ActionCLIP:clip下微调的视频动作识别
论文:arxiv.org/pdf/2109.08472
github地址:GitHub - sallymmx/ActionCLIP: This is the official implement of paper "ActionCLIP: A New Paradigm for Action Recognition"
文章解读
一、建立模型
为动作识别提供了一个新的视角,即重视标签文本的语义信息,而非简单地将其映射为数字。在多模态学习框架内将该任务建模为视频 - 文本匹配问题,这通过更多的语义语言监督增强了视频表示,并使模型能够在不需要任何额外标记数据或参数的情况下进行零样本动作识别。提出了一种新的动作识别范式,称之为 “预训练、提示和微调”。该范式首先通过在大量网络图像 - 文本或视频 - 文本数据上进行预训练来学习强大的表示。然后,通过提示工程使动作识别任务更像预训练问题。
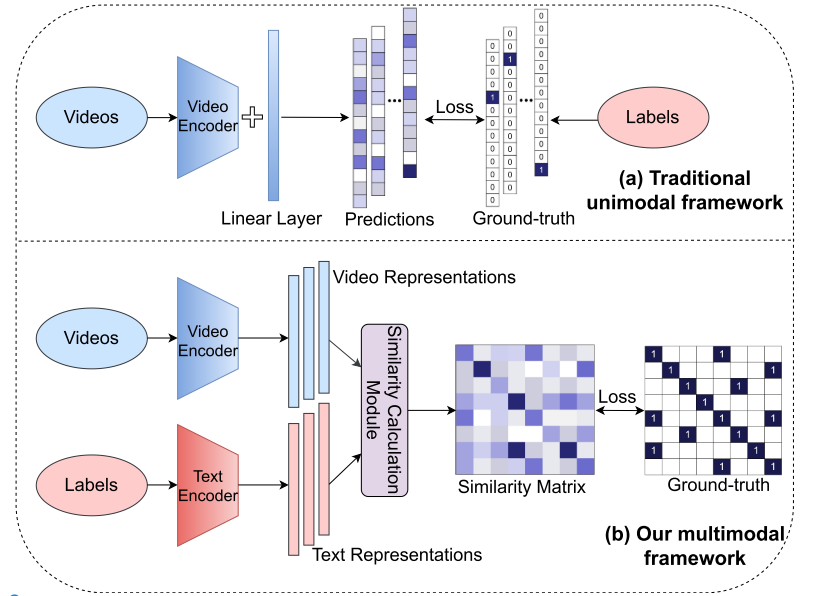
相比于传统的动作识别任务:将标签映射为数字或 one-hot 向量,而 actionclip利用标签文本本身的语义信息并尝试将相应的视频表示拉近。本文旨在实现两个任务:1、通过更多语义语言监督增强传统动作识别的表示;2、使模型能够实现零样本迁移,而无需任何额外的标记数据或参数要求。框架包括两个分别用于视频和标签的单模态编码器以及一个相似度计算模块。训练目标是使成对的视频和标签表示彼此靠近,这其实还是clip的实现方法,将问题建模为 P (f (x|y)),其中 y 是标签的原始文本,f 是一个相似性函数。那么,测试更像是一个匹配过程,得分最高的标签文本就是分类结果。
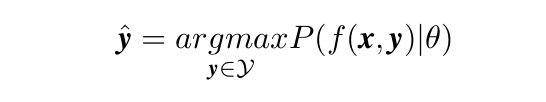
actionclip具有clip的特性,为模型准备了两个编码器,为视频和标签词分别学习了单峰编码器 gV 和 gW。视频编码器 gV 提取视觉模态的时空特征,它可以是任何设计良好的架构。语言编码器 gW 用于提取输入标签文本的特征,它可以是多种语言模型。然后,为了使视频和标签的成对表示彼此靠近,我们在相似度计算模块中利用余弦距离定义了两种模态之间的对称相似度。其中 v = gV(x) 和 w = gW(y) 分别是 x 和 y 的编码特征。
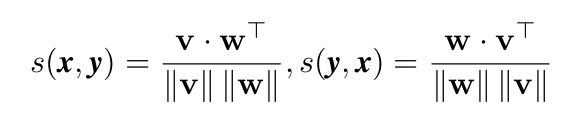
softmax归一化的视频到文本和文本到视频的相似度得分可以计算为如图公式:其中τ 是可学习的温度参数,N 是训练对的数量。 令qx2y(x)、qy2x(y)表示真实相似度分数,其中负对的概率为0,正对的概率为1。
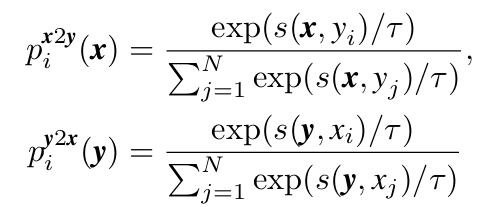
由于视频量远大于固定标签,因此在一批中不可避免地会出现属于一个标签的多个视频。 因此,qx2y i (x) 和 qy2x i (y) 中可能存在多个正对。 我们将 Kullback–Leibler (KL) 散度定义为视频文本对比损失:其中 D 是整个训练集。
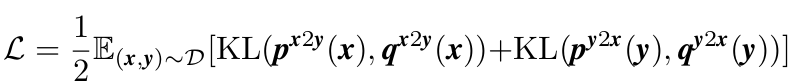
二、训练创新点
预训练过程中主要有三个上游预训练代理任务:多模态匹配(MM)、多模态对比学习(MCL)和掩码语言建模(MLM)。MM 任务用于预测一对模态是否匹配。MCL 旨在使成对的单模态表示彼此更接近。MLM 利用两种模态的特征来预测被掩码的词语。由于巨大的计算成本限制,本文并不聚焦于这一步骤。我们直接选择应用一个预训练模型。
本文制作了两种提示词,即文本提示词和视觉提示词。前者对于标签文本扩展具有重要意义。给定一个标签 y,我们首先定义一组允许值 Z,然后通过填充函数 ffill (y, z) 获得提示性文本输入 y,其中 z∈Z。ffill 有三种类型,分别是前缀提示词、完形填空提示词和后缀提示词。它们是根据填充位置来分类的。

同时,模型还准备了三种视觉提示:如果模型是在视频 - 文本数据上预训练的,那么视觉部分几乎不需要额外的表述,而如果模型是在图像 - 文本数据上预训练的,那么我们就应该让模型学习视频中重要的时间关系。形式上,给定一个视频 x,我们引入提示函数作为 ftem (hI (x)),其中 hI 是预训练模型的视觉编码网络。同样,根据 ftem 作用于 hI 的位置不同,它有三种变体:网络前提示、网络内提示和网络后提示。
部署训练
以训练ucf101为例,conda创建虚拟环境:python=3.8,依次安装以下库:

下载ucf101数据集,数据集划分和提取帧和光流可以参考GitHub - yjxiong/temporal-segment-networks: Code & Models for Temporal Segment Networks (TSN) in ECCV 2016
