【第二十二周】自然语言处理的学习笔记06
文章目录
- 摘要
- Abstract
- 一、模型优化
- 1. CPU与GPU
- 1.1 基本介绍
- 1.2 显卡中有哪些显存的组成
- 1.3 多张显卡的合作方式
- 2. 模型训练优化方式
- 2.1 数据并行
- 2.2 数据并行模型并行
- 2.3 Zero Redundancy Optimizer(0冗余优化器)
- 2.4 Pipeline parallel流水线并行
- 3. 技术优化细节
- 3.2 Offloading
- 3.3 计算重叠
- 3.4 检查点
- 二、模型轻量化
- 1. 知识蒸馏
- 1.1 知识蒸馏原因
- 1.2 温度系数
- 1.3 知识蒸馏的实现过程
- 1.4 算法流程
- 总结
摘要
本周主要学习模型训练优化、核心技术优化以及轻量化模型。
模型训练优化主要通过对CPU 与 GPU 的核心差异以及内部数据流向的学习引入显卡部分内容,显卡部分主要学习了显卡显存的四大占用组成,多张显卡的五大协作算子。以及四种模型训练优化方式:数据并行,模型并行,ZeRO,流水线并行。
核心技术优化方案包括,混合精度训练,Offloading,计算重叠,检查点 + 重计算
轻量化模型本周只来得及学习知识蒸馏,通过知识蒸馏可以在教师模型的基础上对数据有深层的理解后再进行进一步的学习。
Abstract
This week, I mainly learned about model training optimization, core technology optimization, and lightweight models.
For model training optimization, I first studied the core differences between CPUs and GPUs as well as their internal data flow, which led to the introduction of GPU-related content. Specifically, I learned about the four major components of GPU memory usage and the five key collaborative operators for multi-GPU setups. Additionally, I explored four model training optimization methods: data parallelism, model parallelism, ZeRO (Zero Redundancy Optimizer), and pipeline parallelism.
The core technology optimization solutions include mixed-precision training, offloading, computation overlapping, and checkpointing + recomputation.
Regarding lightweight models, I only had time to learn about knowledge distillation this week. Through knowledge distillation, a student model can first gain a deep understanding of data based on the pre-trained teacher model before conducting further learning.
一、模型优化
1. CPU与GPU
1.1 基本介绍
CPU:内部有少数的大计算核心,适合复杂的逻辑值计算
GPU:内部有大量的小计算核心,适合大量的,重复的数值运算。例如:矩阵的乘法

CPU通过给GPU发一些控制信号去控制GPU进行运算,运算的数据也由CPU向GPU传输。
1.2 显卡中有哪些显存的组成
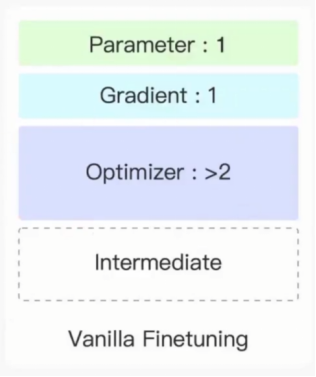
1,参数:为了完成前向传播将模型所有参数都放到显卡当中
2,梯度:反向传播得到的梯度
3,模型中间计算结果:前向传播一个个输入X,由于反向传播对W求梯度需要使用输出梯度与输入进行外积,因此需要保存输入的X

4,优化器:以adam为例:需要保存模型梯度以及模型梯度二次项一些历史信息m,v,因此将各个参数都放在显卡当中

综合上述,每一组成可能占有的参数的数量级如下:其中1表示与模型参数等数量级。由于优化其中需要模型梯度以及其他参数因此数据数量级为>2。
1.3 多张显卡的合作方式
1,广播算子
将一张显卡中的数据传到其他所有显卡上

2,Reduce 规约
求(和)或者(均值)

假设为求和:此时2号显卡内容为:0+1+2+3
3,All reduce
在2的基础上,将结果告诉所有显卡
4,Reduce scatter
将规约结果发给每一张显卡,但是最后每张显卡只得到一部分规约结果

