做公司网站用哪个空间好东营网站制作公司
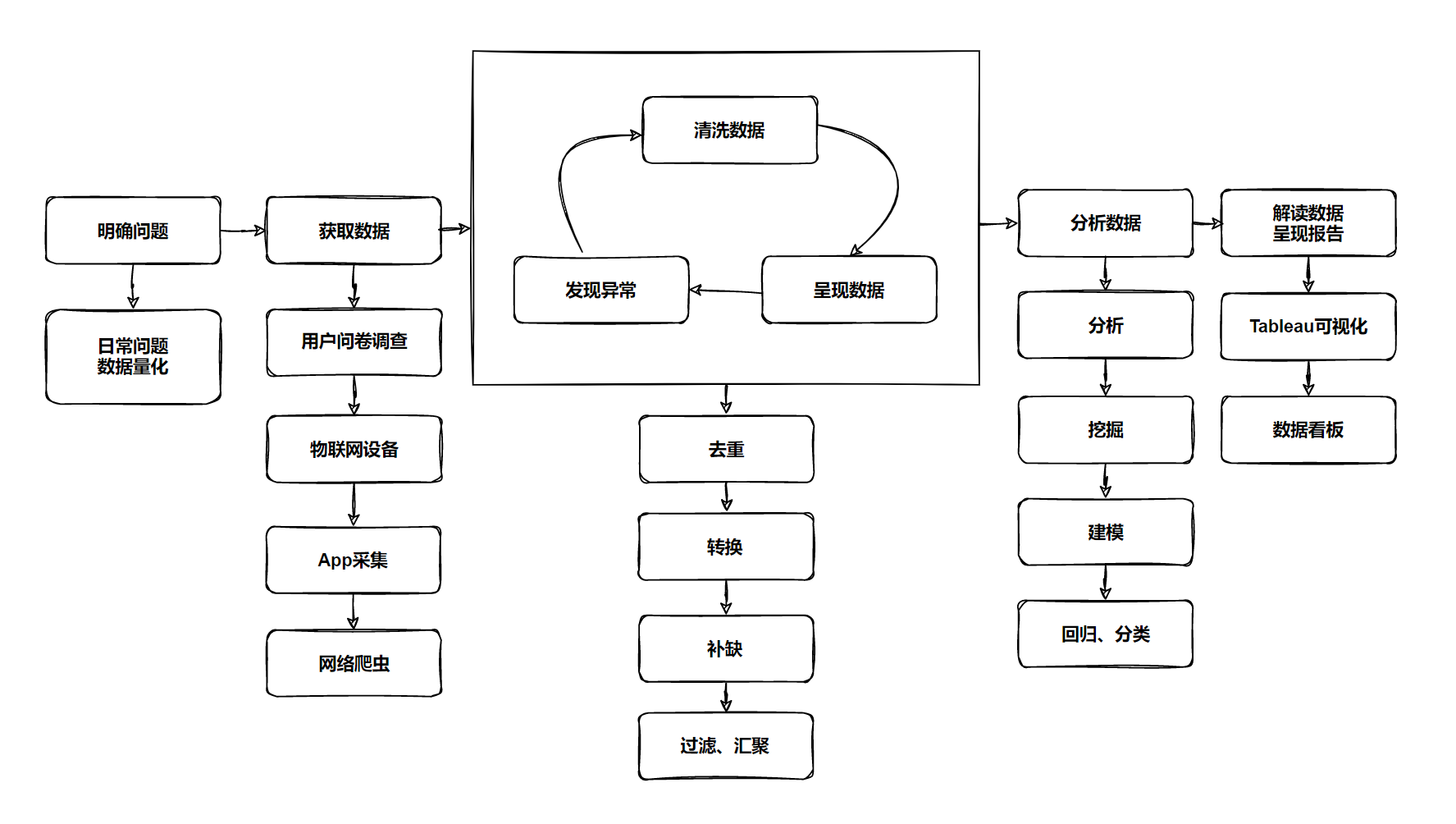
目录
一、数据读取与查看
二、数据清洗(Data Cleaning)
1. 处理缺失值(NaN)
2. 处理重复数据
3. 处理异常值(简单示例)
4. 数据类型转换
三、数据预处理(Data Preprocessing)
1. 重命名列
2. 处理类别变量
3. 新增/删除列
4. 数据排序
5. 数据筛选与过滤
6. 缩放与标准化(用sklearn)
四、数据分析(Data Analysis)
1. 统计指标计算
2. 分组聚合(GroupBy)
3. 透视表
4. 相关性分析
五、数据可视化(Data Visualization)
1. 基础绘图(matplotlib)
2. seaborn 进阶绘图
3. 多图布局
六、数据建模/机器学习
总结
一、数据读取与查看
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns# 读取数据
df = pd.read_csv('data.csv') # 也支持 .xlsx 等# 查看数据
df.head() # 前5行
df.tail() # 后5行
df.info() # 数据概况(行列、类型、缺失)
df.describe() # 数值型统计描述
df.columns # 列名
df.shape # (行数, 列数)
df.dtypes # 各列数据类型
二、数据清洗(Data Cleaning)
1. 处理缺失值(NaN)
# 查看缺失值情况
df.isnull().sum()# 删除缺失值
df.dropna(axis=0, inplace=True) # 删除含有缺失值的行
df.dropna(axis=1, inplace=True) # 删除含有缺失值的列# 填充缺失值
df['列名'].fillna(value=0, inplace=True) # 填充为指定值
df['列名'].fillna(df['列名'].mean(), inplace=True) # 均值填充
df['列名'].fillna(df['列名'].median(), inplace=True) # 中位数填充
df['列名'].fillna(method='ffill', inplace=True) # 前向填充
df['列名'].fillna(method='bfill', inplace=True) # 后向填充
2. 处理重复数据
df.duplicated().sum() # 查看重复行数
df.drop_duplicates(inplace=True) # 删除重复行
3. 处理异常值(简单示例)
# 利用统计量筛选异常值
Q1 = df['列名'].quantile(0.25)
Q3 = df['列名'].quantile(0.75)
IQR = Q3 - Q1
df_clean = df[(df['列名'] >= Q1 - 1.5*IQR) & (df['列名'] <= Q3 + 1.5*IQR)]
4. 数据类型转换
df['列名'] = df['列名'].astype(int)
df['日期列'] = pd.to_datetime(df['日期列'])
三、数据预处理(Data Preprocessing)
1. 重命名列
df.rename(columns={'旧列名':'新列名'}, inplace=True)
2. 处理类别变量
# 查看类别变量分布
df['类别列'].value_counts()# 类别编码
df['类别列编码'] = df['类别列'].astype('category').cat.codes# one-hot编码
df_onehot = pd.get_dummies(df['类别列'], prefix='类别')
df = pd.concat([df, df_onehot], axis=1)
3. 新增/删除列
df['新列'] = df['列1'] + df['列2'] # 新列赋值