下载预训练模型,选择ViT-B/16_8f.pt的。

训练:
需要调整ucf_train.yaml下的数据集读取路径,读取你的划分文件读取路径和预训练权重路径(pretrain和train_list和val_list):
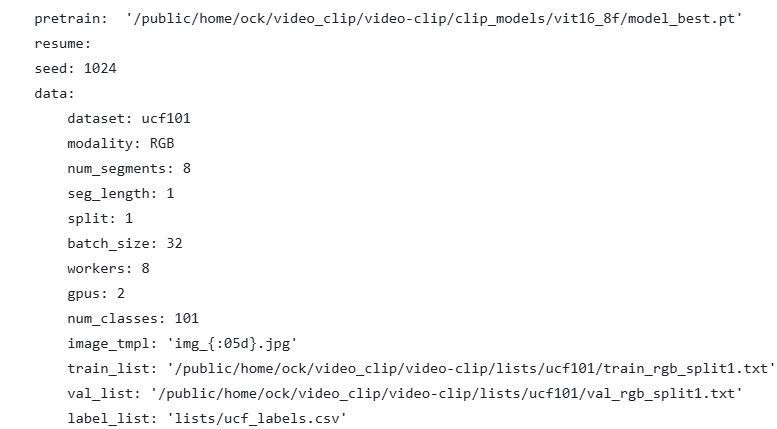
按照自己的需求调整epoch,训练效果不好的可以适当增大num_segments: 8和seg_length: 1
训练好的权重会在exp/下存放。
测试:
bash scripts/run_test.sh ./configs/ucf101/ucf_test.yamlzero-shot:
bash scripts/run_test.sh ./configs/ucf101/ucf_ft_zero_shot.yaml为了测试可视化,观察模型对视频中的动作识别效果,写一个脚本文件:
import os
import sys
import cv2
import yaml
import torch
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
from tqdm import tqdm# 添加项目根目录到Python路径
sys.path.append(os.path.dirname(os.path.abspath(__file__)))# 导入项目中的必要模块
from clip import clip
# 不需要导入UCF101类,因为我们直接使用CLIP模型处理
import torchvision.transforms as transforms
from utils.tools import convert_models_to_fp32def load_model(config_file, checkpoint_path):"""加载模型和配置"""# 读取配置,指定UTF-8编码with open(config_file, 'r', encoding='utf-8') as f:config = yaml.load(f, Loader=yaml.FullLoader)# 移动到设备device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 直接从checkpoint加载模型checkpoint = torch.load(checkpoint_path, map_location=device)# 获取模型架构import clipmodel_name = config['network']['arch']# 创建模型model = clip.load(model_name, device=device, jit=False)[0]# 加载权重model.load_state_dict(checkpoint['model_state_dict'], strict=False)model.eval()# 加载类别标签 - 跳过标题行并获取name列with open(config['data']['label_list'], 'r') as f:lines = f.readlines()[1:] # 跳过标题行labels = [line.strip().split(',')[1] for line in lines] # 获取name列return model, labels, config, devicedef get_video_frames(video_path, num_segments=8):"""从视频中提取帧"""cap = cv2.VideoCapture(video_path)frames = []fps = cap.get(cv2.CAP_PROP_FPS)total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))# 等间隔采样indices = np.linspace(0, total_frames - 1, num_segments, dtype=int)for idx in indices:cap.set(cv2.CAP_PROP_POS_FRAMES, idx)ret, frame = cap.read()if ret:# 转换BGR为RGBframe = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)frames.append((frame, idx))cap.release()return frames, fpsdef