例如求和规约:
0号显卡为:(0,1,2,3)四个显卡前四分之一的数据求和
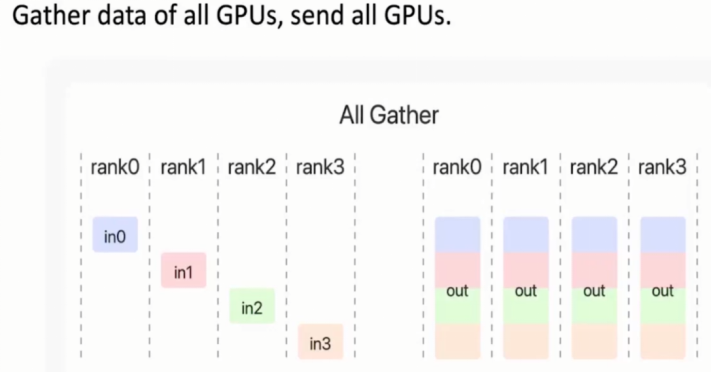
5,All gather收集
收集:拼接每张显卡内容,最后广播到所有显卡中
2. 模型训练优化方式
2.1 数据并行
(1)方法一:数据并行
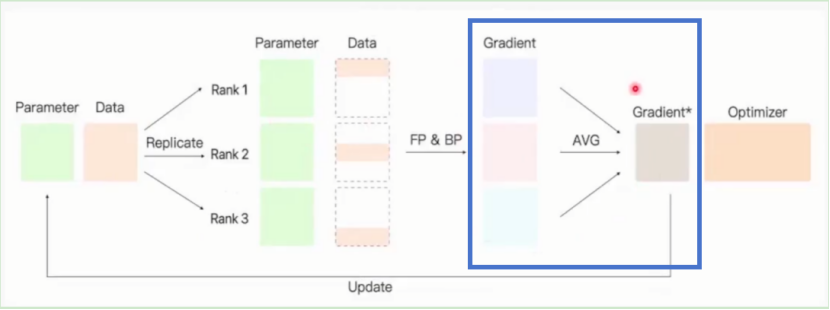
假设有三张显卡,并且每个显卡拥有完整的模型参数。(将服务器中的参数复制给每一张显卡)
此时可以将要训练的数据分为三份,每个显卡个拿到一份数据。
每个显卡可以根据拿到的完整的模型参数和那份数据进行前向传播和反向传播,得到每张显卡上的梯度,最后将梯度进行聚合/规约(求平均值,图中蓝色框框部分),将聚合后的梯度传回参数服务器。
此时参数服务器拥有完整的模型参数和聚合好的完整的梯度,再使用优化器对模型参数进行更新,更新后的参数会广播更新至每一张显卡进入下一轮模型参数迭代。
方法二:Distributed data parallel分布式数据并行
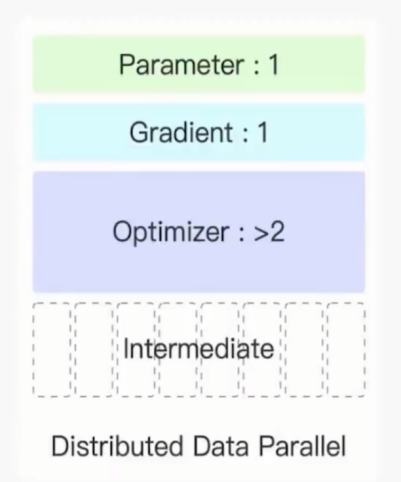
确保除了输入的数据,其他每一个部分的参数都相同。显卡有相同参数,相同的梯度,相同的优化器历史信息。此时可以确保更新后的显卡内部参数也保持相同。
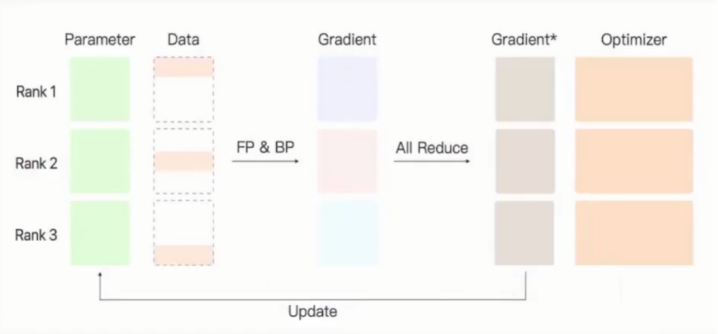
由于每张显卡都分得一部分数据,此时

