Adversarial AtA学习(第二十三周周报)
摘要
本文系统性地阐述了针对深度学习模型的对抗性攻击(Adversarial Attack)的核心原理与方法。文章开篇定义了对抗性攻击的概念:通过向原始输入添加人眼难以察觉的微小扰动,以误导模型的预测结果。接着,文章区分了非定向攻击与更具威胁的定向攻击,并强调了攻击需满足的约束条件,即扰动必须足够小(通常用L2或L∞范数度量)以确保其隐蔽性。随后,文章重点讲解了生成对抗样本的核心算法——基于梯度下降的输入优化,其本质是固定模型参数,将输入本身作为可优化变量,通过迭代计算损失函数的梯度并更新输入,同时通过投影操作严格满足扰动约束。最后,文章点明了快速梯度符号法(FGSM)等高效攻击方法的本质:即利用梯度的方向而非大小,在约束空间内进行最大化扰动。
Abstract
This article provides a systematic explanation of the core principles and methods of adversarial attacks against deep learning models. It begins by defining the concept of an adversarial attack: the act of misleading a model's prediction by adding imperceptibly small perturbations to the original input. The article then distinguishes between non-targeted attacks and the more threatening targeted attacks, emphasizing the constraint that perturbations must be sufficiently small (typically measured by L2 or L∞ norms) to ensure stealth. Subsequently, the article focuses on the core algorithm for generating adversarial examples—input optimization based on gradient descent. The essence of this approach is to keep the model parameters fixed and treat the input itself as an optimizable variable. The input is iteratively updated by computing the gradient of the loss function, with projection steps applied to strictly satisfy the perturbation constraints. Finally, the article highlights the essence of efficient attack methods like the Fast Gradient Sign Method (FGSM): utilizing the direction(sign) of the gradient rather than its magnitude to apply the maximum allowed perturbation within the constrained space.
