注意力机制-学习
1. 自注意力机制
 句子:"The animal didn't cross the street because it was too tired." 在这个句子中,“it”指的是“animal”.
句子:"The animal didn't cross the street because it was too tired." 在这个句子中,“it”指的是“animal”.
在自注意力机制中,当我们处理到“it”这个词时,模型会计算“it”与句子中其他所有词的关联度。这意味着“it”不仅会考虑前一个词“too”,还会考虑更早出现的词,比如“animal”。
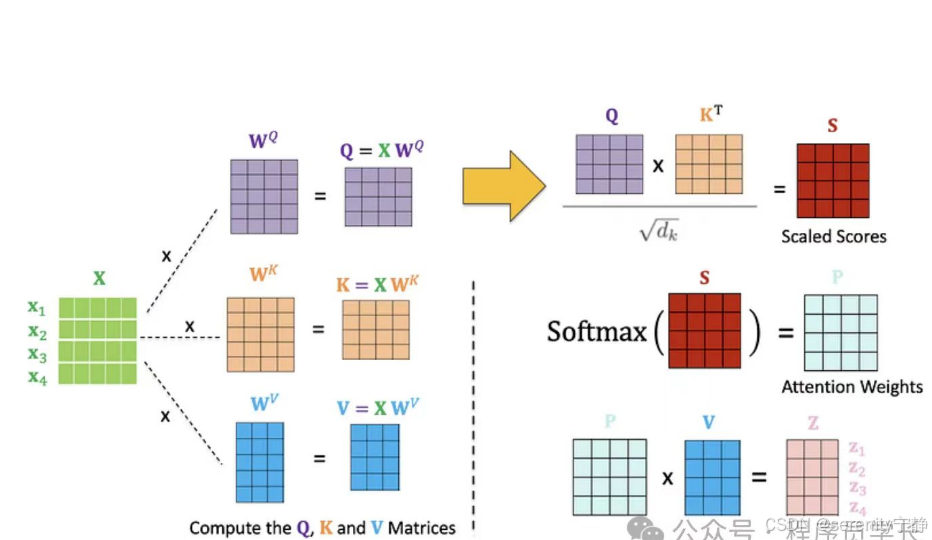
全流程讲解:
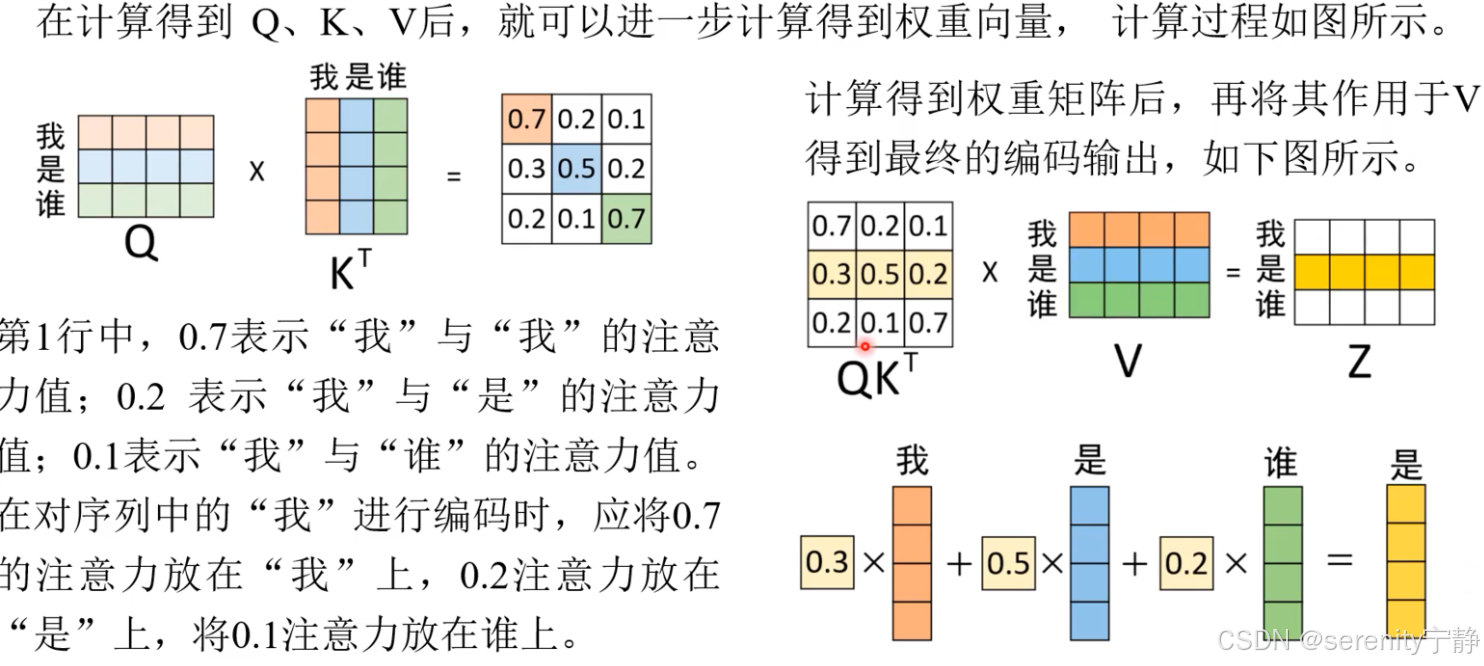
1. 将"The animal d..." 句子通过Embedding转为图中的矩阵x,矩阵中一行代表:一个token或是一个单词,列代表:单词所转换的词向量特征值
2. x矩阵经过三个不同的权重矩阵进行线性变换(就是一层全连接层),得到三个矩阵分别是Q,K,V。
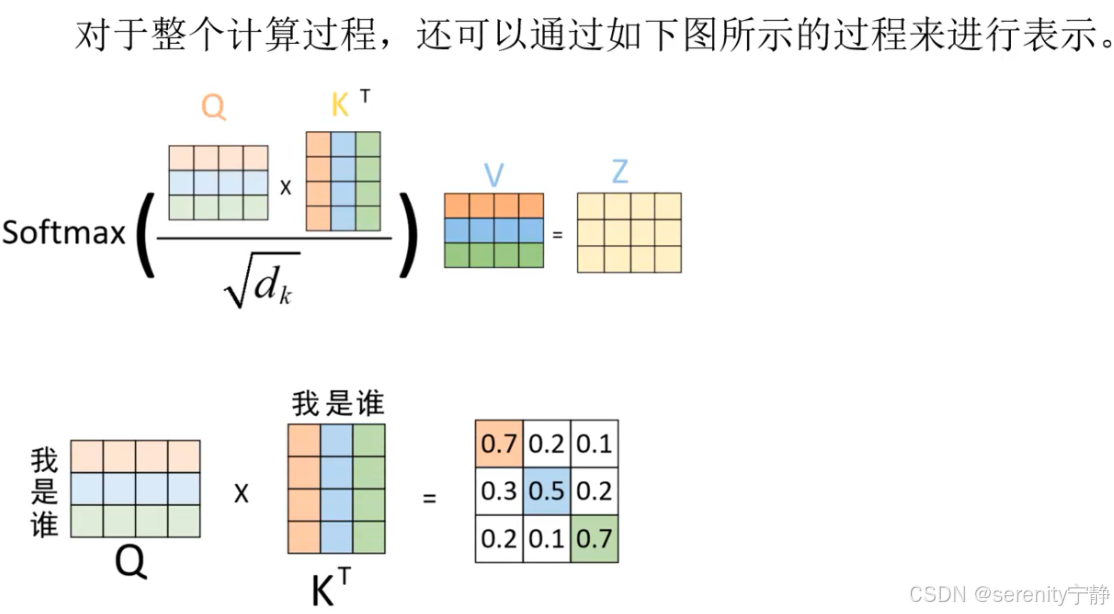
3. 然后根据attention注意力机制的核心公式softmax(Q*K的转置/根号dk)得到对应的注意力分配权重。
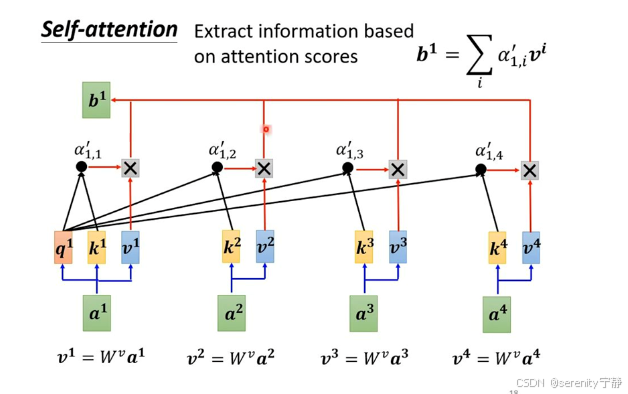
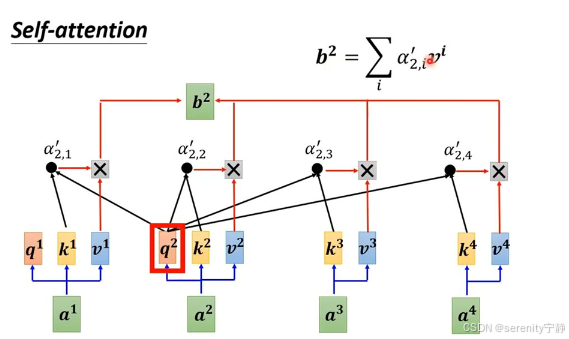
4. 然后注意力权重*V得到结果z。z其实就是对V的加权求和
然后每一个词都会经过以上这套流程,每个词都会被编码为三个向量:Query(查询)、Key(键)和Value(值)。这些向量是通过将原始词嵌入分别乘以三个不同的权重矩阵得到的。
图解就是:
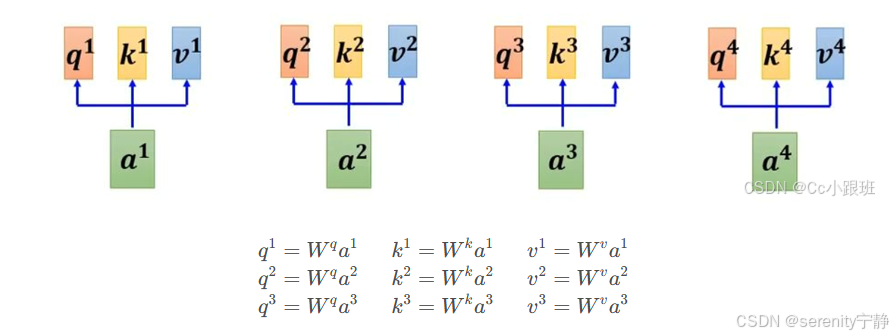
对于每个位置上的词(例如“it”),我们会用它的Query向量和其他所有词的Key向量进行点积运算,然后除以某个缩放因子(通常是根号下Key向量的维度)
即Q1.....Qn都会逐个和K1到Kn进行注意力权重计算。图解如下:
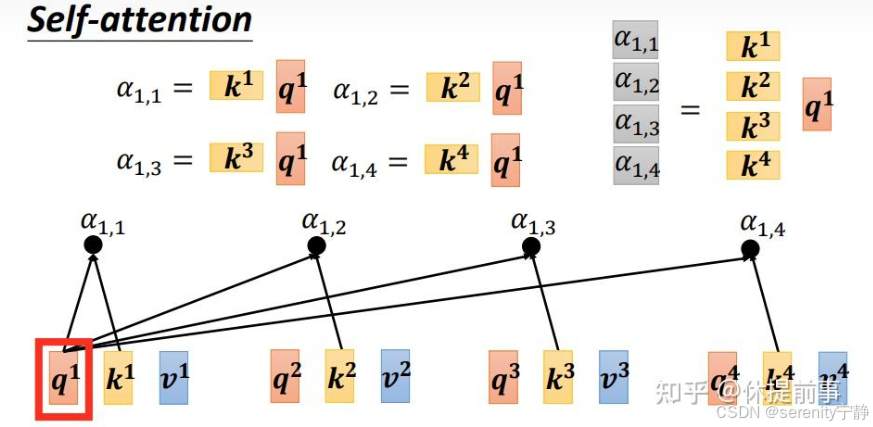
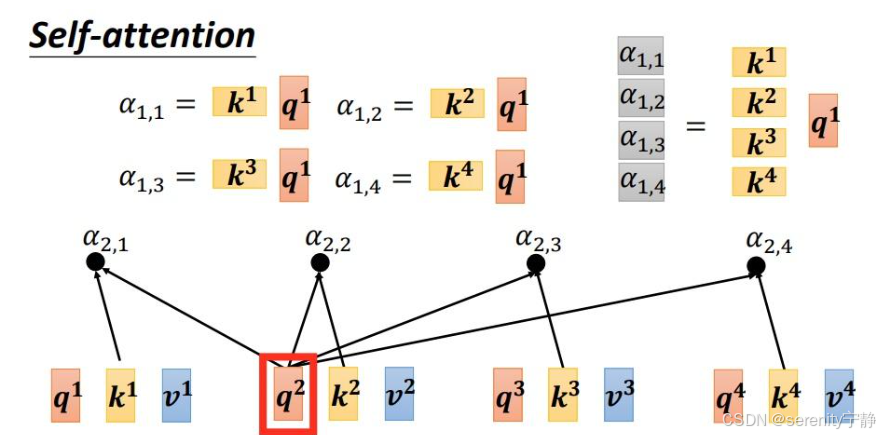
整个自注意力机制就是:
1.1. 自注意力代码实现:
# 导入相关需要的包
import torch
import torch.nn as nn
import torch
import math
def attention(q,k,v,dropout=None):
#将k矩阵的最后一个维度值作为d_k
d_k = k.size(-1)
#将k矩阵的最后两个维度互换(转置),与q矩阵相乘,除以d_k开根号
scores = torch.matmul(q,k.transpose(-2,-1)) / math.sqrt(d_k)
p_attn = torch.softmax(scores,dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn,v)
class SelfAtt(nn.Module):
def __init__(self, hidden_dim):
super(SelfAtt, self).__init__()
self.hidden_dim = hidden_dim
# 一般 Linear 都是默认有 bias
# 一般来说, input dim 的 hidden dim
self.query_proj = nn.Linear(hidden_dim, hidden_dim)
self.key_proj = nn.Linear(hidden_dim, hidden_dim)
self.value_proj = nn.Linear(hidden_dim, hidden_dim)
def forward(self, x):
# X shape is: (batch, seq_len, hidden_dim), 一般是和 hidden_dim 相同
# 但是 X 的 final dim 可以和 hidden_dim 不同
q = self.query_proj(x)
k = self.key_proj(x)
v = self.value_proj(x)
output = attention(q,k,v)
