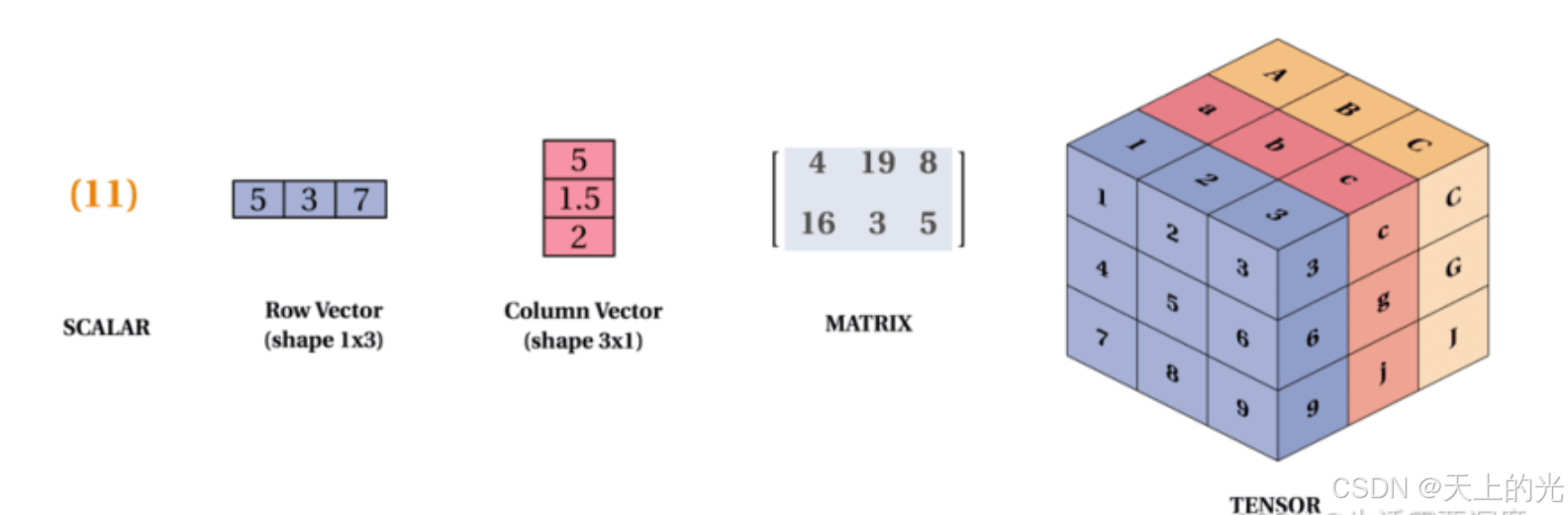
机器学习框架
一、什么是机器学习?
一句话描述,让计算机寻找函数(function)的过程。
我们说,一切事物的运行都有其底层逻辑,如果能够用数学表达式描述出这个逻辑,那么就可以由机器代替人进行分析和解决问题。然而,有许多函数可能十分复杂,单凭人类的直觉经验和大脑的计算能力无法获取到这个函数,这时,我们就可以借助计算机的强大算力,帮我们找到,或无限逼近这个真实函数。
二,机器学习有哪些种?
回归任务(Regression)
回归任务的输出是一个数值(scalar),一般用作预测任务,根据以往的数据预测,如:明天的温度,明天的氧气浓度
分类任务(Classification)
分类任务的输出是,从我们预先设定好的几种结果中返回一个结果,提供的是一个决策的服务。如:输入一张图片,输出图片中是猫还是狗。亦或者,输入一封邮件的文本内容,返回一个结果,该邮件Yes/No是一封垃圾邮件。AlphaGo围棋对弈的过程,本质就是在19*19的格子里,做出选择把棋子下在哪里。
结构化学习(Structured Learning)
让机器的生成具有创造性,如生成一篇文章,生成一张图片。
三、机器学习包含哪几个部分?
