(论文速读)具有深度引导交叉视图一致性的3D高斯图像绘制
论文题目:3D Gaussian Inpainting with Depth-Guided Cross-View Consistency(具有深度引导交叉视图一致性的3D高斯图像绘制)
会议:CVPR2025
摘要:当使用神经辐射场(NeRF)或3D高斯飞溅(3DGS)等新颖的视图渲染方法执行3D图像绘制时,如何在相机视图中实现纹理和几何形状的一致性一直是一个挑战。在本文中,我们提出了一种具有深度引导交叉视图一致性的三维高斯绘制框架(3DGIC),用于交叉视图一致性的三维绘制。在每个训练视图的渲染深度信息的指导下,我们的3DGIC利用不同视图中可见的背景像素来更新喷漆掩码,使我们能够改进3DGS用于喷漆目的。通过对基准数据集的广泛实验,我们确认我们的3DGIC在定量和定性上都优于当前最先进的3D绘图方法。

引言:3D世界的"橡皮擦"
想象这样一个场景:你拍摄了一个美丽公园的多角度照片,但照片中有一个不想要的雕像。传统的PS只能一张张修,而且不同角度修出来的效果对不上。如果能在3D空间直接"擦除"这个雕像,让各个角度看起来都自然一致,该有多好?
这正是3D场景修复(3D Scene Inpainting)要解决的问题。最近在CVPR 2025上发表的一篇论文《3D Gaussian Inpainting with Depth-Guided Cross-View Consistency》提出了创新的解决方案,让这个梦想更接近现实。
现有方法的困境
问题1:各自为政的2D修复
早期方法(如SPIn-NeRF)的思路是:
- 对每张照片分别用2D修复工具(如Photoshop的内容感知填充)处理
- 用处理后的照片训练NeRF或3DGS模型
听起来合理,但问题来了:每张照片是独立修复的,3D一致性无法保证。就像多个画家各画一面墙,拼起来可能对不上。
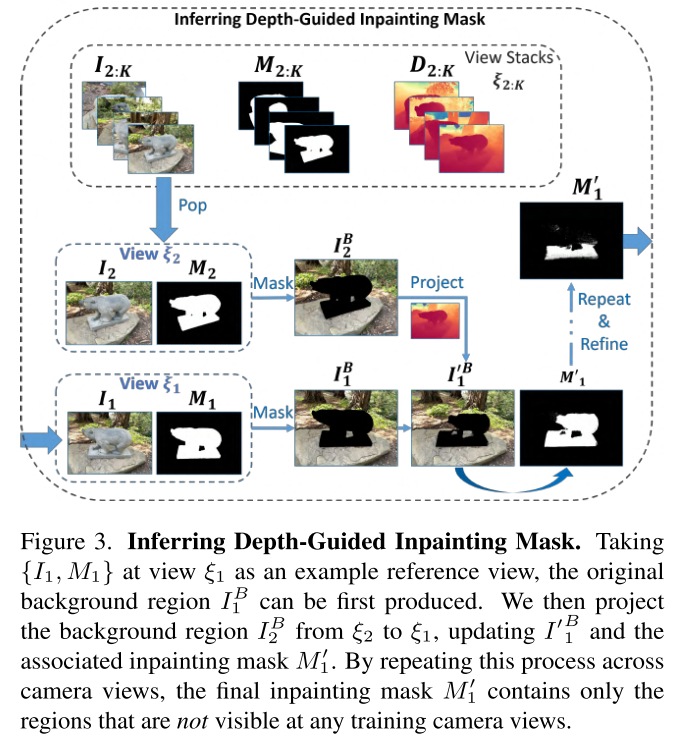
问题2:修复掩码的"越界"
即使使用最先进的SAM(Segment Anything Model)自动生成修复掩码,仍存在一个隐蔽问题:
某个视角的掩码区域,可能包含在其他视角中实际可见的背景!