每个显卡获取的数据批次都变为显卡数量分之1,中间结果的数量也变为下图所示
2.2 数据并行模型并行
将模型分为多个小的部分,每个显卡只处理属于自己的那一部分。
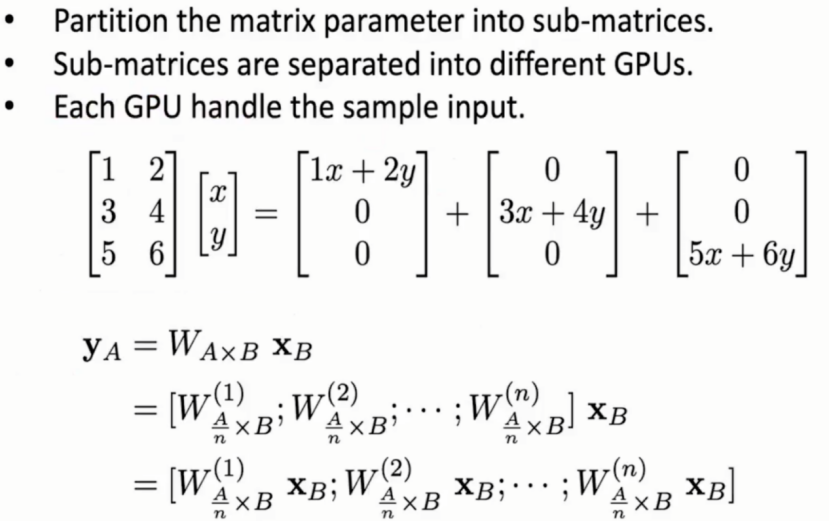
以上图矩阵乘法为例:
假设有3张显卡计算3×2矩阵与2×1向量的运算,则可以划分为参数的每一行与输入数据(向量)的计算,即将线性层参数划分到每一张显卡上,最后再进行拼接(all gather算子)。
优势:每张显卡只需保存原数据的1/n的模型参数
弊端:模型中间计算结果没有减少,因为并没有对数据进行划分,仍需要保存所有数据,因此当模型batch-size比较大时,仍然出现显存溢出问题。
2.3 Zero Redundancy Optimizer(0冗余优化器)
基于数据并行建立的框架,结构如下:
Zero Redundancy Optimizer分为三个阶段,为了逐步优化显存占用、平衡显存节省与通信开销、提供灵活的优化策略
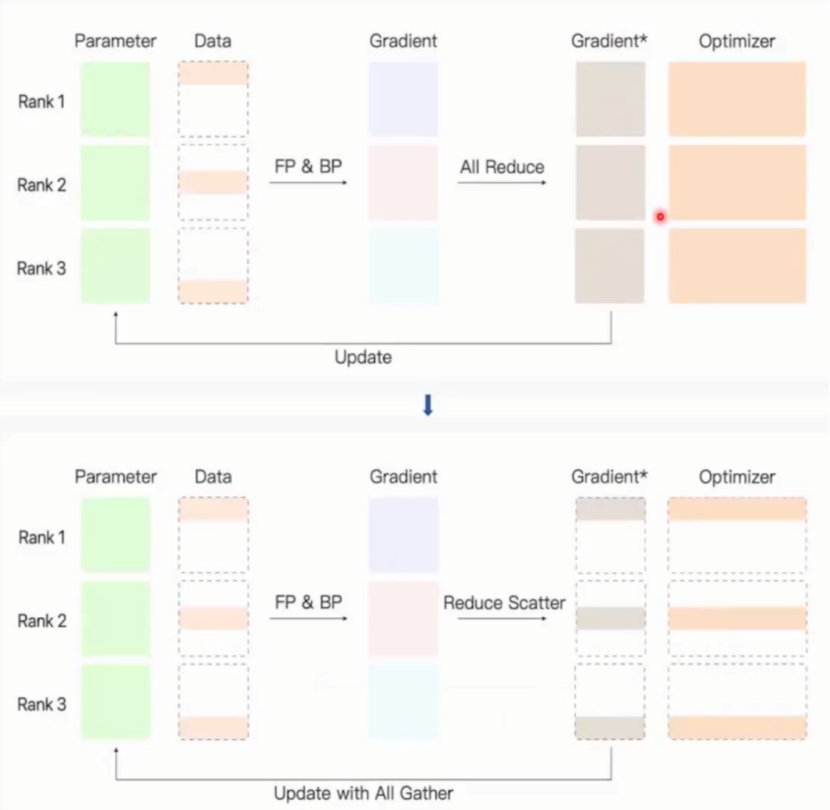
阶段一:
刚开始显卡均拥有完整参数和部分数据,数据通过前向传播和反向传播分别得到各自梯度,各个显卡间可以相互合作,每张显卡更新一部分规约参数并在对应位置优化器进行优化,最后通过all gather收集操作将结果合并告诉所有显卡,此时每张显卡又得到完全一样的参数和一致的结果。
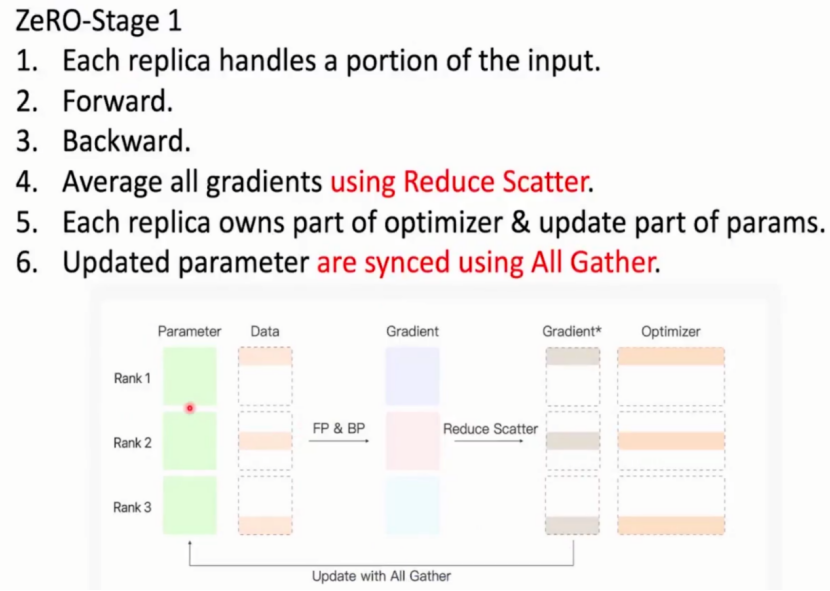
阶段二:
每张显卡处理部分参数进行前向传播和反向传播,其中反向传播使用的梯度参数为reduce scatter后的梯度参数,而非原来的梯度。
那么何时可以释放原来的梯度?
当线性层处理完某一层的反向传播时,使用该层的各个显卡上的梯度进行reduce scatter后得到该层的梯度*,原本的梯度就可以被释放达到节省显存空间的作用。
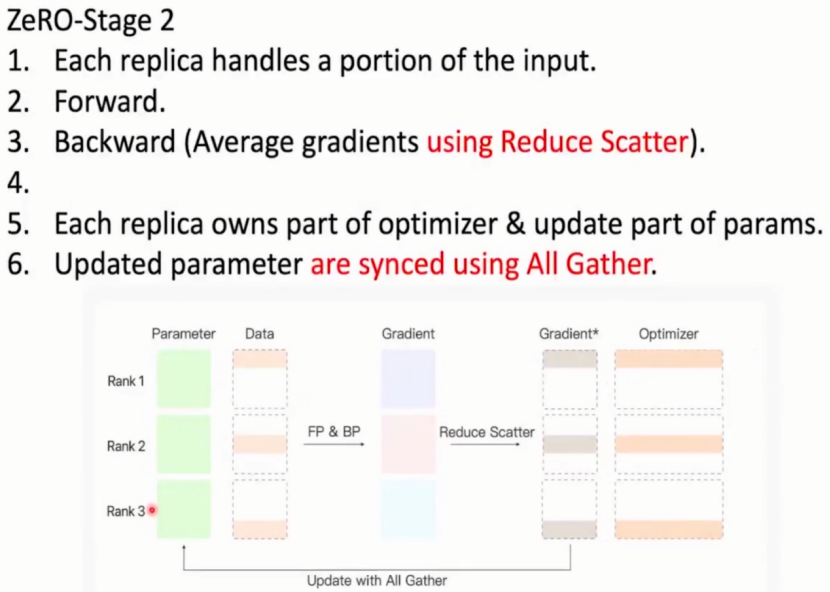
阶段三(用时间换空间的算法):
将模型参数也进行划分,由于参数更新也只更新一部分,因此每张显卡只保存一部分数据,梯度,优化器参数。
但是只有部分数据怎么进行前向和反向传播?
在进行前向传播和反向传播时进行all gather操作,用到参数时将那一部分的参数进行一个收集拼接,使用完后将参数从显卡中释放。