return output
X = torch.rand(3, 2, 4)
net = SelfAtt(4)
net(X)2. 多头自注意力机制(Multi-Head Self-Attention)代码实现
计算机可能需要执行好几次注意力才能真正观察到图片中有效的信息,因此执行多头注意力,然后把多头注意力的值进行concat融合。
在自注意力机制的基础上,增加可训练的线性变换(即矩阵相乘),以提高模型的拟合能力.
多头自注意力机制就是同时通过多个"自注意力机制"进行特征提取

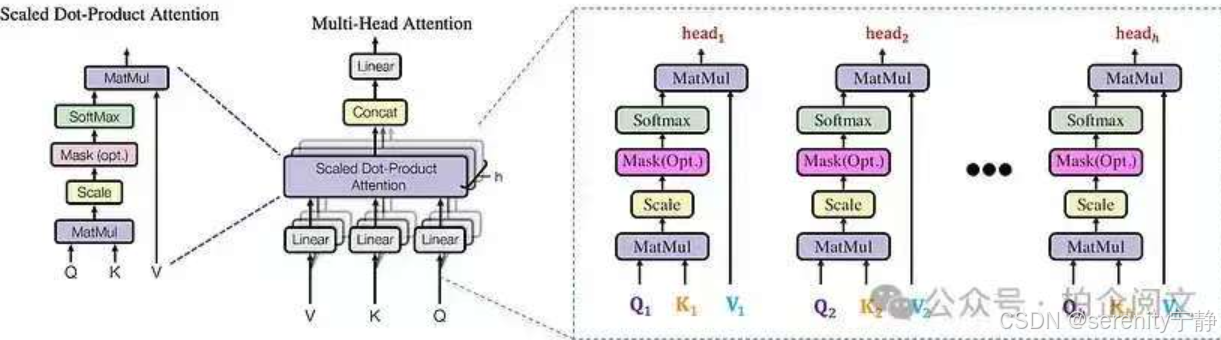
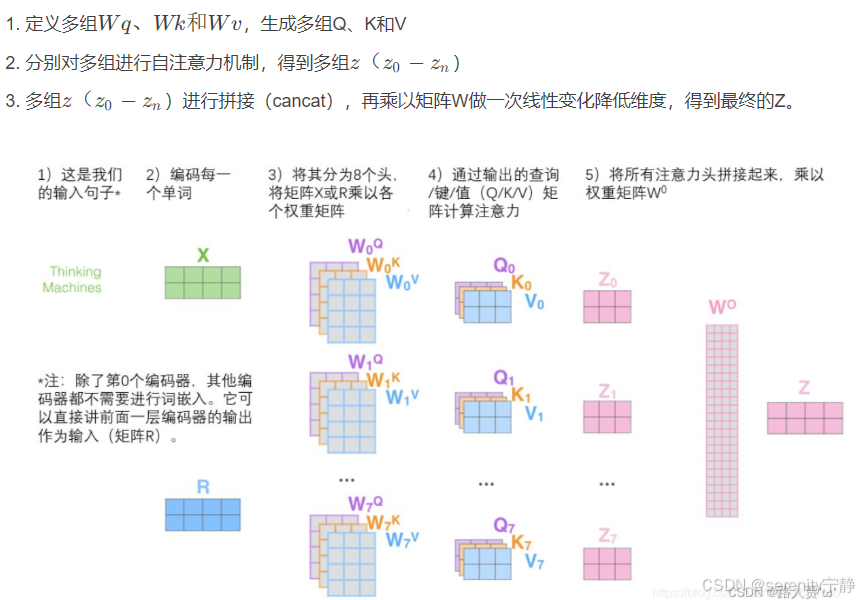


2.2 多头注意力代码实现
# 多头注意力机制
class MultHeadedAttention(nn.Module):
def __init__(self, d_model, n_head, dropout=0.1):
super().__init__()
self.dropout = nn.Dropout(dropout)
# 必须能被整除
assert d_model % n_head == 0
self.d_k = d_model // n_head
self.n_head = n_head
#
self.W_Q = nn.Linear(d_model, d_model, bias=False)
self.W_K = nn.Linear(d_model, d_model, bias=False)
self.W_V = nn.Linear(d_model, d_model, bias=False)
self.linear = nn.Linear(d_model, d_model, bias=False)
def forward(self, q, k, v):
# 分头的主要目的是让模型能够同时关注输入序列的不同部分,从而捕捉更丰富的特征
# q,k,v shape ==> batch_size,seq_len,d_model
n_batchs = q.size(0)
q_seq_len = q.size(1)
k_seq_len = k.size(1)
v_seq_len = v.size(1)