df.drop('列名', axis=1, inplace=True) # 删除列
4. 数据排序
df.sort_values(by='列名', ascending=True, inplace=True)
5. 数据筛选与过滤
df_filtered = df[df['列名'] > 100]
df_filtered = df[(df['列1'] > 100) & (df['列2'] == '某类别')]
6. 缩放与标准化(用sklearn)
from sklearn.preprocessing import MinMaxScaler, StandardScalerscaler = MinMaxScaler()
df[['列1','列2']] = scaler.fit_transform(df[['列1','列2']])scaler = StandardScaler()
df[['列1','列2']] = scaler.fit_transform(df[['列1','列2']])
四、数据分析(Data Analysis)
1. 统计指标计算
df['列名'].mean()
df['列名'].median()
df['列名'].mode()
df['列名'].std()
df['列名'].var()
df['列名'].min()
df['列名'].max()
2. 分组聚合(GroupBy)
grouped = df.groupby('类别列')['数值列'].sum()
grouped = df.groupby(['类别1','类别2'])['数值列'].mean()# 多聚合函数
df.groupby('类别列')['数值列'].agg(['mean', 'sum', 'count'])
3. 透视表
pivot = pd.pivot_table(df, index='类别列', columns='另一类别列', values='数值列', aggfunc='sum')
4. 相关性分析
df.corr() # 相关系数矩阵
df['列1'].corr(df['列2']) # 两列相关系数
五、数据可视化(Data Visualization)
1. 基础绘图(matplotlib)
import matplotlib.pyplot as plt# 折线图
plt.plot(df['列名'])
plt.show()# 条形图
plt.bar(df['类别列'], df['数值列'])
plt.show()# 直方图
plt.hist(df['数值列'], bins=30)
plt.show()# 散点图
plt.scatter(df['列1'], df['列2'])
plt.show()
2. seaborn 进阶绘图
import seaborn as sns# 计数图
sns.countplot(x='类别列', data=df)
plt.show()# 箱线图
sns.boxplot(x='类别列', y='数值列', data=df)
plt.show()# 小提琴图
sns.violinplot(x='类别列', y='数值列', data=df)
plt.show()# 散点图 + 回归线
sns.regplot(x='列1', y='列2', data=df)
plt.show()# 热力图(相关系数矩阵)
sns.heatmap(df.corr(), annot=True, cmap='coolwarm')
plt.show()
3. 多图布局
fig, axs = plt.subplots(2, 2, figsize=(10,8))
axs[0,0].plot(df['列1'])
axs[0,1].bar(df['类别列'], df['数值列'])
axs[1,0].hist(df['数值列'])
axs[1,1].scatter(df['列1'], df['列2'])
plt.tight_layout()
plt.show()
六、数据建模/机器学习
