每日一题--数据库
数据库索引的原理是什么,为什么它能加快查询速度?
MySQL InnoDB 引擎是用了B+树作为了索引的数据结构。
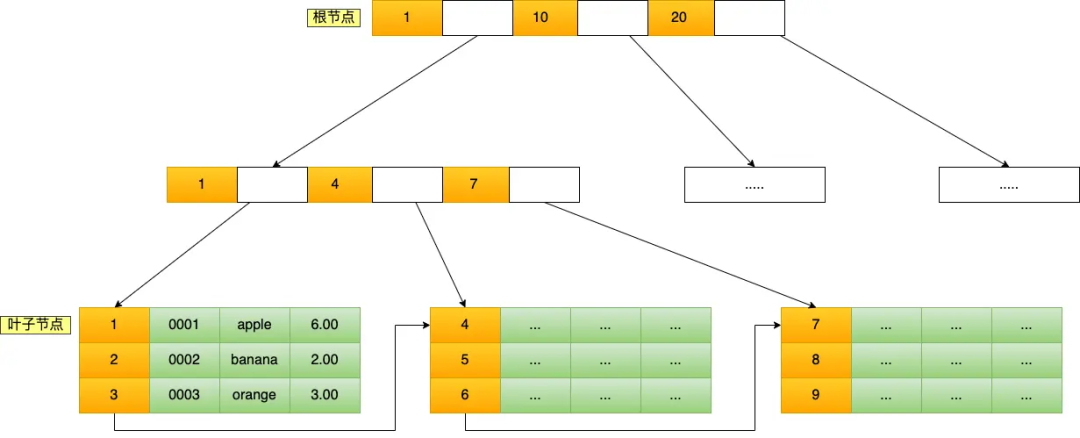
B+Tree 是一种多叉树,叶子节点才存放数据,非叶子节点只存放索引,而且每个节点里的数据是按主键顺序存放的。每一层父节点的索引值都会出现在下层子节点的索引值中,因此在叶子节点中,包括了所有的索引值信息,并且每一个叶子节点都有两个指针,分别指向下一个叶子节点和上一个叶子节点,形成一个双向链表。
主键索引的 B+Tree 如图所示:
null
比如,我们执行了下面这条查询语句:
select * from product where id= 5;
这条语句使用了主键索引查询 id 号为 5 的商品。查询过程是这样的,B+Tree 会自顶向下逐层进行查找:
-
将 5 与根节点的索引数据 (1,10,20) 比较,5 在 1 和 10 之间,所以根据 B+Tree的搜索逻辑,找到第二层的索引数据 (1,4,7);
-
在第二层的索引数据 (1,4,7)中进行查找,因为 5 在 4 和 7 之间,所以找到第三层的索引数据(4,5,6);
-
在叶子节点的索引数据(4,5,6)中进行查找,然后我们找到了索引值为 5 的行数据。
数据库的索引和数据都是存储在硬盘的,我们可以把读取一个节点当作一次磁盘 I/O 操作。那么上面的整个查询过程一共经历了 3 个节点,也就是进行了 3 次 I/O 操作。
B+Tree 存储千万级的数据只需要 3-4 层高度就可以满足,这意味着从千万级的表查询目标数据最多需要 3-4 次磁盘 I/O,所以B+Tree 相比于 B 树和二叉树来说,最大的优势在于查询效率很高,因为即使在数据量很大的情况,查询一个数据的磁盘 I/O 依然维持在 3-4次。