predict_frames(model, frames, labels, config, device):"""预测视频帧的动作类别"""# 定义测试变换transform = transforms.Compose([transforms.Resize((config['data']['input_size'], config['data']['input_size'])),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])# 准备文本提示text_inputs = torch.cat([clip.tokenize(f"a photo of a person {label}") for label in labels]).to(device)predictions = []with torch.no_grad():text_features = model.encode_text(text_inputs)text_features = text_features / text_features.norm(dim=-1, keepdim=True)for frame, frame_idx in frames:# 预处理帧img = transform(Image.fromarray(frame)).unsqueeze(0).to(device)# 获取视觉特征image_features = model.encode_image(img)image_features = image_features / image_features.norm(dim=-1, keepdim=True)# 计算相似度similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1)probs, indices = similarity[0].topk(5)# 保存预测结果predictions.append({'frame': frame,'frame_idx': frame_idx,'top_predictions': [(labels[idx], prob.item()) for prob, idx in zip(probs, indices)],'best_prediction': labels[indices[0]],'best_prob': probs[0].item()})return predictionsdef visualize_predictions(video_path, predictions, output_path, true_label=None):"""可视化预测结果并保存为视频"""# 获取第一帧信息以设置视频写入器first_frame = predictions[0]['frame']height, width, channels = first_frame.shape# 创建视频写入器fourcc = cv2.VideoWriter_fourcc(*'mp4v')out = cv2.VideoWriter(output_path, fourcc, 5, (width, height))for pred in tqdm(predictions, desc="Processing frames"):frame = pred['frame'].copy()frame_idx = pred['frame_idx']best_pred = pred['best_prediction']best_prob = pred['best_prob']# 将RGB转换回BGR用于OpenCVframe_bgr = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)# 在帧上绘制信息 - 只显示top1预测和真实标签# 1. 真实标签(如果提供)if true_label:cv2.putText(frame_bgr, f"Label: {true_label}", (10, 40), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 0, 255), 2)# 2. Top1预测结果和概率cv2.putText(frame_bgr, f"Prediction: {best_pred} ({best_prob:.2%})", (10, 80), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (255, 0, 0), 2)# 写入帧out.write(frame_bgr)out.release()print(f"Output video saved to {output_path}")def