模型(model),
| 网络模型 | 对应场景 | 特点 | 编程调用方式(以PyTorch为例) |
|---|---|---|---|
| VGG | 图像分类,特征提取 | 深层卷积神经网络,结构简单,使用3x3卷积和2x2池化 | torchvision.models.vgg16(pretrained=True)(以VGG16为例) |
| ResNet | 图像分类,目标检测,分割 | 引入残差连接,解决深层网络训练难题,提高性能 | torchvision.models.resnet50(pretrained=True)(以ResNet50为例) |
| Inception | 图像分类,特征提取 | 使用不同尺寸的卷积核,增加网络宽度,提高特征提取能力 | 自定义实现或使用torchvision中的Inception模型(如果可用) |
| YOLO | 目标检测 | 端到端检测,速度快,适用于实时检测场景 | 需要自定义实现或使用第三方库(如ultralytics/yolov5) |
| LaneNet | 车道线检测 | 专门设计用于车道线检测,包括实例分割和车道线拟合两部分 | 需要自定义实现或使用开源实现(如github.com/Mayank7659/LaneNet) |
| U-Net | 医学图像分割,一般图像分割 | 对称编码器-解码器结构,跳跃连接,适用于像素级分类任务 | 自定义实现或使用torchvision中的U-Net(如果可用,否则需自定义) |
| Transformer | 自然语言处理,图像分类,检测 | 自注意力机制,捕捉全局依赖关系,适用于序列和图像数据 | 自定义实现或使用torch.nn.Transformer(适用于NLP)或结合CNN的图像Transformer |
注意:
- 对于某些网络模型(如YOLO、LaneNet),PyTorch的
torchvision库可能不直接提供预训练模型或实现,因此可能需要从第三方库或开源项目中获取。 - 编程调用方式中的
pretrained=True参数表示加载预训练权重,这对于迁移学习和快速启动项目非常有用。 - 对于Transformer在图像领域的应用,通常需要结合卷积神经网络(CNN)来提取图像特征,然后再应用Transformer模块进行序列建模或全局依赖关系捕捉。
损失函数(Optimization),
| 损失函数 | 应用场景 | 公式 | 实现 |
|---|---|---|---|
| 均方误差(MSE) | 线性回归、神经网络回归等回归问题 | M S E = 1 2 n ∑ i = 1 n ( y i − y ^ i ) 2 MSE = \frac{1}{2n}\sum_{i=1}^{n}(y_i - \hat{y}_i)^2 MSE=2n1∑i=1n(yi−y^i)2 | mse = np.mean((y_true - y_pred) ** 2) |
| 均方根误差(RMSE) | 与MSE相同,但误差度量更直观 | R M S E = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 RMSE = \sqrt{\frac{1}{n}\sum_{i=1}^{n}(y_i - \hat{y}_i)^2} RMSE=n1∑i=1n(yi−y^i)2 | rmse = np.sqrt(np.mean((y_true - y_pred) ** 2)) |
| 平均绝对误差(L1损失) | 对异常值不敏感的回归问题 | L 1 = 1 n ∑ i = 1 n ∣ y i − y ^ i ∣ L1 = \frac{1}{n}\sum_{i=1}^{n}|y_i - \hat{y}_i| L1=n1∑i=1n∣yi−y^i∣ | mae = mean_absolute_error(y_true, y_pred) |
| 交叉熵损失函数(二分类) | 二分类问题 | L ( y , p ^ ) = − y log ( p ^ ) − ( 1 − y ) log ( 1 − p ^ ) L(y, \hat{p}) = -y\log(\hat{p}) - (1-y)\log(1-\hat{p}) L(y,p^)=−ylog(p^)−(1−y)log(1−p^) | loss = tf.keras.losses.BinaryCrossentropy()(y_true, y_pred) |
