query加强之深度解析ReDI:通过分解与解释增强query理解的推理方法
一、研究背景与动机
1.1 传统查询理解的困境
在现代搜索引擎和检索增强生成(RAG)系统中,准
确理解用户意图是提升文档检索质量的核心挑战。尽管大语言模型(LLM)在查询理解领域取得了显著进步,但其有效性主要在短关键词查询上得到验证。传统的查询理解方法主要存在以下局限:
静态资源依赖问题:传统方法依赖外部词典(如WordNet、Wikipedia)进行查询扩展,这些资源属于静态知识库,覆盖范围有限,尤其对短关键词查询效果不佳。当用户输入简洁但语义丰富的查询时,系统往往无法捕捉到隐含的多层次信息需求。
长查询泛化能力不足:随着AI驱动搜索的演进,包含复杂意图的长格式查询变得越来越普遍,但现有基于LLM的查询理解方法在处理这类查询时存在偏置问题,且对长文本、多意图的复杂查询泛化能力明显不足。
1.2 复杂查询的新范式
随着OpenAI、DeepSeek和Gemini等AI驱动搜索系统的快速发展,用户查询经常涉及多个实体、扩展的时间范围和多样的知识领域,需要复杂的推理。
研究者将这种新的检索范式称为“推理密集型检索”(reasoning-intensive retrieval)。
例如,一个典型的复杂查询:"下季度财报前是否应抛售A公司股票?"这个查询实际上包含了多个隐含的子意图:
- A公司的生产挑战和供应链状况
- 股价波动性分析
- 宏观经济因素影响
- 市场竞争态势
传统的检索系统将其作为单一查询处理,往往导致检索结果不完整或偏离用户真实需求。
二、ReDI方法论:分解与解释的三阶段流程
2.1 整体架构设计
ReDI(Reasoning-enhanced query understanding through Decomposition and Interpretation)采用三阶段LLM驱动的流程:
- 意图推理与查询分解:将复杂查询拆分为针对性的子查询
- 子查询语义解释生成:为每个子查询丰富详细的语义解释
- 检索结果融合:独立检索每个子查询并采用融合策略聚合最终排序
2.2 第一阶段:意图推理与查询分解
复杂查询经常包含多个隐含的子意图,需要从多个来源进行多跳信息检索。ReDI首先使用LLM显式识别原始查询的潜在意图,通过推理核心意图来确定查询是否由多个子意图或逻辑组件构成。
分解策略:给定查询 $ q_i \in Q $,系统引导模型动态地将其分解为一组清晰、简洁且独立的子查询集合 $ S_i = {s_1, s_2, …, s_m} $,每个子查询对应整体信息需求的特定方面。
案例分析:对于查询"下季度财报前是否应抛售A公司股票?",系统分解为:
- 子查询1:A公司的生产挑战
- 子查询2:股价波动性
- 子查询3:宏观经济因素
- 子查询4:市场竞争
这种显式分解确保了对复杂查询中多跳或多面向性质的全面覆盖,使得能够针对每个独立方面进行目标检索。
2.3 第二阶段:子查询语义解释生成
分解后的子查询往往缺乏检索器有效识别相关文档所需的描述深度。ReDI认为每个子查询的详细解释对于提升检索性能至关重要。系统设计了针对不同检索方法的差异化解释策略:
稀疏检索的词汇扩展:
对于依赖精确词汇匹配的BM25等稀疏检索方法,解释强调词汇多样性,引入同义词、词形变体和相关术语以提升召回率。
示例:对于子查询"低红外光对昆虫行为的影响",系统扩展为包含"LED灯"、“昆虫趋光性”、"热vs光吸引"等相关表述,覆盖同一概念的多种表达方式。
稠密检索的语义增强:
对于基于语义相似度的稠密检索,解释采用改述或阐述形式,将子查询置于更丰富的概念框架中。同样的例子会被扩展为"昆虫对光源的行为反应"或"昆虫趋光性的进化驱动因素"等语义丰富的表述。
推理解释层:
系统还会为每个子查询生成简短的推理解释,捕捉信息需求背后的基本原理或隐含假设。例如,对"A公司的生产挑战"的推理解释为:“突出制造瓶颈、生产线中断、供应链崩溃等制约产量的因素”。
2.4 第三阶段:检索结果融合
2.4.1 稀疏检索的实现
对于稀疏检索,每个检索单元使用BM25函数独立评分。给定子查询 sis_isi 及其解释 eie_iei,系统通过简单拼接构建查询表示:
s^i=si⊕ei\hat{s}_i = s_i \oplus e_is^i=si⊕ei
BM25评分函数为:
