F046 新闻推荐可视化大数据系统vue3+flask+neo4j
文章结尾部分有CSDN官方提供的学长 联系方式名片
关注B站,有好处!
编号: F046
视频
视频链接
1 系统简介
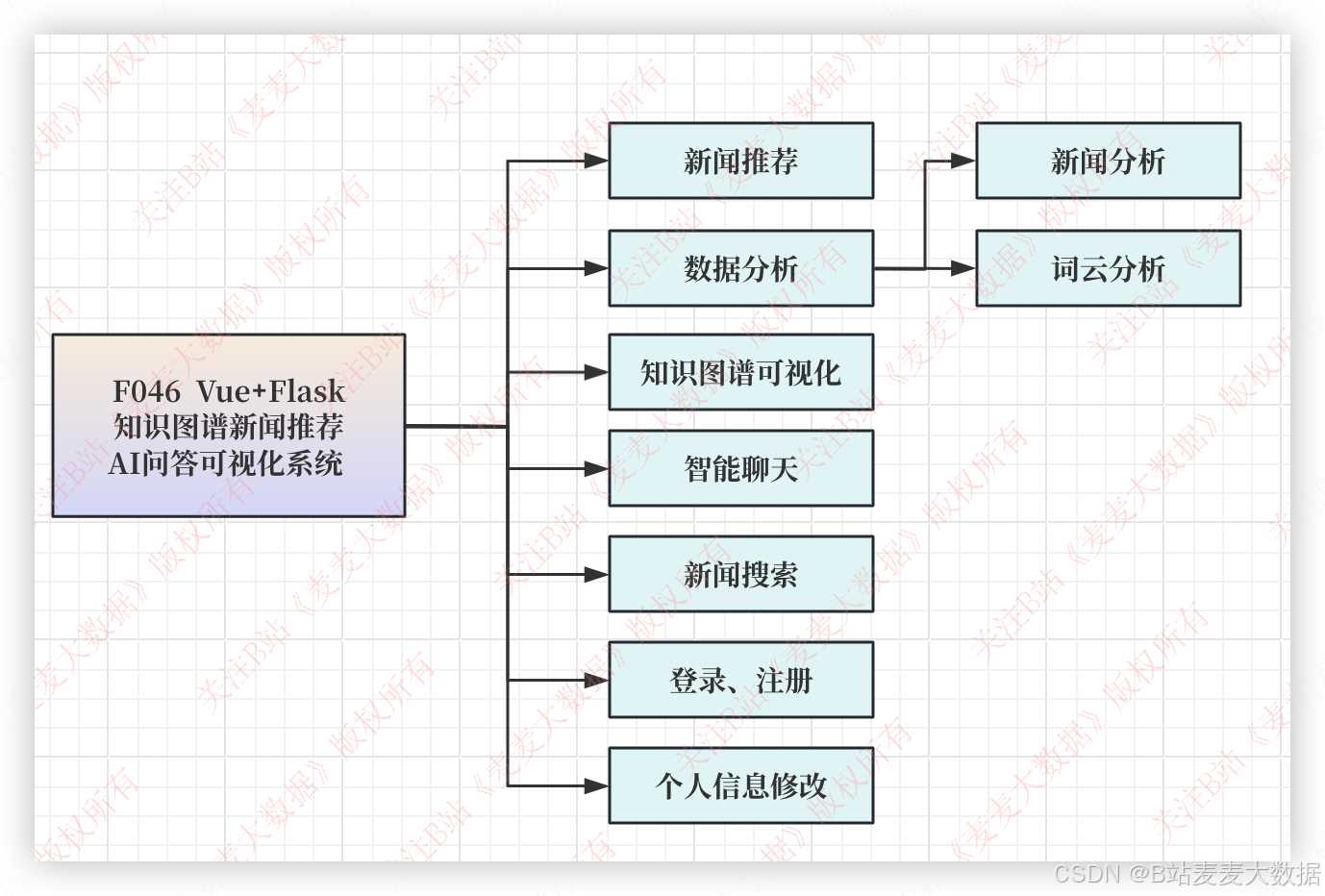
系统简介:本系统是一个基于Vue3和Flask构建的新闻推荐、可视化与问答系统。其核心功能围绕新闻数据的展示、推荐、分析和用户交互展开。主要包括以下模块:
登录与注册:提供用户身份验证功能,支持切换登录注册界面,采用视频背景增强用户体验。
新闻推荐:基于用户兴趣推荐相关新闻,主页布局包含菜单、操作面板和用户交互区域。
数据分析:对新闻数据进行统计分析,生成可视化图表。
知识图谱构造:通过爬取新闻数据,构建知识图谱并存储到Neo4j数据库中。
知识图谱可视化:展示知识网络结构,直观呈现新闻数据关联。
智能聊天:提供自然语言交互的问答服务。
新闻搜索:支持关键词搜索新闻内容。