| 交叉熵损失函数(多分类) | 多分类问题 | L = − ∑ i y i log ( p i ) L = -\sum_{i} y_i \log(p_i) L=−∑iyilog(pi) | 对于多分类问题,可以使用CategoricalCrossentropy或SparseCategoricalCrossentropy(取决于标签的格式) |
| Hinger损失函数 | 支持向量机(SVM)等最大间隔分类器 | L ( y , y ^ ) = max ( 0 , 1 − y y ^ ) L(y, \hat{y}) = \max(0, 1 - y\hat{y}) L(y,y^)=max(0,1−yy^) | hinge_loss_value = np.mean(np.maximum(0, margin - y_true * y_pred)) |
| Huber损失函数 | 结合MSE和MAE优点,对异常值鲁棒的回归问题 | L H u b e r ( y , y ^ ) = { 1 2 ( y − y ^ ) 2 if ∣ y − y ^ ∣ ≤ δ δ ∣ y − y ^ ∣ − 1 2 δ 2 if ∣ y − y ^ ∣ > δ L_{Huber}(y, \hat{y}) = \begin{cases} \frac{1}{2}(y - \hat{y})^2 & \text{if } |y - \hat{y}| \leq \delta \\ \delta |y - \hat{y}| - \frac{1}{2}\delta^2 & \text{if } |y - \hat{y}| > \delta \end{cases} LHuber(y,y^)={21(y−y^)2δ∣y−y^∣−21δ2if ∣y−y^∣≤δif ∣y−y^∣>δ | loss = criterion(input, target) |
| IoU损失 | 预测结果与真实标签的重叠程度,常用于车道线检测 |
将所有x,y的历史数据带入,获得所有的误差loss,求和取平均值。这个数值最小的时刻,所对应的w和b应为最佳。
优化器(Optimizer),常见的有SGD、Adam等
| 优化器 | 对应场景 | 特点 | 编程实现方式(以PyTorch为例) |
|---|---|---|---|
| Adam | 大多数深度学习场景,特别是非平稳目标 | 自适应学习率,结合AdaGrad和RMSProp的优点,收敛速度快且稳定 | torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08) |
| SGD | 大规模数据集,计算资源有限 | 简单,易于实现,适合处理稀疏数据,可能陷入局部最优解 | torch.optim.SGD(params, lr=0.01, momentum=0.9, dampening=0, weight_decay=0, nesterov=False) |
| RMSprop | 非平稳目标,在线和递归学习 | 基于均方根传播的自适应学习率,适用于处理非平稳目标 | torch.optim.RMSprop(params, lr=0.001, alpha=0.99, eps=1e-08, weight_decay=0, momentum=0, centered=False) |
| Adagrad | 稀疏数据,需要自适应学习率 | 根据参数的历史梯度平方和来调整学习率,适用于稀疏梯度 | torch.optim.Adagrad(params, lr=0.01, lr_decay=0, weight_decay=0, initial_accumulator_value=0) |
| Adamax | 需要更高学习率稳定性的场景 | Adam优化器的一个变体,基于无穷范数进行参数更新 | torch.optim.Adamax(params, lr=0.002, betas=(0.9, 0.999), eps=1e-08, weight_decay=0) |
