在树莓派4B上部署ONNX格式的YOLOv8-Pose
前言
最近在将yolov8 pose模型部署到芯片架构为ARM64的树莓派上时,发现在同一张图片上进行推理,如果使用Pytorch格式的模型在100次测试后得到平均每次耗时1175毫秒,而如果使用ONNX格式的相同模型在100次测试后得到的平均每次耗时则为574毫秒。在主要人体目标和关节点识别效果几乎相同的情况下,两者之间的推理耗时,ONNX格式的模型推理在速度上具有明显的提升。
在ONNX官方文档中介绍到,ONNX可以被看作一种专门的用于描述数学函数的编程语言,定义了机器学习模型在推理过程中所需要的所有操作。并且,ONNX的目标是为所有机器学习框架提供一种通用的语言,用来描述模型。通过ONNX可以简化模型在生产环境中的部署,只要有一个ONNX的解释器,模型就可以在目标环境中执行模型,而不需要依赖原始训练框架(如PyTorch或TensofFlow)。由于ONNX的这种特性,ONNX格式的模型在跨平台实现中应用广泛。


深度学习框架
在深度学习领域,PyTorch和TensorFlow是目前最主流的两大框架。其中,PyTorch由FaceBook(现Meta)人工智能研究院于2016年推出,采用Python作为主要开发语言。PyTorch的应用在科研领域非常常见,尤其是在高校科研与学术研究,以及教学当中十分常见。而TensorFlow由Google在2015年开源。
用于部署的深度学习模块格式
由于科研机构普遍采用PyTorch进行深度学习研究,相关的论文的开源实现通常以PyTorch代码配合.pt或.pth格式的模型文件发布。这些资源可通过GitHub等平台便捷的获取到,使得PyTorch模型成为公众最容易接触到的模型参数形式之一。但需要注意,这类模型权重文件须依赖PyTorch环境才能加载和使用,并非跨框架的通用模型格式。
为了解决这个问题,最便捷的方式是将模型转化成另一种在不同的框架和硬件上被正确解析和运行格式。如果同样将PyTorch环境部署到其他平台,一些依赖库可能需要手动编译并安装,极大可能遇到由于依赖库实现而无法直接解决的问题。并且响应慢问题和占用大量的内存问题,使得PyTorch环境不适合部署到一些平台上。
在PyTorch官网页面选择对应的平台,获取对应的PyTorch环境安装命令。
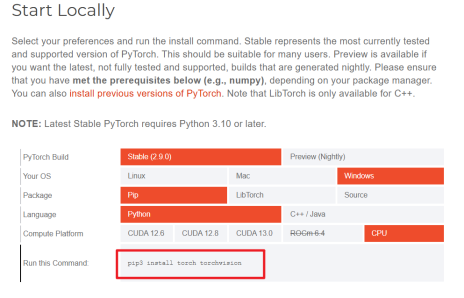
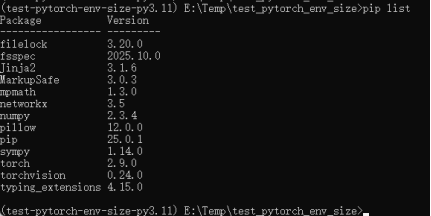

与PyTorch环境占用空间大小对比,测试安装ONNX格式模型的执行引擎和环境:ONNX Runtime。
命令:pip install onnxruntime
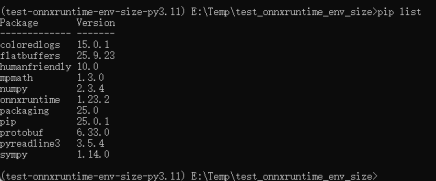
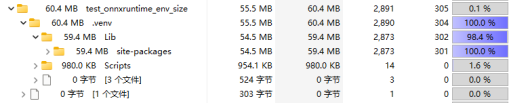
从图五和图七可知,onnxruntime的CPU版本安装后依赖所占用的存储空间大小只有PyTorch的1/10。
言归正传,主流跨平台模型格式有ONNX、TensorFlow Lite、PyTorch Mobile/TorchScript、Core ML、TensorRT和TFLite Micro。其中,ONNX是将训练框架下得到的模型参数部署的最佳格式。部署到iOS或macOS应用使用Core ML可以最大化利用Apple硬件。部署到Android或其他移动设备广泛使用TensorFlow Lite。在NVIDIA GPU上最大程度释放性能使用TensorRT。部署到资源受限的微控制器TFLite Micro是唯一选择。
其中,将模型转换成ONNX格式后,即可将模型用任何适合生产的语言开发,例如C、Jave、Python、Javescript、C#、WebAssembly、ARM等。
使用ONNX格式模型的部署流程
经过上述的了解后,首先将下载的PyTorch模型文件转换成ONNX格式的模型文件。
步骤一 导出ONNX格式的模型
from ultralytics import YOLOmodel = YOLO('yolov8n-pose.pt') # 当前文件夹不存在模型文件yolov8n-pose.pt就会下载
model.export(format='onnx', imgsz=(640, 640), opset=12)
在上述代码片段一中需要关键注意的API是YOLO.export,在ONNX官网表格中可知各个参数的含义和作用。此API常用的重要参数分别有format、imgsz、half和opset,其中format是必选参数表明导出模型的格式;imgsz定义导出模型期望的输入图片尺寸;half是量化选项,用于将模型精度从32位浮点数(FP32)转换成16位浮点数(FP16);opset只在导出ONNX格式模型时有效,表明导出模型的算子集版本。
以下简要介绍算子集。由ONNX官网介绍,算子是表示模型的基础单元。包括:
ai.onnx(主域)基础算子
·数学运算:Add, Sub, MatMul, Transpose
·逻辑比较:Greater, IsNaN
·形状操作:Shape, Reshape
·聚合归约:ReduceSum, ReduceMin
·CNN层:Conv, MaxPool
·RNN层:RNN, Dropout
·激活层:Relu, Softmax
ai.onnx.ml(机器学习扩展域)包括传统ML算子
·树模型:TreeEnsembleRegressor
·预处理:OneHotEncoder, LabelEncoder
·SVM:SVMRegressor
·缺失值填充:Imputer
使用工具Netron可视化神经网络模型,可以直观展示模型算子之间的连接关系、张量(“多维数组”)流动路径以及每个算子的详细属性。