举例:从正面看,雕像挡住了后面的树。掩码覆盖了雕像+被挡的树。但从侧面看,那棵树清晰可见。如果直接修复正面图,可能生成一棵与侧面不一致的"假树"。
创新方案:深度引导的智能修复
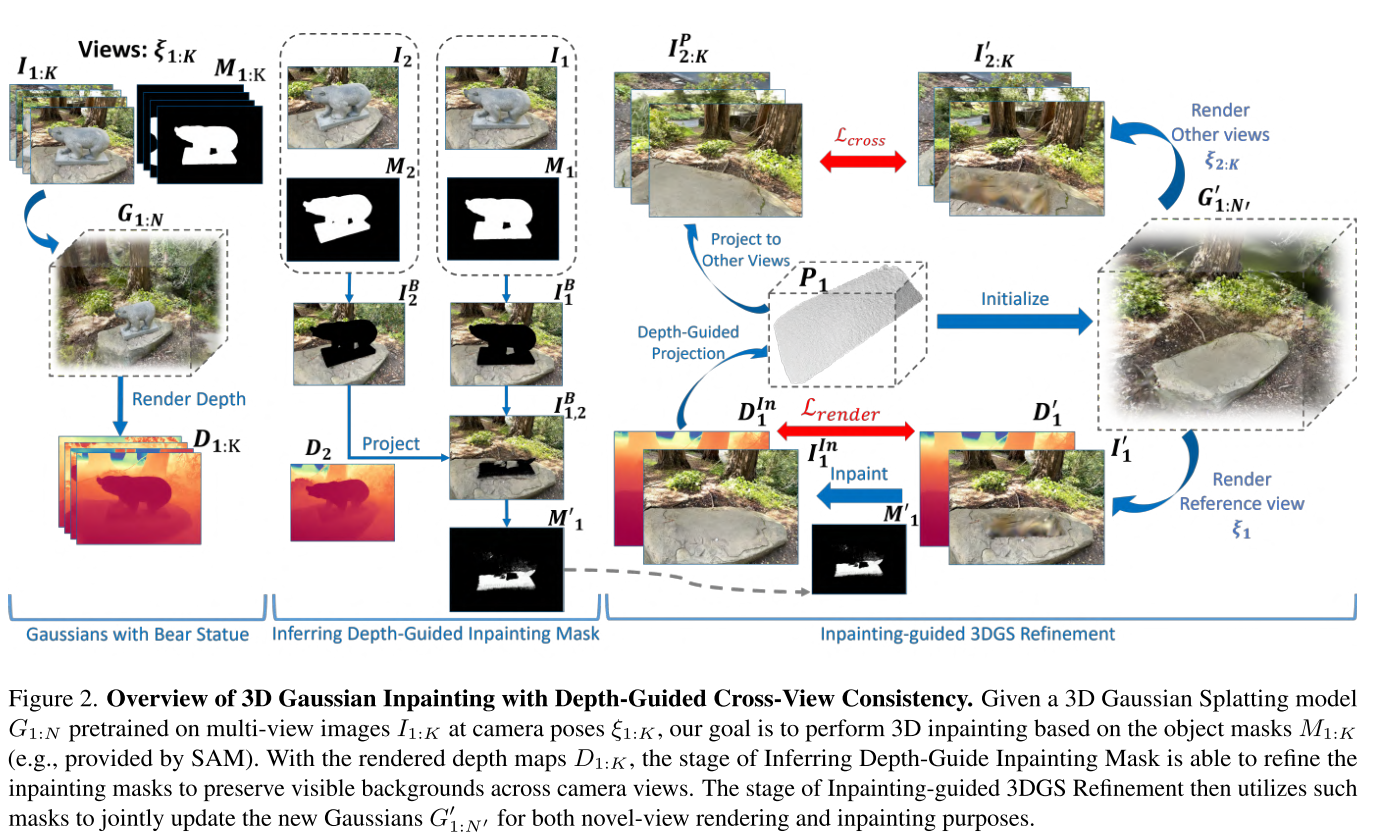
核心思想1:深度信息当"侦探"
论文的第一个创新是深度引导修复掩码:
步骤拆解:
- 渲染深度图:从预训练的3DGS模型获取所有视角的深度图
- 跨视角投影:
- 视角A的背景像素 → 3D空间(用深度+相机参数)
- 3D点 → 投影回视角B
- 智能剔除:如果视角B的某个"待修复"区域,在视角A中实际可见,就把它从修复掩码中移除
- 遍历所有视角:重复上述过程,最终得到"真正需要修复"的区域
打个比方:就像多个摄像头监控一个房间,通过对比各摄像头画面,我们能准确找出哪些区域是"所有摄像头都看不到的死角",只修复这些死角。
核心思想2:单一高质量修复引导全局
传统方法是"多个粗糙修复",本文提出"单一精细修复+投影传播":
工作流程:
- 选参考视角:选择修复掩码最大的视角(覆盖最多3D空间)
- 精修参考视角:用2D修复模型同时修复RGB图像和深度图
- 投影到其他视角:
- 将修复结果转成3D点云
- 投影到其他视角作为"标准答案"
- 联合优化:
- 其他视角的渲染要与投影内容保持感知一致性(LPIPS损失)
- 参考视角要与修复结果匹配(RGB+深度损失)
损失函数设计:
总损失 = 渲染损失(RGB损失 + 深度损失)+ 跨视角一致性损失(LPIPS)
这种设计确保了:
- 高保真:参考视角修复质量高
- 强一致性:其他视角通过投影约束与参考视角对齐
- 几何合理:深度监督确保3D结构正确
实验效果:全面领先
定量结果
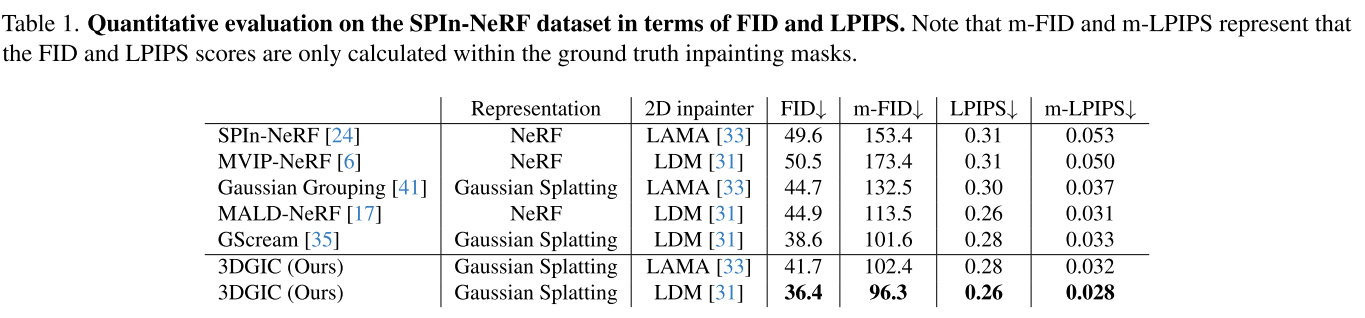
在SPIn-NeRF基准数据集上,相比现有最佳方法GScream:
- FID(图像质量):36.4 vs 38.6(降低5.7%)
- m-FID(修复区域质量):96.3 vs 101.6(降低5.2%)
- LPIPS(感知相似度):0.26 vs 0.28(降低7.1%)
定性观察



对比图显示本文方法的显著优势:
细节保留:
- GScream可能丢失背景细节(如桌上的电源插座)
- 本文方法完整保留可见背景
一致性:
- MALD-NeRF虽然修复质量高,但不同视角的logo图案不一致
- 本文方法跨视角高度一致
复杂场景适应:
- 在360度环绕场景(如InNeRF360数据集)中表现依然优异
- Gaussian Grouping会产生黑洞和阴影,本文方法平滑自然
消融实验的启示
通过逐步移除各模块的对比:

- 只用深度引导掩码:背景保留好,但修复区域模糊
- 只用跨视角一致性:修复区域清晰,但会错误修改可见背景
