深入理解MySQL:体系结构与SQL语句执行流程
在数据库领域,MySQL作为开源关系型数据库的佼佼者,被广泛应用于各类系统中。无论是日常业务查询还是高频数据更新,了解MySQL的内部体系结构与SQL语句执行流程,都是开发者优化性能、排查问题的核心基础。本文将从MySQL的分层结构入手,详细拆解查询语句与更新语句的完整生命周期,帮助大家建立对MySQL运行机制的系统性认知。
1. MySQL 体系结构:分层设计的核心逻辑
MySQL采用分层架构,核心分为「Server层」和「存储引擎层」,这种设计让MySQL具备了良好的灵活性——不同存储引擎(如InnoDB、MyISAM)可按需替换,同时Server层提供统一的核心能力。其整体结构可通过下图直观理解(原文配图参考):
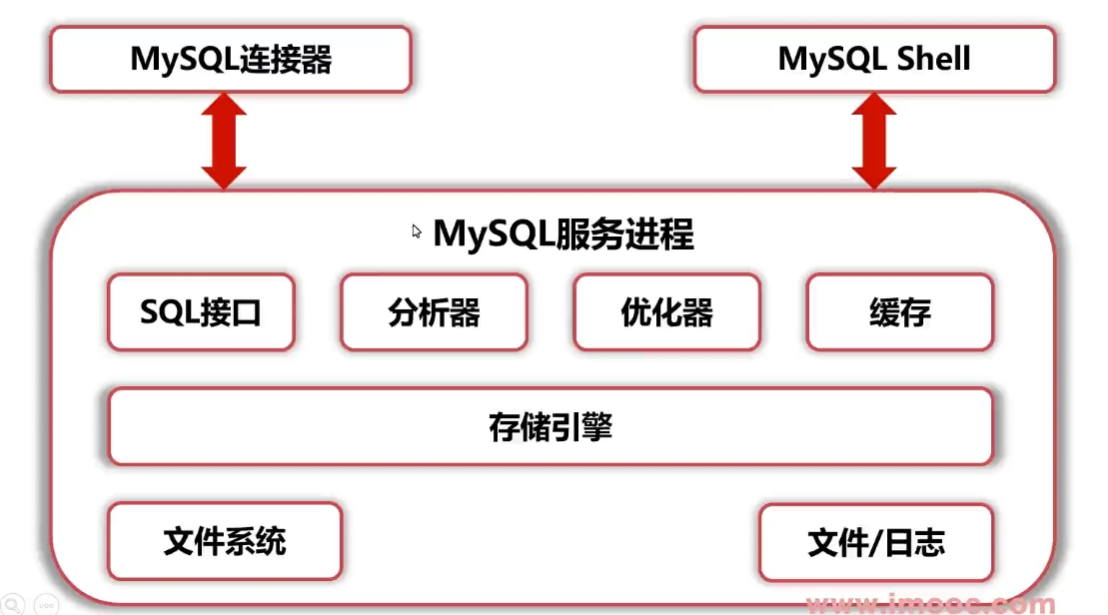
1.1 Server层:统一的核心能力集合
Server层是MySQL的“大脑”,负责处理客户端请求、SQL解析与优化、权限校验等核心逻辑,主要包含以下组件:
-
连接器:客户端与MySQL交互的“入口”,核心作用包括:
- 建立TCP连接,完成身份认证(用户名/密码校验);
- 授予用户对应的操作权限(权限校验仅在连接建立时执行一次);
- 维持与管理连接(长连接/短连接控制,连接超时回收)。
-
SQL接口:接收客户端发送的SQL语句,转发至后续组件处理,并将最终结果返回给客户端,是SQL语句的“中转站”。
-
缓存模块:包含查询缓存、元数据缓存、索引缓存等,其中查询缓存需重点关注:
- MySQL 8.0 及以后版本:官方直接移除了查询缓存功能;
- MySQL 8.0 之前版本:即使可通过SQL开启(如
SET GLOBAL query_cache_type=1),也不建议使用,原因如下:- 缓存命中条件严苛:需SQL语句完全匹配(空格、大小写差异都会导致缓存失效);
- 高并发瓶颈:缓存更新时会加锁,高频写操作会导致缓存频繁失效,反而拖慢性能;
- 内存占用高:缓存结果集需占用大量内存,可能挤压其他核心操作(如索引查询)的内存资源。
-
分析器:SQL语句的“语法翻译官”,分两步处理:
- 词法分析:识别SQL中的关键字(如
SELECT、FROM)、表名、列名等,确定每个字符串的含义; - 语法分析:校验SQL是否符合MySQL语法规则(如关键字顺序、括号匹配),若语法错误则直接返回报错,语法正确则生成“解析树”传递给优化器。
- 词法分析:识别SQL中的关键字(如
-
优化器:SQL执行计划的“决策者”,核心目标是选择最优执行方案,主要优化方向包括:
- 索引选择:判断是否使用索引、使用哪个索引(如避免全表扫描);
- 表关联顺序:多表JOIN时,决定先关联哪张表(选择数据量更小的表作为驱动表,减少关联次数);
- SQL重写:将复杂SQL转换为等价的高效形式(如子查询优化为JOIN)。
1.2 存储引擎层:数据存储与读写的“执行者”
