【RAG从入门到精通系列】【RAG From Scratch 系列教程5: Retrieval】
目录
- 前言
- 一、概述
- 1-1、RAG概念
- 1-2、前置知识
- 1-2-1、ModelScopeEmbeddings 词嵌入模型
- 1-2-2、FAISS介绍&安装 (向量相似性搜索)
- 1-2-3、Tiktoken 分词工具
- 二、Rag From Scratch: Retrieval
- 2-1、Re-ranking(多查询检索重排)
- 2-1-1、倒数排名融合(Reciprocal Rank Fusion, RRF)
- 算法原理
- 公式
- 步骤
- 优点
- 应用场景
- 示例
- 2-1-2、加载网页内容
- 2-1-3、分割文档
- 2-1-4、向量化文档并创建向量存储
- 2-1-5、初始化LLM
- 2-1-6、相关查询问题的生成
- 2-1-7、检索相关文档
- 2-1-8、构建RAG链
- 总结
前言
"检索增强生成”(RAG)系列教程5:Retrieval 检索模块 的详细介绍。
一、概述
1-1、RAG概念
概念:目前的LLM通常是用很多已经存在的文字数据训练出来的。这就导致一个问题:LLM对最新的信息或者个人隐私信息不太了解,因为这些内容在训练时没有被包括进去。虽然可以通过“微调”(也就是针对特定任务再训练一下LLM)来解决这个问题,但微调成本很高,技术相对比较复杂,现在出现了一种新的方法,叫“检索增强生成”(RAG)。这个方法的思路是:从外部的数据源(比如数据库或者网页)中找到相关的资料,然后把这些资料“喂”给聊天机器人,帮助它更好地回答问题。这种方法就像是给聊天机器人提供了一个“外挂”,让它能够接触到更多的知识。

1-2、前置知识
1-2-1、ModelScopeEmbeddings 词嵌入模型
ModelScope Embeddings 是阿里巴巴达摩院推出的嵌入模型,旨在将文本、图像等数据转换为高维向量,便于机器学习模型处理。这些嵌入向量能够捕捉数据的语义信息,广泛应用于自然语言处理(NLP)、计算机视觉(CV)等领域。
安装库:
pip install modelscope
Demo:
from langchain.embeddings import ModelScopeEmbeddings
model_id = "damo/nlp_corom_sentence-embedding_english-base"
embeddings = ModelScopeEmbeddings(model_id=model_id)
text = "This is a test document."
query_result = embeddings.embed_query(text)
doc_results = embeddings.embed_documents(["foo"])
输出:


1-2-2、FAISS介绍&安装 (向量相似性搜索)
FAISS(Facebook AI Similarity Search)是由 Meta(前 Facebook)开发的一个高效相似性搜索和密集向量聚类库。它主要用于在大规模数据集中进行向量相似性搜索,特别适用于机器学习和自然语言处理中的向量检索任务。FAISS 提供了多种索引类型和算法,可以在 CPU 和 GPU 上运行,以实现高效的向量搜索。
FAISS 的主要特性
- 高效的相似性搜索:支持大规模数据集的高效相似性搜索,包括精确搜索和近似搜索。
- 多种索引类型:支持多种索引类型,如扁平索引(Flat Index)、倒排文件索引(IVF)、产品量化(PQ)等。
- GPU 加速:支持在 GPU 上运行,以加速搜索过程。
- 批量处理:支持批量处理多个查询向量,提高搜索效率。
- 灵活性:支持多种距离度量,如欧氏距离(L2)、内积(Inner Product)等。
安装:
# cpu或者是GPU版本
pip install faiss-cpu
# 或者
pip install faiss-gpu
Demo分析: 使用 LangChain 库来处理一个长文本文件,将其分割成小块,然后使用 Hugging Face 嵌入和 FAISS 向量存储来执行相似性搜索。
- CharacterTextSplitter:用于将长文本分割成小块。
- FAISS:用于创建向量数据库。
- TextLoader:用于加载文本文件。
- HuggingFaceEmbeddings:另一个用于生成文本嵌入向量的类。
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.document_loaders import TextLoader
from langchain.embeddings import HuggingFaceEmbeddings
# This is a long document we can split up.
with open('./index.txt', encoding='utf-8') as f:
state_of_the_union = f.read()
text_splitter = CharacterTextSplitter(
chunk_size = 100,
chunk_overlap = 0,
)
docs = text_splitter.create_documents([state_of_the_union])
embeddings = HuggingFaceEmbeddings()
db = FAISS.from_documents(docs, embeddings)
query = "学生的表现怎么样?"
docs = db.similarity_search(query)
print(docs[0].page_content)
输出:

Notice: 查询分数,这里的分数为L2距离,因此越低越好

1-2-3、Tiktoken 分词工具
Tiktoken 是 OpenAI 开发的一个高效的分词工具,专门用于处理 GPT 系列模型(如 GPT-3、GPT-4)的文本输入和输出。它能够将自然语言文本转换为模型可以理解的 token 序列,同时支持从 token 序列还原为文本。Tiktoken 的设计目标是高效、灵活且易于集成到各种自然语言处理(NLP)任务中。
安装:
pip install tiktoken
使用:
import tiktoken
# 编码器的加载
encoder = tiktoken.get_encoding("cl100k_base")
text = "这是一个示例文本。"
# 对文本进行编码
tokens = encoder.encode(text)
print(tokens)
# 对文本进行解码
decoded_text = encoder.decode(tokens)
print(decoded_text)
二、Rag From Scratch: Retrieval
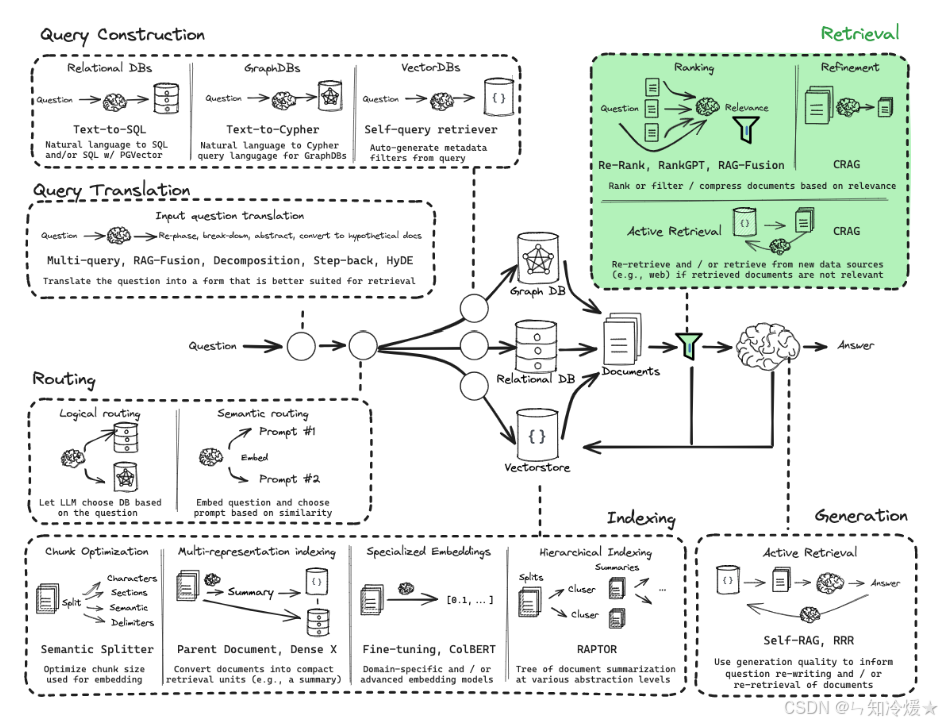
2-1、Re-ranking(多查询检索重排)
概述: RAG-Fusion与多查询检索大部分来看比较相似,区别在于。
- 相关问题生成:RAG-Fusion直接要求生成与输入问题相关的查询,而多查询检索更侧重于生成多个不同视角的查询,以克服基于距离的相似性搜索的局限性。
- 文档检索与融合部分:多查询检索在进行这部分内容时,直接对检索到的文档进行去重处理,而RAG-Fusion,则引入了倒数排名融合(Reciprocal Rank Fusion, RRF) 算法,对多个检索器返回的文档进行融合和重排。

