构建AI智能体:九十四、Hugging Face 与 Transformers 完全指南:解锁现代 NLP 的强大力量
一、Hugging Face 基础介绍
1. 什么是Hugging Face
Hugging Face 是一个专注于自然语言处理(NLP)和人工智能的开源社区和平台。它提供了大量的预训练模型、数据集和工具库,可以用于各种NLP任务,如文本分类、问答、文本生成、情感分析等,使得研究人员和开发者能够轻松地使用最先进的模型。
突出优点:
- 易于使用:提供了简单的API,几行代码就可以使用最先进的模型。
- 社区支持:拥有庞大的社区,不断有新的模型和工具贡献。
- 多框架支持:支持PyTorch、TensorFlow和JAX。
- 丰富的资源:提供了数千个预训练模型和数据集。
核心组件:
- Transformers:核心库,提供了各种Transformer模型的实现。
- Datasets:提供了轻松访问和共享数据集的工具。
- Tokenizers:提供了快速的分词器。
- Accelerate:提供了简化跨GPU/TPU训练和推理的工具。

二、Transformers 库完整介绍
1. Transformers基础
Hugging Face的Transformers库是一个用于自然语言处理(NLP)的库,它提供了数千个预训练模型,并且支持PyTorch、TensorFlow和JAX三大深度学习框架。它的设计理念是让用户能够轻松地使用和部署最先进的Transformer模型。
它通过提供统一的API,使得用户无论使用哪种框架,都可以用相同的方式加载、训练和推理模型。这种设计极大地简化了模型的使用和实验过程。
Transformers 库的工作流程:
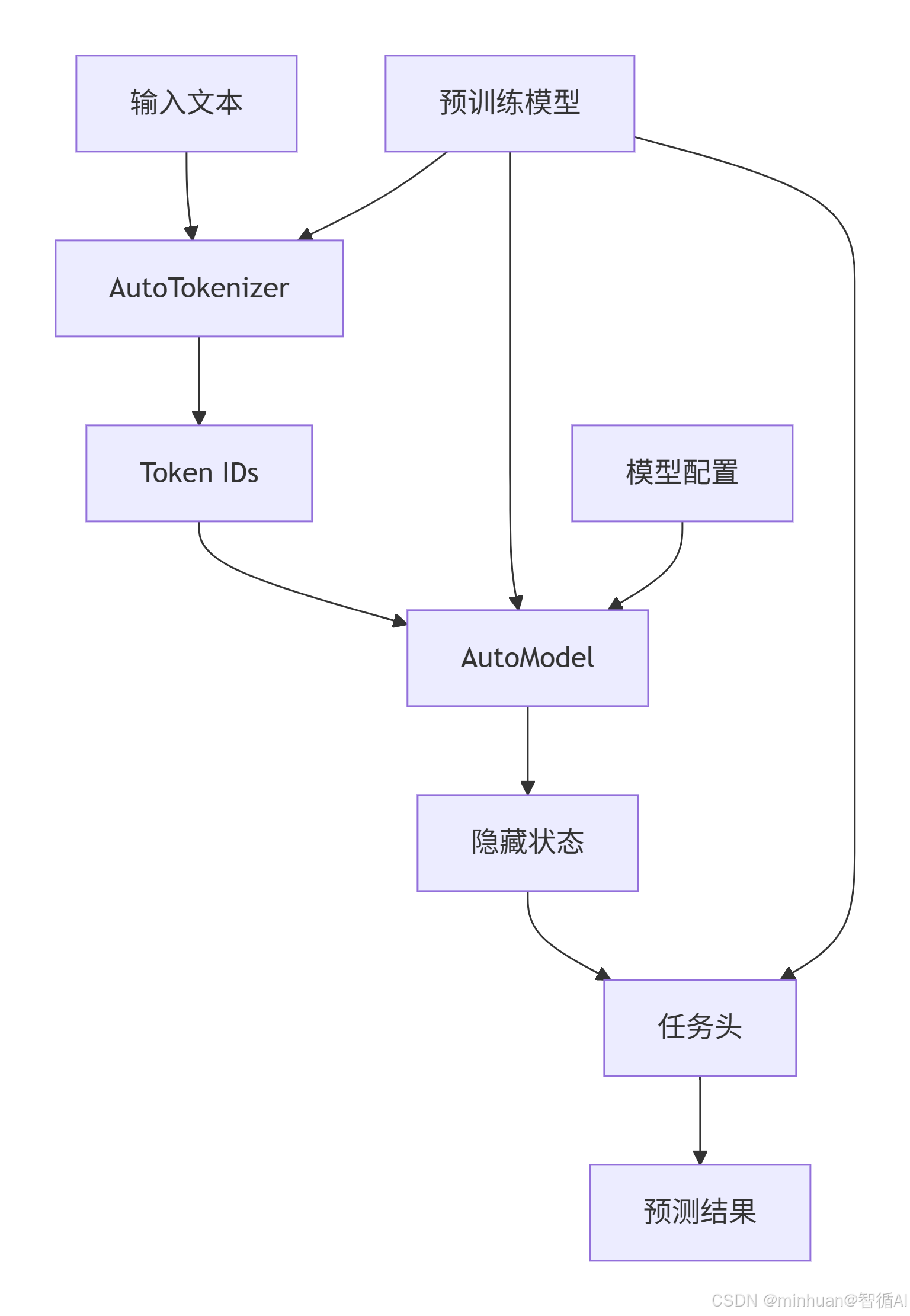
1.1 模型选择策略
按任务类型选择
- 文本分类任务 - 情感分析、主题分类等
- 适合模型: BERT, RoBERTa, DistilBERT, DeBERTa
- 示例模型: "bert-base-uncased", "roberta-base", "distilbert-base-uncased"
- 文本生成任务 - 对话、创作、补全
- 适合模型: GPT-2, GPT-Neo, T5, BART
- 示例模型: "gpt2", "EleutherAI/gpt-neo-1.3B", "t5-small"
- 序列标注任务 - 命名实体识别、词性标注
- 适合模型: BERT, RoBERTa, ELECTRA
- 示例模型: "dslim/bert-base-NER", "bert-base-uncased"