存储引擎层是MySQL的“手脚”,负责与文件系统交互,处理数据的实际存储、读取、锁控制等操作。MySQL支持多种存储引擎,其中InnoDB(MySQL 5.5及以后默认存储引擎)是最常用的,核心职责包括:
- 数据页管理:将磁盘数据按“页”(默认16KB)加载到内存缓存,减少磁盘IO;
- 事务与日志管理:通过Undo Log、Redo Log、Binlog保证事务的ACID特性;
- 锁机制:支持行级锁、表级锁,满足高并发场景下的数据一致性需求。
2. 一条查询语句的生命历程:从请求到响应
以常见的SELECT * FROM user WHERE id = 1;为例,我们拆解其完整执行流程,理解Server层与存储引擎层的协同工作逻辑(原文配图参考):
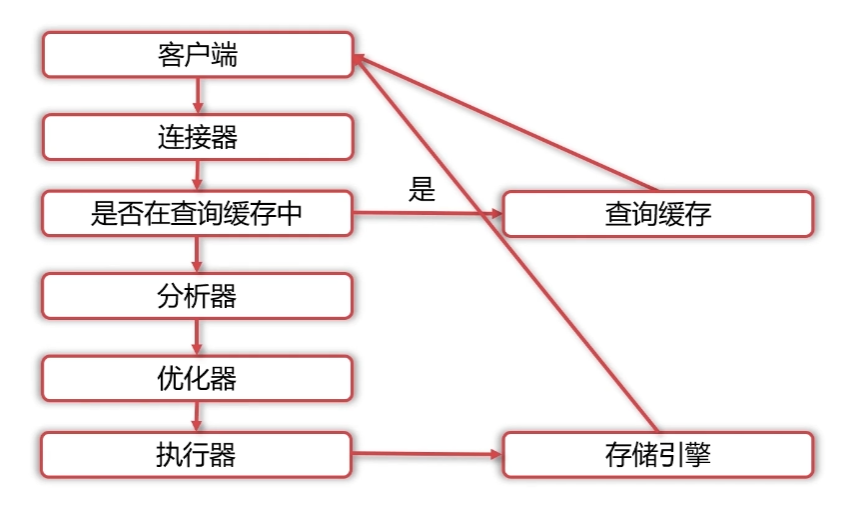
步骤1:连接器建立连接并校验权限
客户端通过mysql -u username -p等命令发起连接,连接器完成:
- TCP三次握手建立连接;
- 校验用户名/密码,授予用户对
user表的操作权限(仅登录时校验); - 若连接空闲超过
wait_timeout(默认8小时),则自动断开连接。
步骤2:查询缓存校验(仅MySQL 8.0前)
- 若开启查询缓存,MySQL会以“SQL语句”为Key,查询缓存中是否存在匹配的结果集;
- 若命中缓存:直接将结果集通过连接器返回给客户端,跳过后续步骤;
- 若未命中缓存:进入分析器处理。
步骤3:分析器生成解析树
- 词法分析:识别
SELECT(查询操作)、user(表名)、id(列名)、1(条件值); - 语法分析:校验
SELECT * FROM user WHERE id = 1;符合MySQL语法,生成“解析树”(描述SQL的执行逻辑)。
步骤4:优化器确定最优执行计划
优化器分析解析树后,做出决策:
- 判断
id列是否有索引(假设id是主键,有聚簇索引); - 选择“通过主键索引查询
id=1的记录”作为最优执行计划,避免全表扫描。
步骤5:执行器调用存储引擎获取数据
- 权限二次校验:执行器校验用户是否有
user表的SELECT权限(连接器仅校验登录权限,此处校验表级操作权限); - 调用存储引擎:执行器向InnoDB发送“查询
id=1的记录”的请求; - 存储引擎执行:InnoDB从内存缓存或磁盘中读取
id=1的记录,返回给执行器; - 结果返回:执行器将记录通过连接器返回给客户端,查询流程结束。
3. 一条更新语句的生命历程:事务与日志的协同
与查询语句不同,更新语句(如UPDATE user SET name = 'zhangsan' WHERE id = 1;)涉及数据修改,需通过事务日志保证一致性,其执行流程更复杂(原文配图参考):
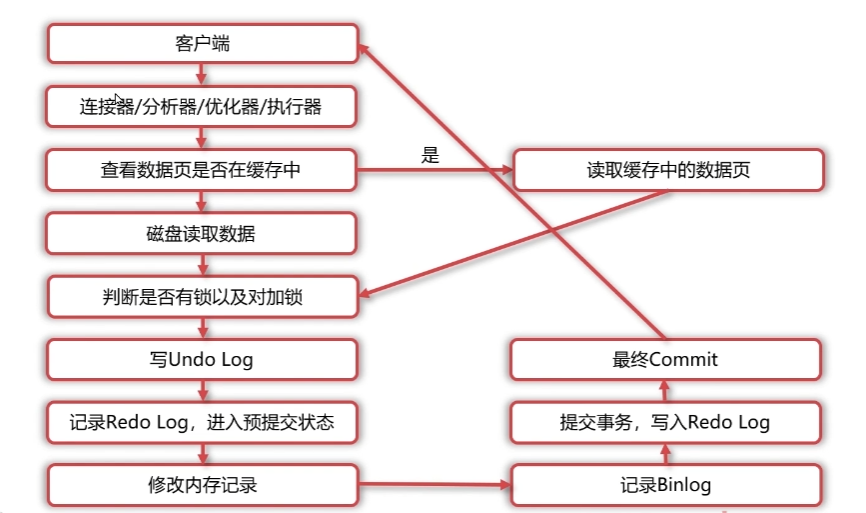
步骤1-4:连接、分析、优化(与查询语句一致)