Sparse(s^i,d)=∑t∈s^i∩dIDF(t)⋅fd(t)⋅(k1+1)fd(t)+k1⋅(1−b+b⋅∣d∣avgdl)⋅fs^i(t)⋅(k3+1)fs^i(t)+k3\text{Sparse}(\hat{s}_i, d) = \sum_{t \in \hat{s}_i \cap d} \text{IDF}(t) \cdot \frac{f_d(t) \cdot (k_1 + 1)}{f_d(t) + k_1 \cdot (1 - b + b \cdot \frac{|d|}{\text{avgdl}})} \cdot \frac{f_{\hat{s}_i}(t) \cdot (k_3 + 1)}{f_{\hat{s}_i}(t) + k_3}Sparse(s^i,d)=∑t∈s^i∩dIDF(t)⋅fd(t)+k1⋅(1−b+b⋅avgdl∣d∣)fd(t)⋅(k1+1)⋅fs^i(t)+k3fs^i(t)⋅(k3+1)
其中,参数 k3k_3k3 控制查询侧词频的影响,这在处理长且推理密集型查询时特别重要。较小的 k3k_3k3 会放大重复关键词的效果,使检索器对核心词汇线索更敏感,而较大的 k3k_3k3 则减少饱和,有利于更广泛的词汇覆盖。
2.4.2 稠密检索的实现
对于稠密检索,系统使用共享的稠密编码器对每个子查询及其解释进行编码,通过加权组合构建融合的查询嵌入,并通过内积计算与文档嵌入的相似度:
Dense(si,ei,d)=⟨λ⋅f(si)+(1−λ)⋅f(ei),f(d)⟩\text{Dense}(s_i, e_i, d) = \langle \lambda \cdot f(s_i) + (1-\lambda) \cdot f(e_i), f(d) \rangleDense(si,ei,d)=⟨λ⋅f(si)+(1−λ)⋅f(ei),f(d)⟩
其中标量 $ \lambda \in [0,1] $ 调整原始子查询语义和丰富解释的相对贡献。
2.4.3 融合策略
一旦所有检索单元被独立评分,系统聚合结果计算最终文档得分。令 S={s1,s2,...,sm}S = \{s_1, s_2, ..., s_m\}S={s1,s2,...,sm} 和 E={e1,e2,...,em}E = \{e_1, e_2, ..., e_m\}E={e1,e2,...,em} 分别表示查询 $ q $ 的 $ m $ 个子查询和对应解释集合,文档 $ d $ 的最终相关性分数通过求和所有单元的得分计算:
score(q,d)=∑si∈S,ei∈ERetrieval(si,ei,d)\text{score}(q, d) = \sum_{s_i \in S, e_i \in E} \text{Retrieval}(s_i, e_i, d)score(q,d)=∑si∈S,ei∈ERetrieval(si,ei,d)
这种加法融合方法优先考虑与多个检索单元相关的文档,从而捕捉复杂查询的组合结构,更忠实地与用户的完整信息需求对齐。
三、Coin数据集:真正需要推理的复杂查询
3.1 数据集构建动机
为了训练ReDI准确理解、分解和解释复杂查询,研究团队构建了Coin(Complex Open-domain INtent)数据集。该数据集针对来自大型搜索引擎的复杂查询,反映了真实用户需求,具有开放域(跨越多样主题)和复杂性(涉及多步推理或多个方面)的特点。
3.2 数据来源与规模
Coin数据集从两个来源构建:
- 通用搜索:约10万条查询,强调信息定位检索的挑战性单轮查询
- AI搜索:约1万条查询,强调推理密集型检索的多轮查询
3.3 四阶段筛选流程
第一阶段-规则过滤:
- 保留点击次数超过10次或经过多次改写的查询
- 排除少于10字符的碎片查询
第二阶段-模型验证:
使用DeepSeek-R1检查查询的清晰度和合法性,确保无敏感内容。
第三阶段-复杂度评估:
这是最关键的筛选步骤。**系统排除那些Top-4文档即可回答的简单查询,**专门筛选需要多源推理的复杂查询。
第四阶段-人工审核:
合并数据源、去重并确认复杂性,最终保留2056条通用搜索查询和1347条AI搜索查询,共计3403条独特的复杂查询。
3.4 数据有效性验证
为验证保留查询确实需要分解,研究团队进行了对比应答实验。对于每个查询,使用标准搜索API检索Top-4文档,并提示DeepSeek-R1通过综合这些文档生成答案,然后沿四个关键维度评估答案质量:
| 查询类型 | 准确性 | 完整性 | 连贯性 | 简洁性 | 平均分 |
|---|---|---|---|---|---|
| 排除查询 | 3.8 | 3.6 | 3.7 | 3.5 | 3.65/5 |
| 保留查询 | 2.1 | 1.9 | 2.0 | 1.8 | 1.95/5 |
结果确认Coin的查询本质上需要多面向推理,无法通过简单检索很好地服务,凸显了意图分解方法的重要性。
四、实验验证:全方位性能评估
4.1 评估Pipeline设计
4.1.1 数据集选择
研究团队在两个著名的检索基准上评估ReDI:
BRIGHT基准:
包含1384个真实世界查询的推理密集型基准,涵盖StackExchange、编程和定理三大类别,还包括StackExchange任务的长文档子集。
BEIR基准:
包含18个数据集的异构IR基准,研究采用其中查询少于2000的9个数据集(ArguAna、Climate-FEVER、DBPedia、FiQA-2018、NF-Corpus、SciDocs、SciFact、Webis-Touche2020、TREC-COVID)。
4.1.2 评估指标
遵循BRIGHT和Rank1的标准,采用nDCG@10作为主要评估指标。对于BRIGHT的长文档子集,采用Recall@1指标。
- nDCG@10:衡量前 10 个结果的 “相关性质量 + 排序合理性”。归一化折损累积增益 @10,评估前 10 个推荐结果的相关性高低,以及这些相关结果的排序是否合理(相关度高的是否排在前面)。
- Recall@K:衡量前 K 个结果的 “召回全面性”。召回率 @K,评估前 K 个推荐结果中,包含了 “所有应该推荐的相关结果” 的比例(K 是自定义数值,比如 Recall@5、Recall@20)。
4.1.3 基线模型
LLM推理扩展基线:
- Claude-3-opus和GPT-4生成的推理扩展(BRIGHT官方版本)
- DeepSeek-R1(671B)生成的推理扩展
最新SOTA方法:
- TongSearch-QR(7B)
- ThinkQE(14B)
- DIVER-QExpand(14B)
4.1.4 检索器配置
稀疏检索:使用Gensim的LuceneBM25Model配合Pyserini分析器。基线使用BRIGHT的BM25设置($ k_1=0.9, b=0.4 ),ReDI调整),ReDI调整),ReDI调整 k_3 $参数,对短文档设为0.4,长文档设为5。
- k1(词频饱和参数)。取值范围通常为 0~3,默认多为 1.2。避免某一查询词因在文档中过度重复(如恶意堆砌)而获得过高得分,平衡高频词与低频词的权重。越小意味着查询词在文档中出现次数的 “边际增益” 会越快饱和。
- b (文档长度归一化参数)。取值范围为 0~1,默认多为 0.75。文档越长,默认会因包含更多词汇而有更高匹配概率。b 值越小,越弱化这种 “长度优势”
- k3 越小会越放大重复关键词的效果,越大会纳入越多的词汇。
稠密检索:使用SBERT(768维双编码器)。ReDI对每个子查询和解释进行嵌入,通过加权平均融合(BRIGHT使用$ \lambda=0.5 $,长文档使用0.4)。
4.2 主要实验结果
4.2.1 BRIGHT基准测试表现
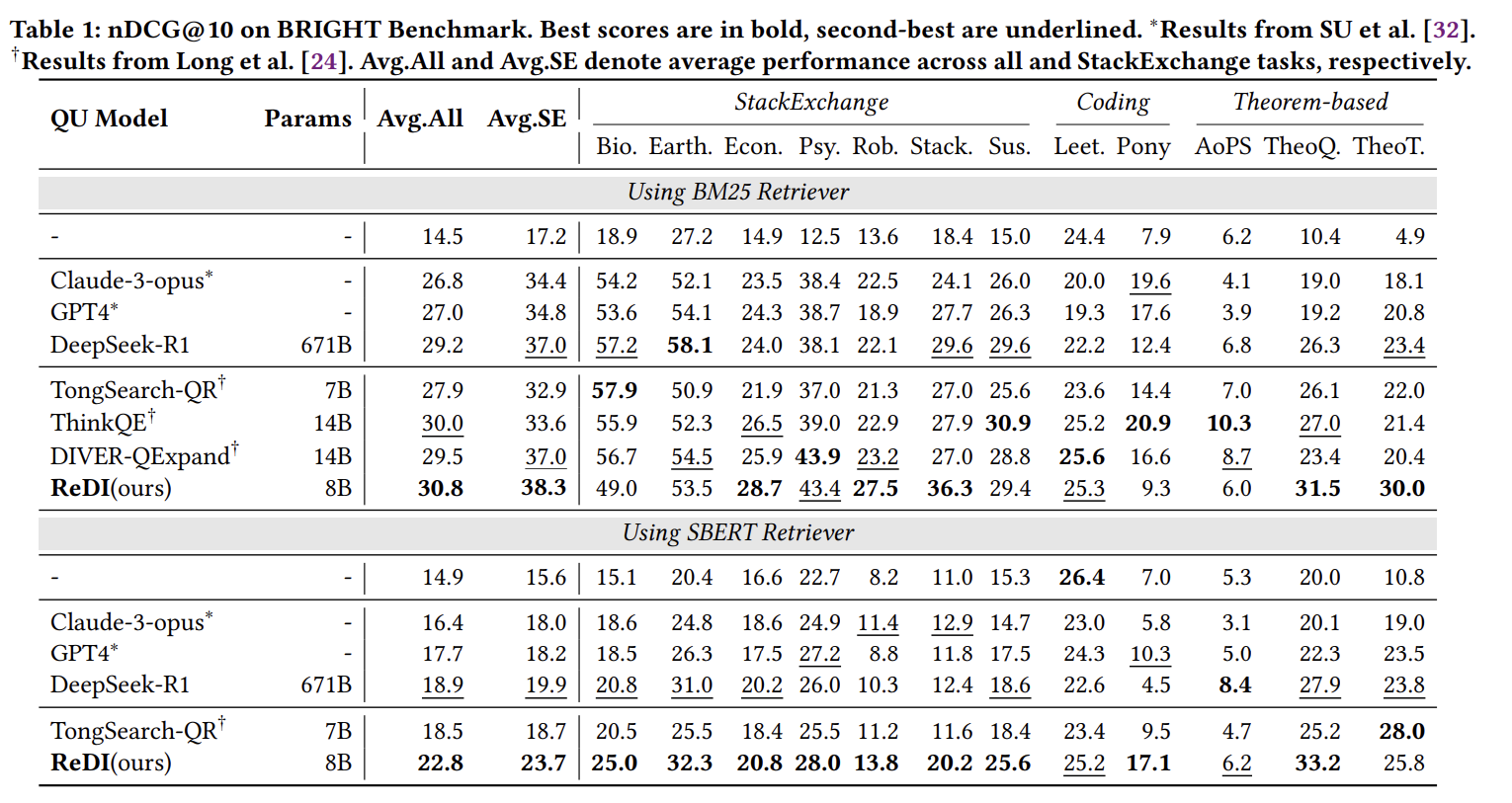
稀疏检索结果:
| 模型 | 参数量 | 平均nDCG@10 | StackExchange平均 | 编程 | 定理 |
|---|---|---|---|---|---|
| BM25(无QU) | - | 14.5 | 17.2 | 24.4 | 7.2 |
| Claude-3-opus | - | 26.8 | 34.4 | 20.0 | 14.0 |
| GPT-4 | - | 27.0 | 34.8 | 19.3 | 14.7 |
| DeepSeek-R1 | 671B | 29.2 | 37.0 | 22.2 | 18.8 |
| ThinkQE | 14B | 30.0 | 33.6 | 25.2 | 19.5 |
| DIVER-QExpand | 14B | 29.5 | 37.0 | 25.6 | 17.5 |
| ReDI | 8B | 30.8 | 38.3 | 25.3 | 22.5 |
