注意力机制:让AI拥有黄金七秒记忆的魔法--(自注意力)
注意力机制:让AI拥有"黄金七秒记忆"的魔法–(自注意力)
⾃注意⼒就是⾃⼰对⾃⼰的注意,它允许模型在同⼀序列中的不同位置之间建⽴依赖关系。⽤我们刚才讲过的最简单的注意⼒来理解,如果我们把x2替换为x1⾃身,那么我们其实就实现了x1每⼀个位置对⾃身其他序列的所有位置的加权和。
如下:
import torch
import torch.nn.functional as F
# 一个形状为 (batch_size, seq_len, feature_dim) 的张量 x
x = torch.randn(2, 3, 4)
# 计算原始权重,形状为 (batch_size, seq_len, seq_len)
raw_weights = torch.bmm(x, x.transpose(1, 2))
# 对原始权重进行 softmax 归一化,形状为 (batch_size, seq_len, seq_len)
attn_weights = F.softmax(raw_weights, dim=2)
# 计算加权和,形状为 (batch_size, seq_len, feature_dim)
attn_outputs = torch.bmm(attn_weights, x)
知道了这个,那么下面继续展示一下如何对输入序列进行不同的线性变换,得到Q,K和V向量,然后应用放缩点积注意力即可:
# 一个形状为 (batch_size, seq_len, feature_dim) 的张量 x
x = torch.randn(2, 3, 4) # 形状 (batch_size, seq_len, feature_dim)
# 定义线性层用于将 x 转换为 Q, K, V 向量
linear_q = torch.nn.Linear(4, 4)
linear_k = torch.nn.Linear(4, 4)
linear_v = torch.nn.Linear(4, 4)
# 通过线性层计算 Q, K, V
Q = linear_q(x) # 形状 (batch_size, seq_len, feature_dim)
K = linear_k(x) # 形状 (batch_size, seq_len, feature_dim)
V = linear_v(x) # 形状 (batch_size, seq_len, feature_dim)
# 计算 Q 和 K 的点积,作为相似度分数 , 也就是自注意力原始权重
raw_weights = torch.bmm(Q, K.transpose(1, 2)) # 形状 (batch_size, seq_len, seq_len)
# 将自注意力原始权重进行缩放
scale_factor = K.size(-1) ** 0.5 # 这里是 4 ** 0.5
scaled_weights = raw_weights / scale_factor # 形状 (batch_size, seq_len, seq_len)
# 对缩放后的权重进行 softmax 归一化,得到注意力权重
attn_weights = F.softmax(scaled_weights, dim=2) # 形状 (batch_size, seq_len, seq_len)
# 将注意力权重应用于 V 向量,计算加权和,得到加权信息
attn_outputs = torch.bmm(attn_weights, V) # 形状 (batch_size, seq_len, feature_dim)
print(" 加权信息 :", attn_outputs)
加权信息 : tensor([[[ 0.5676, -0.0132, -0.8214, -0.0548],
[ 0.5352, -0.1170, -0.5392, -0.0256],
[ 0.6141, -0.1343, -0.5587, -0.0331]],
[[ 0.5973, -0.2426, -0.3217, -0.0335],
[ 0.5996, -0.1914, -0.2840, 0.0152],
[ 0.6117, -0.2507, -0.3363, -0.0404]]], grad_fn=<BmmBackward0>)
1.多头自注意力