# -------------------------
# 逻辑回归(分类任务)
# -------------------------
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report# 假设 df 已经清洗并预处理完成
X = df.drop('目标列', axis=1) # 特征
y = df['目标列'] # 标签# 数据集划分(80%训练,20%测试)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 建立模型
log_model = LogisticRegression(max_iter=1000)
log_model.fit(X_train, y_train)# 预测
y_pred = log_model.predict(X_test)# 评估
print("准确率:", accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred))
# -------------------------
# 随机森林(分类任务)
# -------------------------
from sklearn.ensemble import RandomForestClassifierrf_model = RandomForestClassifier(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train)
y_pred_rf = rf_model.predict(X_test)print("准确率:", accuracy_score(y_test, y_pred_rf))
print(classification_report(y_test, y_pred_rf))
# -------------------------
# XGBoost(分类任务)
# -------------------------
import xgboost as xgbxgb_model = xgb.XGBClassifier(n_estimators=100, learning_rate=0.1, random_state=42)
xgb_model.fit(X_train, y_train)
y_pred_xgb = xgb_model.predict(X_test)print("准确率:", accuracy_score(y_test, y_pred_xgb))
print(classification_report(y_test, y_pred_xgb))
总结
# Creating a comprehensive Excel and PDF containing Python data-processing + ML pipeline.
# The document will include: Module, Step, Description, and Example Code (with detailed comments).
# Files created: /mnt/data/python_data_ml_pipeline.xlsx and /mnt/data/python_data_ml_pipeline.pdffrom textwrap import dedent
import pandas as pd
from reportlab.lib.pagesizes import A4, landscape
from reportlab.platypus import SimpleDocTemplate, Paragraph, Spacer, PageBreak
from reportlab.lib.styles import getSampleStyleSheet, ParagraphStyle
from reportlab.lib.units import cm# Prepare rows for the table. Each entry is a dict with Module, Step, Description, Example Code.