ReDI在BM25上持续改进性能,在StackExchange领域实现最高平均nDCG@10为38.3%,相比单一长格式扩展方法(Claude-3-opus、GPT-4、DeepSeek-R1),ReDI的结构化分解和解释导致更有针对性的检索。
稠密检索结果:
| 模型 | 参数量 | 平均nDCG@10 | StackExchange平均 |
|---|---|---|---|
| SBERT(无QU) | - | 14.9 | 15.6 |
| DeepSeek-R1 | 671B | 18.9 | 19.9 |
| TongSearch-QR | 7B | 18.5 | 18.7 |
| ReDI | 8B | 22.8 | 23.7 |
使用SBERT检索器,单查询扩展相比稀疏设置产生有限的改进。尽管如此,**ReDI实现了最佳平均nDCG@10为22.8%,**在生物学和StackOverflow等任务上取得实质性提升。
4.2.2 跨域泛化能力:BEIR测试
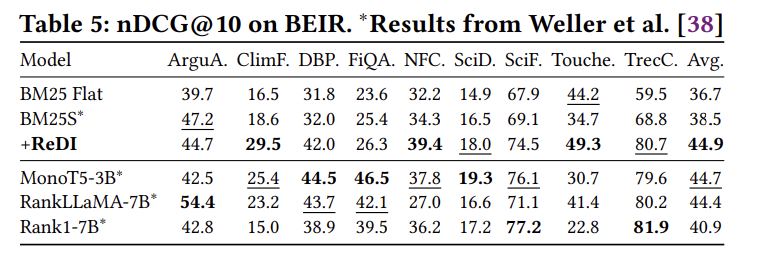
| 模型 | ArguA | ClimF | DBP | FiQA | NFC | SciD | SciF | Touche | TrecC | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|
| BM25 Flat | 39.7 | 16.5 | 31.8 | 23.6 | 32.2 | 14.9 | 67.9 | 44.2 | 59.5 | 36.7 |
| BM25* | 47.2 | 18.6 | 32.0 | 25.4 | 34.3 | 16.5 | 69.1 | 34.7 | 68.8 | 38.5 |
| MonoT5-3B | 42.5 | 25.4 | 44.5 | 46.5 | 37.8 | 19.3 | 76.1 | 30.7 | 79.6 | 44.7 |
| +ReDI | 44.7 | 29.5 | 42.0 | 26.3 | 39.4 | 18.0 | 74.5 | 49.3 | 80.7 | 44.9 |
ReDI配合BM25在9个任务上实现平均nDCG@10为44.9,超越Rank1-7B(40.9)、MonoT5-3B(44.7)和RankLLaMA-7B(44.4),展示了强大的跨域泛化能力。
4.3 长文档检索性能
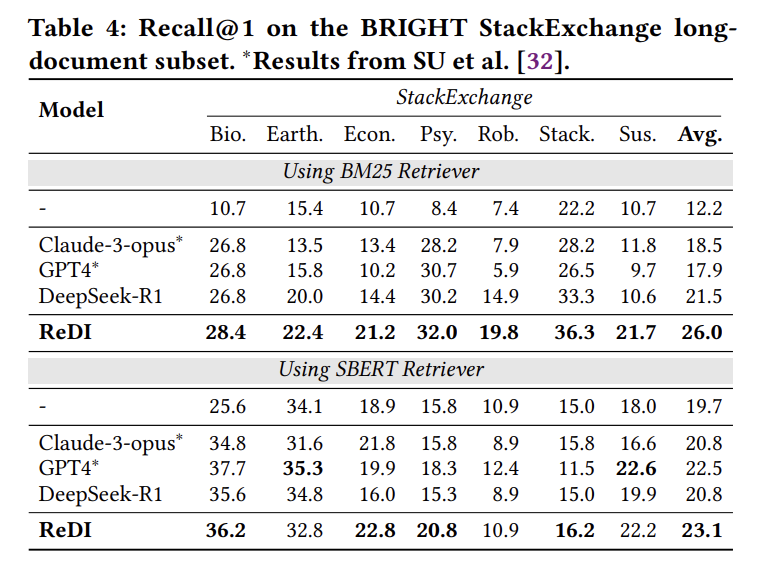
对于BRIGHT StackExchange长文档子集:
| 模型 | 生物 | 地球科学 | 经济 | 心理 | 机器人 | Stack | 可持续 | 平均Recall@1 |
|---|---|---|---|---|---|---|---|---|
| BM25基线 | 10.7 | 15.4 | 10.7 | 8.4 | 7.4 | 22.2 | 10.7 | 12.2 |
| +DeepSeek-R1 | 26.8 | 20.0 | 14.4 | 30.2 | 14.9 | 33.3 | 10.6 | 21.5 |
| +ReDI | 28.4 | 22.4 | 21.2 | 32.0 | 19.8 | 36.3 | 21.7 | 26.0 |
ReDI在所有7个任务上都领先(BM25都提升, SBERT部分提升),平均Recall@1为26.0%,相比DeepSeek-R1提升4.5个百分点,验证了推理分解与解释策略的有效性。
五、消融实验:组件贡献度分析
5.1 推理能力的作用
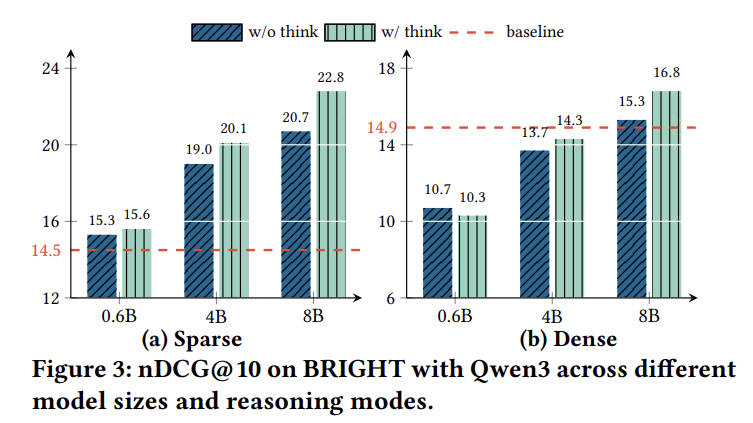
研究团队比较了不同规模的Qwen3模型(0.6B/4B/8B)在无思考(直接回答)和有思考(推理增强)模式下的表现:
关键发现:
- 模型规模增大和显式推理轨迹都导致BRIGHT检索性能的持续提升
- 推理优势随基础模型规模扩大而增强
5.2 解释对分解的贡献
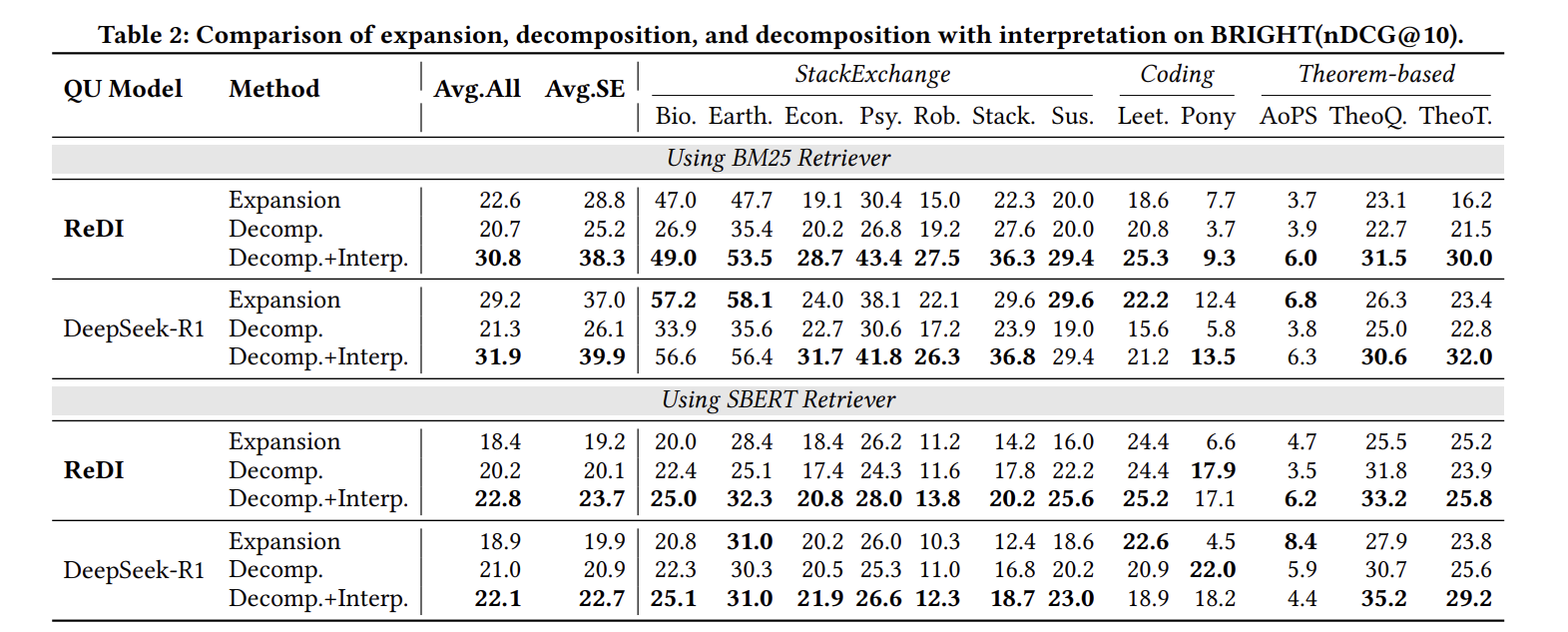
比较三种策略的性能:
| 策略 | BM25平均 | SBERT平均 | StackExchange(BM25) |
|---|---|---|---|
| 单一长格式扩展 | 22.6 | 18.4 | 28.8 |
| 仅分解 | 20.7 | 20.2 | 25.2 |