- 连接器建立连接并校验权限;
- 分析器生成“更新
user表id=1记录的name字段”的解析树; - 优化器选择“通过主键索引定位
id=1记录”的执行计划; - 执行器校验用户对
user表的UPDATE权限。
步骤5:存储引擎层的核心操作(事务与日志)
这是更新语句的核心环节,InnoDB通过多日志协同保证事务安全,步骤如下:
-
数据页加载与锁控制:
- 检查
id=1对应的“数据页”是否在内存缓存中:若在则直接读取,若不在则从磁盘加载到内存; - 对
id=1的记录加行级锁,防止其他事务同时修改该记录(保证隔离性)。
- 检查
-
写入Undo Log:
- 记录“
id=1的name原 value”(如原name='lisi'),用于事务回滚(若后续执行ROLLBACK,可通过Undo Log恢复数据)。
- 记录“
-
写入Redo Log(预提交状态):
- 记录“
id=1的name更新为zhangsan”的操作日志,标记为“预提交”(Prepare)状态; - Redo Log是物理日志,存储在磁盘中,即使MySQL崩溃,重启后可通过Redo Log恢复未完成的操作(保证持久性)。
- 记录“
-
修改内存数据:
- 直接在内存缓存中修改
id=1记录的name字段为zhangsan(此处会用到change buffer:若修改的是非唯一索引数据,先缓存到change buffer,后续批量刷盘,减少磁盘IO)。
- 直接在内存缓存中修改
-
写入Binlog:
- 记录“
UPDATE user SET name = 'zhangsan' WHERE id = 1;”的SQL逻辑日志; - Binlog是逻辑日志,主要用于数据备份、主从复制(主库将Binlog同步到从库,从库执行Binlog实现数据一致性)。
- 记录“
-
事务提交(Commit):
- 将Redo Log的状态从“预提交”改为“提交”(Commit);
- 释放
id=1记录的行级锁; - 执行器收到存储引擎的“更新完成”通知,通过连接器返回“更新成功”给客户端,更新流程结束。
4. 总结:MySQL执行逻辑的核心要点
- 分层架构是基础:Server层提供统一的SQL处理能力(连接、解析、优化),存储引擎层负责数据存储与事务控制,二者解耦提升灵活性;
- 查询缓存需慎用:MySQL 8.0后已移除,8.0前因高并发瓶颈不建议开启;
- 权限校验分两次:连接器校验登录权限,执行器校验表级操作权限,双重保障数据安全;
- 更新语句靠日志:Undo Log(回滚)、Redo Log(崩溃恢复)、Binlog(备份/复制)协同工作,是事务ACID特性的核心保障。
理解MySQL的体系结构与SQL执行流程,不仅能帮助我们写出更高效的SQL,更能在性能优化、故障排查(如慢查询、事务死锁)时快速定位问题根源。后续可进一步深入InnoDB的锁机制、事务隔离级别等细节,逐步构建完整的MySQL知识体系。