rows = []def add_row(module, step, desc, code):rows.append({"模块": module,"步骤": step,"说明": desc,"示例代码(带详细注释)": dedent(code).strip()})# 1. Data reading and inspection
add_row("数据读取与查看","读取文件与基本查看","读取常见文件格式(CSV、Excel、JSON),并做基本查看:head/tail/info/describe/shape/columns。","""import pandas as pdimport numpy as np# 读取 CSV 文件df = pd.read_csv('data.csv') # 若含中文路径或编码问题,可加 encoding='utf-8' 或 encoding='gbk'# 读取 Excel 文件(第一个 sheet)df_x = pd.read_excel('data.xlsx', sheet_name=0)# 快速查看数据print(df.head()) # 打印前5行print(df.tail()) # 打印后5行print(df.info()) # 数据类型、非空数量print(df.describe()) # 数值列基本统计量(count/mean/std/min/25%/50%/75%/max)print(df.shape) # (行数, 列数)print(list(df.columns)) # 列名列表"""
)# 2. Missing values
add_row("数据清洗","缺失值检测与处理","检测缺失值并选择合适策略:删除、常数填充、均值/中位数填充、前向/后向填充、基于模型的插补(示例使用 sklearn 的 SimpleImputer)。","""# 查看每列缺失值数量print(df.isnull().sum())# 删除含缺失值的行(谨慎使用)df_drop = df.dropna(axis=0, how='any') # 删除任意含NaN的行# 用指定值填充df['col'].fillna(0, inplace=True)# 用均值或中位数填充df['col'].fillna(df['col'].mean(), inplace=True)df['col'].fillna(df['col'].median(), inplace=True)# 前向/后向填充(时间序列中常用)df['col'].fillna(method='ffill', inplace=True) # 用上一个有效值填充df['col'].fillna(method='bfill', inplace=True) # 用下一个有效值填充# 使用 sklearn 的 SimpleImputer(适合流水线)from sklearn.impute import SimpleImputerimputer = SimpleImputer(strategy='median') # 可选均值 mean、最频繁 most_frequent、常数 constantdf[['num1','num2']] = imputer.fit_transform(df[['num1','num2']])"""
)# 3. Duplicates
add_row("数据清洗","重复值检测与删除","检测重复行并删除,通常在合并数据来源后会出现重复。","""# 查看重复行数量dup_mask = df.duplicated()print('重复行数:', dup_mask.sum())# 删除重复行(保留第一次出现)df_no_dup = df.drop_duplicates(keep='first')# 若根据特定列判断是否重复df_no_dup2 = df.drop_duplicates(subset=['id','date'], keep='last')"""
)# 4. Data types and conversions
add_row("数据清洗","数据类型转换与日期解析","确保每列的数据类型正确(数值、类别、日期、字符串),将日期列转换为 datetime 便于时间序列处理。","""# 转换整数/浮点df['count'] = df['count'].astype(int)df['price'] = df['price'].astype(float)# 将日期列解析为 datetime(自动识别多种格式)df['order_date'] = pd.to_datetime(df['order_date'], errors='coerce') # errors='coerce' 将无法解析的变成 NaT# 将对象列设置为 category(节省内存并加速 groupby)df['category'] = df['category'].astype('category')"""
)# 5. Outlier handling
add_row("数据清洗","异常值检测与处理(IQR 和 Z-score 方法)","使用 IQR 或 Z-score 判断异常值,并视情况删除或替换。还可以使用基于模型的方法(IsolationForest)检测异常。","""# IQR 方法Q1 = df['amount'].quantile(0.25)Q3 = df['amount'].quantile(0.75)IQR = Q3 - Q1lower = Q1 - 1.5 * IQRupper = Q3 + 1.5 * IQRdf_iqr = df[(df['amount'] >= lower) & (df['amount'] <= upper)]# Z-score 方法(使用 numpy)from scipy import statsz_scores = stats.zscore(df['amount'].dropna())abs_z = np.abs(z_scores)df_z = df.loc[abs_z < 3] # 绝对 z-score 小于3视为非异常# 基于模型的异常检测(IsolationForest)from sklearn.ensemble import IsolationForestiso = IsolationForest(contamination=0.01, random_state=42)df['is_inlier'] = iso.fit_predict(df[['amount','other_feature']])df_clean = df[df['is_inlier']==1]"""
)# 6. Renaming, dropping, creating columns