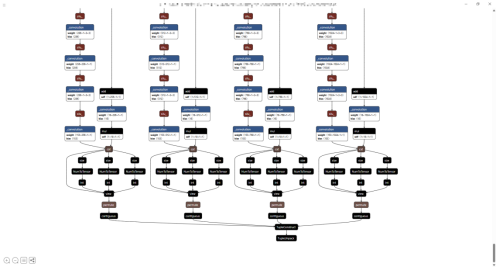
步骤二 使用ONNX格式的模型推理(完整代码)
# -------------------------------------------------------------------------------
# 版权所有 (C) [2025] [noedn/无]。保留所有权利。
#
# 本代码由豆包编程助手生成,并根据用户的需求进行了修改和优化。
#
# 许可证:你可以自由使用、复制、修改和分发此代码,
# 前提是在所有副本或衍生作品中保留此版权声明和许可证信息。
#
# 免责声明:本代码仅供参考和学习使用,不提供任何明示或暗示的保证,
# 包括但不限于适销性、特定用途适用性或非侵权性。使用此代码所产生的任何后果,
# 由使用者自行承担全部责任。
# -------------------------------------------------------------------------------import cv2
import numpy as np
import onnxruntime as ort
import pandas as pd
import tkinter as tk# -------------------------- 配置参数 --------------------------
ONNX_MODEL_PATH = 'yolov8n-pose.onnx'
IMG_PATH = r'onnx_test\teacher.jpg'
# IMG_PATH = r'onnx_test\teacher.png'
# IMG_PATH = r'onnx_test\teacher1.png'INPUT_SIZE = (640, 640) # 模型输入尺寸
CONF_THRESH = 0.5 # 目标检测置信度阈值
IOU_THRESH = 0.45 # NMS IoU 阈值
KPT_CONF_THRESH = 0.3 # 关键点置信度阈值# 绘图颜色和样式
BOX_COLOR = (0, 255, 0) # BGR: 绿色
BOX_THICKNESS = 2
KPT_COLOR = (255, 0, 0) # BGR: 蓝色
KPT_RADIUS = 3
LINE_COLOR = (0, 0, 255) # BGR: 红色
LINE_THICKNESS = 2# 关键点连接关系(17个关键点)
KPT_CONNECTIONS = [(0, 1), (0, 2), (1, 3), (2, 4), (5, 6), (5, 7), (7, 9), (6, 8), (8, 10),(11, 12), (11, 13), (13, 15), (12, 14), (14, 16), (5, 11), (6, 12)
]# -------------------------- 预处理:调整图像大小并添加灰/黑边 --------------------------
def preprocess_image(img, input_size):h, w = img.shape[:2]input_w, input_h = input_size# 计算缩放比例(保持纵横比)scale = min(input_w / w, input_h / h)new_w = int(w * scale)new_h = int(h * scale)# 缩放图像print(f"缩放前图像尺寸: {w}x{h}, 缩放比例: {scale:.4f}, 缩放后尺寸: {new_w}x{new_h}")resized = cv2.resize(img, (new_w, new_h), interpolation=cv2.INTER_LINEAR)print(f"缩放后图像尺寸: {resized.shape[:2]}")# 创建灰/黑边画布padded = np.full((input_h, input_w, 3), 0, dtype=np.uint8)pad_x = (input_w - new_w) // 2pad_y = (input_h - new_h) // 2padded[pad_y:pad_y+new_h, pad_x:pad_x+new_w] = resized# 归一化并调整维度 (HWC -> CHW -> NCHW)input_img = padded.astype(np.float32) / 255.0input_img = input_img.transpose(2, 0, 1) # HWC -> CHWinput_img = np.expand_dims(input_img, axis=0) # CHW -> NCHWreturn input_img, (h, w, scale, pad_x, pad_y)# -------------------------- NMS 后处理 --------------------------