- 问答任务 - 阅读理解、问题回答
- 适合模型: BERT, RoBERTa, ALBERT
- 示例模型: "bert-large-uncased-whole-word-masking-finetuned-squad"
- 多语言任务 - 跨语言理解
- 适合模型: XLM-RoBERTa, mBERT
- 示例模型: "xlm-roberta-base", "bert-base-multilingual-uncased"
按资源约束选择
- 资源充足情况 - 追求最佳性能
- 大型模型: "roberta-large", "bert-large", "gpt2-xl"
- 平衡情况 - 性能与效率兼顾
- 中型模型: "bert-base", "roberta-base", "distilbert-base"
- 资源受限情况 - 移动端、边缘设备
- 小型模型: "distilbert-base", "albert-base", "tiny-bert"
1.2 模型使用流程
步骤1:导入和模型选择
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
import numpy as np# 情景:我们要做一个中文情感分析应用
# 选择模型考虑因素:
# 1. 任务:情感分析 → 序列分类
# 2. 语言:中文 → 需要中文预训练模型
# 3. 资源:希望快速响应 → 选择轻量模型# 从 Hugging Face Hub 选择模型
model_name = "bert-base-chinese" # 基础中文BERT模型print(f"正在加载模型: {model_name}")
print("这个模型适合处理中文文本的分类任务")# 加载分词器 - 为什么需要分词器?
# 中文文本 → 模型理解的数字ID
tokenizer = AutoTokenizer.from_pretrained(model_name)# 加载模型 - 为什么用 AutoModelForSequenceClassification?
# 因为我们要做分类任务,这个类在BERT基础上添加了分类头
model = AutoModelForSequenceClassification.from_pretrained(model_name,num_labels=3, # 3个分类:正面、负面、中性id2label={0: "负面", 1: "中性", 2: "正面"}, # ID到标签的映射label2id={"负面": 0, "中性": 1, "正面": 2} # 标签到ID的映射
)print("模型加载完成!")