add_row("数据预处理","重命名/删除/新增列","对列名进行重命名;删除不需要的列;通过已有列创建新特征(特征工程)。","""# 重命名列df.rename(columns={'old_name':'new_name'}, inplace=True)# 删除列df.drop(['unnecessary_col1','unnecessary_col2'], axis=1, inplace=True)# 新增列(字符串处理、数值计算、条件赋值)df['total'] = df['price'] * df['quantity'] # 数值相乘df['is_high_price'] = (df['price'] > 100).astype(int) # 条件创建标签列# 字符串处理(示例:去除空白、小写化)df['name_clean'] = df['name'].str.strip().str.lower()"""
)# 7. Categorical encoding
add_row("数据预处理","类别变量编码(Label Encoding / One-Hot / Target Encoding)","将文本类别转为数值:Label encoding(类别较多且有序时),One-hot(无序类别,使用 get_dummies 或 OneHotEncoder),Target encoding 可用于高基数类别但需防止泄露。","""# Label encoding(简单)df['cat_code'] = df['cat'].astype('category').cat.codes# One-hot 编码(pandas)df_onehot = pd.get_dummies(df, columns=['cat'], prefix=['cat'])# sklearn 的 OneHotEncoder(适用于流水线)from sklearn.preprocessing import OneHotEncoderohe = OneHotEncoder(sparse=False, handle_unknown='ignore')ohe_arr = ohe.fit_transform(df[['cat']])df_ohe = pd.DataFrame(ohe_arr, columns=ohe.get_feature_names_out(['cat']))df = pd.concat([df, df_ohe], axis=1)"""
)# 8. Feature scaling
add_row("数据预处理","缩放与标准化(MinMaxScaler / StandardScaler)","对数值特征进行缩放以便于训练(尤其是基于距离或正则化的模型,例如 KNN、SVM、LR)。","""from sklearn.preprocessing import StandardScaler, MinMaxScalerscaler = StandardScaler() # 均值为0,方差为1num_cols = ['num1','num2','num3']df[num_cols] = scaler.fit_transform(df[num_cols])# Min-Max 将数据缩放到 [0,1]mm = MinMaxScaler()df[num_cols] = mm.fit_transform(df[num_cols])"""
)# 9. Train-test split and sampling
add_row("数据预处理","划分训练集与测试集,以及处理样本不平衡(下采样/上采样/SMOTE)","使用 train_test_split 划分数据,并针对不平衡分类问题用欠采样、过采样(如 SMOTE)等手段。","""from sklearn.model_selection import train_test_splitX = df.drop('target', axis=1)y = df['target']# 常见划分 80/20X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)# 处理不均衡(示例:SMOTE)from imblearn.over_sampling import SMOTEsm = SMOTE(random_state=42)X_res, y_res = sm.fit_resample(X_train, y_train)"""
)# 10. Exploratory Data Analysis (EDA)
add_row("数据分析","描述性统计与类别分布检查","使用 describe、value_counts、unique 等函数快速理解数据分布、离散程度以及类别占比。","""# 数值列统计print(df.describe())# 类别分布print(df['category'].value_counts())print(df['category'].value_counts(normalize=True)) # 占比# 唯一值print(df['user_id'].nunique())print(df['user_id'].unique()[:10])"""
)# 11. GroupBy and aggregation
add_row("数据分析","分组聚合(groupby)","按类聚合计算 sum/mean/count/agg 等,常用于报表与特征工程。","""# 单列分组求和sales_by_cat = df.groupby('category')['sales'].sum().reset_index()# 多列分组并多函数聚合agg = df.groupby(['store','category'])['sales'].agg(['sum','mean','count']).reset_index()# 自定义聚合agg2 = df.groupby('user_id').agg({'order_id':'nunique','sales':'sum','quantity':'mean'}).reset_index()"""
)# 12. Pivot table
add_row("数据分析","透视表(pivot_table)","用于交叉表格计算(如按月和类别展开的销售额表),支持不同的聚合函数和缺失值填充。","""pivot = pd.pivot_table(df, index='month', columns='category', values='sales', aggfunc='sum', fill_value=0)"""
)# 13. Correlation and feature selection
