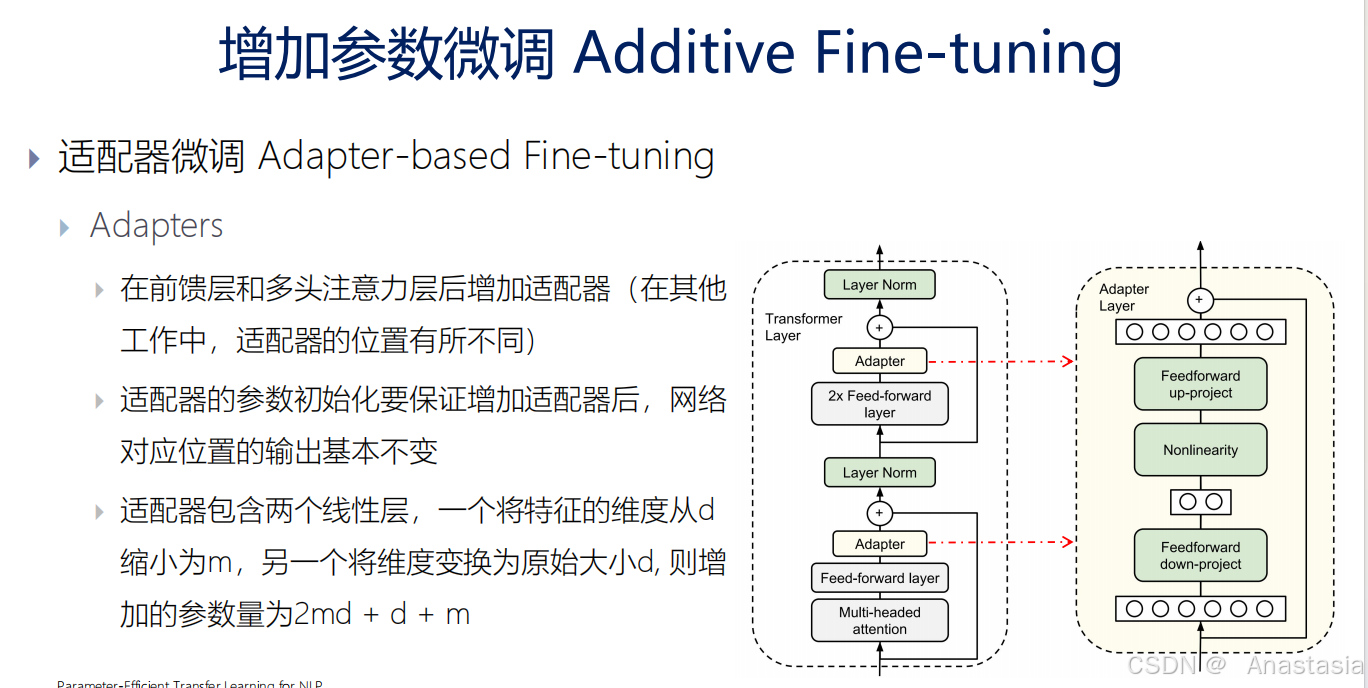
适配器微调 Adapter-based Fine-tuning
在前馈层和多头注意力层后增加适配器(在其他工作中,适配器的位置有所不同)。
适配器的参数初始化要保证增加适配器后,网络对应位置的输出基本不变。
适配器包含两个线性层,一个将特征的维度从d 缩小为m,另一个将维度变换为原始大小d, 则增
加的参数量为2md + d + m。
软提示微调
Soft Prompt
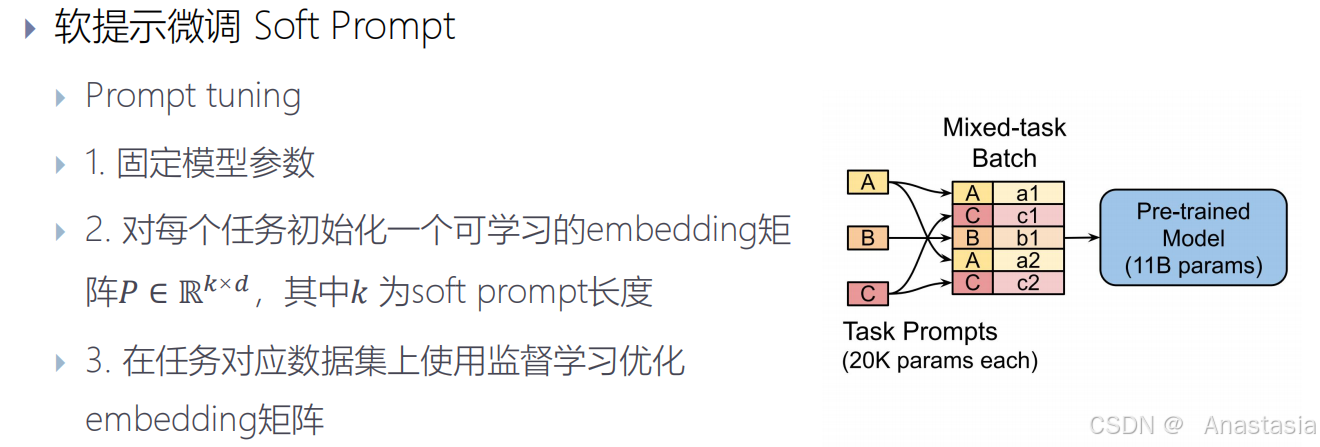
软提示微调 Soft Prompt:针对某种任务调整prompt可以使模型产生更好的回答,但离散的token只能通过尝试来调整,很难直接优化 ,可以优化一系列embeddings加在输入LLM的序列的前面 (soft prompt)。
Prompt tuning
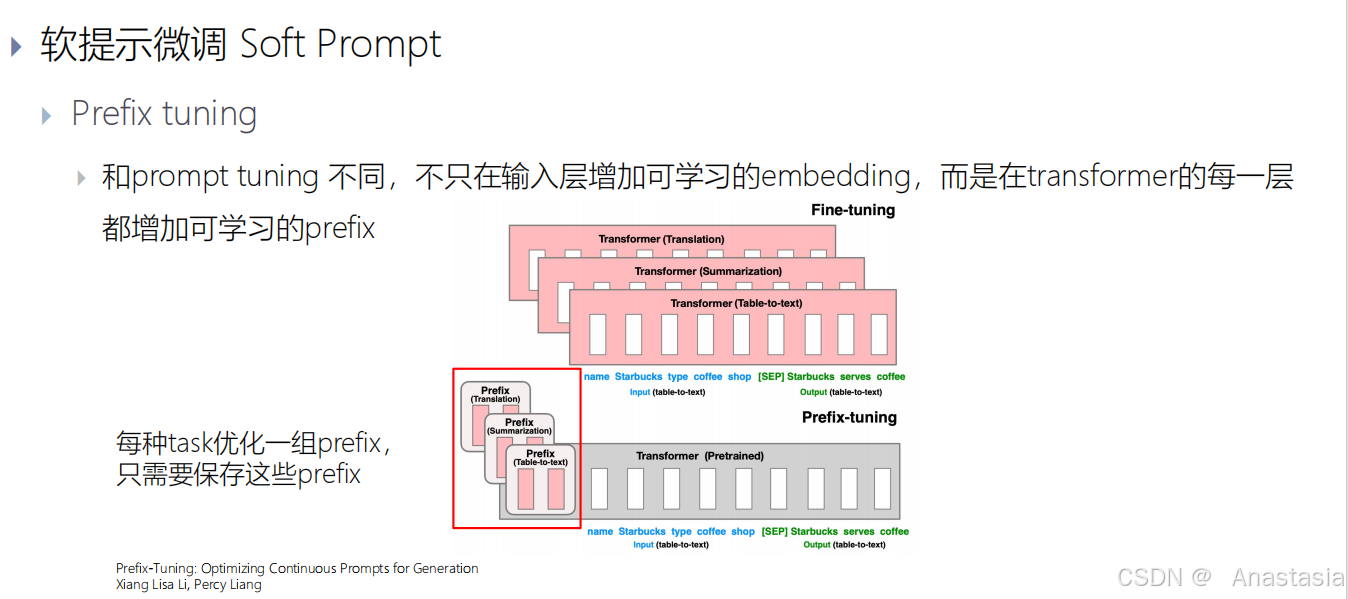
Prefix tuning
- 和prompt tuning 不同,不只在输入层增加可学习的embedding,而是在transformer的每一层都增加可学习的prefix。
- 每种task优化一组prefix, 只需要保存这些prefix。
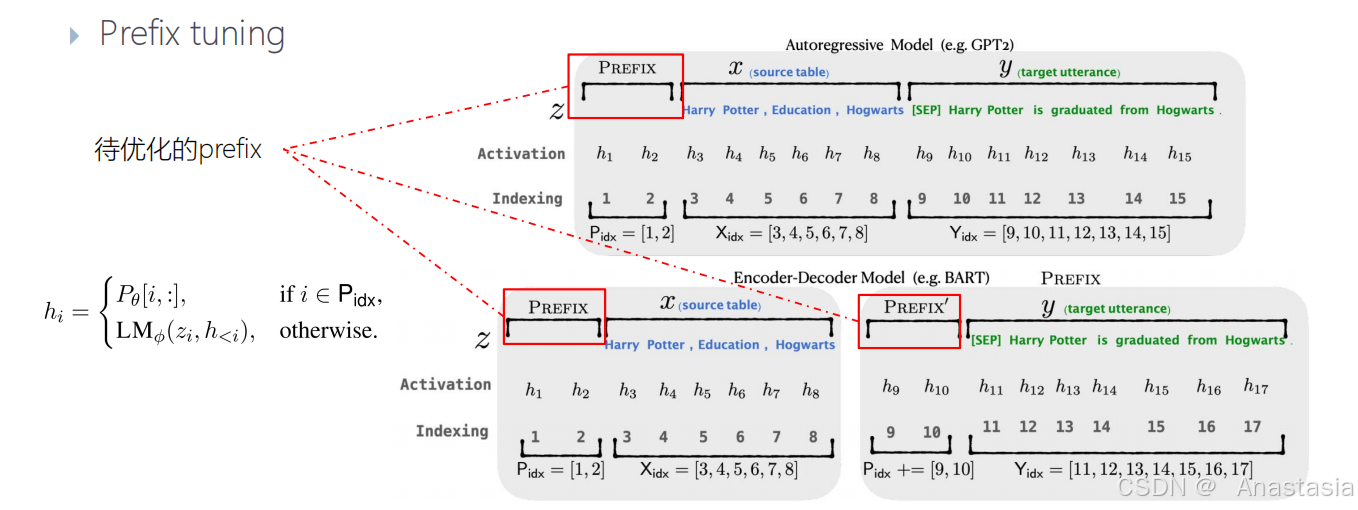