个人设置:包含用户信息修改和密码更改功能,支持个性化头像设置。
2 功能设计
该系统采用B/S架构模式,前端使用Vue3框架,结合其生态系统中的Pinia(状态管理)、Vue Router(路由导航)和Echarts(数据可视化)等组件构建用户界面。前端通过RESTful API与Flask后端交互,Flask后端负责业务逻辑处理,并使用SQLAlchemy等ORM工具与MySQL数据库进行数据持久化,同时整合Neo4j图数据库存储知识图谱数据。系统还包含独立的爬虫模块,用于抓取新闻数据并导入数据库,为推荐和分析提供数据支撑。
2.1系统架构图
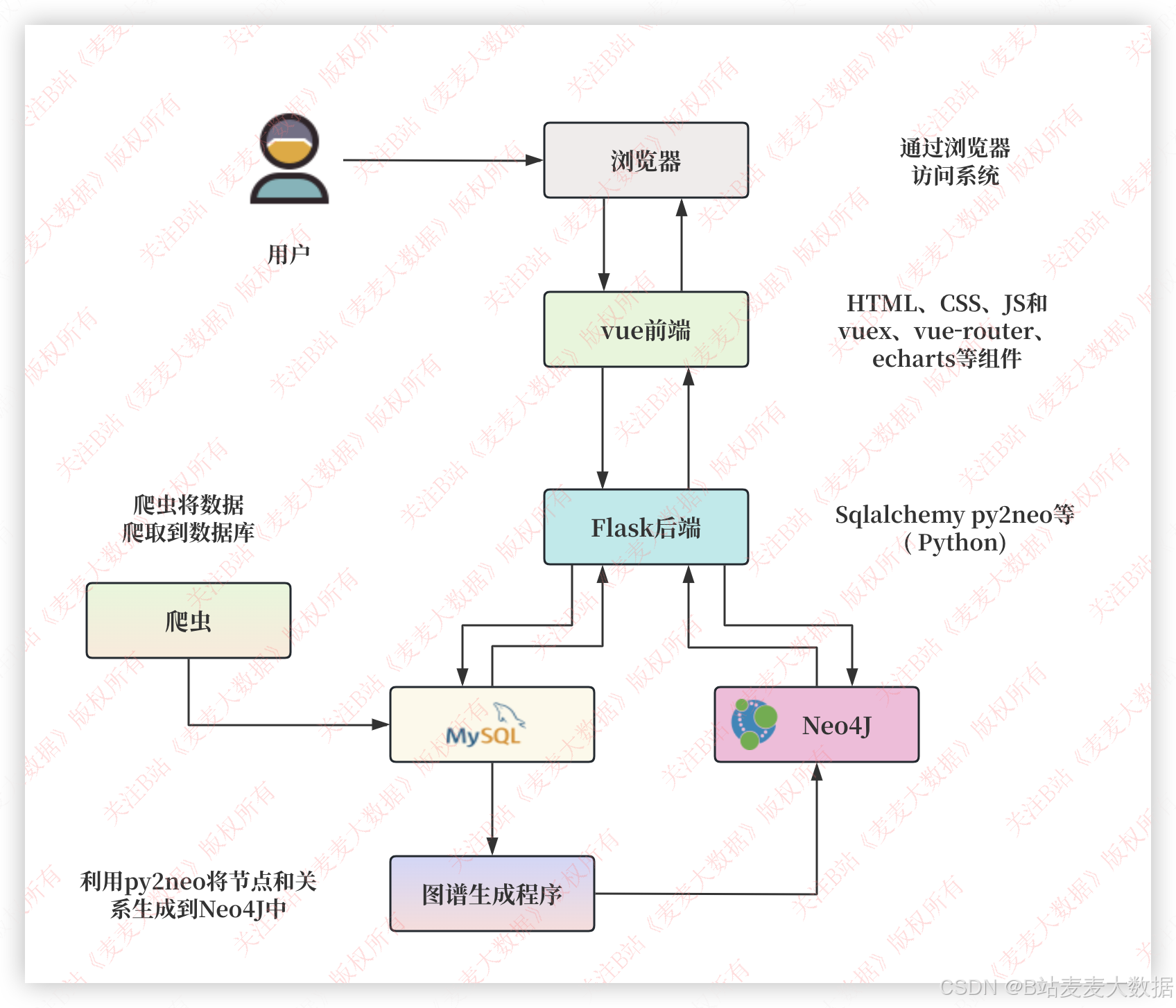
2.2 功能模块图
3 功能展示
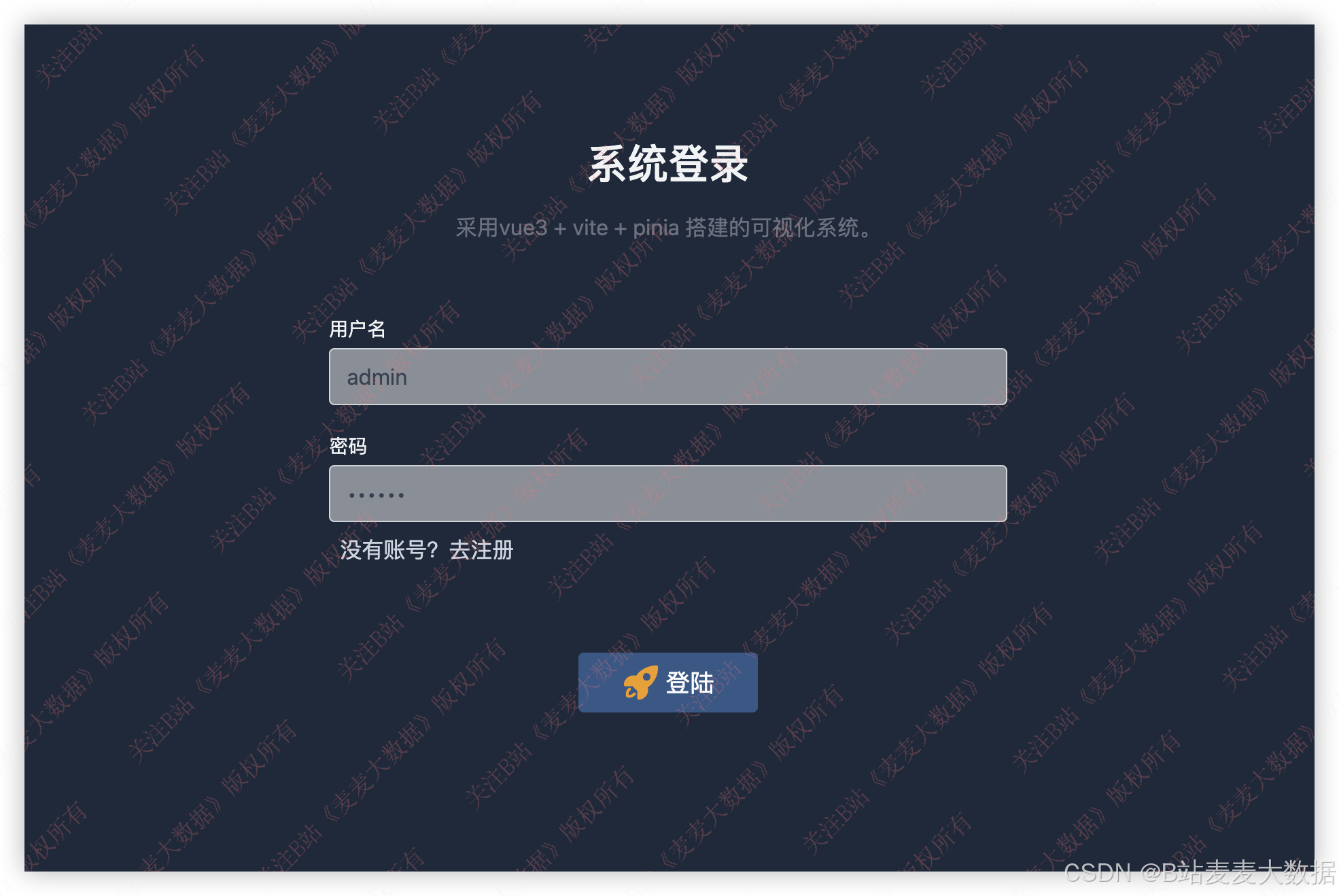
3.1 登录 & 注册
登录需要验证用户名和密码是否正确,如果不正确会有错误提示。