add_row("数据分析","相关性分析与简单特征选择","查看相关系数矩阵,删除高度相关(共线性)特征。可使用方差阈值、SelectKBest 或基于模型的重要性做特征选择。","""# 相关系数矩阵corr = df.corr()print(corr['target'].sort_values(ascending=False))# 方差阈值(去掉低方差特征)from sklearn.feature_selection import VarianceThresholdsel = VarianceThreshold(threshold=0.01)X_reduced = sel.fit_transform(X)# 基于模型的选择(随机森林特征重要性)from sklearn.ensemble import RandomForestClassifierrf = RandomForestClassifier(n_estimators=100, random_state=42)rf.fit(X_train, y_train)importances = rf.feature_importances_"""
)# 14. Visualization - matplotlib basics
add_row("数据可视化","matplotlib 基础:折线图、柱状图、直方图、散点图","展示如何绘制基本图表并保存图片。","""import matplotlib.pyplot as plt# 折线图plt.figure(figsize=(8,4))plt.plot(df['date'], df['sales'])plt.title('Sales over time')plt.xlabel('date')plt.ylabel('sales')plt.xticks(rotation=45)plt.tight_layout()plt.savefig('sales_line.png')plt.show()# 直方图plt.hist(df['amount'].dropna(), bins=30)plt.title('Amount distribution')plt.show()# 散点图plt.scatter(df['feature1'], df['feature2'], alpha=0.6)plt.xlabel('feature1')plt.ylabel('feature2')plt.show()"""
)# 15. Visualization - seaborn examples
add_row("数据可视化","seaborn:箱线图、小提琴图、热力图、回归图","seaborn 提供更美观且便捷的统计图表,适合快速展示分布与关系。","""import seaborn as snsimport matplotlib.pyplot as plt# 箱线图(箱须图)sns.boxplot(x='category', y='sales', data=df)plt.show()# 小提琴图sns.violinplot(x='category', y='sales', data=df)plt.show()# 相关矩阵热力图sns.heatmap(df.corr(), annot=True, fmt='.2f')plt.show()# 散点图并拟合回归线sns.regplot(x='feature1', y='target', data=df)plt.show()"""
)# 16. Save and export cleaned data
add_row("实用技巧","保存清洗与处理后的数据","将清洗后的数据保存为 CSV 或 Excel 以供后续使用或共享。","""# 保存为 CSV(不保存索引)df.to_csv('cleaned_data.csv', index=False)# 保存为 Exceldf.to_excel('cleaned_data.xlsx', index=False)"""
)# 17. ML - prepare features and target
add_row("机器学习建模","准备特征矩阵与目标向量","选择要训练的特征 X 与目标 y,处理缺失值与编码后再划分数据集。","""# 假设 df 已完成清洗与编码X = df.drop(['target','id','date'], axis=1) # 特征矩阵y = df['target'] # 标签# 可选:保留列名方便后续分析feature_names = X.columns.tolist()"""
)# 18. ML - train_test_split and stratify
add_row("机器学习建模","划分训练集 / 验证集 / 测试集","以保证模型评估的可靠性。分类问题可使用 stratify 保持类别分布一致。若需要交叉验证,可不保留单独验证集。","""from sklearn.model_selection import train_test_split# 首先划分为训练+验证(80)和测试(20)X_tmp, X_test, y_tmp, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)# 再从训练集中划分训练(75% of 80)和验证(25% of 80)X_train, X_val, y_train, y_val = train_test_split(X_tmp, y_tmp, test_size=0.25, random_state=42, stratify=y_tmp)"""
)# 19. ML - Pipelines and ColumnTransformer
add_row("机器学习建模","使用 Pipeline 与 ColumnTransformer 组合预处理与模型","将数值与类别的预处理(缺失值/缩放/编码)放在流水线中,避免数据泄露并简化训练/预测流程。","""from sklearn.pipeline import Pipelinefrom sklearn.compose import ColumnTransformerfrom sklearn.impute import SimpleImputerfrom sklearn.preprocessing import StandardScaler, OneHotEncoderfrom sklearn.linear_model import LogisticRegressionnumeric_features = ['num1','num2']categorical_features = ['cat1','cat2']numeric_transformer = Pipeline(steps=[('imputer', SimpleImputer(strategy='median')),('scaler', StandardScaler())])categorical_transformer = Pipeline(steps=[('imputer', SimpleImputer(strategy='most_frequent')),('ohe', OneHotEncoder(handle_unknown='ignore'))])preprocessor = ColumnTransformer(transformers=[('num', numeric_transformer, numeric_features),('cat', categorical_transformer, categorical_features)])clf = Pipeline(steps=[('preprocessor', preprocessor),('classifier', LogisticRegression(max_iter=1000))])# 训练流水线(预处理和模型一体化)clf.fit(X_train, y_train)# 对原始 X_test 直接 predict(流水线会自动对 X_test 做相同预处理)y_pred = clf.predict(X_test)"""