| 分解+解释 | 30.8 | 22.8 | 38.3 |
在两种检索范式和生成模型中,分解加解释方法在几乎所有任务和整体平均上都实现了最高的nDCG@10。这突显了:
- 分解本身不足够:单纯分解甚至可能比长格式扩展表现更差
- 解释提供语义基础:通过提供语义基础、减少词汇不匹配,实现对复杂多面查询的更完整覆盖
5.3 灵活分解vs固定分解
ReDI采用灵活分解,在所有固定设置下持续优于不同检索模型:
- 对复杂查询使用更多检索单元
- 对简单查询使用较少单元
- 动态调整分解粒度提升整体检索性能
5.4 超参数敏感性分析
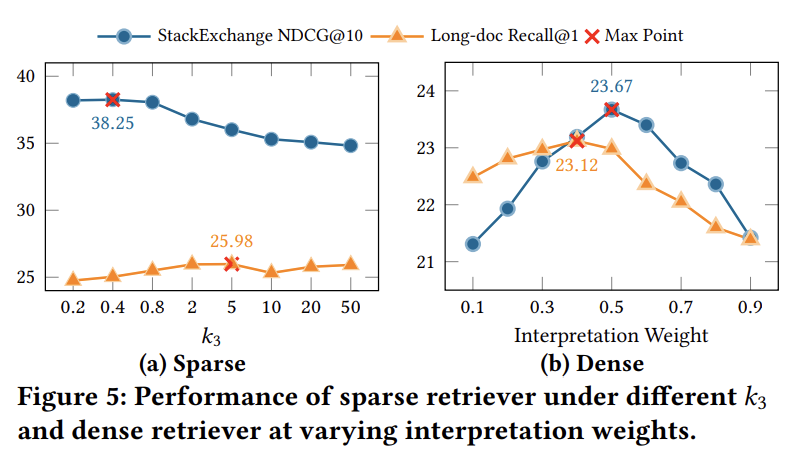
5.4.1 稀疏检索的$ k_3 $参数
对于较短文档,较小的k3k_3k3值(0.2-0.8)产生更好结果,在k3=0.4k_3=0.4k3=0.4时达到峰值nDCG@10为38.25。
相反,对于较长文档,Recall@1随k3k_3k3增大而改善,在k3=5k_3=5k3=5时达到最大值25.98并随后趋于平稳。
设计洞察:
- 短文档受益于低k3k_3k3,强调匹配更广泛的查询词汇
- 长文档需要高k3k_3k3,在更广泛内容中加强核心词汇信号
5.4.2 稠密检索的权重参数
nDCG@10在λ=0.5\lambda=0.5λ=0.5时达到峰值23.67,而Recall@1在λ=0.4\lambda=0.4λ=0.4时达到最大值23.12。
当插值向任一极端偏移时性能持续下降,突显了平衡意图(子查询)和上下文线索(解释)的重要性。
5.5 训练策略对比
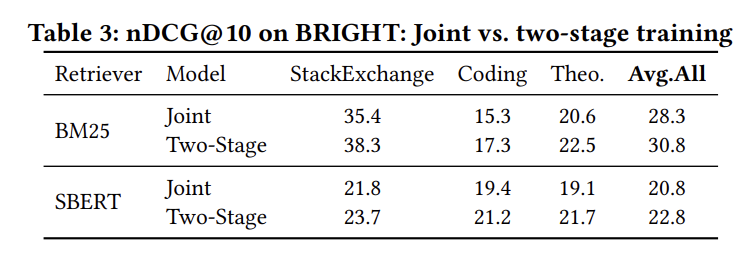
| 训练方法 | StackExchange(BM25) | 全部任务(BM25) | StackExchange(SBERT) | 全部任务(SBERT) |
|---|---|---|---|---|
| 联合训练 | 35.4 | 28.3 | 21.8 | 20.8 |
| 两阶段训练 | 38.3 | 30.8 | 23.7 | 22.8 |
两阶段训练在两种检索设置中持续优于联合训练。具体而言
原因分析:解耦学习目标使每个阶段能够专门化而不受梯度干扰,从而提高稳定性和整体检索效果。
5.6 与推理型检索器的交互
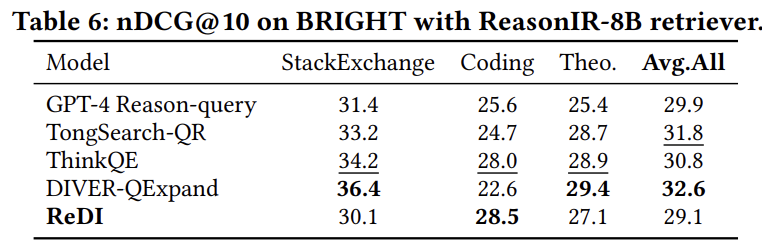
使用ReasonIR-8B作为检索器时的结果:
| 模型 | StackExchange平均 | 编程平均 | 定理平均 | 全部平均 |
|---|---|---|---|---|
| GPT-4推理查询 | 31.4 | 25.6 | 25.4 | 29.9 |
| DIVER-QExpand | 36.4 | 22.6 | 29.4 | 32.6 |
| ReDI | 30.1 | 28.5 | 27.1 | 29.1 |
使用**ReasonIR-8B**时,ReDI的表现不如其他单一长格式扩展方法。这可能是因为ReasonIR在合成的推理密集长格式查询上微调(300-2000个自然词),具有更大的嵌入尺寸(4096维),能够更好地捕捉复杂查询中的多维意图。
- ReasonIR - 8B 的核心优势就在于依托 ReasonIR - SYNTHESIZER 工具生成了大量 300 - 2000 词的合成推理密集型查询数据来微调模型。这类查询本身包含多层逻辑关联和抽象意图,比如跨段落的因果推导、多条件约束的问题等,模型在训练中早已适配了这类复杂查询的深层语义解析模式。
- 嵌入尺寸直接决定模型捕捉查询语义细节的能力。ReasonIR - 8B 采用 4096 维的大嵌入尺寸,相比主流模型 1536 维等常见尺寸,能为推理密集型查询分配更多语义存储空间,比如同时容纳查询中的背景信息、核心诉求、约束条件等多维意图,通过余弦相似度计算精准匹配到符合复杂逻辑的文档。
- ReasonIR-8B 的优势在于处理长文本、高推理复杂度的检索场景(如学术文献检索、多步骤问题解答),但代价是更高的计算资源需求(显存、算力)和更慢的响应速度。普通检索模型则在短查询、高吞吐量场景中更高效,资源消耗更低。
重要发现:BM25+ReDI在StackExchange任务上实现平均分38.3,优于最佳基线ReasonIR+DIVER-QExpand的36.4。这验证了ReDI能够有效提升轻量级检索器的性能,使其适用于实际部署。