目录
1 注意力机制的对抗性攻击
2 总结
1 注意力机制的对抗性攻击
通过微小的、人眼难以察觉的扰动来干扰模型的注意力分布,从而误导模型的预测结果。这就是注意力机制的对抗性攻击。如下图所示,添加难以人眼观察的噪点等后,输出会改变。
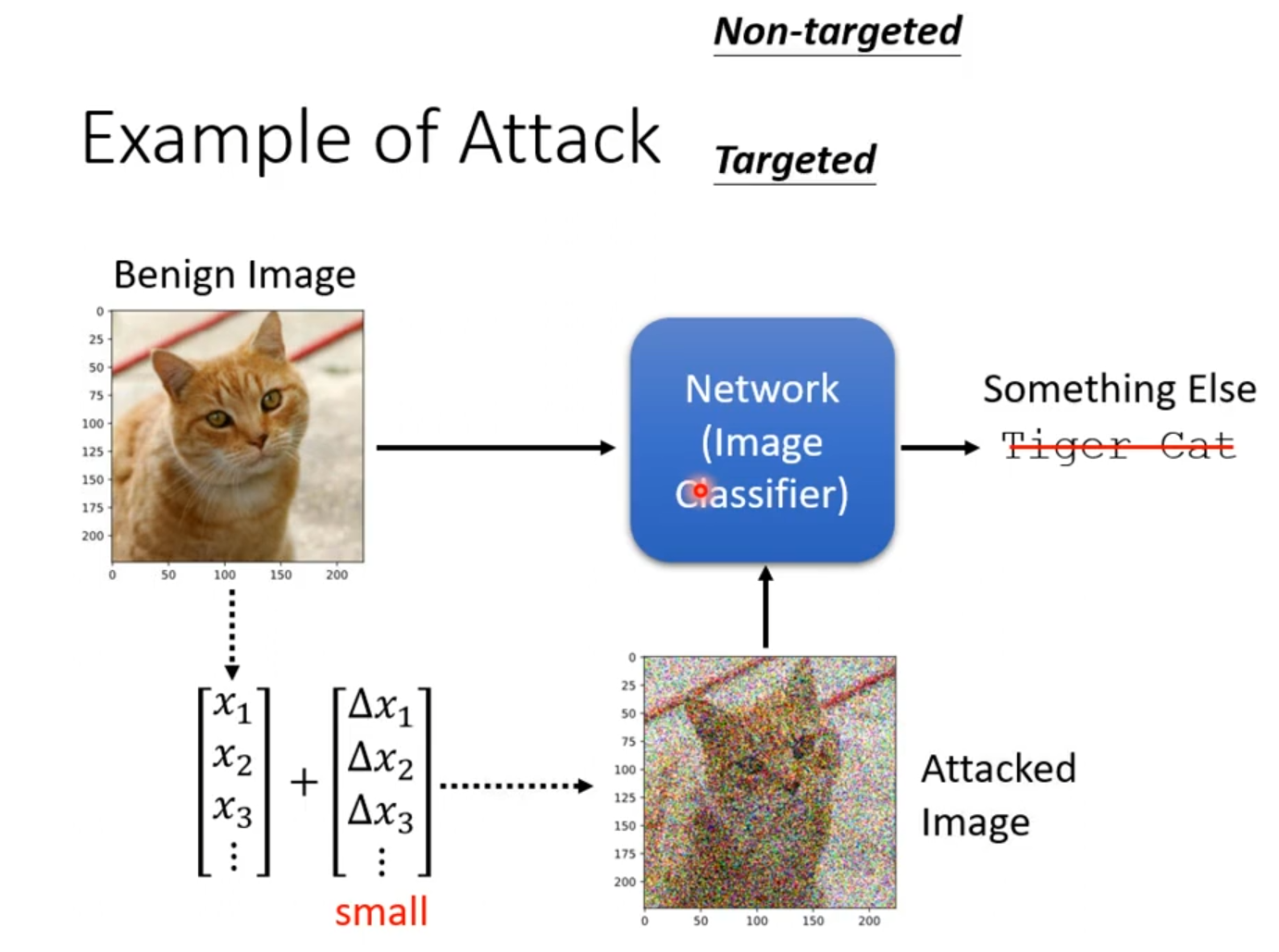
图的左侧展示了一张正常的、被分类器正确识别为“虎猫”的良性图像。攻击的目标正是这个分类网络,攻击者生成一个极其微小、人眼难以察觉的扰动数据矩阵。当这个微小的扰动被添加到原始图像数据上后,便生成了右侧的受攻击图像;尽管在人类视觉上,这张受攻击的图片与原始图片几乎没有差别,但它却彻底欺骗了图像分类器,导致模型做出了完全错误的判断。
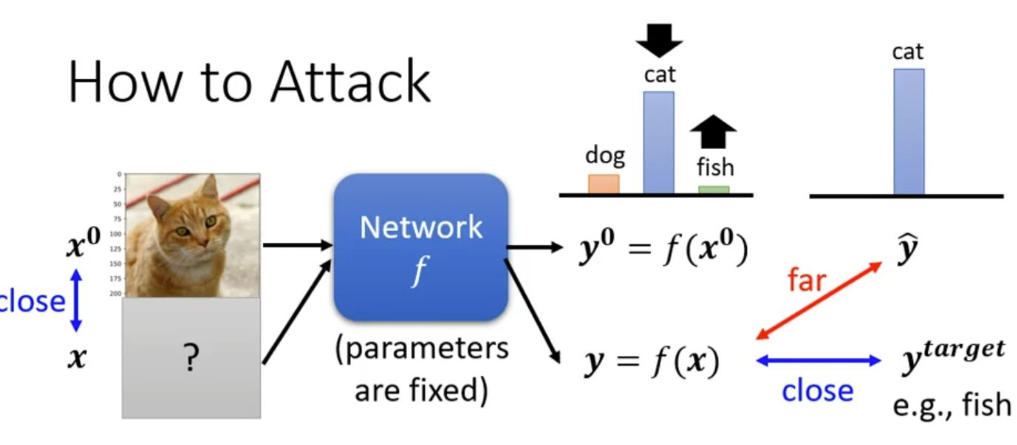
非定向攻击仅以误导模型为目的,其损失函数旨在拉大模型预测y与真实标签ŷ之间的距离,使得预测结果错误即可;而更具威胁的定向攻击则有一个明确的目标标签y_target,其损失函数在促使模型远离真实标签的同时,还会引导预测结果向这个特定的错误类别靠近,例如将猫刻意误判为鱼。整个攻击过程需要一个严格的约束条件,即扰动后的图片x必须与原始图片x⁰足够“接近”,以确保其欺骗性对人类视觉是隐蔽的。
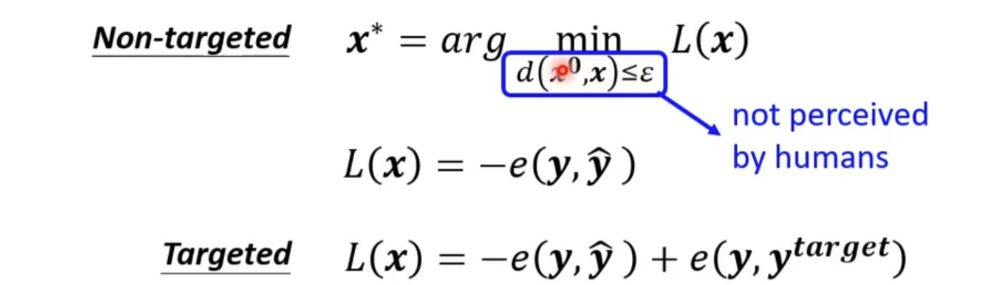