对ZeRO三个阶段数据内容进行说明:
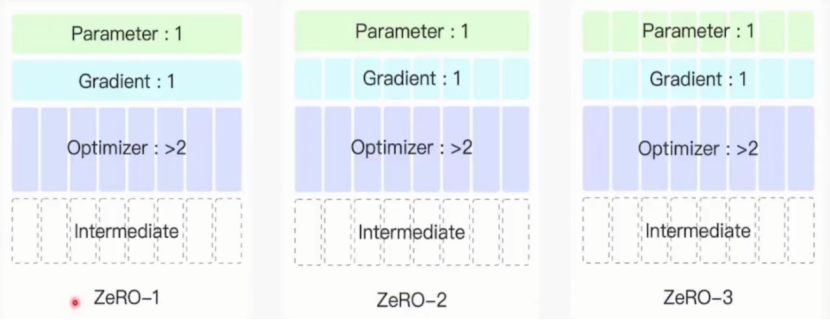
分为三个阶段的详细说明:
(1)逐步优化显存占用:随着模型规模的不断增大,显存成为限制模型训练的关键因素。ZeRO 通过分阶段逐步对优化器状态、梯度和模型参数进行分片,越来越彻底地消除数据冗余存储,从而逐步降低单卡显存占用,使得能够训练更大规模的模型。
(2)平衡显存节省与通信开销:不同阶段的分片方式在节省显存的同时,也会带来不同程度的通信开销。Stage 1 的通信开销最低,Stage 3 的通信开销最高。分阶段设计可以让用户根据具体的硬件环境、模型规模和训练需求,选择合适的阶段,在显存节省和通信开销之间找到最佳平衡。例如,对于中等规模模型和 GPU 数量较少的情况,Stage 1 可能就足够了;而对于超大规模模型且有高速网络支持的场景,Stage 3 可以实现更好的显存优化效果。
(3)提供灵活的优化策略:不同的训练场景对显存优化的需求不同。分三个阶段可以让用户根据实际情况灵活选择优化方式。比如单卡训练时,启用 ZeRO Stage 2 和 3 可能会得不偿失,而 Stage 1 在多卡训练中能减少显存冗余,但在单卡训练中可能效果不明显甚至增加开销,这种分阶段的设计使得 ZeRO 能够适应更广泛的训练场景。
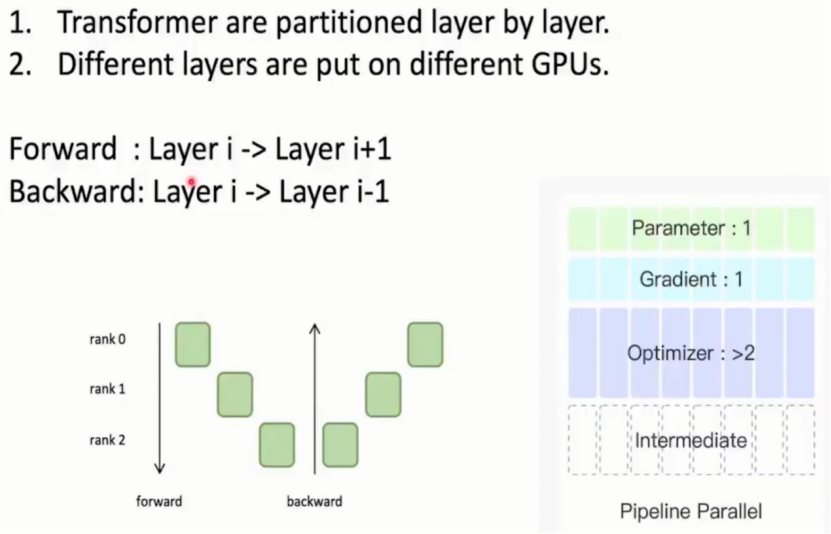
2.4 Pipeline parallel流水线并行
流水线并行(Pipeline parallel):按层拆分 Transformer 模型,不同层部署在不同显卡,按前向 / 反向传播顺序依次运算。
3. 技术优化细节
00000### 3.1 混合精度训练
对于浮点数使用FP16和FP32数据类型地说明:
使用FP16优点:
1,数学计算运行更快
2,数据传输使用更少的内存带宽
3,数据能表示的范围小,但不会溢出
使用FP32的优势:
1,当保存数据为FP16时,参数的更新即梯度×学习率,小于FP16下界时,会产生下溢地情况,因此更加适用于精度更高的FP32数据类型
在具体使用中使用精确度更高的FP32数据类型
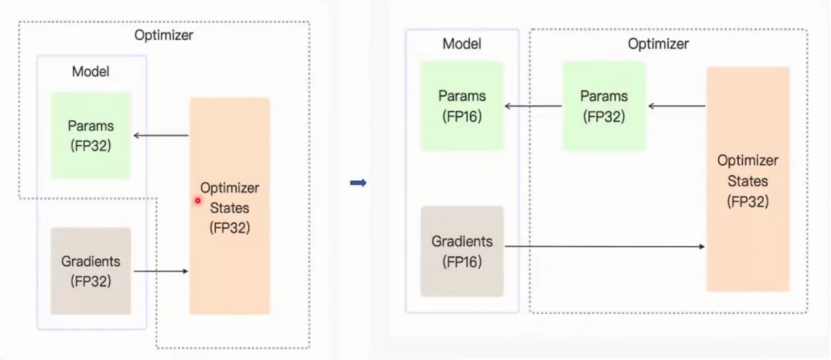
优化为:在优化器上单独添加一个FP32数据类型,并且参数和梯度都为半精度数据类型(FP16),将半精度梯度传入优化器进行优化器更新,优化器更新量保存为FP32类型,将FP32数据类型通过优化器临时创建的FP32的参数进行有效累计,接着再将其转会FP16参数以供模型计算。
优化后:模型内部运算加快,优化器参数精度也保持较准确状态。 FP16 做主要计算(省显存、提速度); FP32 保存关键数据(如模型参数、梯度),通过 “动态转换” 平衡效率与精度。
3.2 Offloading