六、创新点与差异化分析
6.1 核心创新点
1. 分解+解释的双重机制
与传统查询扩展方法不同,ReDI不是简单地生成长格式推理文本,而是:
- 结构化分解:将复杂查询拆解为独立的子意图
- 差异化解释:针对稀疏和稠密检索设计不同的解释策略
- 单元级检索:每个子查询独立检索后融合
这种设计避免了长格式扩展引入的噪声和主题漂移问题。
2. 检索器适配性设计
ReDI为稀疏和稠密检索设计了定制的查询提示,增强了在不同设置下的适应性:
- 稀疏检索:强调词汇扩展,引入同义词和术语变体
- 稠密检索:强调语义清晰度和改述
3. 知识蒸馏实现生产部署
使用DeepSeek-R1生成高质量意图标注,将其蒸馏到紧凑的学生模型(Qwen3-8B)以适应实际生产环境。这种方法实现了高效、可扩展和隐私保护的查询理解,且不牺牲性能。
4. Coin数据集的严格筛选
不同于简单从搜索日志中随机采样,Coin经过四阶段严格筛选,确保每个查询都真正需要多源推理,为训练提供了高质量监督信号。
6.2 与相关工作的对比
vs. 传统PRF方法:
传统伪相关反馈方法依赖初始检索质量,容易产生语义漂移。ReDI通过LLM的推理能力主动分解查询,不依赖初始检索结果。
vs. HyDE和Query2Doc:
这些方法生成假设文档或伪答案,但仍将查询作为单一单元处理。ReDI通过分解显式处理多面向信息需求。
vs. ReasonIR和ReasonRank:
这些方法训练推理导向的检索器或重排序器,需要专门的训练数据和大量计算资源。ReDI可与轻量级检索器(如BM25)配合使用,更具实用性。
vs. 反馈驱动方法(ThinkQE、DIVER):
ThinkQE和DIVER通过迭代细化查询,需要多轮检索反馈。值得注意的是,ReDI在不使用任何检索反馈的情况下超越了两者,突显了显式分解对意图理解的关键作用。
6.3 方法的理论基础
ReDI的有效性可以从信息检索理论的角度理解:
1. 分而治之原则:
复杂问题分解为简单子问题是经典的问题解决策略。在IR领域,这对应于将多面向信息需求分解为单一方面的子需求。
2. 查询-文档匹配的语义层级:
- 词汇层:稀疏检索关注词汇匹配
- 语义层:稠密检索关注概念匹配
- 推理层:ReDI的解释提供推理上下文
3. 冗余性原理:
多个子查询的融合优先考虑与多个检索单元相关的文档,利用冗余信号提升检索鲁棒性。
七、局限性分析与后续研究
7.1 论文自述局限性
ReDI虽然有效,但存在几个局限性,突显了未来工作的方向:
1. 稠密检索改进不如稀疏检索明显
这表明稠密表示与细粒度查询语义之间可能存在不匹配。未来需要研究:
- 如何设计更适合子查询+解释融合的稠密嵌入空间
- 探索子查询和解释嵌入空间的互补性
2. 分解依赖LLM内部知识
当前分解严重依赖LLM的内部知识,开发更受控的方法来决定分解什么和何时分解仍然是有趣的探索方向。可能的改进方向:
- 结合外部信号(如图结构、用户点击轨迹、网页摘要)指导分解
- 在知识稀疏领域实现更鲁棒的子查询生成
3. 自由格式解释可能引入虚假语义
自由格式解释可能引入降低检索准确性的虚假语义,激发关于可控生成、事实性约束和基于检索的验证的未来工作。
4. 检索器适配性有限
虽然ReDI具有竞争力,但ReasonIR的结果表明其收益在不同域之间不太稳定,激发关于检索器适配解释的未来工作以进一步增强鲁棒性。
7.2 实际应用中的挑战
基于对RAG系统普遍挑战的分析,ReDI在工业落地时可能面临:
1. 延迟问题
RAG系统面临延迟和性能瓶颈。ReDI的三阶段流程涉及:
- LLM调用进行分解和解释生成
- 多个子查询的并行检索
- 结果融合
实验数据显示,ReDI的QU阶段耗时8.50秒(稀疏)或7.74秒(稠密),虽然检索阶段很快,但总体延迟仍需优化。
解决方案:
- 批处理优化:并行处理多个子查询
- 模型压缩:进一步蒸馏到更小的模型
- 缓存机制:对常见查询模式缓存分解结果
2. 成本控制
每个查询需要多次LLM调用:
- 1次分解调用
- m次解释生成(m为子查询数量)
对于高QPS场景,成本可能成为瓶颈。
3. 调试复杂性
传统模型评估技术不适用于RAG系统,错误可能源自查询误解、检索不佳或检索上下文与生成之间的不对齐。ReDI的多阶段设计增加了调试难度:
- 分解是否准确?
- 解释是否相关?
- 融合权重是否合理?