在transformer的每一层都增加可学习的prefix。

实际上,直接更新Prefix参数(Pθ)容易导致优化不稳定和性能的轻微下降。
可以使用一个神经网络把调Prefix参数(Pθ),变成一个神经网络和一个更小的矩阵。

选择性微调 Selective Fine-tuning
选择性微调 Selective Fine-tuning:只选择原始模型中的一小部分参数微调。
DiffPruning
DiffPruning:学习模型参数中有哪些参数需要更新,将新的参数表示为预训练参数和稀疏的更新参数的和。通过约束更新参数的L0-norm实现。
但是
L0-norm没有梯度无法直接优化,可以使用L1-norm或 Hard-Concrete distribution做可微近似。
L0约束可以不是逐参数的,而是将参数分组后按组约束。
Bitfit
Bitfit:在注意力层和前馈层中,只有偏差项b被更新。(只更新红色部分)

选择性微调选择的参数可以人工指定也可以通过学习得到,学习的方法并不总是比人工指定的好。
DiffPruning相比全参数微调需要更多的显存开销,因此比较大的模型可能难以使用。
重参数化微调 Reparameterized Fine-tuning
重参数化微调 Reparameterized Fine-tuning:微调时可能只需要优化原始参数空间中的一
个小的子空间就可以实现优化目标。把参数用维度较低的代理参数来表示,只更新代理参数来节省计算量。
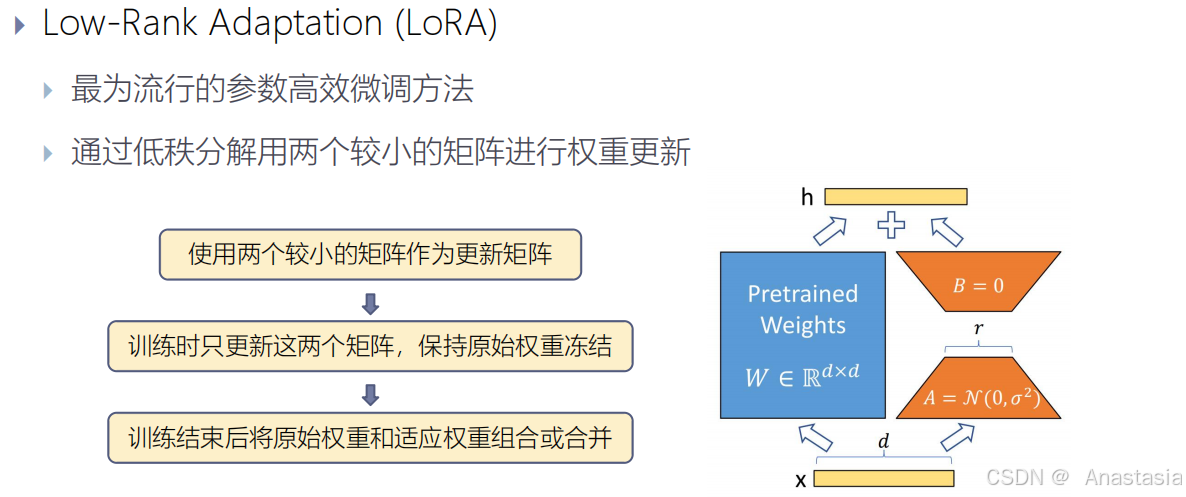
Low-Rank Adaptation (LoRA)
Low-Rank Adaptation (LoRA):最为流行的参数高效微调方法,通过低秩分解用两个较小的矩阵进行权重更新。训练时只更新这两个矩阵,保持原始权重冻结。训练结束后将原始权重和适应权重组合或合并。
LoRA 的核心思想是将预训练模型的权重矩阵分解为两个低秩矩阵的乘积,从而减少参数的数量。在微调过程中,只需要更新这两个低秩矩阵的参数,而无需修改预训练模型的其他参数。

Infused Adapter by Inhibiting and Amplifying Inner Activations (IA3)
Infused Adapter by Inhibiting and Amplifying Inner Activations (IA3)(通过抑制和放大内部激活的注入适配器 (IA3)):使用一个可学习的向量重新缩放内部激活,将这些学习到的向量注入到transformer的attention和feedforward模块中。这些学习到的向量是微调过程中唯一可训练的参数。