def non_max_suppression(boxes, scores, iou_thresh):if len(boxes) == 0:return []order = scores.argsort()[::-1]keep = []while len(order) > 0:i = order[0]keep.append(i)if len(order) == 1:breakious = compute_iou(boxes[i], boxes[order[1:]])order = order[1:][ious < iou_thresh]return keepdef compute_iou(box, boxes):x1, y1, x2, y2 = boxx1s, y1s, x2s, y2s = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]inter_x1 = np.maximum(x1, x1s)inter_y1 = np.maximum(y1, y1s)inter_x2 = np.minimum(x2, x2s)inter_y2 = np.minimum(y2, y2s)inter_area = np.maximum(0, inter_x2 - inter_x1) * np.maximum(0, inter_y2 - inter_y1)area = (x2 - x1) * (y2 - y1)area_others = (x2s - x1s) * (y2s - y1s)union_area = area + area_others - inter_areareturn inter_area / (union_area + 1e-6)# -------------------------- 解析 ONNX 模型输出 --------------------------
def parse_output(output, orig_shape, scale, pad_x, pad_y):# 1. 提取正确的输出数组(移除batch维度)if not isinstance(output, list) or len(output) != 1:raise ValueError(f"Expected a single numpy array in the output list, but got {type(output)} with length {len(output)}.")output_array = output[0] # 原始输出:(1, 56, 8400)output_array = output_array[0] # 去除batch维度:(56, 8400)output_array = output_array.transpose(1, 0) # 最终正确维度:(8400, 56)print("修正后输出维度:", output_array.shape) # 应打印 (8400, 56)orig_h, orig_w = orig_shape# 2. 拆分输出数据(原始格式,可能含科学计数法)xywh_raw = output_array[:, :4] # 原始中心坐标+宽高conf_raw = output_array[:, 4] # 原始置信度kpts_flat_raw = output_array[:, 5:] # 原始关键点数据# 关键修改:对所有数据进行数值转换(处理科学计数法)# 转换xywh(4列数据)xywh = np.array([pd.to_numeric(col, errors="coerce") for col in xywh_raw.T]).T# 转换置信度(1列数据)conf = pd.to_numeric(conf_raw.tolist(), errors="coerce")# 转换关键点(51列数据:17个关键点×3个属性)kpts_flat = np.array([pd.to_numeric(col, errors="coerce") for col in kpts_flat_raw.T]).Tprint("conf前3个数据:", sorted(conf, reverse=True)[:3])# 3. 坐标计算(使用转换后的xywh)x_center = xywh[:, 0] y_center = xywh[:, 1] width = xywh[:, 2] height = xywh[:, 3]x1 = x_center - width / 2y1 = y_center - height / 2x2 = x_center + width / 2y2 = y_center + height / 2boxes = np.stack([x1, y1, x2, y2], axis=-1) # (N, 4)# 处理关键点kpts = kpts_flat.reshape(-1, 17, 3) # (N, 17, 3) -> (x, y, conf)# 过滤低置信度(使用转换后的conf)mask = conf > CONF_THRESH # 假设CONF_THRESH已定义boxes = boxes[mask]conf = conf[mask]kpts = kpts[mask]print("目标框前3个数据:", boxes[:3])if len(boxes) == 0:return [], []# 移除填充偏移、映射回原始尺寸、限制范围boxes -= [pad_x, pad_y, pad_x, pad_y]kpts[:, :, :2] -= [pad_x, pad_y]boxes /= scalekpts[:, :, :2] /= scaleboxes = np.clip(boxes, 0, [orig_w, orig_h, orig_w, orig_h]).astype(int)kpts[:, :, :2] = np.clip(kpts[:, :, :2], 0, [orig_w, orig_h]).astype(int)# NMS(使用转换后的conf)keep_indices = non_max_suppression(boxes, conf, IOU_THRESH) # 假设IOU_THRESH和non_max_suppression已定义boxes = [boxes[i] for i in keep_indices]kpts = [kpts[i] for i in keep_indices]return boxes, kpts# -------------------------- 新增:绘制关节点函数 --------------------------