多头⾃注意⼒(Multi-head Attention)机制是注意⼒机制的⼀种扩展,它可以帮助模型从不同的表示⼦空间捕获输⼊数据的多种特征。具体⽽⾔,多头⾃注意⼒在计算注意⼒权重和输出时,会对Q、K、V向量分别进⾏多次线性变换,从⽽获得不同的头(Head),并进⾏并⾏计算
如下图所示:
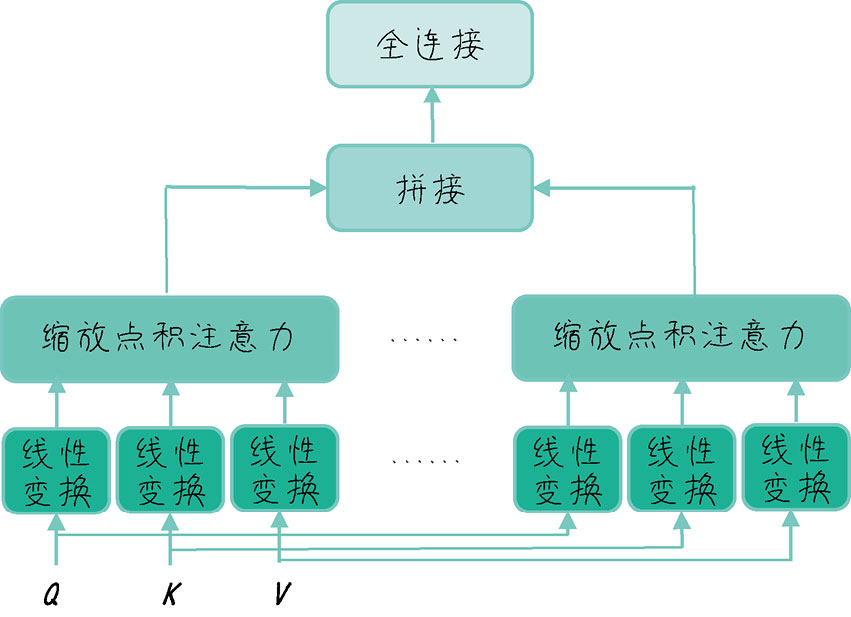
以下是多头⾃注意⼒的计算过程。
(1)初始化:设定多头⾃注意⼒的头数。每个头将处理输⼊数据的⼀个⼦空间。
(2)线性变换:对Q、K、V向量进⾏数次线性变换,每次变换使⽤不同的权重矩阵。这样,我们可以获得多组不同的Q、K、V向量。
(3)缩放点积注意⼒:将每组Q、K、V向量输⼊缩放点积注意⼒中进⾏计算,每个头将⽣成⼀个加权输出。
(4)合并:将所有头的加权输出拼接起来,并进⾏⼀次线性变换,得到多头⾃注意⼒的最终输出。
- 假设我们有一个输入序列的表示矩阵 X(例如编码器的输出或者词嵌入),
- 我们通过三个不同的线性层(也就是不同的权重矩阵)分别计算 Query、Key 和 Value:
- q = X W q q=XW_q q=XWq
- k = X W k k=XW_k k=XWk
- v = X W v v= XW_v v=XWv
- 这里, W q W_q Wq、 W k W_k Wk 和 W v W_v Wv 是模型在训练过程中学习到的参数矩阵。
多头⾃注意⼒机制的优势在于,通过同时学习多个⼦空间的特征,可以提⾼模型捕捉⻓距离依赖和不同语义层次的能⼒。
如下列代码:
import torch
import torch.nn.functional as F
# 一个形状为 (batch_size, seq_len, feature_dim) 的张量 x
x = torch.randn(2, 3, 4) # 形状 (batch_size, seq_len, feature_dim)
# 定义头数和每个头的维度
num_heads = 2
head_dim = 2
# feature_dim 必须是 num_heads * head_dim 的整数倍
assert x.size(-1) == num_heads * head_dim
# 定义线性层用于将 x 转换为 Q, K, V 向量
linear_q = torch.nn.Linear(4, 4)
linear_k = torch.nn.Linear(4, 4)
linear_v = torch.nn.Linear(4, 4)
# 通过线性层计算 Q, K, V
Q = linear_q(x) # 形状 (batch_size, seq_len, feature_dim)
K = linear_k(x) # 形状 (batch_size, seq_len, feature_dim)
V = linear_v(x) # 形状 (batch_size, seq_len, feature_dim)
# 将 Q, K, V 分割成 num_heads 个头
def split_heads(tensor, num_heads):
batch_size, seq_len, feature_dim = tensor.size()
head_dim = feature_dim // num_heads
output = tensor.view(batch_size, seq_len, num_heads, head_dim).transpose(1, 2)
return output # 形状 (batch_size, num_heads, seq_len, feature_dim)
Q = split_heads(Q, num_heads) # 形状 (batch_size, num_heads, seq_len, head_dim)
K = split_heads(K, num_heads) # 形状 (batch_size, num_heads, seq_len, head_dim)
V = split_heads(V, num_heads) # 形状 (batch_size, num_heads, seq_len, head_dim)
# 计算 Q 和 K 的点积,作为相似度分数 , 也就是自注意力原始权重
raw_weights = torch.matmul(Q, K.transpose(-2, -1)) # 形状 (batch_size, num_heads, seq_len, seq_len)