原始图片 x⁰经过网络 f的处理,会得到一个正确的预测输出 y⁰ = f(x⁰)。找到一个对抗样本 x。这个 x由原始图片 x⁰加上一个微小的扰动构成,即 x = x⁰ + δ。这个扰动 δ非常小,需要满足约束条件 d(x⁰, x) ≤ ε,以确保人类视觉上几乎无法区分 x和 x⁰。非目标攻击可以让模型错误判断,目标攻击可以让模型定向错误判断。
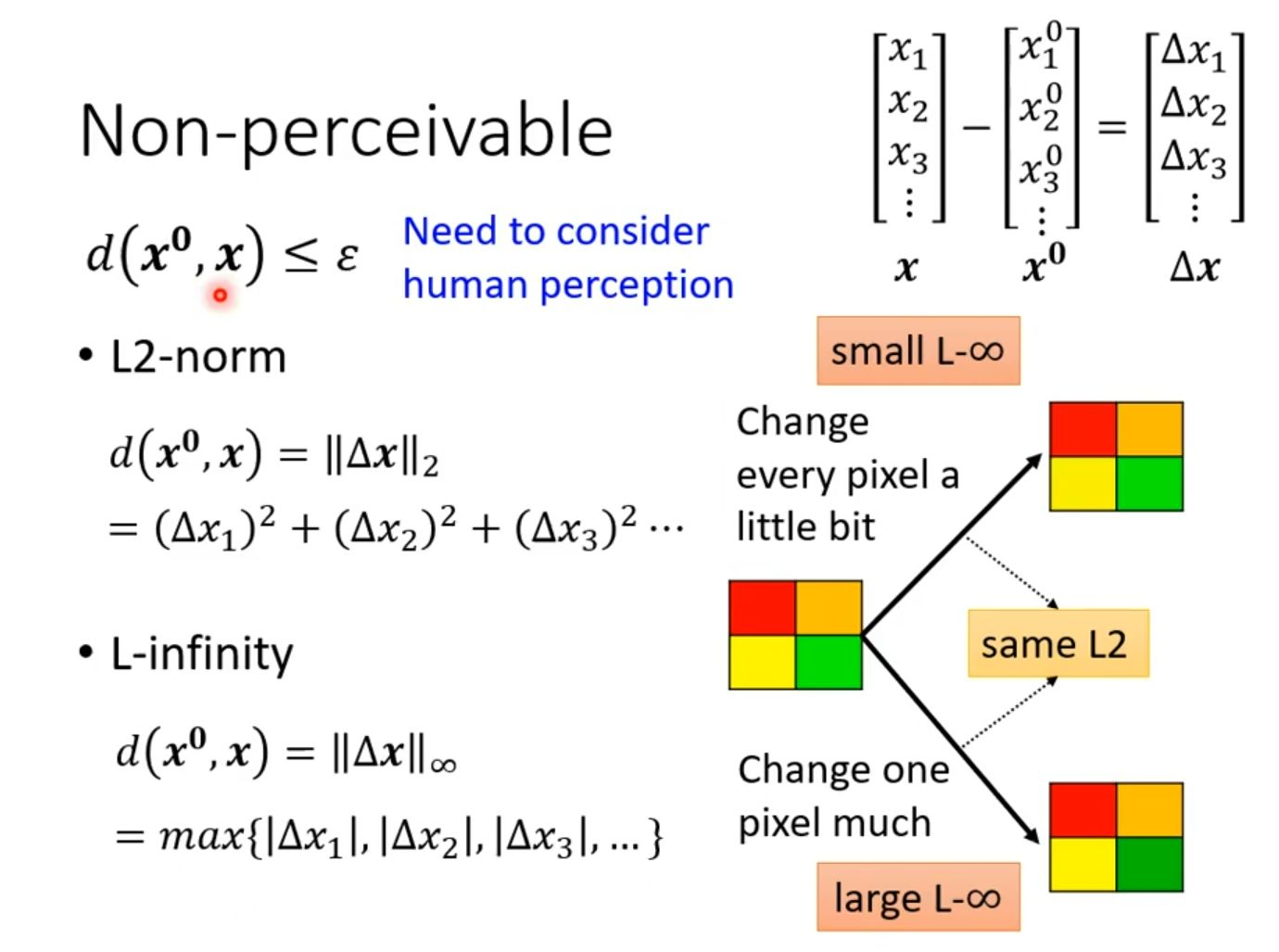
L2范数:它计算的是所有像素点上扰动值的平方和。这种度量反映的是扰动的“总能量”。如图中右侧示意图上半部分所示,当L∞范数较小时,意味着我们将这种“总能量”平均分配到许多像素上,对每个像素只做微小的改动,这种均匀的微小变化人眼很难察觉。
L∞范数:它计算的是所有像素点中扰动绝对值的最大值。这种度量反映的是单个像素点的最大变化幅度。图中示意图下半部分表明,即使L2范数相同,如果扰动集中在少数像素点上,会导致L∞范数变大,即某个像素点的改动非常显著,这就容易形成一个明显的、人眼可见的异常点,从而破坏不可感知性。
如下图所示,可以知道。与常规的机器学习训练(其目标是寻找最优的模型参数 w*, b*以最小化损失函数 L)不同,这种攻击方法的根本区别在于它固定模型参数不变,转而将输入数据 x本身作为需要优化的变量,其目标是寻找一个能最小化特定损失函数 L(x)的最优输入 x*。为实现这一目标,该方法采用了梯度下降算法:攻击过程从原始干净图像 x⁰开始,进行 T 次迭代;在每一次迭代中,首先计算损失函数 L对当前输入 x的梯度 g(这是一个向量,其每个分量是损失函数对输入中每个像素的偏导数),然后沿着梯度反方向以步长 η 更新输入,即 xᵗ = xᵗ⁻¹ - ηg。通过这种迭代优化,输入图像被微妙地修改,从而引导模型做出错误的预测,而人眼却难以察觉其变化。