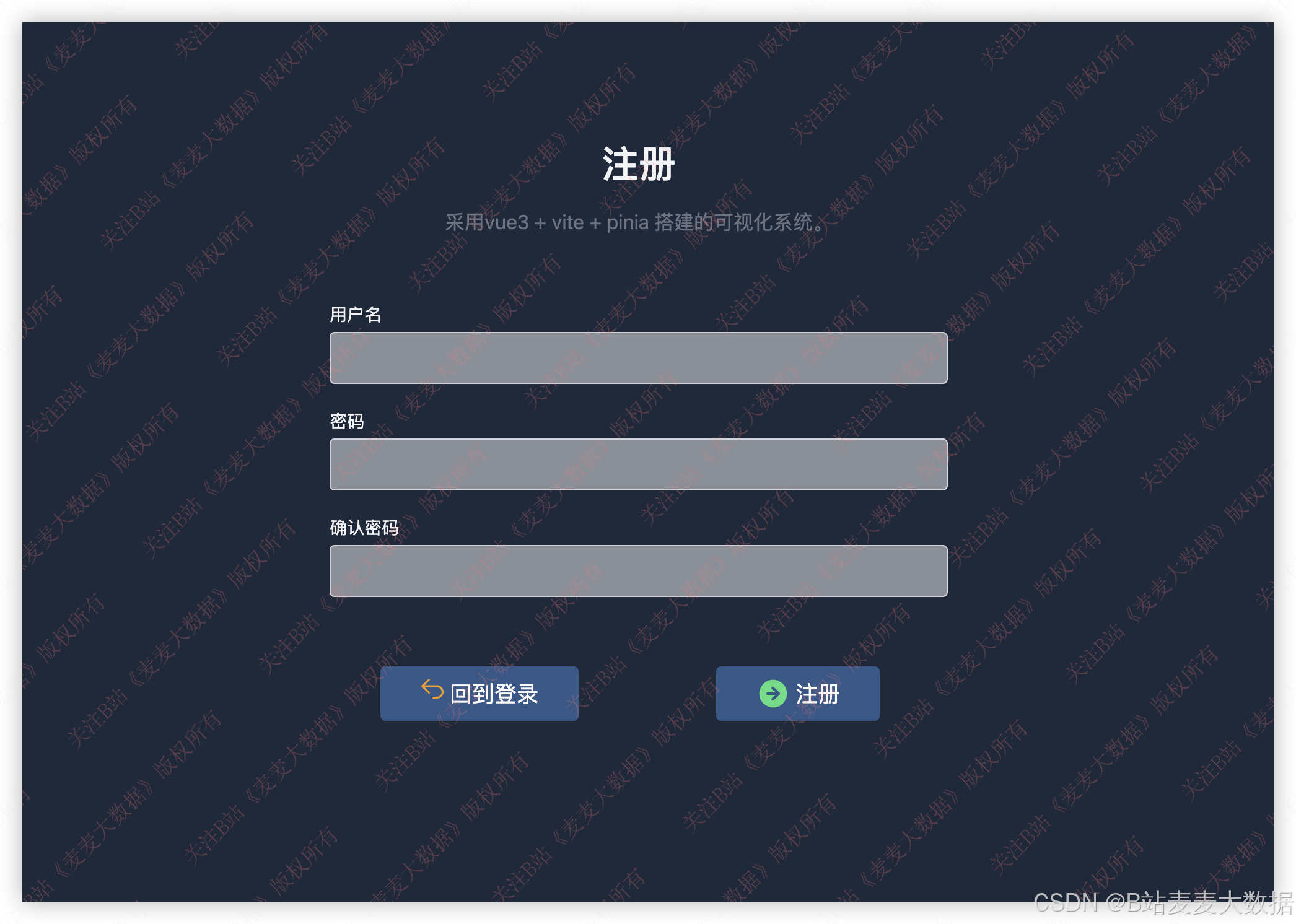
注册需要验证用户名是否存在,如果错误会有提示。
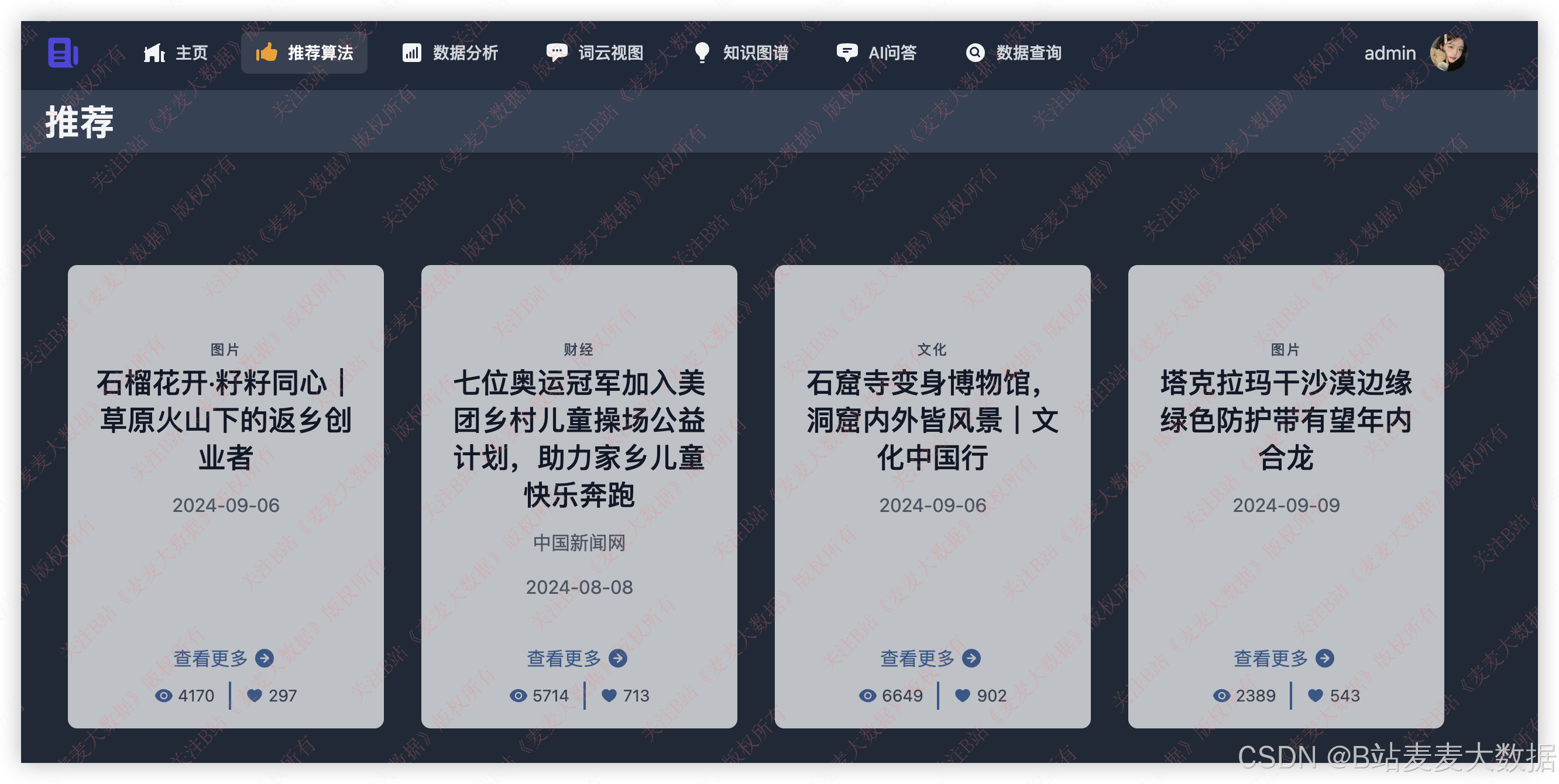
3.2 新闻推荐 (2种推荐算法)
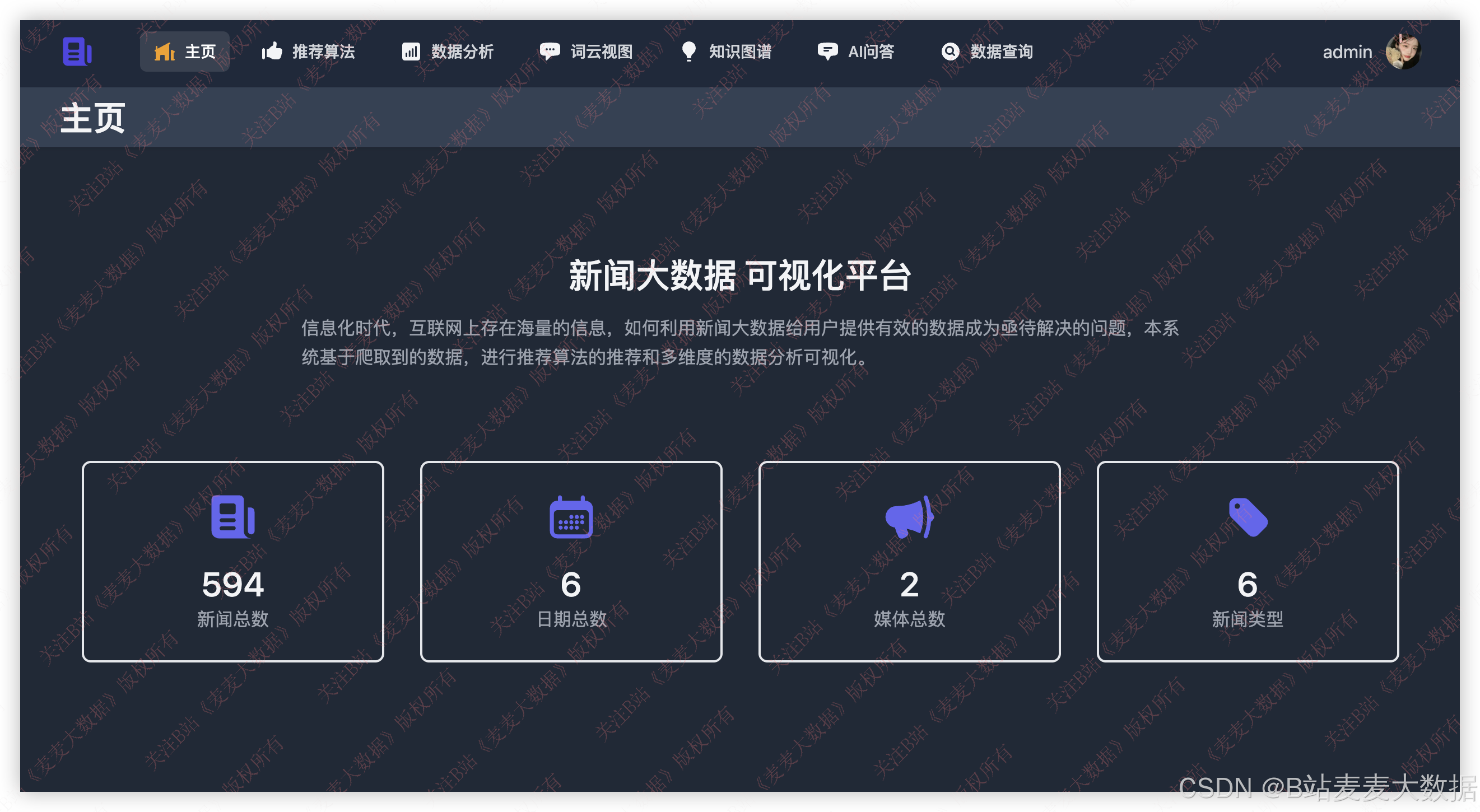
主页的布局采用了上侧是菜单,下侧是操作面板的布局方法,右侧的上方还有用户的头像和退出按钮,如果是新注册用户,没有头像,这边则不显示,需要在个人设置中上传了头像之后就会显示。
主页布局:
希望推荐就是根据用户兴趣点推荐相关新闻:
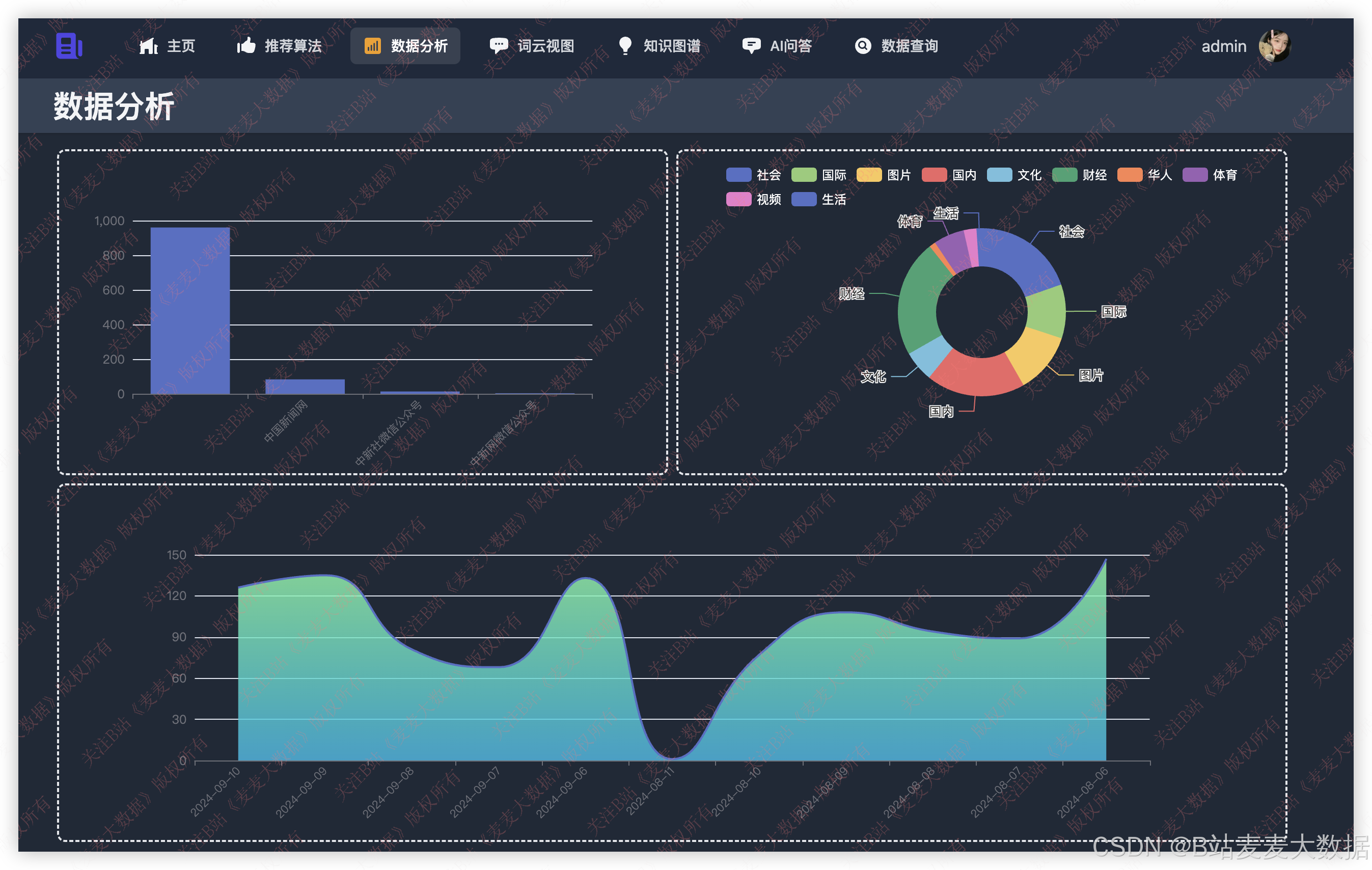
3.3 数据分析
对新闻数据进行统计分析
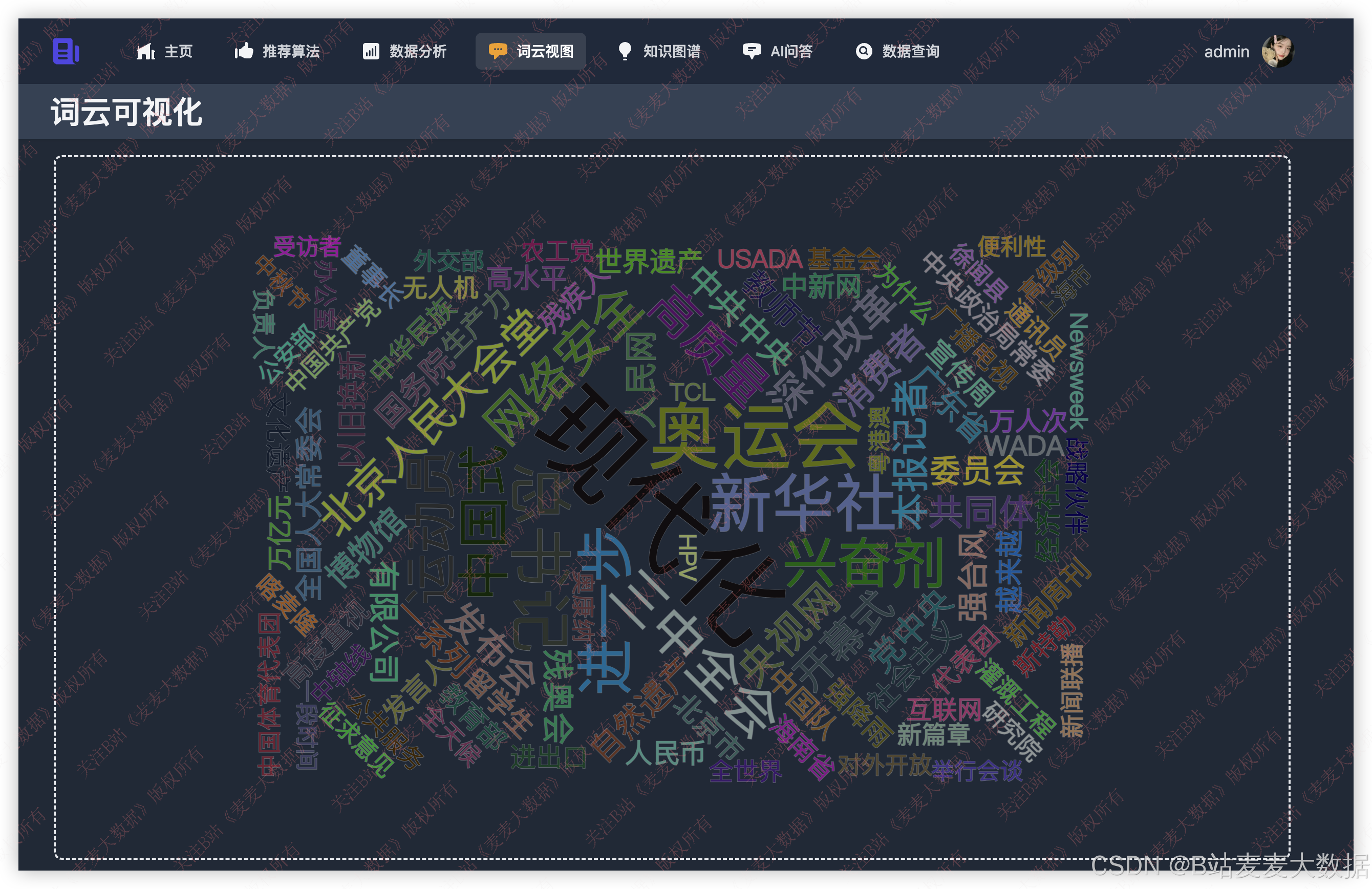
词云分析:
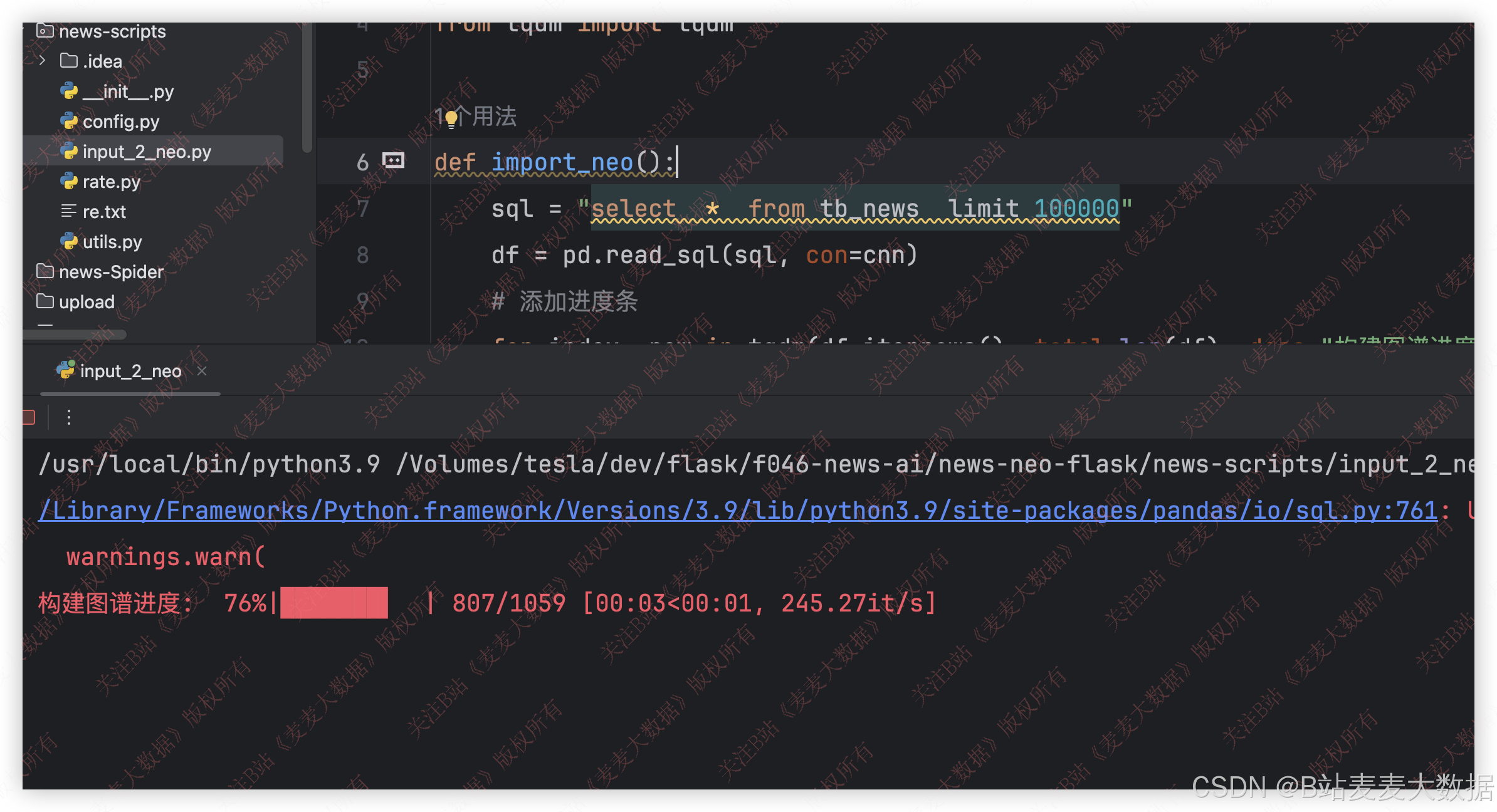