def draw_keypoints(frame, boxes, keypoints):"""在图像上绘制姿态关键点和连接"""# 关键点连接规则(YOLOv8姿态估计的17个关键点索引,对应人体部位)skeleton = [(0, 1), (0, 2), (1, 3), (2, 4), # 头部:鼻子-左眼、鼻子-右眼、左眼-左耳、右眼-右耳(0, 5), (0, 6), (5, 7), (7, 9), # 左上肢:鼻子-左肩、左肩-左肘、左肘-左手腕(6, 8), (8, 10), # 右上肢:鼻子-右肩、右肩-右肘、右肘-右手腕(5, 11), (6, 12), (11, 12), # 躯干:左肩-左髋、右肩-右髋、左髋-右髋(11, 13), (13, 15), # 左下肢:左髋-左膝、左膝-左脚踝(12, 14), (14, 16) # 右下肢:右髋-右膝、右膝-右脚踝]# 颜色定义(BGR格式,OpenCV默认用BGR)keypoint_color = (0, 255, 0) # 绿色:关键点(填充圆)skeleton_color = (255, 0, 0) # 蓝色:骨架连接(线条)bbox_color = (0, 0, 255) # 红色:目标边界框text_color = (0, 0, 255) # 红色:置信度文字# 遍历每个检测到的人体for i in range(len(boxes)):# 1. 绘制目标边界框和置信度x1, y1, x2, y2 = boxes[i]# 绘制矩形边界框(厚度2)cv2.rectangle(frame, (x1, y1), (x2, y2), bbox_color, 2)# 2. 绘制关键点和骨架kpt = keypoints[i]points = [] # 存储单个人的有效关键点((x,y)或None)# 遍历17个关键点,过滤低置信度(<0.5)的点for j in range(17):x, y, conf = kpt[j] # 解析单个关键点的x、y、置信度if conf > 0.5:# 置信度足够,转换为整数坐标存入列表points.append((int(x), int(y)))else:# 置信度不足,用None标记(后续跳过)points.append(None)# 3. 绘制关键点(只处理非None的有效点)for point in points:if point is not None: # 关键修复:跳过None值,避免解包错误x, y = point# 绘制填充圆(半径5,厚度-1表示填充)cv2.circle(frame, (x, y), 5, keypoint_color, -1)# 4. 绘制骨架连接(只连接两个都有效的关键点)for (start_idx, end_idx) in skeleton:# 先判断索引是否在有效范围内(避免越界)if 0 <= start_idx < len(points) and 0 <= end_idx < len(points):start_point = points[start_idx]end_point = points[end_idx]# 只有两个点都有效时才绘制线条if start_point is not None and end_point is not None:cv2.line(frame, start_point, end_point, skeleton_color, 2)return frame# -------------------------- 主函数 --------------------------
def main():try:# 1. 加载 ONNX 模型session = ort.InferenceSession(ONNX_MODEL_PATH)input_name = session.get_inputs()[0].nameprint(f"✅ 模型加载成功!输入节点名: {input_name}")# 2. 读取图像raw_img = cv2.imread(IMG_PATH)if raw_img is None:raise FileNotFoundError(f"❌ 无法读取图像: {IMG_PATH}")orig_h, orig_w = raw_img.shape[:2]print(f"✅ 图像读取成功!尺寸: {orig_w}x{orig_h}")# 3. 预处理input_img, (h, w, scale, pad_x, pad_y) = preprocess_image(raw_img, INPUT_SIZE)print(f"✅ 预处理完成!缩放比例: {scale:.2f}")# 4. 推理print("🔍 正在推理...")output = session.run(None, {input_name: input_img})print(f"✅ 推理完成!输出形状: {output[0].shape}")# -------------------------- 新增:将output保存为表格 --------------------------print("📊 正在保存输出为表格...")# 1. 处理输出维度:(1, 56, 8400) → (8400, 56)output_array = output[0] # 原始输出:(1, 56, 8400)output_2d = output_array[0].transpose(1, 0) # 去除批次+转置:(8400, 56)# 2. 