process_video(video_path, config_file, checkpoint_path, output_dir, true_label=None):"""处理单个视频并可视化预测结果"""# 加载模型model, labels, config, device = load_model(config_file, checkpoint_path)# 提取视频帧frames, fps = get_video_frames(video_path, config['data']['num_segments'])# 预测帧predictions = predict_frames(model, frames, labels, config, device)# 创建输出目录os.makedirs(output_dir, exist_ok=True)# 生成输出文件名video_name = os.path.basename(video_path).split('.')[0]output_path = os.path.join(output_dir, f"{video_name}_visualized.mp4")# 可视化预测结果visualize_predictions(video_path, predictions, output_path, true_label)return output_pathif __name__ == '__main__':# 示例用法import argparseparser = argparse.ArgumentParser(description="Visualize ActionCLIP predictions on a video")parser.add_argument('--video', type=str, required=True, help='Path to input video file')parser.add_argument('--config', type=str, default='./configs/ucf101/ucf_test.yaml', help='Path to config file')parser.add_argument('--checkpoint', type=str, default='./exp/clip_ucf/ViT-B/16/ucf101/20251102_094712/model_best.pt', help='Path to model checkpoint')parser.add_argument('--output-dir', type=str, default='./visualizations', help='Directory to save output video')parser.add_argument('--true-label', type=str, default=None, help='True label of the video')args = parser.parse_args()# 处理视频output_path = process_video(args.video, args.config, args.checkpoint, args.output_dir, args.true_label)print(f"Visualization complete! Output saved to {output_path}")这个脚本会生成一个带有预测结果的可视化视频,显示:
- 真实标签(如果提供)
- 模型的预测结果和置信度
- 视频帧的实时预测
再创建以下批量识别代码:
import os
import random
import subprocess
import argparse
from tqdm import tqdmdef get_all_categories(videos_dir):"""获取所有类别的列表"""categories = []for item in os.listdir(videos_dir):item_path = os.path.join(videos_dir, item)if os.path.isdir(item_path):categories.append(item)return categoriesdef get_random_videos(category_dir, num_samples=2):"""从指定类别中随机选择指定数量的视频"""videos = []for item in os.listdir(category_dir):if item.endswith('.avi') or