2-1-1、倒数排名融合(Reciprocal Rank Fusion, RRF)
倒数排名融合(Reciprocal Rank Fusion, RRF)是一种用于融合多个排序列表的算法,常用于信息检索和推荐系统。它通过将不同排序列表中的排名进行加权融合,生成一个综合排序列表。
算法原理
RRF 的核心思想是将每个排序列表中的排名转换为倒数,然后进行加权求和,最终根据总和重新排序。
公式
对于每个项目 d ,其在融合后的得分S(d) 计算公式为:

其中:
- n 是排序列表的数量。
- r i ( d ) r_i(d) ri(d) 是项目 d 在第 i 个排序列表中的排名(从 1 开始)。
- k 是一个常数,通常取 60,用于平滑排名差异。
步骤
- 输入多个排序列表:每个列表包含一组项目及其排名。
- 计算每个项目的 RRF 得分:根据公式计算每个项目在所有列表中的 RRF 得分。
- 按得分排序:根据 RRF 得分对所有项目进行降序排列,生成最终的融合排序列表。
优点
- 简单易实现:算法逻辑简单,易于实现和调试。
- 无需归一化:RRF 不需要对原始排名进行归一化处理。
- 鲁棒性强:对个别列表的噪声和异常值具有较强的鲁棒性。
应用场景
- 信息检索:融合多个搜索引擎的搜索结果。
- 推荐系统:融合多个推荐算法的输出。
- 数据融合:融合来自不同数据源的排序数据。
示例
假设有两个排序列表:
- 列表 A: [A, B, C]
- 列表 B: [B, A, C]
取 ( k = 60 ),计算 RRF 得分:
-
项目 A:
- 列表 A 排名 1: 1 60 + 1 = 1 61 \frac{1}{60 + 1} = \frac{1}{61} 60+11=611
- 列表 B 排名 2: 1 60 + 2 = 1 62 \frac{1}{60 + 2} = \frac{1}{62} 60+21=621
- 总得分: 1 61 + 1 62 ≈ 0.0326 \frac{1}{61} + \frac{1}{62} \approx 0.0326 611+621≈0.0326
-
项目 B:
- 列表 A 排名 2: 1 60 + 2 = 1 62 \frac{1}{60 + 2} = \frac{1}{62} 60+21=621
- 列表 B 排名 1: 1 60 + 1 = 1 61 \frac{1}{60 + 1} = \frac{1}{61} 60+11=611
- 总得分: 1 62 + 1 61 ≈ 0.0326 \frac{1}{62} + \frac{1}{61} \approx 0.0326 621+611≈0.0326
-
项目 C:
- 列表 A 排名 3: 1 60 + 3 = 1 63 \frac{1}{60 + 3} = \frac{1}{63} 60+31=631
- 列表 B 排名 3: 1 60 + 3 = 1 63 \frac{1}{60 + 3} = \frac{1}{63} 60+31=631
- 总得分: 1 63 + 1 63 ≈ 0.0317 \frac{1}{63} + \frac{1}{63} \approx 0.0317 631+631≈0.0317
最终排序为 [A, B, C] 或 [B, A, C],取决于具体实现, RRF 是一种简单有效的排序融合算法,适用于多种场景,能够有效提升排序结果的准确性和鲁棒性。
2-1-2、加载网页内容
- WebBaseLoader:从指定 URL 加载网页内容。
- bs4.SoupStrainer:只解析特定类名的 HTML 元素(如 post-content、post-title、post-header),以减少解析时间。
- blog_docs:加载后的文档对象。
import bs4
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
blog_docs = loader.load()
2-1-3、分割文档
- RecursiveCharacterTextSplitter:将文档递归分割成小块。
- chunk_size=300:每个块的最大 token 数量。
- chunk_overlap=50:块之间的重叠 token 数量,用于保持上下文连贯。
- splits:分割后的文档块。
# Split
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=300,
chunk_overlap=50)
# Make splits
splits = text_splitter.split_documents(blog_docs)
输出:

2-1-4、向量化文档并创建向量存储
- ModelScopeEmbeddings:使用 ModelScope 嵌入模型将文档块转换为向量。
- FAISS:将嵌入向量存储到 FAISS 向量数据库中。
- retriever:创建一个检索器,用于查询相关文档。
from langchain_community.embeddings import ModelScopeEmbeddings
from langchain_openai import ChatOpenAI
import os
from langchain_community.vectorstores import FAISS
vectorstore = FAISS.from_documents(
documents=splits,
embedding=ModelScopeEmbeddings(),
)
retriever = vectorstore.as_retriever()
2-1-5、初始化LLM
- ChatOpenAI:初始化一个 LLM 实例,使用 qwen-max 模型。
- temperature=0: 控制生成文本的随机性,值为 0 时生成确定性结果。
- max_tokens=1024:限制生成文本的最大长度。
- base_url:指定 API 的基础 URL。
from langchain_openai import ChatOpenAI
import os
llm = ChatOpenAI(
model="qwen-max",
temperature=0,
max_tokens=1024,
timeout=None,
max_retries=2,
api_key=os.environ.get('DASHSCOPE_API_KEY'),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
2-1-6、相关查询问题的生成
# RAG-Fusion: Related
template = """You are a helpful assistant that generates multiple search queries based on a single input query. \n
Generate multiple search queries related to: {question} \n
Output (4 queries):"""
prompt_rag_fusion = ChatPromptTemplate.from_template(template)
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
generate_queries = (
prompt_rag_fusion
| llm
| StrOutputParser()
| (lambda x: x.split("\n"))
)
generate_queries.invoke({"question": '论如何解决提出无理要求的员工?'})
输出:
[‘1. 如何有效沟通处理员工的不合理要求’, ‘2. 企业应对员工无理请求的最佳实践’, ‘3. 解决工作场所中不切实际的员工诉求的方法’, ‘4. 管理技巧:面对员工过分要求时的策略与解决方案’]
2-1-7、检索相关文档
reciprocal_rank_fusion: 倒数排名融合(RRF)函数(1、融合分数计算 2、重新排序文档,即按照融合分数对文档进行降序排序。)
- results:一个包含多个排序列表的列表,每个子列表包含一组排序后的文档。
- k:RRF 公式中的平滑常数(默认值为 60)。主要是为了防止除0错误,并且平衡低排名文档的影响。
from langchain.load import dumps, loads
from operator import itemgetter
def reciprocal_rank_fusion(results: list[list], k=60):
""" Reciprocal_rank_fusion that takes multiple lists of ranked documents
and an optional parameter k used in the RRF formula """
# Initialize a dictionary to hold fused scores for each unique document
fused_scores = {}
# Iterate through each list of ranked documents
for docs in results:
# Iterate through each document in the list, with its rank (position in the list)
for rank, doc in enumerate(docs):
# Convert the document to a string format to use as a key (assumes documents can be serialized to JSON)
# 使用 dumps 将文档序列化为字符串,以便用作字典的键。
doc_str = dumps(doc)
# If the document is not yet in the fused_scores dictionary, add it with an initial score of 0
if doc_str not in fused_scores:
fused_scores[doc_str] = 0
# Retrieve the current score of the document, if any
previous_score = fused_scores[doc_str]
# Update the score of the document using the RRF formula: 1 / (rank + k)
fused_scores[doc_str] += 1 / (rank + k)
# Sort the documents based on their fused scores in descending order to get the final reranked results
# 重新排序后,使用 loads 将文档字符串反序列化为原始格式。
reranked_results = [
(loads(doc), score)
for doc, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)
]
# Return the reranked results as a list of tuples, each containing the document and its fused score
return reranked_results
question = "What is task decomposition for LLM agents?"
retrieval_chain_rag_fusion = generate_queries | retriever.map() | reciprocal_rank_fusion
docs = retrieval_chain_rag_fusion.invoke({"question": question})
print(docs)
输出:

2-1-8、构建RAG链
# RAG
template = """Answer the following question based on this context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
final_rag_chain = (
{"context": retrieval_chain_rag_fusion,
"question": itemgetter("question")}
| prompt
| llm
| StrOutputParser()
)
print(final_rag_chain.invoke({"question":question}))
输出:

参考文章:
rag-from-scratch 官方GitHub仓库.
总结
家家有本难念的经🤕