模型参数梯度从GPU传给CPU,在CPU上进行优化,优化结果传回GPU。
将一个GPU与多个CPU绑定,使用ZeRO3将参数,梯度和优化器划分到CPU卡数分之一,此时每张CPU的计算量都会降到足够低,能让CPU不成为模型训练的瓶颈。
3.3 计算重叠
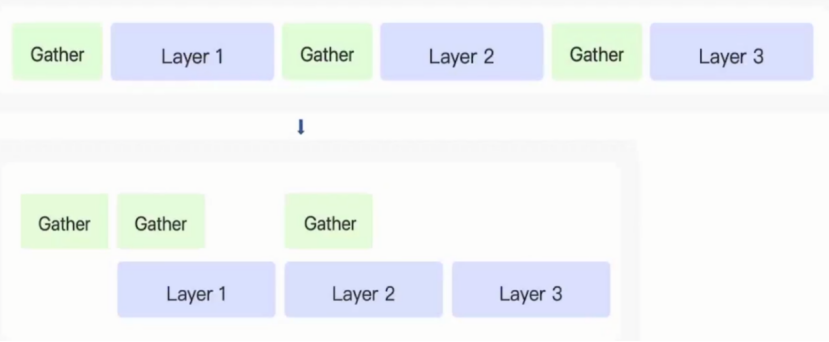
CPU中存储操作一般是异步。
当需要存取时提前发出数据请求,于是CPU继续处理其他计算,处理完后再对存取的数据请求进行接收。
上图中优化部分解读:
提前收集layer1数据,当处理layer1时,收集layer2参数,此时确保CPU一直在工作,没有造成资源浪费,并且该过程效率高
3.4 检查点
不保存所有的结果于显存当中,只保留一定的存档点。
只对每一个大层的输入,输出进行保存,Transfomer blocks(attention和FFN)结果均不做任何保存
重计算:对transformer每个大层的输入在反向传播过程中重新对它进行前向传播,临时得到每一个大层里面所有线性层的输入,得到中间结果就可以得到,就可以进行反向传播
例如一个12层的transfomer,每个里面五个线性层,因此有60个中间结果,通过检查点方式将60个降低为12个
二、模型轻量化
大模型预训练模型压缩的相关技术:、压缩大模型为一个小模型,该小模型继承大模型的大部分特点,达到更快的运算速度和更少更普通的设备完成对模型的训练
1. 知识蒸馏
传统训练:一个轻量的小模型(学生)直接从硬标签(例如,图片是“猫”或“狗”)中学习。这就像一个小学生只被告诉了标准答案,但没有理解背后的推理过程。
知识蒸馏:小模型从一个庞大、复杂但性能强大的模型(教师)那里学习。教师模型提供的不是硬标签,而是软标签。
1.1 知识蒸馏原因
1,从“教师的智慧”中学习,而非仅从“原始数据”中学习
硬标签为绝对0,1的独热编码(one-hot)
软标签则包含丰富知识