)# 20. ML - Logistic Regression
add_row("机器学习建模","逻辑回归(Logistic Regression)示例","适用于二分类或多分类(使用 multi_class 参数)。包含正则化参数 C、solver 等超参数的简单说明。","""from sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import accuracy_score, classification_report, confusion_matrixmodel = LogisticRegression(max_iter=1000, C=1.0, solver='lbfgs', random_state=42)model.fit(X_train, y_train)y_pred = model.predict(X_test)print('Accuracy:', accuracy_score(y_test, y_pred))print(classification_report(y_test, y_pred))print(confusion_matrix(y_test, y_pred))"""
)# 21. ML - Random Forest
add_row("机器学习建模","随机森林(Random Forest)示例","集成树模型,适用于分类与回归。常调参:n_estimators、max_depth、max_features、min_samples_split。","""from sklearn.ensemble import RandomForestClassifierfrom sklearn.metrics import accuracy_score, classification_reportrf = RandomForestClassifier(n_estimators=200, max_depth=None, random_state=42, n_jobs=-1)rf.fit(X_train, y_train)y_pred_rf = rf.predict(X_test)print('RF Accuracy:', accuracy_score(y_test, y_pred_rf))print(classification_report(y_test, y_pred_rf))# 特征重要性(可视化)importances = rf.feature_importances_fi = pd.Series(importances, index=feature_names).sort_values(ascending=False)print(fi.head(20))"""
)# 22. ML - XGBoost
add_row("机器学习建模","XGBoost(XGBClassifier / XGBRegressor)示例","高性能梯度提升树,常用于线上竞赛与公司项目。注意安装 xgboost 库并使用早停(early_stopping_rounds)避免过拟合。","""import xgboost as xgbfrom sklearn.metrics import accuracy_scorexgb_clf = xgb.XGBClassifier(n_estimators=500,learning_rate=0.05,max_depth=6,subsample=0.8,colsample_bytree=0.8,random_state=42,use_label_encoder=False,eval_metric='logloss')# 可以传入验证集用于早停xgb_clf.fit(X_train, y_train,eval_set=[(X_val, y_val)],early_stopping_rounds=30,verbose=50)y_pred_xgb = xgb_clf.predict(X_test)print('XGB Accuracy:', accuracy_score(y_test, y_pred_xgb))"""
)# 23. ML - Model evaluation metrics
add_row("机器学习建模","评估指标(分类/回归)","分类常用:accuracy、precision、recall、f1、ROC-AUC;回归常用:MAE、MSE、RMSE、R2。","""# 分类指标from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_scoreprint('accuracy', accuracy_score(y_test, y_pred))print('precision', precision_score(y_test, y_pred, average='weighted'))print('recall', recall_score(y_test, y_pred, average='weighted'))print('f1', f1_score(y_test, y_pred, average='weighted'))# 回归指标from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_scoreprint('MAE:', mean_absolute_error(y_true, y_pred_reg))print('RMSE:', mean_squared_error(y_true, y_pred_reg, squared=False))print('R2:', r2_score(y_true, y_pred_reg))"""
)# 24. ML - Cross-validation & GridSearch