4. 数据隐私与安全
RAG系统在专有或受监管数据集上运行,引发额外的数据隐私问题。对于Coin数据集的构建和使用,需要确保:
- 搜索日志的脱敏处理
- 用户隐私保护
- 合规性审计
7.3 后续研究补充
基于搜索结果,已有一些研究在补充ReDI的不足:
1. 多模态扩展
高级RAG系统支持多种数据类型,将向量搜索与SQL、图查询和API查找结合。ReDI目前仅处理文本查询,可以扩展到:
- 图像-文本联合查询
- 表格数据查询
- 多模态融合检索
2. 知识图谱集成
知识图谱RAG通过捕捉实体和关系来解决标准RAG框架将文档视为孤立单元的问题。将ReDI与知识图谱结合可以:
- 利用实体关系指导分解
- 基于图结构优化子查询生成
- 实现更精确的多跳推理
3. 自适应分解策略
将查询分解和文档选择建模为赌博机问题,解决了复杂信息需求的两个核心挑战:检索本质上是顺序的和预算受限的,子查询的相关性最初是不确定的。
- 对应 “顺序性 + 预算受限”:检索需按顺序生成子查询、选择文档,且算力 / 时间有限(类似赌博机的 “尝试次数上限”),需优先分配资源给潜在收益高的操作。
- 对应 “子查询相关性不确定”:子查询是否贴合原始需求、能否召回有效文档,初期未知(类似赌博机各臂的 “收益概率未知”),需通过 “探索(尝试新子查询)+ 利用(聚焦有效子查询)” 逐步明确。
这种方法可以帮助ReDI:
- 动态决定分解粒度
- 优化计算资源分配
- 提高检索效率
八、实际落地与复现指南
8.1 工业落地挑战
1. 生产环境适配
论文中提到的模型配置:
- 查询理解:Qwen3-8B(经过微调)
- 检索器:BM25或SBERT
- 硬件:A100 GPU用于训练
生产环境可能需要:
- 更轻量级的模型(如1.5B或3B参数)
- CPU友好的推理优化
- 分布式部署架构
2. 性价比考量
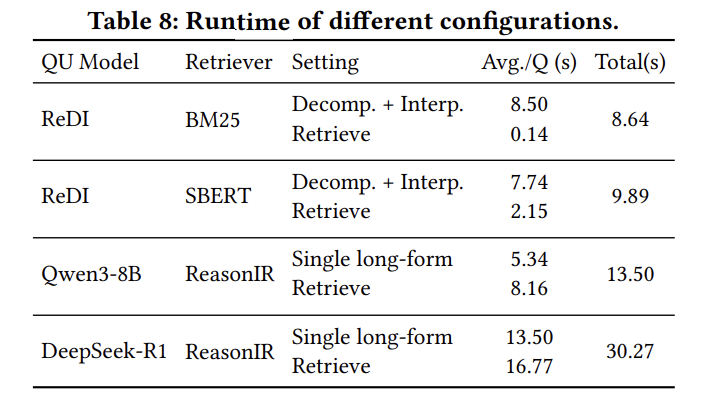
从效率分析表可以看出:
| 配置 | QU时间 | 检索时间 | 总时间 | 性能(nDCG@10) |
|---|---|---|---|---|
| BM25+ReDI | 8.50s | 0.14s | 8.64s | 38.3 (SE) |
| SBERT+ReDI | 7.74s | 2.15s | 9.89s | 23.7 (SE) |
| ReasonIR+Qwen3-8B | 5.34s | 8.16s | 13.50s | 30.1 (SE) |
| ReasonIR+DeepSeek-R1 | 13.50s | 16.77s | 30.27s | - |
经济性分析:
- BM25+ReDI:最佳性价比,检索极快但QU较慢
- SBERT+ReDI:适中性能,QU和检索都较快
- 专用检索器:性能强但成本高
3. 实时性要求
对于需要毫秒级响应的场景(如搜索引擎),ReDI的8-9秒延迟不可接受。可能的优化:
- 预计算:对高频查询预先分解和解释
- 增量处理:流式返回部分结果
- 混合策略:简单查询跳过分解,复杂查询才使用ReDI
8.2 复现步骤
8.2.1 代码开源情况
论文提到代码将发布在匿名链接:https://anonymous.4open.science/r/ReDI-6FC7/
但这是审稿期间的匿名链接。正式发布后应该会有公开的GitHub仓库。
目前可用的相关代码:
- BRIGHT基准:https://github.com/xlang-ai/BRIGHT
- TongSearch-QR:https://github.com/bigai-nlco/TongSearch-QR
- ReasonIR:https://huggingface.co/reasonir/ReasonIR-8B
8.2.2 关键实现步骤
步骤1:准备基础模型
# 下载Qwen3-8B基础模型
from transformers import AutoModelForCausalLM, AutoTokenizermodel_name = "Qwen/Qwen3-8B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
步骤2:构建训练数据
如果没有Coin数据集,可以:
- 从公开搜索日志(如MS MARCO)筛选复杂查询
- 使用DeepSeek-R1或GPT-4生成分解和解释标注
- 人工审核确保质量
步骤3:两阶段微调
# 伪代码示例
# 阶段1:分解模型训练
train_decomposition_model(model=model,data=decomposition_data, # 格式: (query, [sub-queries])learning_rate=1e-4,epochs=3
)# 阶段2A:稀疏解释模型
train_interpretation_model(model=model,data=sparse_interpretation_data, # 格式: (sub-query, sparse_interpretation)mode="sparse"
)# 阶段2B:稠密解释模型
train_interpretation_model(model=model,data=dense_interpretation_data, # 格式: (sub-query, dense_interpretation)mode="dense"
)
步骤4:检索器集成
from gensim.similarities import BM25# BM25配置
class ReDIRetriever:def __init__(self, k1=0.9, b=0.4, k3=0.4):self.k1 = k1self.b = bself.k3 = k3def retrieve(self, query, documents):# 1. 分解查询sub_queries = self.decompose(query)# 2. 生成解释interpretations = [self.interpret(sq) for sq in sub_queries]# 3. 独立检索scores = []for sq, interp in zip(sub_queries, interpretations):combined_query = sq + " " + interpscore = self.bm25_score(combined_query, documents)scores.append(score)# 4. 融合final_scores = self.fuse(scores)return final_scores
8.2.3 技术难点
1. Prompt工程
论文没有完整公开Prompt模板,需要自行设计。关键是:
分解Prompt设计:
Given a complex query, identify the core user intent and decompose it into independent sub-queries.Query: {query}Instructions:
1. Analyze what the user fundamentally seeks
2. Identify distinct sub-intents or aspects
3. Generate 2-7 clear, focused sub-queries
4. Ensure sub-queries are independent and complementaryOutput format:
Sub-query 1: ...