2,弥补“容量差距”带来的信息损失
轻量化模型(学生)由于其参数少、结构简单,模型容量 有限。
教师模型(如大型神经网络)已经具备了强大的能力,它将原始数据中复杂、隐晦的规律“消化”并“提炼”成了更易于理解的软标签。学生模型 则从这些已经提炼过的、富含信息的软标签中学习,无需从海量数据中自己总结规律。
1.2 温度系数
温度系数:用于控制和优化软标签的质量。
温度系数的作用:
(1)抑制过拟合: 高蒸馏温度下的软目标概率分布更平滑,相比硬目标更容忍学生模型的小误差。这有助于防止学生模型在训练过程中对教师模型的一些噪声或细微差异过度拟合,提高了模型的泛化能力。
(2)降低标签噪声的影响: 在训练数据中存在标签噪声或不确定性时,平滑的软目标可以减少这些噪声的影响。学生模型更倾向于关注教师模型输出的分布,而不是过于依赖单一的硬目标。
(3)提高模型鲁棒性: 平滑的软目标有助于提高模型的鲁棒性,使其对输入数据的小变化更加稳定。这对于在实际应用中面对不同环境和数据分布时的模型性能至关重要。
需要注意的是,过高的蒸馏温度也可能导致学生模型过于平滑化,失去了对数据细节的敏感性,因此需要在实践中进行调优。