| Adadelta | 无需手动设置学习率,适用于在线学习 | 根据梯度平方的累积自适应调整学习率,减少了学习率选择的复杂性 | torch.optim.Adadelta(params, lr=1.0, rho=0.9, eps=1e-06, weight_decay=0) |
注意:
params是需要优化的模型参数的迭代器。lr是学习率。- 其他参数是特定于优化器的配置选项,可以根据需要进行调整。
四、数据预处理
数据归一化
原因:神经网络通常假设输入数据服从均值为0,标准差为1的正态分布。如果数据未进行归一化处理,不同特征的量纲差异可能导致模型训练困难。
解决方案:对数据进行归一化处理,例如使用零均值归一化或线性函数归一化(Min-Max Scaling)。
数据预处理
原因:数据中存在噪声、异常值或缺失值,可能影响模型的训练效果。
解决方案:对数据进行清洗,去除噪声和异常值,填补缺失值,并进行适当的数据增强。
标签设置
原因:数据标签设置错误,导致模型无法正确学习数据的真实分布。
解决方案:检查数据标签是否正确,确保标签与数据对应。
样本量不足或分布不均
原因:样本量不足可能导致模型过拟合,样本分布不均可能导致模型无法学习到数据的真实分布。
解决方案:增加样本量,确保样本覆盖数据的各种可能情况;对样本进行重采样或数据增强,以改善样本分布。
五、网络框架
基础变量
batch_size=128 //每次训练在训练集中取batchsize个样本训练
hidden_size=64 //隐藏层数
learning_rate=0.001 //学习率
num_epoch=10 //1个epoch等于使用训练集中的全部样本训练一次
张量转换
torchvision图像处理;torchtext自然语言处理;torchaudio音频处理
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5,),(0.5,),)])
数据集
trainset = torchvision.datasets.MINST(root="./data",train=True,download=True,transform=transform)
testset = torchvision.datasets.MINST(root="./data",train=False,download=True,transform=transform)
数据缓存器
train_data_loader = torch.utils.data.DataLoader(trainset, batch_size=batch_size,shuffle=True)
test_data_loader = torch.utils.data.DataLoader(testset, batch_size=batch_size,shuffle=False)
输入输出
input_size = 784 //图像展成一维后的大小
num_classes = 10 //若为分类任务设置输出种类
网络
class Net(nn.Module):
def __init__(self,input_size,hidden_size, num_classes):
super(Net, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 =nn.Linear(hidden_size, num_classes)
def forward(self, x):
out = self.fc1(x.view(-1,input_size))
out = self.relu(out)
out = self.fc2(out)
return out
实例化
model = Net(inpute_size, hidden_size, num_classes)
损失函数
criterion = nn.CrossEntropyLoss()
优化器
optimizer = optim.SGD(model.parameters(), lr=Learning_rate)
存储损失值:
train_loss_list = []
test_loss_list = []
总批数(有多少batchs)
total_step = len(train_loader)
开始训练
for epoch in range(num_epochs):