# (batch_size, seq_len, d_model) ===> (batch_size, seq_len, n_head, d_k)
# 其中 n_head 是头的数量,d_k 是每个头的维度
# #为了方便计算,需要将头的维度移到前面,变成 (batch_size, n_head, seq_len, d_k)
q = self.W_Q(q).view(n_batchs, q_seq_len, self.n_head, self.d_k).transpose(1, 2)
k = self.W_Q(k).view(n_batchs, k_seq_len, self.n_head, self.d_k).transpose(1, 2)
v = self.W_Q(v).view(n_batchs, v_seq_len, self.n_head, self.d_k).transpose(1, 2)
# 计算注意力
att = attention(q, k, v, self.dropout)
# 拼接
# contiguous()确保张量在内存中是连续存储的,提高计算效率;
concat = att.transpose(1, 2).contiguous().reshape(n_batchs, -1, self.n_head * self.d_k)
output = self.linear(concat)
return output
mha = MultHeadedAttention(8, 2)
q = k = v = torch.randn(2, 3, 8)
mha_out = mha(q, k, v)
print(mha_out)
import torch
import torch.nn as nn
class CNNWithAttention(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.conv_layers = nn.Sequential(
nn.Conv2d(3, 16, 3, bias=False),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(16, 32, 3, bias=False),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 3, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, 128, 3, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(128, 256, 3, bias=False),
nn.BatchNorm2d(256),
nn.ReLU()
)
# self.attention = nn.MultiheadAttention(embed_dim=32,num_heads=1)
self.attention = MultHeadedAttention(d_model=256, n_head=4)
self.fc = nn.Linear(400 * 256, num_classes)
def forward(self, x):
x = self.conv_layers(x)
# shape: [1,256,20,20] N C H W
x = x.permute(0, 2, 3, 1) # shape: [1,20,20,256] N H W C
x = x.reshape(x.size(0), -1, x.size(-1)) # shape: [1,400,256] N V C
# 调整为(batch_size(有多少个格子),sequence_length,embedding_dim)
x = x.permute(1, 0, 2) # shape: [400,1,256]
# x,_ = self.attention(x,x,x)
# 多头自注意力 q=k=v=x
x = self.attention(x, x, x) # shape: [400,1,256]
x = x.reshape(x.size(1), -1) # shape: [1,102400]
x = self.fc(x)
return x
# 创建模型实例
model = CNNWithAttention(6)
x = torch.randn(1, 3, 112, 112)
y = model(x)
print(y.shape)