LanceDB快速入门之基本操作与API一览
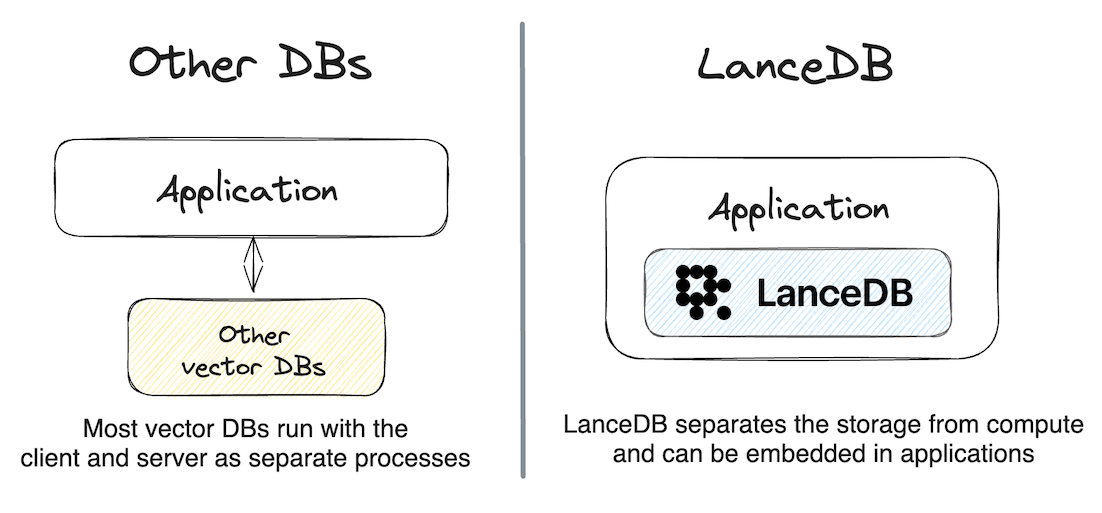
LanceDB可以以多种方式运行
- 可以嵌入到现有后端(如您的 Django、Flask、Node.js 或 FastAPI 应用程序)中
- 直接从如 Jupyter 笔记本等客户端应用程序中用于分析工作负载
- 部署为远程无服务器数据库
安装
Python:
pip install lancedb
TypeScript:
npm install @lancedb/lancedb
连接数据库
Python:
同步
import lancedb
import pandas as pd
import pyarrow as pa
uri = "data/sample-lancedb"
db = lancedb.connect(uri)
异步
import lancedb
import pandas as pd
import pyarrow as pa
uri = "data/sample-lancedb"
db = await lancedb.connect_async(uri)
TypeScript:
import * as lancedb from "@lancedb/lancedb";
import * as arrow from "apache-arrow";
const db = await lancedb.connect(databaseDir);
创建表
根据初始数据创建表
如果在创建表时有数据需要插入,那么可以同时创建表并将数据插入其中。数据的架构将被用作表的架构。
Python
如果表已经存在,LanceDB 默认会抛出一个错误。如果想覆盖该表,可以在 create_table 方法中传入 mode=“overwrite”。
同步
data = [
{"vector": [3.1, 4.1], "item": "foo", "price": 10.0},
{"vector": [5.9, 26.5], "item": "bar", "price": 20.0},
]
tbl = db.create_table("my_table", data=data)
异步:
data = [
{"vector": [3.1, 4.1], "item": "foo", "price": 10.0},
{"vector": [5.9, 26.5], "item": "bar", "price": 20.0},
]
tbl = await db.create_table("my_table_async", data=data)
还可以直接传入一个 pandas DataFrame:
df = pd.DataFrame(
[
{"vector": [3.1, 4.1], "item": "foo", "price": 10.0},
{"vector": [5.9, 26.5], "item": "bar", "price": 20.0},
]
)
tbl = await db.create_table("table_from_df_async", df)
pandas 是一个开源的 Python 数据分析和数据处理库,它提供了快速、灵活和表达力强的数据结构,旨在使“关系”或“标签”数据的处理工作变得既简单又直观。pandas 适合于许多不同类型的数据分析任务,比如数据清洗和准备、数据转换、以及数据分析与建模。
pandas 的核心数据结构是 DataFrame,它是一个二维的、大小可变的、有标签的数据结构,可以存储具有不同数据类型(整数、字符串、浮点数、Python 对象等)的列。DataFrame 既有行索引也有列索引,这使得数据的访问、筛选和操作变得非常灵活和方便。
pandas 还提供了大量的函数和方法来进行数据清洗、转换、聚合、连接等操作,以及进行时间序列分析和可视化等高级功能。此外,pandas 还支持与其他 Python 库(如 NumPy、SciPy、Matplotlib、Seaborn、Scikit-learn 等)的集成,使得数据分析的整个过程可以更加高效和无缝。
TypeScript:
const _tbl = await db.createTable(
"myTable",
[
{ vector: [3.1, 4.1], item: "foo", price: 10.0 },
{ vector: [5.9, 26.5], item: "bar", price: 20.0 },
],
{ mode: "overwrite" },
);
在内部机制中,LanceDB 读取 Apache Arrow 数据,并使用 Lance 格式将其持久化保存到磁盘上。
在使用嵌入模型时,建议使用LanceDB的嵌入API,以便在后台自动为数据和查询创建向量表示。
创建空表
Python
同步
schema = pa.schema([pa.field("vector", pa.list_(pa.float32(), list_size=2))])
tbl = db.create_table("empty_table", schema=schema)
异步:
schema = pa.schema([pa.field("vector", pa.list_(pa.float32(), list_size=2))])
tbl = await db.create_table("empty_table_async", schema=schema)
TypeScript
const schema = new arrow.Schema([
new arrow.Field("id", new arrow.Int32()),
new arrow.Field("name", new arrow.Utf8()),
]);
const emptyTbl = await db.createEmptyTable("empty_table", schema);
打开既存的表
Python
同步:
tbl = db.open_table("my_table")
异步
const _tbl = await db.openTable("myTable");
列出所有的表:
print(db.table_names())
TypeScript
const _tbl = await db.openTable("myTable");
列出所有的表:
const tableNames = await db.tableNames();
添加数据到表
Python
同步:
# Option 1: Add a list of dicts to a table
data = [
{"vector": [1.3, 1.4], "item": "fizz", "price": 100.0},
{"vector": [9.5, 56.2], "item": "buzz", "price": 200.0},
]
tbl.add(data)
# Option 2: Add a pandas DataFrame to a table
df = pd.DataFrame(data)
tbl.add(data)
异步:
# Option 1: Add a list of dicts to a table
data = [
{"vector": [1.3, 1.4], "item": "fizz", "price": 100.0},
{"vector": [9.5, 56.2], "item": "buzz", "price": 200.0},
]
await tbl.add(data)
# Option 2: Add a pandas DataFrame to a table
df = pd.DataFrame(data)
await tbl.add(data)
TypeScript
const data = [
{ vector: [1.3, 1.4], item: "fizz", price: 100.0 },
{ vector: [9.5, 56.2], item: "buzz", price: 200.0 },
];
await tbl.add(data);
搜索最近邻
Python
同步:
tbl.search([100, 100]).limit(2).to_pandas()
异步:
await tbl.vector_search([100, 100]).limit(2).to_pandas()
TypeScript:
const res = await tbl.search([100, 100]).limit(2).toArray();
默认情况下,LanceDB会对数据集进行暴力扫描以找到K个最近邻(KNN)。对于包含超过50,000个向量的表格,建议创建一个近似最近邻(ANN)索引以加快搜索速度。LanceDB允许您按如下方式在表格上创建ANN索引:
Python 同步:
tbl.create_index(num_sub_vectors=1)
Python 异步:
await tbl.create_index("vector")
TypeScript
await tbl.createIndex("vector");
为什么需要手动创建索引?
LanceDB不会自动创建近似最近邻(ANN)索引,原因有两个。首先,它旨在通过基于磁盘的索引实现极快的检索速度,而创建这样的索引可能涉及复杂的预处理和资源分配。其次,数据和查询的工作负载可能非常多样化,因此不存在适用于所有情况的统一索引配置。LanceDB提供了许多参数,以便用户能够微调索引的大小、查询延迟和准确性。
从表删除行
Python
同步:
tbl.delete('item = "fizz"')
异步:
await tbl.delete('item = "fizz"')
TypeScript
await tbl.delete('item = "fizz"');
删除谓词是一个SQL表达式,它支持在搜索中的where()子句(在Rust中为only_if())所使用的相同表达式。这些表达式可以根据需要简单或复杂。
删除表
Python
同步
db.drop_table("my_table")
异步
await db.drop_table("my_table_async")
TypeScript
await db.dropTable("myTable");
使用嵌入式API
在使用嵌入模型时,可以利用嵌入API。该API会在数据摄入和查询时自动对数据进行向量化处理,并且与流行的嵌入模型(如OpenAI、Hugging Face、Sentence Transformers、CLIP等)内置了集成功能。
Embedding API指的是一种用于处理嵌入(Embedding)操作的应用程序编程接口(API)。嵌入通常指的是将文本、图像或其他类型的数据转换为低维向量表示的过程,这些向量能够捕捉原始数据的某些关键特征或语义信息。
在文本处理领域,Embedding API常用于将文本数据转换为向量形式,以便进行后续的分析、分类、聚类、搜索等操作。这些向量通常是通过深度学习模型(如Word2Vec、BERT、GPT等)训练得到的,能够反映单词或句子之间的语义关系。
Python
这里目前仅有同步的API, 异步的尚未提供
from lancedb.pydantic import LanceModel, Vector
from lancedb.embeddings import get_registry
db = lancedb.connect("/tmp/db")
func = get_registry().get("openai").create(name="text-embedding-ada-002")
class Words(LanceModel):
text: str = func.SourceField()
vector: Vector(func.ndims()) = func.VectorField()
table = db.create_table("words", schema=Words, mode="overwrite")
table.add([{"text": "hello world"}, {"text": "goodbye world"}])
query = "greetings"
actual = table.search(query).limit(1).to_pydantic(Words)[0]
print(actual.text)
TypeScript
import * as lancedb from "@lancedb/lancedb";
import "@lancedb/lancedb/embedding/openai";
import { LanceSchema, getRegistry, register } from "@lancedb/lancedb/embedding";
import { EmbeddingFunction } from "@lancedb/lancedb/embedding";
import { type Float, Float32, Utf8 } from "apache-arrow";
const db = await lancedb.connect(databaseDir);
const func = getRegistry()
.get("openai")
?.create({ model: "text-embedding-ada-002" }) as EmbeddingFunction;
const wordsSchema = LanceSchema({
text: func.sourceField(new Utf8()),
vector: func.vectorField(),
});
const tbl = await db.createEmptyTable("words", wordsSchema, {
mode: "overwrite",
});
await tbl.add([{ text: "hello world" }, { text: "goodbye world" }]);
const query = "greetings";
const actual = (await tbl.search(query).limit(1).toArray())[0];