for i,(images, labels)in enumerate(train_loader):
//前向传播
outputs = model(images) //模型加载图片
Loss =criterion(outputs,labels) //计算损失
//反向传播
optimizer.zero_grad()//清除之前的梯度
Loss.backward()//更新损失
optimizer.step()//更新优化器
train_loss_list.append(loss.item())//存储损失值
if(i+ 1)% 100 == 0: //每100批打印一次信息
print('Epoch [{}/{}l,step [{}/{}],Train Loss: {:.4f}'.format(epoch + 1,num_epochs,i + 1,total_step,loss.item()))
开始验证
model.eval()//评估模式,停止训练
with torch.no_grad(:
test loss =0.0
for images,labels in test loader:
outputs = model(images)
Loss =criterion(outputs,labels)
test loss += loss.item()*images.size(0)//某批次的总损失求和
test loss /= len(test_loader.dataset)
test loss list.extend([test_loss] * total step)
//改回训练模式,打印结果
model.train()
print('Epoch [{}/{}], Test Loss: {:.4f}'.format(epoch + 1, num_epochs, test_loss))
图像化展示
plt.plot(train loss list, label='Train Loss')
plt.plot(test_loss_list,
label='Test Loss')
plt.title('Model Loss')
plt.xlabel('Iterations')
plt.ylabel('Loss')
plt.legend()
plt.show()
六、如何调参?
图像角度
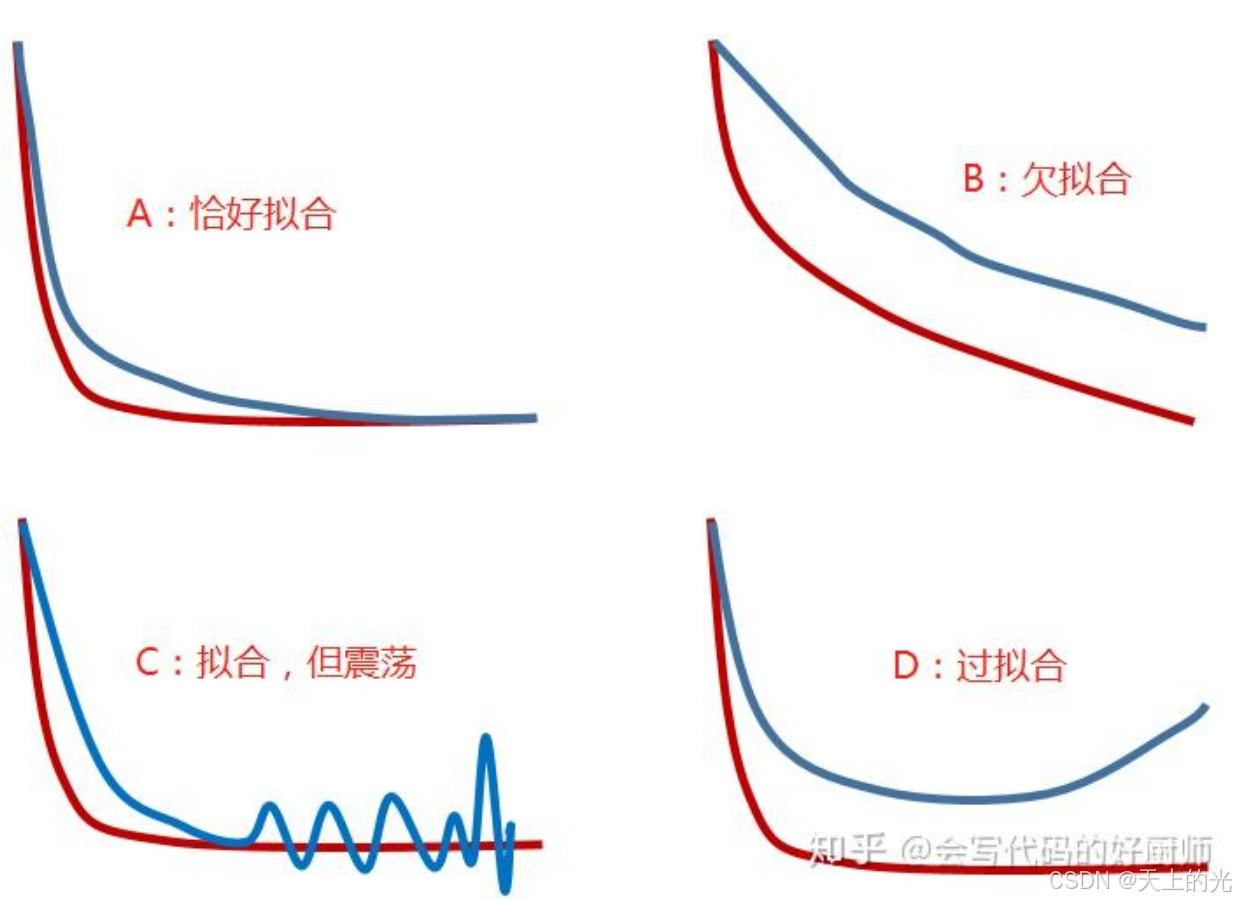
1、不收敛
网络不收敛一般涉及如下可能:
网络设计不合理
输入的图像数据有问题
2、过拟合
数据增强,样本数少了,旋转缩放平移裁切,增加数据
早停法,在验证集性能不再提升时停止训练
随机失活dropout
使用正则化
降低学习率
降低训练轮数
降低网络层数
降低神经元个数
3、欠拟合
增加训练轮数
提升网络层数
适当增加relu函数,引入非线性提升拟合
过度正则化
4、震荡收敛
降低学习率
减少批次数据
参数角度
1、学习率
原因:学习率过大可能导致模型在训练过程中震荡,无法收敛;学习率过小可能导致模型收敛速度过慢。
解决方案:可以尝试从较大的学习率开始,逐步减小,直到找到合适的学习率。
2、单层神经元个数
逐步增加法:从较小的数量开始,如输入层神经元数量的75%,逐步增加,观察模型在验证集上变化。当性能不再显著提升时,停止。
网格搜索和随机搜索:在预设的神经元数量范围内(如10到1000),使用网格搜索或随机搜索方法,遍历不同的神经元数量组合,找到使模型性能最优的配置。
经验公式:
平均数法则:隐藏层神经元数量 = (输入层神经元数量 + 输出层神经元数量) / 2。
K乘法法则:使用常数K(如2或3)乘以输入特征数量,作为隐藏层神经元数量的初步估计。
3、网络层数
简单任务:如线性回归、逻辑回归,可能只需要一层隐藏层,且神经元数量较少。
复杂任务:如图像识别、自然语言处理,可能需要多层隐藏层,且每层神经元数量较多,以提取高维特征。
4、激活函数选择错误
原因:激活函数选择不当可能导致模型在训练过程中梯度消失或梯度爆炸,无法收敛。
解决方案:根据任务需求选择合适的激活函数,如ReLU、Sigmoid、Tanh等。
根据任务类型选择
二分类问题:
输出层:优先选择Sigmoid函数,因为Sigmoid函数的输出范围在(0,1)之间,可以表示概率,适用于二分类问题的输出。