# 对自注意力原始权重进行缩放
scale_factor = K.size(-1) ** 0.5
scaled_weights = raw_weights / scale_factor # 形状 (batch_size, num_heads, seq_len, seq_len)
# 对缩放后的权重进行 softmax 归一化,得到注意力权重
attn_weights = F.softmax(scaled_weights, dim=-1) # 形状 (batch_size, num_heads, seq_len, seq_len)
# 将注意力权重应用于 V 向量,计算加权和,得到加权信息
attn_outputs = torch.matmul(attn_weights, V) # 形状 (batch_size, num_heads, seq_len, head_dim)
# 将所有头的结果拼接起来
def combine_heads(tensor, num_heads):
batch_size, num_heads, seq_len, head_dim = tensor.size()
feature_dim = num_heads * head_dim
output = tensor.transpose(1, 2).contiguous().view(batch_size, seq_len, feature_dim)
return output# 形状 : (batch_size, seq_len, feature_dim)
attn_outputs = combine_heads(attn_outputs, num_heads) # 形状 (batch_size, seq_len, feature_dim)
# 对拼接后的结果进行线性变换
linear_out = torch.nn.Linear(4, 4)
attn_outputs = linear_out(attn_outputs) # 形状 (batch_size, seq_len, feature_dim)
print(" 加权信息 :", attn_outputs)
多头自注意力机制就是将输⼊向量投影到多个向量空间,在每个向量空间中执⾏点积注意⼒计算,然后连接各头的结果。
在实际应⽤中,多头⾃注意⼒通常作为更复杂模型(如Transformer)的⼀个组成部分。这些复杂的模型通常包含其他组件,例如前馈神经⽹络(Feed-Forward Neural Network)和层归⼀化(Layer Normalization),以提⾼模型的表达能⼒和稳定性。
2.注意力掩码
注意⼒中的掩码机制,不同于BERT训练过程中的那种对训练⽂本的“掩码”。注意⼒掩码的作⽤是避免模型在计算注意⼒分数时,将不相关的单词考虑进来。掩码操作可以防⽌模型学习到不必要的信息。
要直观地解释掩码,我们先回忆⼀下填充(Padding)的概念。在NLP任务中,我们经常需要将不同⻓度的⽂本输⼊模型。为了能够批量处理这些⽂本,我们需要将它们填充⾄相同的⻓度。
以这段有关损失函数的代码为例。
criterion = nn.CrossEntropyLoss(ignore_index=word2idx_en['']) # 损失函数
这段代码中的ignore_index=word2idx_en[‘’],就是为了告诉模型,是附加的冗余信息,模型在反向传播更新参数的时候没有必要关注它,因此也没有什么单词会被翻译成。
填充掩码(Padding Mask)的作⽤和上⾯损失函数中的ignore_index参数有点类似,都是避免在计算注意⼒分数时,将填充位置的单词考虑进来(⻅右图)。因为填充位置的单词对于实际任务来说是⽆意义的,⽽且可能会引⼊噪声,影响模型的性能。

加⼊了掩码机制之后的注意⼒如下图所示,我们会把将注意⼒权重矩阵与⼀个注意⼒掩码矩阵相加,使得不需要的信息所对应的权重变得⾮常⼩(接近负⽆穷)。然后,通过应⽤softmax函数,将不需要的信息对应的权重变得接近于0,从⽽实现忽略它们的⽬的。
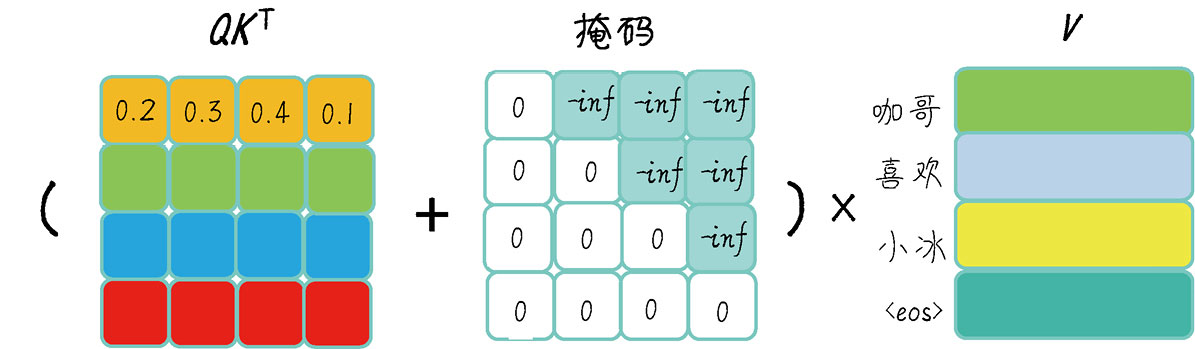
在Transformer中,使⽤了⾃注意⼒机制、多头⾃注意⼒机制和掩码,不仅有前⾯介绍的填充掩码,还有⼀种解码器专⽤的后续注意⼒掩码(Subsequent Attention Mask),简称后续掩码,也叫前瞻掩码(Look-ahead Masking),这是为了在训练时为解码器遮蔽未来的信息。