机器学习周报二十二
文章目录
- 摘要
- Abstract
- 1 目标检测
- 1.1 RCNN
- 2 图像分割
- 2.1 语义分割FCN算法
- 2.2 语义分割Unet算法
- Swin-Transformer
- 总结
摘要
本周学习的是目标检测和图像分割任务的做法,并且补充了swin-transformer模型的位置编码模块,学习swin-transformer如何应用于其他的视觉任务。
Abstract
This week, we studied methods for object detection and image segmentation, and additionally explored the positional encoding module of the Swin-Transformer model, learning how the Swin-Transformer can be applied to other visual tasks.
1 目标检测
之前学习的任务都是分类任务,对其他任务的迁移从来没有过,在学习了swin-transformer之后,swin-transformer可以很好的迁移到视觉的其他任务,比如物体检测、图像语义分割。在此之前,先了解目标检测和图像分割的基础流程。
1.1 RCNN
RCNN是2014年提出的目标检测算法,与之前的SVM和随机森林不同,RCNN引入了卷积神经网络,利用卷积神经网络强大的特征学习能力,极大地改进了目标检测的准确性和性能。
RCNN的核心思想是将目标检测问题转化成一系列的候选区域的分类问题。第一步,基于选择性搜索的方法生成一组可能包含目标的候选区域。第二步,对于每个候选区域,通过神经网络提取特征。第三步,将特征输入到SVM分类器,判断这个区域有没有目标,同时还有一个边界框回归器用于定位目标的位置。
(1)Selective Search算法
在不能事先知道物体的大小的情况下,传统的方法是用不同的矩形框,一行一行地扫描整张图像,通过提取框内特征判断有没有物体,这种方法复杂度太高。Selective Search采用一种具备层次结构的算法,负责快速生成可能是物体的区域,而不做具体的预测。
1.借助efficient graph-based image segmentation提到的图分割方法初始化区域集R;这个方法的大致做法就是,一张图开始所有的像素都是孤立的,从第一个像素开始计算与其他相邻像素的权值(像素值的平方差,最小的一个平方差的像素和这个像素相连,得到一个区域,然后下一个相邻像素和区域计算差值,判断是不是小于阈值,然后合并,区域和区域之间的合并判断:diff(c1,c2)>min(int(c1),int(c2))diff(c_1,c_2)>min(int(c_1),int(c_2))diff(c1,c2)>min(int(c1),int(c2))。c1c_1c1代表区域1,int(c1)int(c_1)int(c1)代表区域1内的最大边权重)
2.计算R中相邻区域的相似度,并以此构建相似度集S;
3.如果S为空,跳转步骤4,S不为空,则执行:
①获取S中的最大值s(ri,rj)s(r_i,r_j)s(ri,rj);
②将rir_iri与rjr_jrj合并成一个新的区域rtr_trt;
③将S中与rir_iri有关的值S(ri,r∗)S(r_i,r_*)S(ri,r∗)都去掉;
④将S中与rjr_jrj有关的值S(rj,r∗)S(r_j,r_*)S(rj,r∗)都去掉;
⑤执行步骤2,构建StS_tSt,是S的元素和rtr_trt之间相似度的集合。
⑥将StS_tSt的元素全部添加到S中;
⑦将rtr_trt放入R中;
4.将R中的区域作为目标的位置框L。
相似度的计算有:颜色,纹理、尺度、填充相似度。
(2)获取图像特征
借助于AlexNet或者VGGNet等算法来获取图像特征。
(3)获取当前区域类别