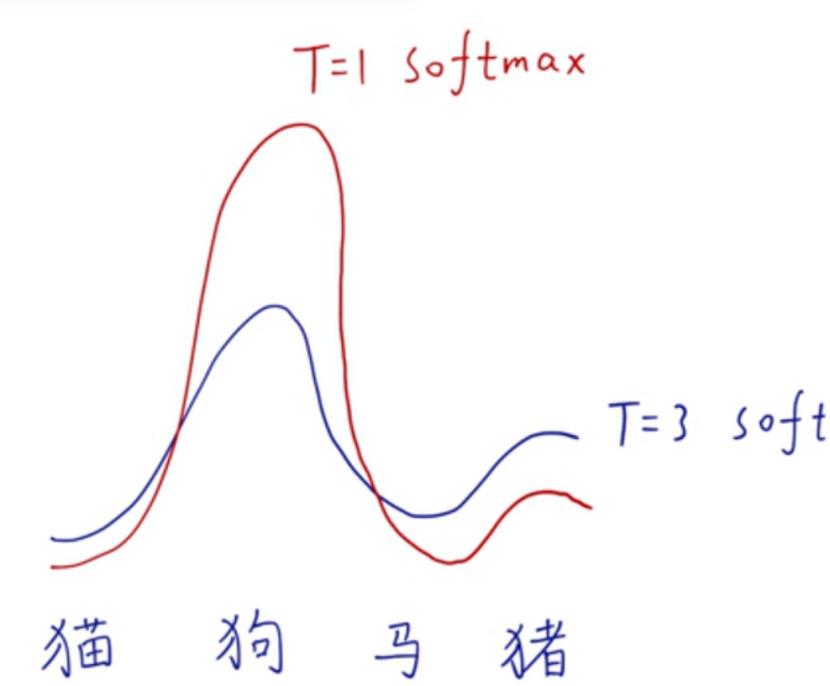
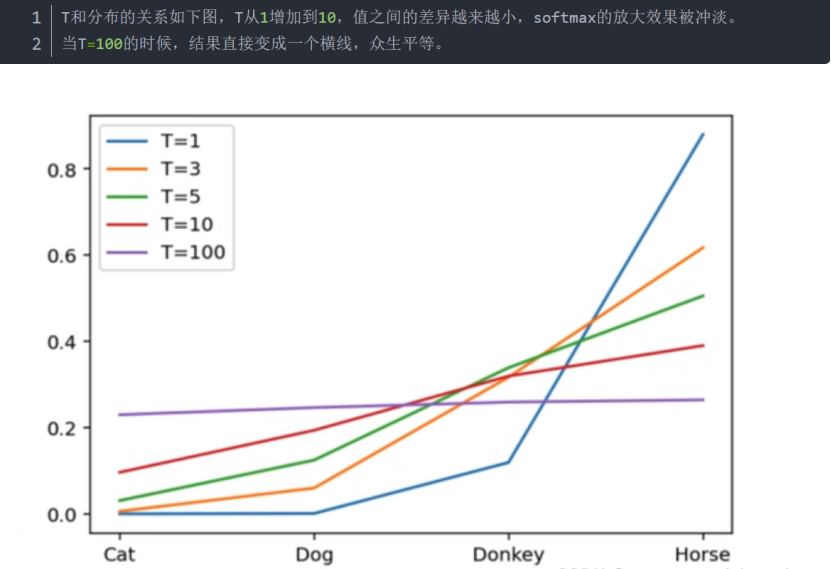
例如下图:对动物分类不同温度系数对softmax的影响
1.3 知识蒸馏的实现过程
1,训练教师模型:在大数据集上训练一个复杂模型至收敛
2,蒸馏:
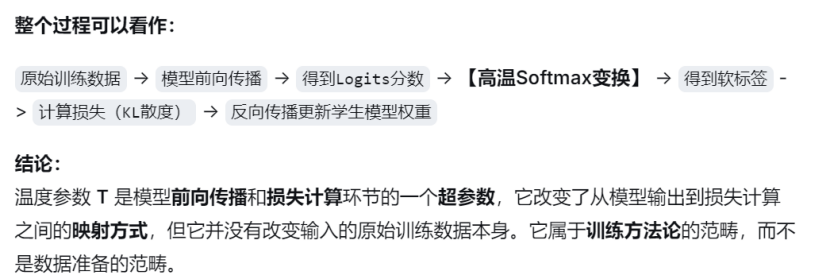
(1)再次将训练数据输入教师模型,使用高温,得到软标签
(2)使用相同数据训练学生模型,温度同上
补充说明:
疑问一:使用高温,高温属于训练数据范围吗?
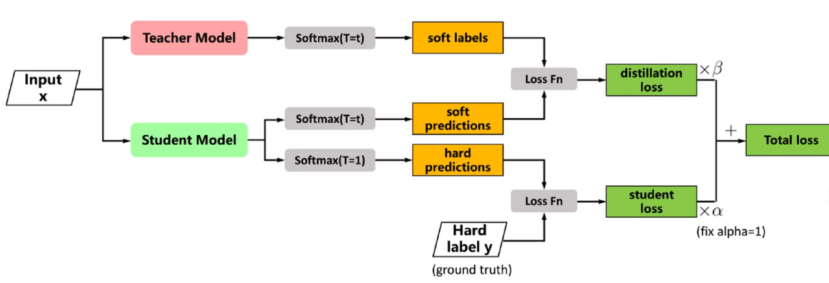
3,设计损失函数:学生模型的训练目标由两部分组成:
(1)蒸馏损失:让学生模型的高温软输出尽可能接近教师模型的高温软输出。常用KL散度衡量两个分布的差异。
(2)学生损失:让学生模型的输出(通常使用T=1)接近数据的真实硬标签。常用交叉熵损失。
4,总损失:L = α*L(soft) + (1-α)*L(hard)
说明:L(soft):蒸馏损失;L(hard):学生损失
5,反向传播与参数更新:对总损失L进行反向传播
需要注意:梯度只更新学生模型的参数,教师模型的参数是冻结的,不参与更新。
6,重复:对下一批数据进行1-5操作
疑问:教师的参数在一轮训练后不更新,是否会存在学生模型参数较于教师参数更加有效?从而导致后续训练再进入教师模型训练结果形成倒退?
解答:
首先,学生模型在教师模型的基础上进行学习,学生青出于蓝而胜于蓝,正是知识蒸馏成功和强大的体现;
其次,不会导致“训练倒退”或者负面循环。