item.endswith('.mp4'):videos.append(os.path.join(category_dir, item))# 随机选择num_samples个视频,如果视频数量不足,则全部选择if len(videos) > num_samples:return random.sample(videos, num_samples)else:return videosdef batch_process_videos(videos_dir, config_file, checkpoint_path, output_dir, num_samples=2):"""批量处理所有类别的视频"""# 获取所有类别categories = get_all_categories(videos_dir)print(f"找到 {len(categories)} 个类别")# 为每个类别处理视频for category in tqdm(categories, desc="处理类别"):category_dir = os.path.join(videos_dir, category)# 获取随机视频videos = get_random_videos(category_dir, num_samples)# 处理每个视频for video_path in videos:print(f"处理视频: {video_path}")# 构建命令cmd = ['python', 'visualize_predictions.py','--video', video_path,'--config', config_file,'--checkpoint', checkpoint_path,'--output-dir', output_dir,'--true-label', category]# 执行命令try:subprocess.run(cmd, check=True)except subprocess.CalledProcessError as e:print(f"处理视频 {video_path} 失败: {e}")if __name__ == '__main__':parser = argparse.ArgumentParser(description="批量可视化所有类别的视频预测结果")parser.add_argument('--videos-dir', type=str, default='./findlab/videos', help='视频目录路径')parser.add_argument('--config', type=str, default='./configs/findlab/findlab_test.yaml', help='配置文件路径')parser.add_argument('--checkpoint', type=str, default='./exp/clip_ucf/ViT-B/16/findlab/cv_fold5/model_best.pt', help='模型检查点路径')parser.add_argument('--output-dir', type=str, default='./visualizations/batch/findlab/cv_fold5', help='输出目录路径')parser.add_argument('--num-samples', type=int, default=2, help='每个类别选择的视频数量')args = parser.parse_args()# 创建输出目录os.makedirs(args.output_dir, exist_ok=True)# 批量处理视频batch_process_videos(args.videos_dir, args.config, args.checkpoint, args.output_dir, args.num_samples)print("批量处理完成!")执行以下指令:分别输入视频路径、配置路径、训练好的权重、输出路径、每个类别的视频采样数
python batch_visualize_test.py \--videos-dir ./ucf101/videos \--config ./configs/ucf101/ucf_test.yaml \--checkpoint ./exp/clip_ucf/ViT-B/16/ucf101/20251102_094712/model_best.pt \--output-dir ./visualizations/batch/ucf101 \--num-samples 2输出结果:
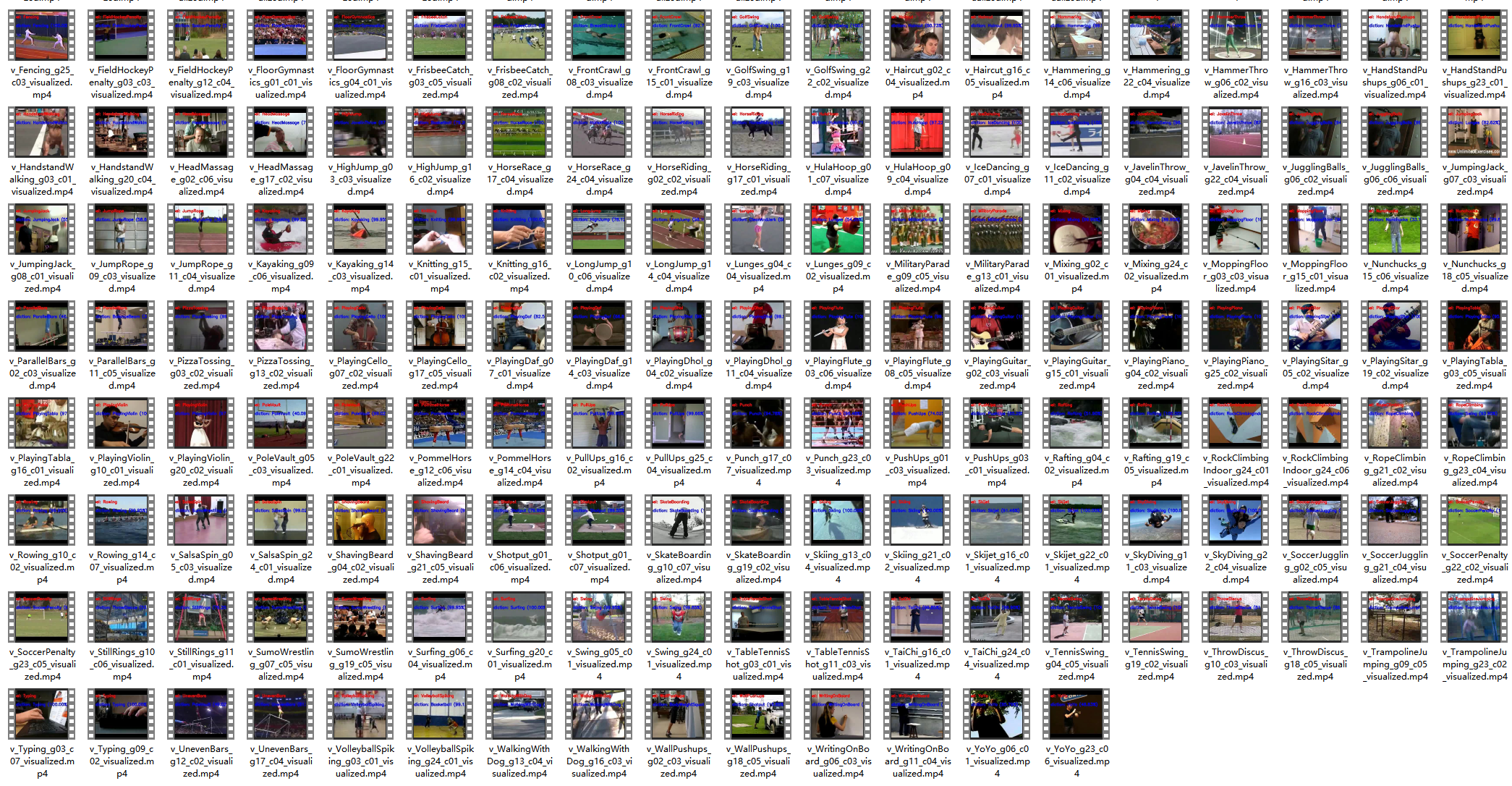
actionclip在epoch为50训练下能达到97+的准确率,效果很好。