通过分类器进行分类。
(4)微调区域位置
通过位置回归器对位置进行微调。
这就是RCNN算法的大概流程,算法的难处可能是在Selective Search上了。传统算法的暴力搜索,范围很大,计算量也很大,经过Selective Search可以捕捉到不同尺度、多样化的特征,而且计算量降低很多。
但是RCNN也不是很好的算法,测试速度很慢,Selective Search提取候选框需要时间,候选框之间又存在重叠。从算法的步骤看,训练之前的准备步骤就很多,AlexNet训练的时间也很长。
对于Swin-Transformer应用于目标检测,将Swin-Transformer替换AlexNet进行特征提取。
2 图像分割
图像分割主要分为三大领域:语义分割(Semantic Segmentation)、实例分割(Instance Segmentation)、全景分割(Panoptic Segmentation):
语义分割:每个像素对应一个类标签。同一类会被定义成一个区域块,不区分其中单个物体。
实例分割:每个对象的掩码和类标签。区分单个物体以及单个物体所属的类型,无法识别的都作为背景。
全景分割:每像素类+实例标签。相当于在语义分割的基础上,增加单个实例的区分。
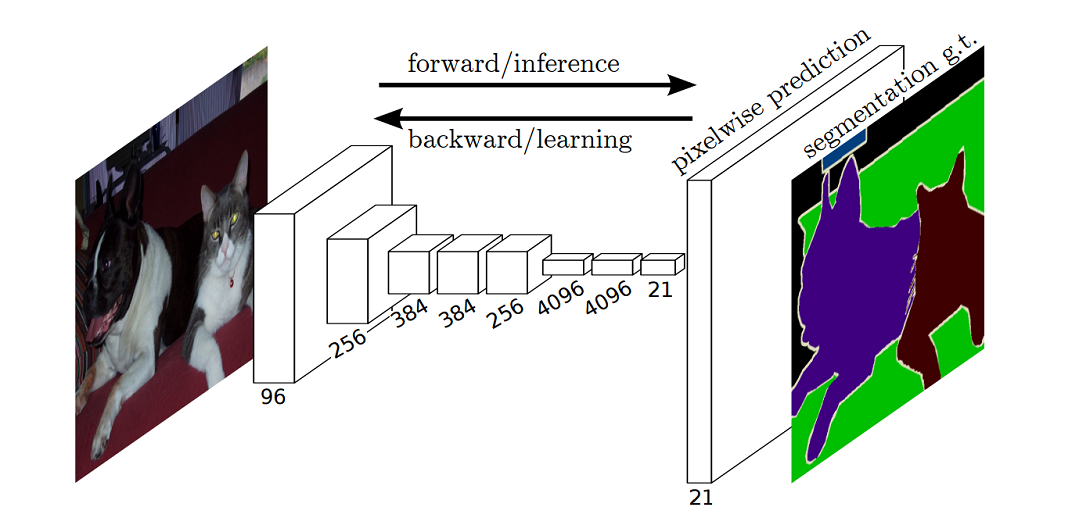
2.1 语义分割FCN算法
FCN是2015年提出的算法,将传统CNN的全连接层换成卷积层。然后再上采样成原图大小。
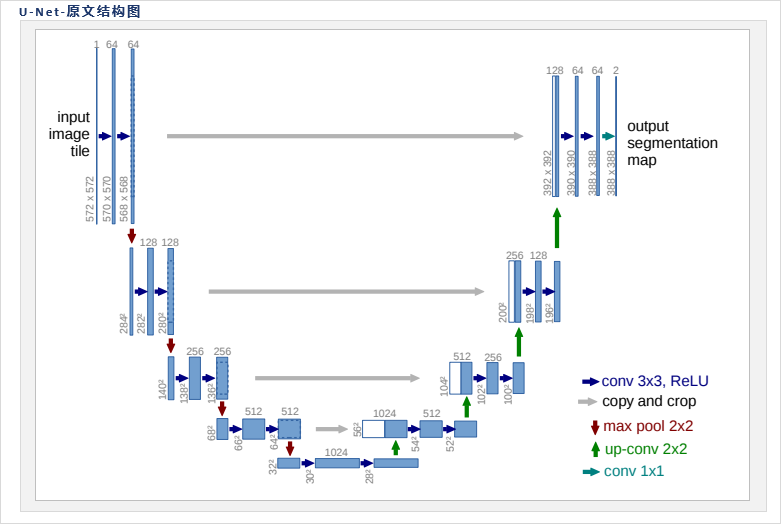
2.2 语义分割Unet算法
通过卷积提取特征再通过上采样对像素进行预测,通过跳跃连接来补充上采样的输入,让特征的语义更强。
我也实现了一个简单的unet:https://gitee.com/diskcache/torch.git用于CamVid数据集的图像分割,最后的准确率在60%左右,由于笔记本性能的限制,没办法将特征维度设置得很大,模型的实现方面也不够高效和正确,导致unet的效果不好。
在此之外还有实例分割Mask RCNN算法、全景分割UPSnet算法
使用swin-transformer替换特征提取模块,需要把输出的序列进行转换,完成后面的跳跃连接和上采样步骤。
Swin-Transformer
在之前的transformer的基础上,加入了位置编码模块,但是对模型的提升很低,可能是由于图片尺寸太小,stage设置不合理,每一个stage的模块数没有差异,可能在捕捉全局特征的能力就没那么好。
模型的提点只有1%.
使用设备: cuda
模型参数量: 1268434
Epoch 1, Loss: 1.6553, Accuracy: 39.66%
Epoch 2, Loss: 1.3325, Accuracy: 51.89%
Epoch 3, Loss: 1.1706, Accuracy: 57.76%
Epoch 4, Loss: 1.0421, Accuracy: 62.73%
Epoch 5, Loss: 0.9333, Accuracy: 66.61%
Epoch 6, Loss: 0.8334, Accuracy: 70.32%
Epoch 7, Loss: 0.7319, Accuracy: 73.84%
Epoch 8, Loss: 0.6324, Accuracy: 77.48%
Epoch 9, Loss: 0.5267, Accuracy: 81.48%
Epoch 10, Loss: 0.4321, Accuracy: 84.75%
Test loss: 1.1943
Test accuracy: 63.77% (6377/10000)
代码存放在https://gitee.com/diskcache/torch.git
总结
本周学习了视觉除分类外的另外的两大块,对其中的原理和逻辑有所了解,同时实现了swin-transformer加入位置编码。