过程如下图:
疑问:学生模型学习教师模型是只需要学习到最终输出层知识吗?
解答:
引入Patient Knowledge Distillation(耐心知识蒸馏PKD),一种知识蒸馏变体,核心思想:让学生模型有“耐心”地从教师模型的多个中间层学习知识,而不仅仅是最终输出层。(传统知识蒸馏就是学生模型只模仿教师模型的最终输出)
Patient KD 最早在论文《Patient Knowledge Distillation for BERT Model Compression》中提出,用于压缩巨大的BERT模型。
1.4 算法流程
1,选择“耐心层”:

2,建立层映射关系:
疑问:教师模型层数和学生模型层数相同吗?不相同如何完成中间层的学习?对应关系?
解答:
教师模型层数和学生模型层数不一定相同。通常采用均匀映射策略。举例:

3,计算耐心损失:

均方误差损失公式的进一步解释:

推导过程:

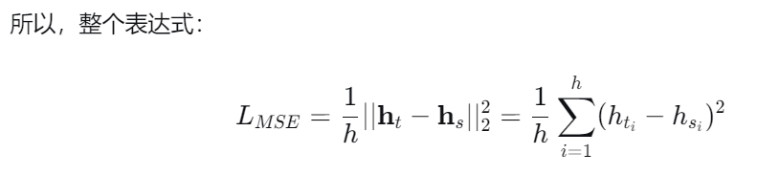
说明:
1/h:是取平均,其中h 是隐藏层的维度。这样做的目的是确保损失值不会因为向量维度很大而变得巨大,使得损失函数更加稳定。
4,总损失函数:

耐心蒸馏损失的具体说明:

补充:
疑问一:隐藏状态的定义?出现在哪些地方?
隐藏状态 是神经网络(尤其是循环神经网络RNN、LSTM和Transformer)在内部层计算出的、用于表示输入数据的中间表示或特征向量。

疑问二:transformer中隐藏状态出现在哪些地方?
(1)编码器最后一层输出
对于输入序列的每一个token,编码器都会输出一个对应的向量(编码器的最后一层)。这个向量就是这个token的“最终隐藏状态”。
包含的信息: 这个向量不仅仅代表这个词本身的意思,它浓缩了整个输入序列所有其他词对于理解当前词的信息。因为它经过了所有层的自注意力机制处理,与序列中的每一个词都进行了“交流”。
(2)每一层的输出
Transformer由多个层(比如BERT-base有12层)堆叠而成。每一层都会为每个token生成一个该层的隐藏状态:
- 浅层隐藏状态: 更靠近输入层的隐藏状态,通常包含更多语法、词性、局部短语等低级特征。
- 深层隐藏状态: 更靠近输出层的隐藏状态,通常包含更多语义、上下文、全局推理等高级特征。
这恰恰是Patient Knowledge Distillation发挥作用的地方! 它让学生模型去模仿教师模型这些不同深度的隐藏状态,从而学习到从低级到高级的完整特征表示。
对Transformer中状态的说明:
注:一个Transformer层 = 自注意力子层 + 前馈神经网络子层

疑问三:学生模型取的教师模型的隐藏状态是否为输出隐藏状态?
是的。在Patient Knowledge Distillation中,让学生模型去匹配的“教师模型的隐藏状态”,正是指这些定义明确、层层传递的“每一Transformer层的最终输出”。
补充:RNN,Transformer中的隐藏状态

RNN的隐藏状态是一个动态的、不断更新的“记忆单元”。它在每个时间步都会融合当前输入和过去的记忆,从而实现对序列信息的编码。正是通过这个机制,RNN能够处理序列数据,并考虑到上下文的顺序关系。
总结:RNN中隐藏状态主要起到“记忆”的作用;Transformer中隐藏状态主要是“理解、推理”作用。
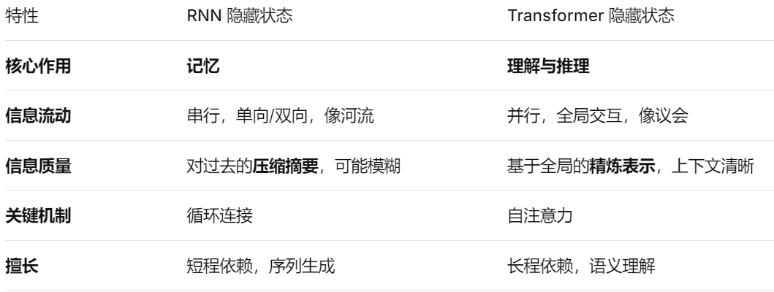
RNN结构更像流水线,一个接一个完成任务;transformer结构更像所有参会者同时参加会议,消息同时更新。

知识蒸馏参考文章如下:
全网最细图解知识蒸馏(涉及知识点:知识蒸馏实现代码,知识蒸馏训练过程,推理过程,蒸馏温度,蒸馏损失函数)
总结
本周学习知识蒸馏过程产生非常多的疑问,已经通过大模型和博文阅读进行问题分析与解决,补充了前面学习中相关隐藏状态的知识,区分RNN与Transformer中的隐藏状态的区别。RNN中隐藏状态更倾向于记忆,Transformer中隐藏状态更倾向于分析,推理。