3.4 知识图谱构造
通过代码对爬取到的新闻创建知识图谱导入到neo4j:
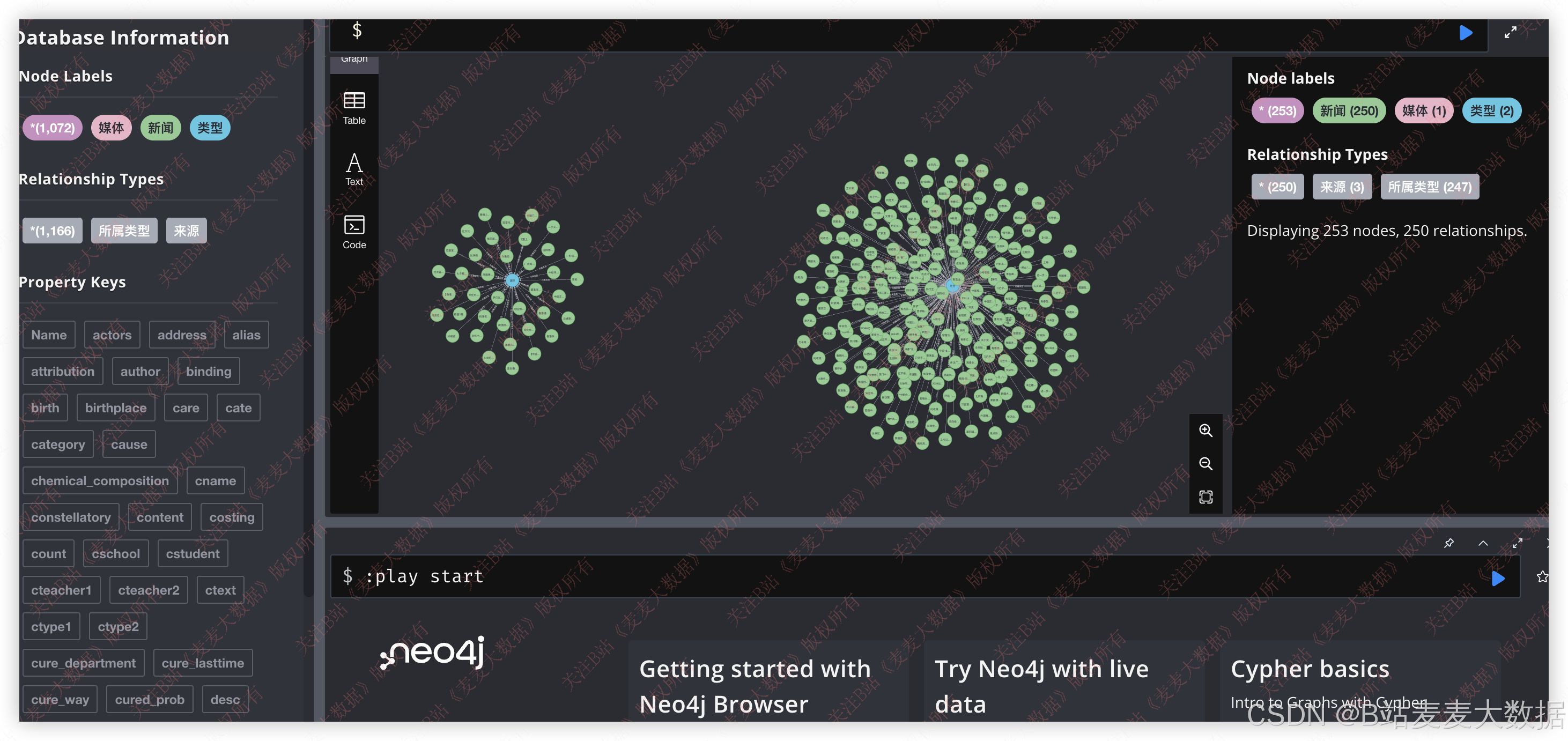
3.5 知识图谱可视化
展示知识网络结构

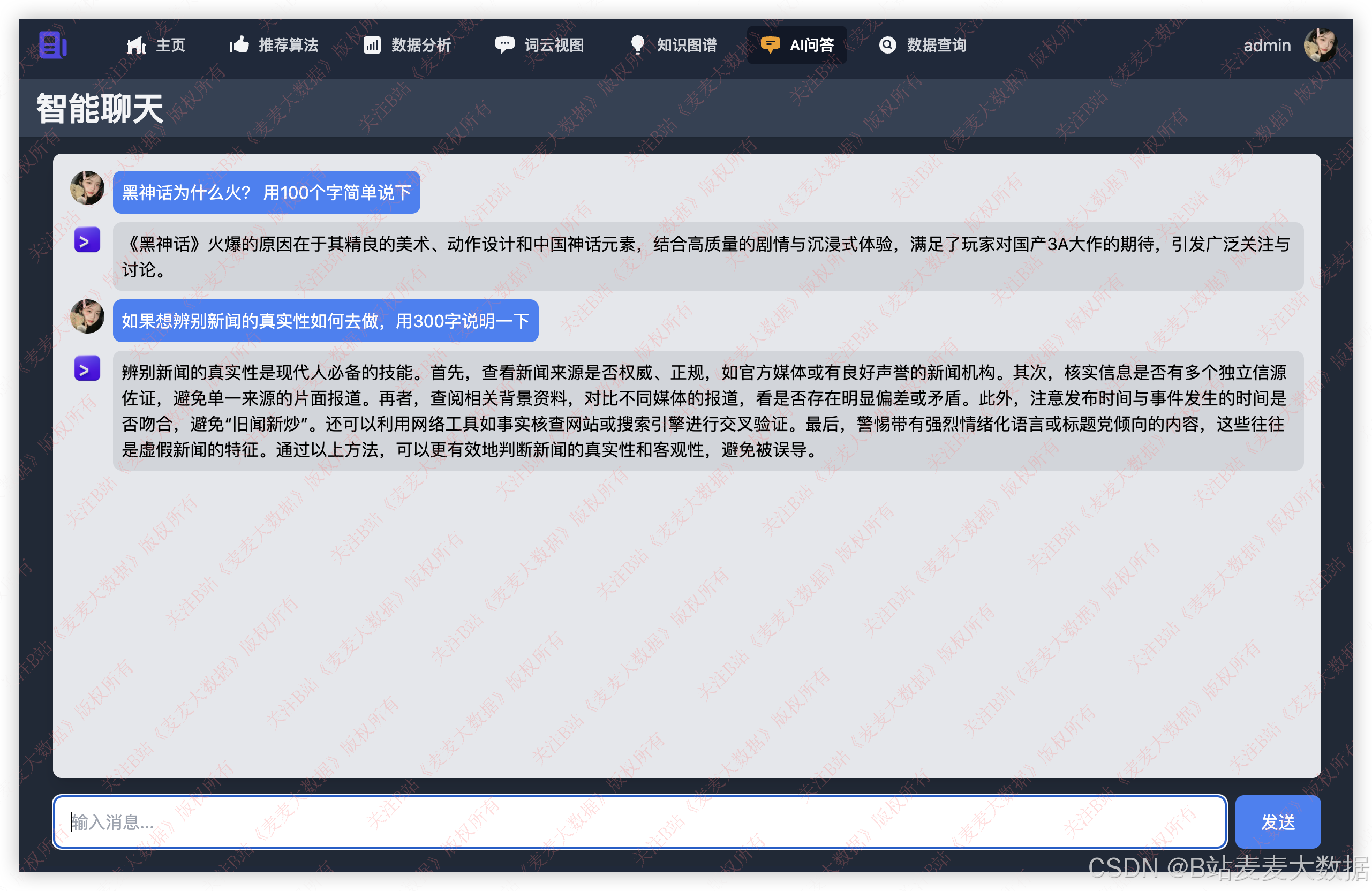
3.6 智能聊天
提供自然语言交互问答服务
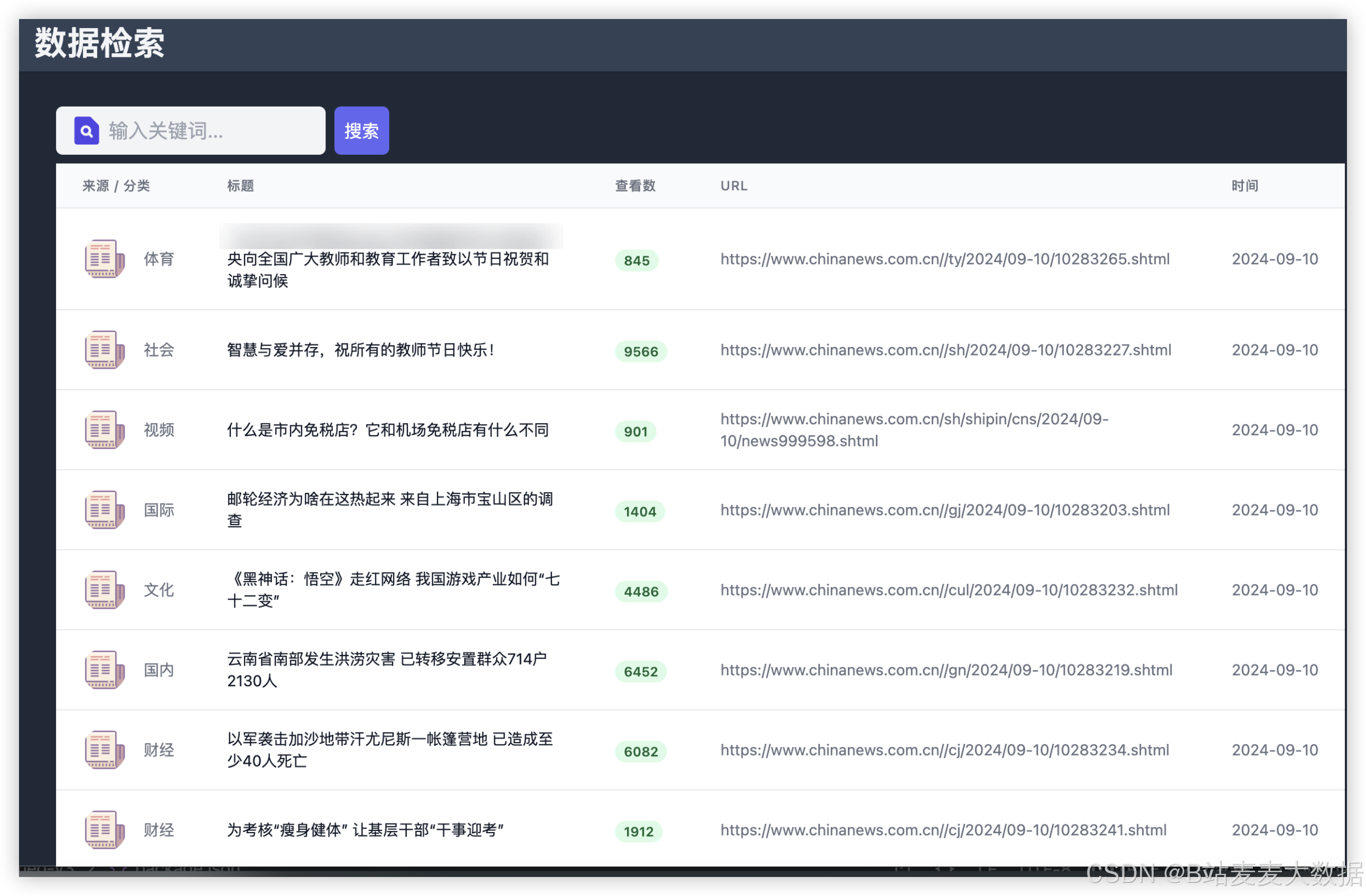
3.7 新闻搜索
支持关键词搜索新闻内容
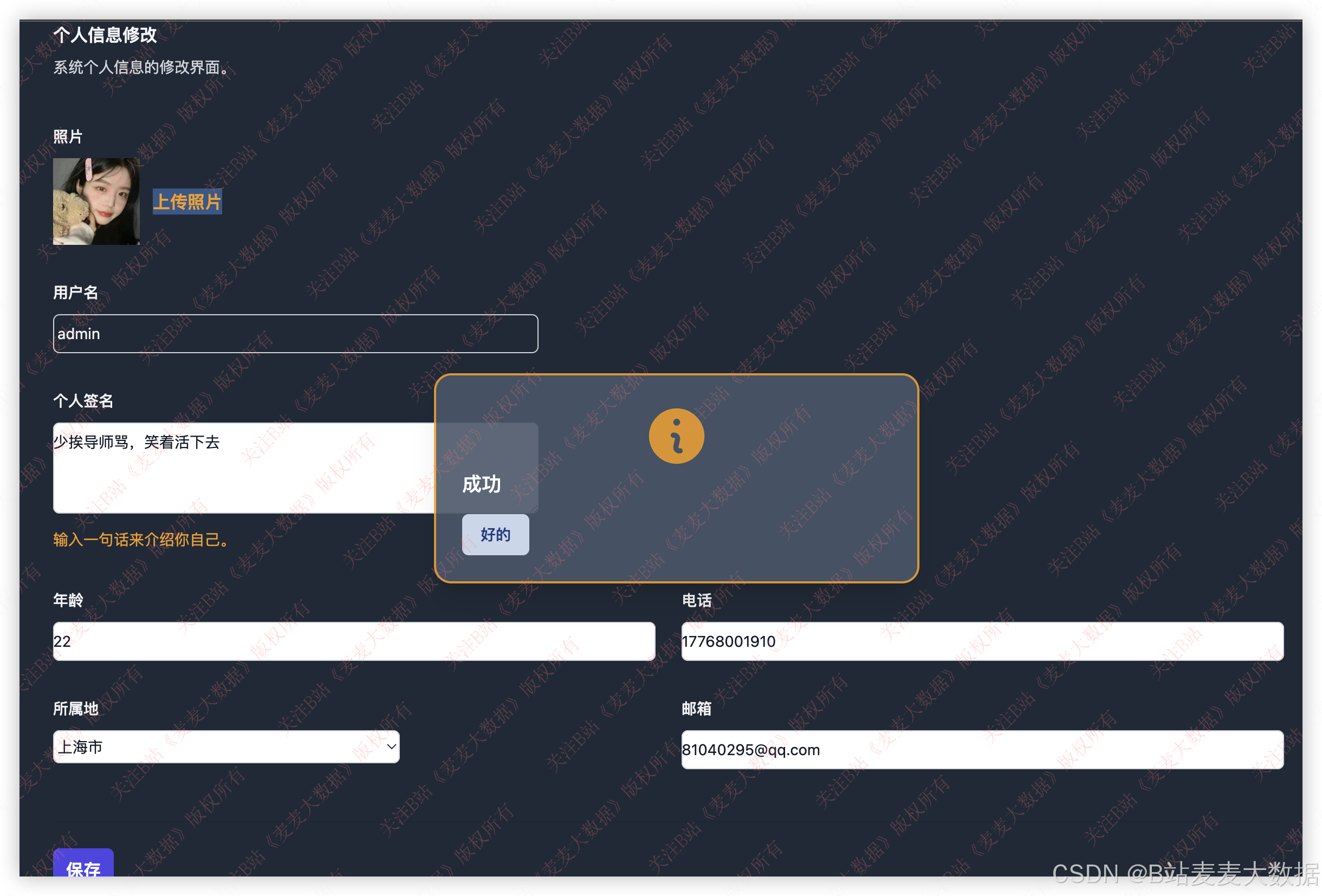
3.8 个人设置
个人设置方面包含了用户信息修改、密码修改功能。
用户信息修改中可以上传头像,完成用户的头像个性化设置,也可以修改用户其他信息。
4程序代码
4.1 代码说明
代码介绍:以下是基于协同过滤的新闻推荐算法的实现代码
4.2 流程图
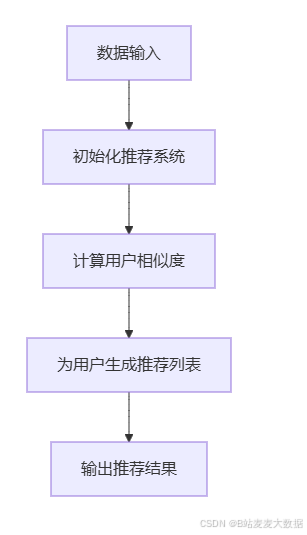