给表格列命名(明确每列含义)columns = []# 2.1 前4列:边界框坐标(xywh)columns.extend(["box_x_center", "box_y_center", "box_width", "box_height"])# 2.2 第5列:目标置信度columns.append("confidence")# 2.3 第6-56列:17个关键点(每个关键点含x、y、conf)for i in range(17):columns.extend([f"kpt_{i}_x", f"kpt_{i}_y", f"kpt_{i}_conf"])# 3. 创建DataFrame并保存df = pd.DataFrame(output_2d, columns=columns)# 保存为CSVcsv_path = "yolov8_pose_output.csv"df.to_csv(csv_path, index=False, encoding="utf-8")print(f"✅ 表格已保存:")print(f" - CSV文件:{csv_path}")# 5. 后处理boxes, keypoints = parse_output(output, (orig_h, orig_w), scale, pad_x, pad_y)print(f"✅ 检测到 {len(boxes)} 个目标")# 6. 绘制结果(使用新的draw_keypoints函数)result_img = raw_img.copy()result_img = draw_keypoints(result_img, boxes, keypoints)# 7. 显示和保存# 获取屏幕分辨率(需先创建一个临时窗口获取)root = tk.Tk()root.withdraw() # 隐藏主窗口screen_width = root.winfo_screenwidth()screen_height = root.winfo_screenheight()root.destroy()print(f"✅ 屏幕分辨率: {screen_width}x{screen_height}")# 计算最大允许尺寸(屏幕的3/4)max_width = int(screen_width * 0.5)max_height = int(screen_height * 0.5)# 获取图像原始尺寸h, w = result_img.shape[:2]# 计算调整比例(保持原图比例)scale = min(max_width / w, max_height / h)new_width = int(w * scale)new_height = int(h * scale)# 调整图像大小resized_img = cv2.resize(result_img, (new_width, new_height), interpolation=cv2.INTER_AREA)print(f"✅ 调整后的图像尺寸: {new_width}x{new_height}")print(f"✅ 调整尺寸: {resized_img.shape[:2]}")# 显示调整后的图像cv2.namedWindow('YOLOv8 Pose (ONNX Runtime)', cv2.WINDOW_NORMAL)cv2.imshow('YOLOv8 Pose (ONNX Runtime)', resized_img)cv2.waitKey(0)cv2.destroyAllWindows()cv2.imwrite('yolov8_pose_manual_result.jpg', result_img)print("✅ 结果已保存: yolov8_pose_manual_result.jpg")except Exception as e:print(f"❌ 错误: {str(e)}")if __name__ == "__main__":main()
总结
将PyTorch的.pt模型转为ONNX,解决了嵌入式设备框架依赖与资源限制(无GPU)问题。经过实验测试,将yolov8n-pose.pt模型导出为ONNX格式的模型文件,并部署在ARM64的树莓派开发板上,测试确认ONNX可以在安装更少的依赖库的同时,相较于作为模型训练成果的PyTorch模型文件在推理效果几乎相同的情况下具有更快的推理速度。
注意
在将原生pytorch格式的模型转为onnx格式后,可能出现onnx格式模型输出的结果完全错误的问题。关键问题在于onnx格式的模型推理output = session.run(None, {input_name: input_img})输出的数据有按照科学计数法,如0.231*10^-2这种输出数据。如果直接使用输出的数据将会导致所有数值都为0的情况。
为了解决onnx格式模型推理输出数据格式问题,需要使用pandas库来对数据进行清洗,如代码当中函数parse_output中的代码段pd.to_numeric支持将特殊的数据格式转换成正常的数值类型。然后继续使用经过清洗得到的正常数据进行图片处理即可。
此问题可以在代码debug调试过程中发现,代码中也增加了将模型推理结果保存csv表格的实现,可以通过表格直观的查看模型推理输出,确认输出内容是否正确。
应用展望
由于ONNX格式的模型可以广泛应用于各种平台,可以很简单的想到此实现个人可以很简单的应用到一些场景:
游戏辅助
步骤1:使用ffmpeg等工具获取当前屏幕界面画面
步骤2:识别人头或者人身位置
步骤3:使用python库PyAutoGUI获取和控制鼠标
完成以上步骤基本上即可获取自己实现的游戏辅助工具。
无感AR智能家居
步骤1:使用Tof相机或者双目相机获取人体画面
步骤2:识别人眼和人手,结合Tof相机或双目相机获取距离
步骤3:使用手势模型获取手势,并通过手和眼的位置信息,通过透视变换获取到需要控制的目标(灯、电视、空调等等)[以气驭剑]
步骤4:通过预设手势触发相应的电器功能,从而实现无感AR的家电控制。