【ODHead】BEVDet的 CenterHead的推理和拓展到蒸馏损失的算法细节
文章目录
- 背景常识
- 1、BEVDet的CenterHead整体方案
- 2、蒸馏部分
- 3、输出 preds_dicts 部分
- 3.1、headmap
- 3.2、bbox
- 3.3、Mask掩膜
- 3.4、损失
背景常识
在BEVDet和BEVFormer里,使用了不同的3D detection head(BEVDet用了centerhead,BEVFormer用了deformable detr)
BEVDet 主要采用 CenterHead,类似于 CenterNet 风格的检测头:
- Heatmap 预测(目标中心点)
- 3D 目标框回归(偏移量、尺寸、旋转角等)
- 速度预测(用于运动状态估计)
BEVDepth 在 BEVDet 的基础上增强了深度信息,并通常采用 Anchor-Free Head 或者 CenterHead:
- 增加了 Depth Estimation Head,用于估计深度(Depth Regression)
- 保持 Heatmap-based Head 进行 3D 目标检测
- 可能集成 IoU 预测分支 以优化最终目标框
CenterNet 和 CenterPoint 都是基于中心点(Center-based)的目标检测方法,但它们的应用和改进方向有所不同。
CenterNet
- 主要用于 2D 目标检测
- 通过 Heatmap 预测目标中心点
- 使用 回归分支 预测尺寸、偏移等信息
- 核心思想:将目标检测转化为 Keypoint Detection
CenterPoint
- 主要用于 3D 目标检测(激光雷达点云检测)
- 继承 CenterNet 的中心点思想
- 采用 Pillar-based 或 Voxel-based 方式 处理点云
- 采用 两阶段检测:
第一阶段:使用 CenterNet-like 方式预测目标中心点、尺寸、角度等
第二阶段:基于目标中心点进行进一步的 Box Refinement(如 IoU 预测)
1、BEVDet的CenterHead整体方案
Head 是在得到不同的Task 后,分别对每个Task 配置一个独立的separate_head,SeparateHead这个类型应该是有定义的(我接下来找找),然后加入nn.ModuleList()列表。
def __init__(self,common_heads=dict(), separate_head=dict(type='SeparateHead', init_bias=-2.19, final_kernel=3),tasks):
num_classes = [len(t['class_names']) for t in tasks]
for num_cls in num_classes:
heads = copy.deepcopy(common_heads)
heads.update(dict(heatmap=(num_cls, num_heatmap_convs)))
separate_head.update(
in_channels=share_conv_channel, heads=heads, num_cls=num_cls)
self.task_heads.append(builder.build_head(separate_head))
def run():
for task in self.task_heads:
ret_dicts.append(task(x))
return ret_dicts
SeparateHead在mmdet3d v0.9.0 (31/12/2020) 修复了bugFix channel setting in the SeparateHead of CenterPoint (#228),具体定义位置在
mmdet3d\models\dense_heads\centerpoint_head.py 定义了 SeparateHead
2、蒸馏部分
1、对于Heatmap是进行CrossEntropyLossKD蒸馏老师和学生的损失
2、输出bbox,采用loss_bbox蒸馏老师和学生的损失
3、输出 preds_dicts 部分
利用 enumerate() 可遍历的数据对象preds_dicts 。preds_dicts 是一个包含多个字典的列表。
for task_id, preds_dict in enumerate(preds_dicts):
这里买呢task_id 很重要的作用是索引真值
3.1、headmap
预测 heatmap 是preds_dict[0][‘heatmap’]
真值 heatmap就是heatmaps[task_id]) / max(num_pos, 1),这个触发需不需要应该都可以,除法可能对损失更加柔和。其中num_pos是heatmaps[task_id].eq(1).float().sum().item()计算的真值中的“热力图中值为 1 的位置个数”
3.2、bbox
预测的 preds_dict[0]['anno_box'] 是 preds_dict[0]['reg'], preds_dict[0]['height'],preds_dict[0]['dim'], preds_dict[0]['rot'],preds_dict[0]['vel'])这些参数torch.cat()联合起来的结果。
然后对preds_dict[0]['anno_box'] 进行H*W维度处理,从 [B, H, W, C] 转换为 [B, H * W, C],即将 H 和 W 展平为一个维度,形成一个二维张量。
然后根据真值获得ind目标框索引,形状为 [B, max_obj]。max_obj 是每张图像中最多的目标数目(最大目标数)。ind 中的每个元素表示目标框在特征图中的位置(好好理解),这就是为何preds_dict[0]['anno_box'] 进行H*W维度处理的原因。我草草画个图:
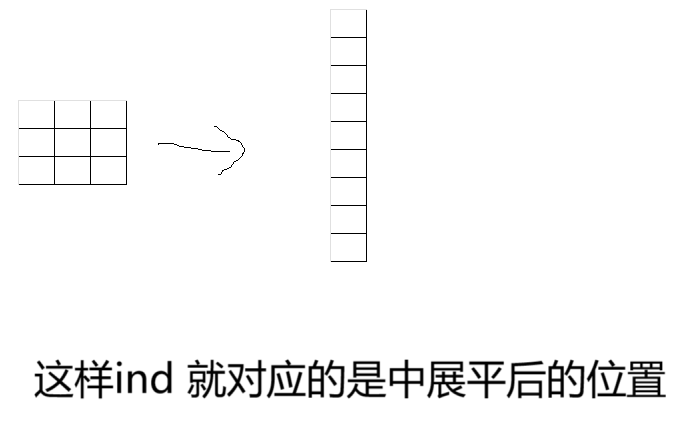
因为preds_dict[0]['anno_box'] 进行H*W维度处理后有一个C维度,因此ind扩展后的形状为 [B, max_obj, C]维度。
然后利用gather(1, ind).从 feat 中提取特征,理所当然,维度是 [B, max_obj, C]。
3.3、Mask掩膜
mask 是从真值获得,维度应该[B, H, W],然后先unsqueeze到[B, H, W,1],然后再变成和真值 target_box 一样的维度,我估计也是[B, H, W, 1] 维度。然后再和target_box 相乘,掩膜 mask 中有效的部分(即 target_box 中有效的部分),而无效的部分会被标记为 0。
Mask 掩膜随后会和我们自定义的超参数相乘,摇身一变,成为了target_box 的权重,精细化调节损失。
3.4、损失
loss_bbox()计算bbox和target_box差值,Mask是权重。
如果是其他输出的损失呢?刚都说了 preds_dict[0]['anno_box'] 是 preds_dict[0]['anno_box'] 是 preds_dict[0]['reg'], preds_dict[0]['height'],preds_dict[0]['dim'], preds_dict[0]['rot'],preds_dict[0]['vel'])
我们设置其他参数的列表,然后for循环提取对应的参数,
name_list=['xy','z','whl','yaw','vel']
clip_index = [0,2,3,6,8,10] # TODO reg=(2, 2), height=(1, 2), dim=(3, 2), rot=(2, 2), vel=(2, 2))
for reg_task_id in range(len(name_list)):
pred_tmp = pred[...,clip_index[reg_task_id]:clip_index[reg_task_id+1]]
这样就可以得到其他参数了。
真值也是一样的,self.loss_bbox计算损失。
target_box_tmp = target_box[...,clip_index[reg_task_id]:clip_index[reg_task_id+1]]
bbox_weights_tmp = bbox_weights[...,clip_index[reg_task_id]:clip_index[reg_task_id+1]]
(正文完)