add_row("机器学习建模","交叉验证与超参数搜索(GridSearchCV / RandomizedSearchCV)","通过交叉验证评估模型稳定性并用网格搜索或随机搜索寻找最优超参数,注意设置 n_jobs=-1 加速。","""from sklearn.model_selection import GridSearchCV, RandomizedSearchCVparam_grid = {'n_estimators':[100,200],'max_depth':[None, 10, 20]}grid = GridSearchCV(RandomForestClassifier(random_state=42), param_grid, cv=5, scoring='f1_weighted', n_jobs=-1)grid.fit(X_train, y_train)print('best params:', grid.best_params_)print('best score:', grid.best_score_)"""
)# 25. ML - Model persistence
add_row("机器学习建模","保存与加载模型(joblib / pickle)","训练完成后保存模型便于线上部署或后续加载,joblib 对大型 numpy 数组更高效。","""import joblib# 保存模型(示例:随机森林)joblib.dump(rf, 'rf_model.pkl')# 加载模型rf_loaded = joblib.load('rf_model.pkl')y_pred_loaded = rf_loaded.predict(X_test)"""
)# 26. ML - Explainability (feature importance & SHAP brief)
add_row("机器学习建模","模型可解释性(Feature importance / SHAP)","通过模型自带的重要性或 SHAP 值解释模型决策,SHAP 对树模型效果好且直观。","""# 随机森林特征重要性(已在上文展示)fi.plot(kind='barh')# SHAP(可视化 每个特征的贡献)import shapexplainer = shap.TreeExplainer(rf)shap_values = explainer.shap_values(X_sample) # X_sample 为少量样本shap.summary_plot(shap_values, X_sample)"""
)# 27. ML - Deployment notes
add_row("实用技巧","模型上线简要注意事项","考虑数据一致性、特征工程复现、版本控制、延迟、监控、A/B 测试以及模型更新策略。","""# 常见 checklist(伪代码,便于记录)- 确保训练时的预处理 pipeline 与线上一致(用 sklearn Pipeline/ColumnTransformer)- 保存训练时用到的特征名称与编码器(例如 one-hot 的列名)- 写入模型输入校验(缺失、类型、范围)- 配置监控(预测分布漂移、性能退化)"""
)# Build DataFrame
df_out = pd.DataFrame(rows)# Save to Excel
excel_path = "/mnt/data/python_data_ml_pipeline.xlsx"
df_out.to_excel(excel_path, index=False)# Create PDF document using reportlab
pdf_path = "/mnt/data/python_data_ml_pipeline.pdf"
styles = getSampleStyleSheet()
styleN = styles['Normal']
styleH = styles['Heading1']
ps = ParagraphStyle('para', fontSize=10, leading=12)doc = SimpleDocTemplate(pdf_path, pagesize=A4, rightMargin=2*cm, leftMargin=2*cm, topMargin=2*cm, bottomMargin=2*cm)
flowables = []# Title
flowables.append(Paragraph("Python 数据处理与机器学习建模流程(含示例代码与详细注释)", styles['Title']))
flowables.append(Spacer(1, 12))# For readability, include each row as a small section
for idx, r in df_out.iterrows():flowables.append(Paragraph(f"<b>模块:</b> {r['模块']}", styles['Heading3']))flowables.append(Paragraph(f"<b>步骤:</b> {r['步骤']}", ps))flowables.append(Paragraph(f"<b>说明:</b> {r['说明']}", ps))flowables.append(Paragraph(f"<b>示例代码(缩略显示,完整代码请查看 Excel):</b>", ps))# Truncate code shown in PDF to first 600 characters for readable layoutcode_text = r['示例代码(带详细注释)']preview = code_text if len(code_text) <= 800 else code_text[:800] + "\n\n...(PDF 中仅展示片段,完整代码请查看 Excel 表格)"# Encode special characterspreview = preview.replace("&", "&").replace("<", "<").replace(">", ">")# Use preformatted font by wrapping in <pre> if small; reportlab Paragraph may strip newlines; we'll use simple Paragraph with <font face="Courier"> flowables.append(Paragraph(f"<font face='Courier' size=8>{preview}</font>", ps))flowables.append(Spacer(1, 8))if (idx+1) % 3 == 0:flowables.append(PageBreak())doc.build(flowables)# Return result info (python_user_visible will display outputs and files)
excel_path, pdf_path, len(df_out)