前馈神经网络 - 自动梯度计算
神经网络的参数主要通过梯度下降来进行优化,当确定了风险函数以及网络结构后,我们就可以手动用链式法则来计算风险函数对每个参数的梯度,并用代码进行实现。但是手动求导并转换为计算机程序的过程非常琐碎并容易出错,导致实现神经网络变得十分低效.实际上,参数的梯度可以让计算机来自动计算。
一、人工计算和自动梯度计算的区别
1. 核心区别:人工 vs. 自动化
| 维度 | 手动推导数学公式 | 符号微分(自动化) |
|---|---|---|
| 执行者 | 人类手动逐步推导(纸笔或教学场景) | 计算机代数系统(如 Mathematica、SymPy) |
| 过程 | 人工应用求导规则(如链式法则、乘积法则) | 程序自动解析表达式并应用符号微分规则 |
| 错误率 | 易因计算疏忽出错 | 严格遵循数学规则,无计算错误 |
| 效率 | 低效,耗时(尤其对复杂函数) | 高效,秒级生成复杂导数表达式 |
2. 处理能力对比
(1) 简单函数示例

| 方法 | 步骤 |
|---|---|
| 手动推导 | 人工逐项求导:幂函数导数 + 链式法则处理 sin(2x),可能需多次验算。 |
| 符号微分 | 输入表达式,系统自动输出 3x^2+2cos(2x),无需人工干预。 |
(2) 复杂函数示例
-
函数:

-
导数:需应用商法则、链式法则、乘积法则,手动推导可能需多步骤并易出错。
-
符号微分:直接输出结果,例如:
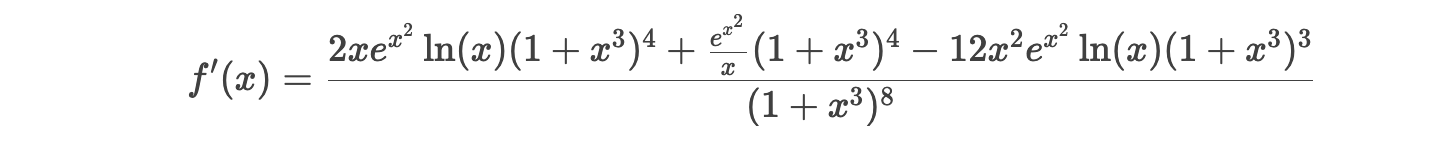
关键区别:符号微分可处理任意复杂度表达式,但结果可能冗长;手动推导在复杂时易出错且效率低。
3. 动态性与灵活性
| 场景 | 手动推导 | 符号微分 |
|---|---|---|
| 条件分支函数 | 可分情况讨论(如分段函数导数) | 需明确分段条件,处理能力有限 |
| 循环结构 | 可手动展开循环(如递归函数) | 无法处理动态生成的循环或递归 |
| 实时更新 | 可即时调整推导步骤 | 需重新解析整个表达式 |

-
符号微分:需明确输入分段条件,否则可能输出错误或未简化的表达式。
4. 表达式简化与优化
| 方法 | 策略 |
|---|---|
| 手动推导 | 人工合并同类项、因式分解,使表达式简洁(如 f′(x)=x(3x+2))。 |
| 符号微分 | 输出原始导数表达式,可能冗长(如 f′(x)=3x^2+2x 而非 x(3x+2))。 |
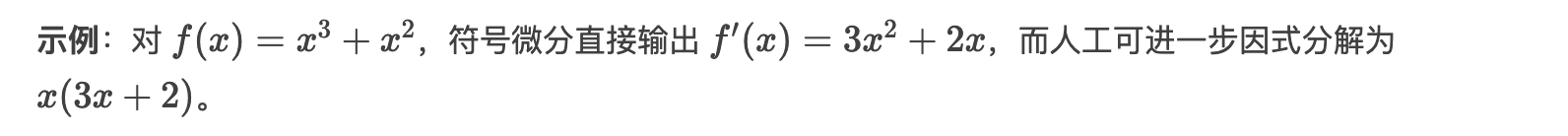
5. 实际应用场景
| 场景 | 手动推导 | 符号微分 |
|---|---|---|
| 教学/学习 | 帮助学生理解导数原理 | 较少使用,可能用于验证结果 |
| 工程开发 | 不适用于复杂模型 | 生成解析梯度用于优化算法(如早期 TensorFlow 的符号梯度) |
| 科研验证 | 验证符号微分结果是否正确 | 快速生成复杂模型的梯度表达式 |
总结
-
手动推导是人工驱动的数学过程,适用于教学、简单函数或验证符号微分结果,但效率低且易出错。
-
符号微分是计算机自动化的符号计算,适用于生成复杂函数的精确导数表达式,但结果可能冗长且无法处理动态结构。
核心区别:符号微分通过算法自动化生成导数,而手动推导依赖人工数学能力,两者互补而非替代。在实际深度学习中,符号微分逐渐被自动微分(如反向传播)取代,因其更适应动态计算图和高效内存管理。
二、自动梯度计算的三种主要方法
自动梯度计算是深度学习中用于高效计算函数导数的关键技术,尤其在训练神经网络时至关重要。以下是其详细解释及主要类型:
(一)自动梯度计算的定义
自动梯度计算(Automatic Gradient Computation)是一种通过算法自动计算函数在某一点的导数值的方法,无需手动推导数学公式。它通过分解复杂函数为基本操作(如加法、乘法、激活函数等),并应用链式法则逐层计算梯度。
核心目标:
在神经网络的反向传播中,高效计算损失函数对参数的梯度(如权重和偏置),用于参数优化(如梯度下降)。
(二)自动梯度计算的三种主要方法
1. 符号微分(Symbolic Differentiation)
原理:
通过数学表达式直接推导导数公式。例如,对函数 f(x)=x^2,符号微分会得到导数表达式 f′(x)=2x。
示例:

优点:
-
生成精确的导数表达式。
-
适用于简单函数或符号计算工具(如 Mathematica)。
缺点:
-
表达式膨胀:复杂函数的导数表达式可能极其冗长(如深层神经网络)。
-
无法处理分支或循环:动态计算图难以用符号表示。
应用场景:
数学软件、简单函数的解析求导。
2. 数值微分(Numerical Differentiation)
原理:
通过有限差分近似导数。例如,使用中心差分公式:
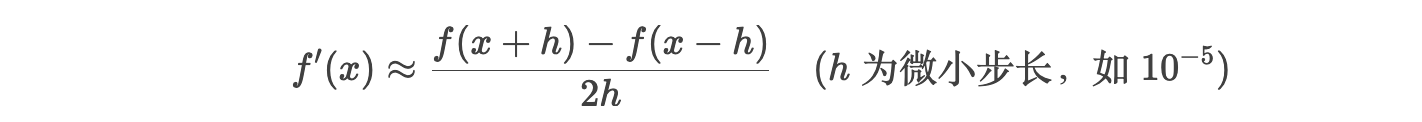
示例:

优点:
-
实现简单,无需数学推导。
-
适用于任何可计算的函数。
缺点:
-
计算误差:舍入误差和截断误差影响精度。
-
计算成本高:每个参数需多次前向计算,复杂度为 O(n)(n 是参数数量)。
应用场景:
快速验证梯度计算的正确性(如梯度检查)。
3. 自动微分(Automatic Differentiation, AD)
原理:
将函数分解为一系列基本操作(如加减乘除、指数函数等),通过链式法则动态计算梯度。自动微分有两种模式:
(1) 前向模式(Forward Mode)
-
计算方式:
沿计算图从输入到输出逐层计算导数。-
每个中间变量同时计算其值和导数。
-
适用于输入维度低、输出维度高的情况。
-
示例:

优点:
-
适合输入维度低的问题。
缺点:
-
输入维度高时计算成本高(复杂度 O(n),n 是输入维度)。
(2) 反向模式(Reverse Mode,即反向传播)
-
计算方式:
沿计算图从输出到输入反向传播梯度。-
先执行一次前向传播计算所有中间值。
-
再反向计算梯度,适用于输入维度高、输出维度低的情况。
-
示例:

优点:
-
输入维度高时效率高(复杂度 O(m),m 是输出维度)。
-
深度学习中的标准方法(如 PyTorch、TensorFlow 的反向传播)。
缺点:
-
需要存储所有中间变量,内存占用较高。
(三)自动微分在深度学习中的应用
深度学习框架(如 PyTorch、TensorFlow)通过构建**计算图(Computational Graph)**实现自动微分:
-
前向传播:记录所有操作,构建计算图。
-
反向传播:从损失函数开始,反向遍历计算图,应用链式法则计算梯度。
示例代码(PyTorch):
import torch
# 定义输入和参数
x = torch.tensor([2.0], requires_grad=True)
y = torch.tensor([3.0], requires_grad=True)
# 前向计算
a = x * y
b = torch.sin(x)
f = a + b
# 反向传播自动计算梯度
f.backward()
print(x.grad) # 输出:tensor([3.4161]) = y + cos(2) = 3 + (-0.4161)
print(y.grad) # 输出:tensor([2.])(四)总结:自动梯度计算方法的对比
| 方法 | 原理 | 优点 | 缺点 | 应用场景 |
|---|---|---|---|---|
| 符号微分 | 解析推导导数公式 | 精确 | 表达式膨胀,无法处理动态计算图 | 数学软件、简单函数 |
| 数值微分 | 有限差分近似导数 | 实现简单 | 计算误差大,效率低 | 梯度检查 |
| 自动微分 | 链式法则分解计算图 | 高效精确,支持复杂模型 | 需要存储中间变量(反向模式) | 深度学习框架(如PyTorch) |
自动微分(尤其是反向模式)是深度学习的核心,因为它高效地解决了高维参数空间的梯度计算问题,使得训练深层神经网络成为可能。