4.3 代码实例
import numpy as npclass NewsRecommender:def __init__(self, user_news_data):"""初始化推荐系统:param user_news_data: 用户新闻交互矩阵,形状为(用户数,新闻数)"""self.user_news_data = user_news_dataself.user_num = user_news_data.shape[0]self.news_num = user_news_data.shape[1]self.similarity_matrix = self.calculate_similarity()def calculate_similarity(self):"""计算用户之间的余弦相似度"""similarity = np.zeros((self.user_num, self.user_num))for i in range(self.user_num):for j in range(i+1, self.user_num):vec_i = self.user_news_data[i]vec_j = self.user_news_data[j]dot = np.dot(vec_i, vec_j)norm_i = np.linalg.norm(vec_i)norm_j = np.linalg.norm(vec_j)if norm_i == 0 or norm_j == 0:sim = 0else:sim = dot / (norm_i * norm_j)similarity[i][j] = simsimilarity[j][i] = simreturn similaritydef recommend(self, user_id, num_recommend=5):"""为指定用户生成推荐列表:param user_id: 用户ID:param num_recommend: 推荐数量:return: 推荐的新闻列表"""scores = {}for news_id in range(self.news_num):if self.user_news_data[user_id][news_id] == 0:total = 0.0count = 0for other_user_id in range(self.user_num):if other_user_id != user_id and self.user_news_data[other_user_id][news_id] > 0:total += self.similarity_matrix[user_id][other_user_id] * self.user_news_data[other_user_id][news_id]count += 1if count > 0:scores[news_id] = total / count# 按照得分排序,取前num_recommend个sorted_news = sorted(scores.items(), key=lambda x: x[1], reverse=True)[:num_recommend]return [news[0] for news in sorted_news]# 示例使用:
user_news_data = np.array([[1, 0, 1, 1, 0], # 用户1喜欢新闻1、3[1, 1, 0, 0, 1], # 用户2喜欢新闻0、1、4[0, 1, 1, 1, 0], # 用户3喜欢新闻1、2、3[1, 0, 1, 0, 0], # 用户4喜欢新闻0、2
])recommender = NewsRecommender(user_news_data)
recommended = recommender.recommend(0) # 为用户0推荐新闻
print(f"推荐新闻:{recommended}")