多分类问题:
输出层:优先选择Softmax函数,Softmax函数可以将输出转换为概率分布,适用于多分类问题的输出。
回归问题:
输出层:当目标值y可以是正数或负数时,优先选择线性函数;当目标值y只能取非负数时,ReLU函数也是一个不错的选择。
根据网络选择
输出层:
优先选择ReLU函数或其变体(如Leaky ReLU、PReLU等)。
ReLU函数计算简单,收敛速度快,且在一定程度上能够缓解梯度消失问题。
在训练过程中,如果ReLU函数导致梯度消失,可以尝试使用Leaky ReLU或PReLU等变体来解决。
对于某些特定任务(如循环神经网络RNN),Sigmoid和Tanh函数仍然具有一定的应用价值。但需要注意的是,这两个函数都存在梯度消失的问题,可能会影响网络的训练效果。
5、正则化不足
原因:正则化的主要目的是防止模型过拟合,通过限制模型参数的复杂度来提高模型的泛化能力。
解决方案:使用合适的正则化方法,如Dropout、L1正则化、L2正则化等。
选取正则化方法的经验
| 正则化方法 | 适用场景 | 特点 | 实际编程实现方法 |
|---|---|---|---|
| L1正则化(Lasso) | 特征选择,特别是当数据集中存在大量不相关或冗余特征时 | 通过添加模型参数绝对值的和作为惩罚项,使一些参数变为零 | 在库如scikit-learn中,使用Lasso类,设置alpha参数控制正则化强度 |
| L2正则化(Ridge) | 处理多重共线性问题,以及当模型对异常值较为敏感时 | 通过添加模型参数平方的和作为惩罚项,使参数值尽可能小,但不为零 | 在库如scikit-learn中,使用Ridge类,设置alpha参数控制正则化强度 |
| 弹性网络正则化 | 高维数据和特征选择任务 | 结合了L1正则化和L2正则化的优点,既可以实现特征选择,又可以处理多重共线性问题 | 在库如scikit-learn中,使用ElasticNet类,设置alpha和l1_ratio参数控制正则化强度和L1/L2比例 |
| Dropout正则化 | 神经网络模型,特别是当模型层数较多、神经元数量较大时 | 在训练过程中随机将一部分神经元的输出设置为零,防止神经元之间过度依赖 | 在深度学习框架如TensorFlow或PyTorch中,使用Dropout层,设置keep_prob或p参数控制保留神经元的概率 |
| 数据增强(Data Augmentation) | 图像、语音等需要处理大量数据且数据易于变换的任务 | 通过对训练数据进行随机变换或扩充来增加数据集的多样性 | 在图像处理库如OpenCV或PIL中,使用随机旋转、缩放、翻转等方法进行数据增强 |
根据任务类型选择
对于线性回归、逻辑回归等简单模型,可以选择L1正则化或L2正则化。
对于神经网络模型,特别是深度神经网络,可以选择Dropout正则化。
对于图像、语音等任务,可以选择数据增强作为正则化手段。
根据数据特点选择
当数据集中存在大量不相关或冗余特征时,可以选择L1正则化进行特征选择。
当数据集中特征之间存在多重共线性问题时,可以选择L2正则化或弹性网络正则化。
当数据量较少且难以收集更多数据时,可以选择数据增强来增加数据集的多样性。
根据模型复杂度选择
当模型复杂度较高、参数较多时,需要更强的正则化来防止过拟合。此时可以选择Dropout正则化或结合多种正则化方法。
当模型复杂度较低、参数较少时,可以选择较弱的正则化或不加正则化。
实验验证与调整
在实际应用中,可以通过实验验证不同正则化方法的效果,选择使模型性能最优的正则化方法。
同时,还可以根据实验结果调整正则化参数(如正则化系数λ)以达到更好的正则化效果。
6、权重初始化不当
原因:权重初始化不当可能导致模型在训练初期陷入局部最优解,无法继续收敛。
解决方案:使用合适的权重初始化方法,如He初始化、Xavier初始化等。
6、Batch Size设置不当
原因:过大的Batch Size可能导致网络卡在局部最优点,而过小的Batch Size则可能导致训练速度很慢且不易收敛
通用理论认为,GPU对2的幂次或8的倍数的Batch Size可以发挥出更好的性能。因此,在设置Batch Size时,可以考虑将其设置为16、32、64、128等数值。
网络基础部分参考视频