CSFAFormer:用于多模态遥感图像语义分割的类别选择性特征聚合 Transformer
随着成像分辨率的提升,高分辨率光学图像(OI)的细节变得更加复杂。**光照变化和遮挡等因素导致类内特征差异增大,而局部纹理的高度相似又加剧了类间混淆,从而影响分割精度。**来自不同传感器的辅助数据(AD)能够从多个角度捕获目标特征,克服单模态数据的局限性。**然而,多模态数据融合面临挑战,主要由于不同数据源之间存在特征表达差异。**因此,设计针对多模态数据特性的高效融合策略,以充分发挥其互补优势,显得尤为重要 [20,21]。
当前多模态数据特征融合方法可分为三类:数据级融合、决策级融合和特征级融合 [22]。数据级融合通过拼接或预处理输入数据来学习特征,具有简单、高效的优点 [23]。但数字表面模型(DSM)中的噪声可能影响特征学习的稳定性。决策级融合通过组合不同分类结果,具有良好的可扩展性和灵活性,使得每种模态的优势都能体现在最终决策中。然而,它忽略了模态之间的内在关系,无法充分利用其互补信息 [24,25]。特征级融合通过多尺度特征交互充分挖掘跨模态依赖关系,能够有效捕获模态之间的细粒度差异。随着技术发展,特征级融合方法已从简单的通道拼接或求和 [26],演变为更复杂的基于门控 [22,27] 和注意力的交互技术 [28,29],显著增强了融合特征的表达能力。
尽管多模态融合方法取得了进展,但在实际应用中仍存在若干挑战。
首先,现有方法通常未能考虑模态间类别信息的异质性,导致融合过程中特征交互存在信息冗余,难以实现有效融合。
其次,大多数方法未充分利用不同模态的互补优势,使得模型在复杂场景中的性能提升受限。
尽管多模态融合方法取得了进展,但在实际应用中仍存在若干挑战。首先,现有方法通常未能考虑模态间类别信息的异质性,导致融合过程中特征交互存在信息冗余,难以实现有效融合。
其次,大多数方法未充分利用不同模态的互补优势,使得模型在复杂场景中的性能提升受限。
如图 1 所示,OI 擅长捕获细粒度纹理细节,但往往难以区分纹理相似的建筑与植被。相反,辅助数据(如 DSM)可结合高度信息弥补这一不足。然而,对于不依赖高度的类别,如不透水面和植被,仍可能发生混淆。若能够有效整合来自 OI 和 AD 的类别信息并用于引导自适应特征融合,则可以更准确地捕获细粒度类别特征,提高模型在复杂动态环境下的鲁棒性,并改善语义分割的准确性与稳定性。
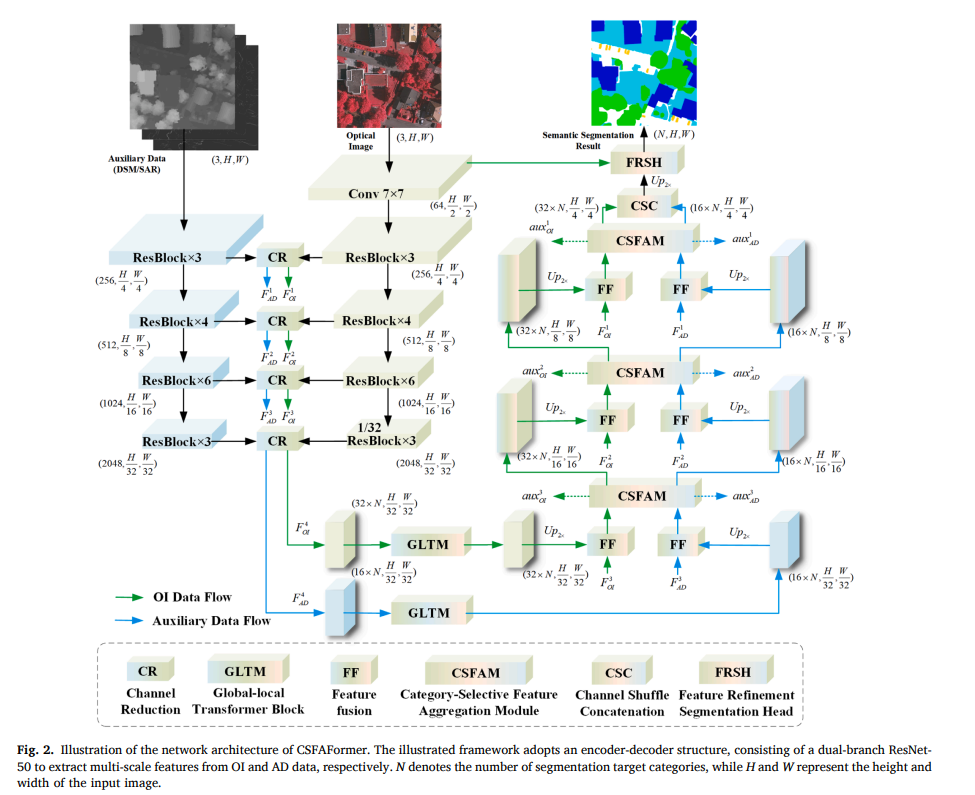
基于上述考虑,我们提出了一种基于 Transformer 的类别选择性特征聚合框架(CSFAFormer)。
通过引入类别引导的动态特征加权策略,该框架能够自适应地调节模态间的交互权重,从而增强融合效果并提高特征的可分性。
在解码器中引入了类别选择性特征聚合模块(CSFAM),由局部分支与全局分支构成。局部分支侧重于捕获细粒度空间特征(OI),促进多尺度下的高质量融合。全局分支利用类别信息引导(语义,高级特征)特征聚合,有助于保持语义特征的类内一致性。