- 两者结合:既保留背景又修复清晰,达到最佳效果
这验证了两个模块缺一不可且协同增效。
技术细节深挖
为什么选择3DGS而非NeRF?
论文选择3D Gaussian Splatting作为底层表示,主要考虑:
- 速度:3DGS渲染达到100 fps,而最快的NeRF方法仅10 fps
- 显式表示:Gaussians是显式点云,更便于编辑(删除对应Gaussians即可)
- 实用性:快速渲染使方法更适合实际VR/AR应用
2D修复器的选择
论文测试了两种2D修复模型:
- LAMA:基于傅里叶卷积的非扩散模型,速度快
- LDM:Latent Diffusion Model,质量高但较慢
有趣发现:即使使用较简单的LAMA,本文方法也能超越使用LDM的竞争方法,说明框架设计比2D修复器选择更关键。
深度投影的数学
跨视角投影的核心公式:
I^B_{1,2} = Proj^{2D}(Proj^{3D}(I^B_2, D_2, ξ_2), ξ_1) · M_1
其中:
Proj^{3D}:将2D像素通过深度和相机参数投影到3D空间Proj^{2D}:将3D点云投影回2D图像平面· M_1:仅保留落在原掩码内的像素
这个操作本质是多视角几何的应用,利用深度建立不同视角间的几何对应关系。
方法的局限与未来方向
当前局限
- 依赖预训练模型:需要先训练好3DGS模型,如果初始重建质量差,深度图不准确会影响掩码质量
- 2D修复器依赖:虽然框架通用,但最终质量仍受2D修复模型影响
- 计算成本:需要多次渲染和投影,相比直接2D修复计算量更大
可能的改进方向
- 端到端训练:将3DGS重建和修复统一到一个框架
- 3D感知修复:训练直接在3D空间操作的修复模型,而非依赖2D工具
- 实时应用:优化算法使其能在VR/AR设备上实时运行
- 泛化能力:当前针对每个场景独立优化,未来可探索跨场景的修复先验
实际应用场景
这项技术的潜在应用包括:
VR/AR内容编辑:
- 在虚拟场景中移除不需要的物体
- 实时编辑增强现实中的元素
影视后期制作:
- 从多角度拍摄的场景中移除穿帮对象(如威亚、反光板)
- 修复历史建筑的3D重建(移除现代设施)
房地产可视化:
- 从房屋照片中移除家具,展示空房效果
- 保证各角度视觉一致
文化遗产保护:
- 数字化重建古迹时移除现代干扰物
- 虚拟修复受损遗址
总结:3D修复的范式转变
这篇论文的核心贡献不仅是性能提升,更是思维方式的转变:
从"多个独立2D修复"到"深度引导的3D一致性修复"
关键创新点:
- ✅ 深度信息作为桥梁:连接多视角几何关系
- ✅ 智能掩码优化:只修复真正需要的区域
- ✅ 单源高质量扩散:用一个精修结果引导全局
- ✅ 显式一致性约束:通过投影机制而非隐式学习
这些创新使3D场景修复在保真度和一致性上达到新高度,为虚拟内容编辑开辟了更广阔的可能性。