Sub-query 2: ...
...
解释Prompt设计(稀疏):
For the sub-query below, generate a lexically diverse interpretation that includes:
- Synonyms and morphological variants
- Domain-specific terminology
- Related concepts and phrasesSub-query: {sub_query}Sparse interpretation:
解释Prompt设计(稠密):
For the sub-query below, generate a semantic interpretation that:
- Paraphrases the core meaning
- Provides broader conceptual context
- Explains underlying assumptionsSub-query: {sub_query}Dense interpretation:
2. 超参数调优
需要针对具体数据集调整:
- BM25的k3k_3k3:短文档用0.4,长文档用5
- 稠密检索的λ\lambdaλ:通常0.4-0.5
- 分解数量:2-7个子查询
3. 评估流程
# 在BRIGHT上评估
from bright_evaluation import evaluate_brightresults = evaluate_bright(retriever=redi_retriever,dataset="biology",metric="ndcg@10"
)
8.3 模型选择建议
查询理解模型:
| 模型 | 参数量 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| Qwen3-8B | 8B | 性能强,推理能力好 | 较大,需GPU | 高质量要求 |
| Qwen3-4B | 4B | 平衡性能和效率 | 推理能力略弱 | 一般生产环境 |
| Qwen3-0.6B | 0.6B | 极快,CPU可运行 | 性能有限 | 资源受限场景 |
检索器选择:
| 检索器 | 优点 | 缺点 | 最佳搭配 |
|---|---|---|---|
| BM25 | 极快,无需训练 | 语义理解有限 | ReDI稀疏解释 |
| SBERT | 语义理解好,轻量 | 需要GPU | ReDI稠密解释 |
| ReasonIR-8B | 推理能力强 | 成本高,与ReDI不太匹配 | 长格式查询 |
生产部署建议:
- 原型阶段:使用Qwen3-8B + BM25,快速验证效果
- 优化阶段:蒸馏到Qwen3-4B,平衡性能和成本
- 大规模部署:考虑混合策略,简单查询直达,复杂查询才用ReDI
8.4 Prompt工程实践
虽然论文没有公开完整的Prompt,但基于论文描述和实践经验,关键Prompt应包含:
边界情况处理:
- 过度分解:限制子查询数量(2-7个)
- 分解不足:要求至少2个子查询,除非查询确实简单
- 解释质量控制:要求解释简洁(< 100词),相关且不重复原查询
# 带质量控制的Prompt示例
decomposition_prompt = """
Decompose this query into 2-7 independent sub-queries.Rules:
- Each sub-query must address a distinct aspect
- Avoid overlapping or redundant sub-queries
- Ensure sub-queries are self-containedQuery: {query}Think step by step:
1. What is the core intent?
2. What are the key aspects to cover?
3. Generate focused sub-queriesOutput (JSON format):
{"intent": "...","sub_queries": ["...", "..."]
}
"""
九、总结与展望
9.1 核心贡献总结
ReDI论文的主要贡献可以概括为:
- 理论贡献:证明了对于复杂查询,分解仍然是有效的方法,但需要配合解释来提升检索性能
- 方法创新:设计了三阶段pipeline(分解-解释-融合),针对稀疏和稠密检索定制化解释策略
- 数据资源:构建并开源了3403条真正需要多源推理的复杂查询数据集Coin
- 实用价值:通过知识蒸馏实现了生产级部署,使用8B模型达到或超越671B模型的性能
9.2 对RAG领域的启示
1. 查询理解的重要性被重新强调
在大模型时代,很多研究者将重点放在检索器和生成器的优化上,而忽视了查询理解。ReDI证明,即使使用简单的BM25,配合好的查询理解也能达到SOTA性能。
2. 结构化优于自由生成
相比直接让LLM生成长格式推理文本,结构化的分解+解释范式更有效。这提示我们在设计LLM系统时,应该引入更多的结构化约束。
3. 轻量级方案的可行性
不是所有问题都需要670B参数的模型。通过精心设计的方法和高质量数据,8B模型可以与巨型模型竞争。
9.3 未来研究方向
基于ReDI的工作和现有局限性,未来可以探索:
- 自适应分解:根据查询复杂度动态决定是否分解以及分解粒度
- 多模态扩展:将方法扩展到图像、视频、表格等多模态查询
- 在线学习:从用户反馈中持续学习,优化分解和解释策略
- 知识图谱结合:利用结构化知识指导分解和推理
- 可解释性增强:让系统能够解释为什么这样分解,提升用户信任
- 跨语言泛化:将方法应用到多语言场景
- 领域适配:针对医疗、法律等专业领域定制解释策略
参考文献
- 论文原文: Zhong, Y., Yang, J., Fan, Y., et al. (2025). Reasoning-enhanced Query Understanding through Decomposition and Interpretation. arXiv:2509.06544. https://arxiv.org/abs/2509.06544
- BRIGHT基准: Su, H., Yen, H., Xia, M., et al. (2025). BRIGHT: A Realistic and Challenging Benchmark for Reasoning-Intensive Retrieval. ICLR 2025. https://brightbenchmark.github.io/
- BEIR基准: Thakur, N., Reimers, N., Rücklé, A., et al. (2021). BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models. https://github.com/beir-cellar/beir
- ReasonIR: Shao, R., Qiao, R., Kishore, V., et al. (2025). ReasonIR: Training Retrievers for Reasoning Tasks. https://huggingface.co/reasonir/ReasonIR-8B
- TongSearch-QR: Qin, X., Bai, J., Li, J., et al. (2025). TongSearch-QR: Reinforced Query Reasoning for Retrieval. https://github.com/bigai-nlco/TongSearch-QR
- RAG局限性综述: TechTarget (2025). Understanding the limitations and challenges of RAG systems. https://www.techtarget.com/searchenterpriseai/tip/Understanding-the-limitations-and-challenges-of-RAG-systems
- 查询分解在RAG中的应用: Medium (2024). Advanced RAG Optimization: Smarter Queries, Superior Insights. https://medium.com/@myscale/advanced-rag-optimization-smarter-queries-superior-insights-d020a66a8fac
- 知识图谱RAG: EdenAI (2025). The 2025 Guide to Retrieval-Augmented Generation (RAG). https://www.edenai.co/post/the-2025-guide-to-retrieval-augmented-generation-rag