全局分支包括类别交叉校准机制(C3M)和类别选择性 Transformer 模块(CSTM)C3M 估计两个分支中每个像素的潜在类别分布,并通过基于信息熵的校准策略优化该信息,随后将校准后的信息加权求和以获得更准确的类别预测。值得注意的是,C3M 输出的类别估计可视为两种模态特征的一种压缩表示。随后,CSTM 模块利用校准后的类别信息,从全局视角沿类别维度对特征进行加权,实现选择性特征聚合。这种方式能够有效捕获细粒度的类别差异,增强模态之间的互补关系,并显著提升复杂遥感场景中的语义分割性能。
本文贡献:
• 提出一种新的基于 Transformer 的多模态语义分割框架 CSFAFormer,通过沿类别分布维度引导 OI 与 AD 特征融合,从而提升特征融合的准确性。
• 提出了类别交叉校准机制(C3M),用于压缩不同模态的特征,执行自适应的类别级特征融合,并通过基于置信度的策略校准类别预测,确保类别信息的准确与可靠。
• 提出了类别选择性特征聚合模块(CSFAM),包含局部和全局分支。局部分支捕获细粒度空间特征,全局分支利用 CSTM 根据校准的类别信息自适应加权特征,有效增强语义一致性与类别间可分性。
相关工作
随着注意力机制和 Transformer 架构在单模态语义分割中的广泛应用,这些技术也逐渐被用于多模态融合,以更有效整合多模态的全局特征。TransFuser [43] 利用多个带自注意力的 Transformer 模块捕获图像与激光雷达数据之间的跨模态依赖,从而增强全局上下文融合能力。SwinFusion [44] 使用自注意力和交叉注意力建模跨模态与模态内部的依赖关系,提高融合效果。CMFNet [45] 使用跨模态多尺度 Transformer 整合光学图像与 DSM 特征,通过建模长程依赖以获得更优的分割表现。MIEFNet [29] 分别使用 CNN 和图卷积网络(GCN)提取光学图像与 DSM 特征,并通过基于 Transformer 的融合编码器与解码器实现高效的高级语义信息学习。FTransDeepLab [46] 将 Transformer 与 DeepLabv3+ 相结合,通过多尺度编码器和跨模态注意力机制有效整合特征,并显著提升遥感图像的分割性能。MCKTNet [47] 通过跨模态迁移学习、极化跨自注意力机制以及多尺度边缘感知模块,实现高效且轻量化的多模态遥感图像语义分割。
然而,基于注意力的融合方法通常会造成特征冗余与纠缠,增加计算复杂度,并削弱对模态特定细节的捕获能力,从而影响分割性能。
在本文中,我们提出了 CSFAM,旨在利用多模态数据中的类别特定信息,高效优化特征选择与融合过程。不同于传统的简单拼接或加权求和(这些方法往往忽略类别特定细节),CSFAM 融入类别嵌入向量进行条件建模。
该方法能够有效过滤冗余或不相关的信息,并增强对各类别关键特征的表达能力。
方法