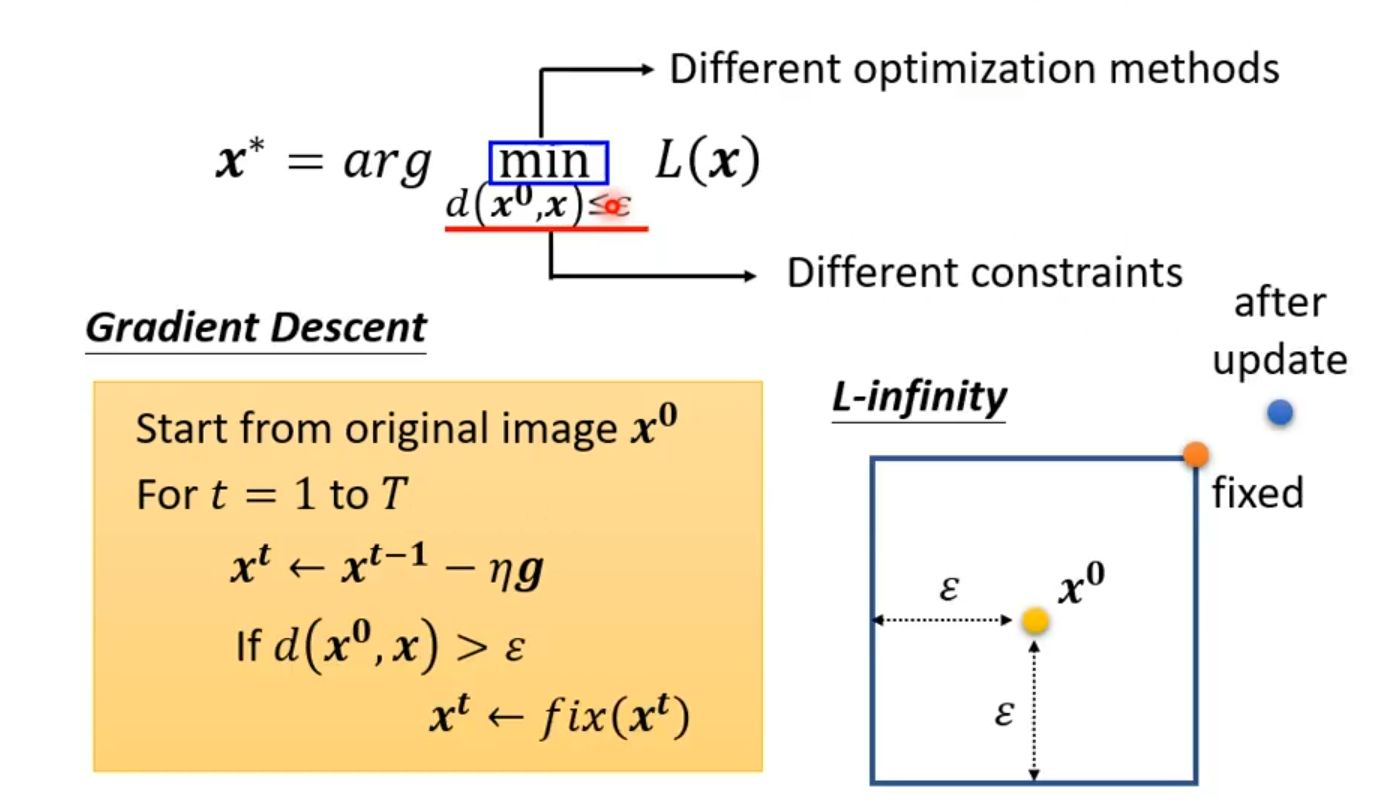
固定预训练模型的参数,将原始图像 x0作为优化变量,通过迭代更新寻找一个满足距离约束 d(x0,x)≤ε的新样本 x∗,使得损失函数 L(x)最小化(例如,让模型对 x∗的预测错误)。算法从 t=1开始进行 T次迭代。在每一步迭代中,首先计算当前样本 xt−1的梯度 g,然后按照公式 xt=xt−1−ηg沿梯度反方向更新样本(其中 η为学习率)。最关键的一步是,在每次更新后立即进行投影操作:检查新样本 xt与原始样本 x0的距离是否超过了预设的阈值 ε。如果超过,则将 xt投影回以 x0为中心、半径为 ε的约束空间内(例如对于L-∞范数,该空间是一个超立方体),从而确保生成的对抗样本与人眼所见的原始图像差异极小。
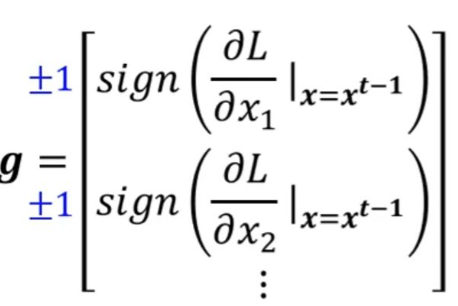
其每个分量是损失函数 L对输入对应维度 xi的偏导数的符号函数结果,即 ±1。这揭示了L-无穷范数攻击(如著名的FGSM方法)的本质:不考虑梯度的大小,只依据梯度的方向(正负号)在每个维度上进行最大允许幅度(±ε)的扰动。这种策略能最有效地在严格的像素值变化限制内,快速将数据点推向决策边界,从而高效地生成对抗样本。整张图通过几何直观和数学公式相结合,完美展示了此类攻击如何在保证扰动“不可感知”的前提下欺骗模型。
2 总结
对抗性攻击是一种通过优化输入数据而非模型参数来欺骗AI系统的技术。学习了模型决策边界的脆弱性。关键要点包括:1)攻击需在扰动“不可感知”的约束下进行(L∞约束尤为关键);2)其通用算法是带约束的梯度下降;3)高效攻击(如FGSM)的核心是依据梯度符号进行最大化扰动。