print(f"模型架构: {type(model).__name__}")
print(f"分类类别数: {model.num_labels}")步骤2:文本预处理深度解析
# 输入文本 - 用户评论
texts = ["这个产品非常好用,我非常喜欢!","质量很差,完全不推荐购买。","还可以,没什么特别的感觉。"
]print("原始文本:", texts)# 分词处理 - 逐步分析
print("\n=== 分词过程详解 ===")for i, text in enumerate(texts):print(f"\n文本 {i+1}: '{text}'")# 1. 基础分词tokens = tokenizer.tokenize(text)print(f"分词结果: {tokens}")# 2. 转换为IDinput_ids = tokenizer.encode(text)print(f"输入ID: {input_ids}")# 3. 完整预处理(生产环境使用)inputs = tokenizer(text,padding=True, # 填充到相同长度truncation=True, # 截断到模型最大长度max_length=512, # 最大长度return_tensors="pt" # 返回PyTorch张量)print(f"输入字典结构: {list(inputs.keys())}")print(f"input_ids形状: {inputs['input_ids'].shape}")print(f"attention_mask形状: {inputs['attention_mask'].shape}")# 批量处理所有文本
batch_inputs = tokenizer(texts,padding=True,truncation=True, max_length=128,return_tensors="pt"
)print(f"\n批量输入形状:")
print(f"Input IDs: {batch_inputs['input_ids'].shape}")
print(f"Attention Mask: {batch_inputs['attention_mask'].shape}")步骤3:模型推理和输出解析
# 模型推理 - 详细步骤
print("\n=== 模型推理过程 ===")# 设置为评估模式(关闭dropout等训练专用层)
model.eval()# 不计算梯度,节省内存和计算资源
with torch.no_grad():# 模型前向传播outputs = model(**batch_inputs)print("模型输出类型:", type(outputs))print("输出属性:", outputs.keys())# 获取logits(未归一化的分数)logits = outputs.logitsprint(f"Logits形状: {logits.shape}") # [批次大小, 类别数]# 转换为概率probabilities = torch.nn.functional.softmax(logits, dim=-1)print(f"概率分布: {probabilities}")# 获取预测结果predictions = torch.argmax(logits, dim=-1)print(f"预测类别ID: {predictions}")print("\n=== 结果解析 ===")
# 详细解析每个预测结果
for i, (text, pred_id, prob) in enumerate(zip(texts, predictions, probabilities)):predicted_label = model.config.id2label[pred_id.item()]confidence = prob[pred_id].item()print(f"\n文本 {i+1}: '{text}'")print(f"预测情感: {predicted_label}")print(f"置信度: {confidence:.3f}")print(f"所有类别概率: { {model.config.id2label[j]: prob[j].item():.3f} for j in range(len(prob)) }")2. 主要组件
Transformers库主要由以下几个组件构成:
- 模型(Models): 提供了各种Transformer架构的预训练模型,如BERT、GPT、T5、RoBERTa等。
- 分词器(Tokenizers): 负责将原始文本转换为模型可以处理的数字形式。它支持多种分词算法,如BPE、WordPiece、SentencePiece等。
- 配置(Configs): 保存模型的配置信息,如层数、隐藏层维度等。通过配置,用户可以轻松地调整模型结构。
3. 调用方式
3.1 使用Pipeline
Pipeline是Transformers库中一个高级工具,它将数据预处理、模型推理和后处理三个步骤封装成一个简单的API。使用Pipeline,用户只需几行代码就可以完成复杂的NLP任务。
Pipeline的设计目的是为了简化模型的使用,让用户无需关心底层的细节,例如如何预处理数据、如何调用模型、如何将模型输出转换为可读的结果。它提供了一种“箱即用的体验。它适用于快速进行推理,并将一个复杂任务的三个步骤封装为一体。

3.1.1 Pipeline的三个核心步骤:
3.1.1.1 预处理
- 作用:将原始文本(或图像、音频等)转换为模型可以理解的格式。对于NLP任务,这通常包括分词、将分词结果转换为ID、填充或截断序列等,它不仅仅是简单地按空格分词,还处理子词、特殊标记等。
- 关键步骤:
- 分词:将句子拆分成词或子词。
- 添加特殊标记:如 [CLS](分类开始)、[SEP](分隔符)。
- Padding:将序列填充到相同长度。
- Truncation:截断过长的序列。
- Attention Mask:告诉模型哪些 token 是真实的,哪些是填充的。
from transformers import AutoTokenizercheckpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)text = "Hello, my dog is cute."
inputs = tokenizer(text, padding=True, truncation=True, return_tensors="pt") # 返回PyTorch张量
# 如果是TensorFlow,则使用 return_tensors="tf"print(inputs)
# {
# 'input_ids': tensor([[ 101, 7592, 1010, 2026, 3899, 2003, 10140, 1012, 102]]),
# 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0]]),
# 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1]])
# }3.1.1.2 模型推理
- 作用:将预处理后的数据输入模型,得到模型的输出。
- AutoModel 是一个通用的模型加载类,可以根据 checkpoint 名称自动推断模型架构。
- 不同的任务有对应的 AutoModel 子类:
- AutoModelForSequenceClassification:用于文本分类。
- AutoModelForTokenClassification:用于命名实体识别。
- AutoModelForCausalLM:用于因果语言模型(如 GPT)。
- AutoModelForQuestionAnswering:用于问答。
from transformers import AutoModelForSequenceClassification
import torchmodel = AutoModelForSequenceClassification.from_pretrained(checkpoint)with torch.no_grad():outputs = model(**inputs)logits = outputs.logits
print(logits)
# tensor([[ 0.1, -0.2]]) # 假设是二分类,输出两个类别的原始分数# 通过 softmax 得到概率
probabilities = torch.softmax(logits, dim=1)
print(probabilities)
# tensor([[0.5744, 0.4256]])3.1.1.3 后处理
- 作用:将模型的原始输出(如logits)转换为人类可读的格式,例如将logits转换为概率分布,然后找到对应的标签。
predicted_class_id = logits.argmax().item()
model.config.id2label[predicted_class_id] # 通过模型配置将id映射回标签名,例如 ‘POSITIVE’3.1.2 一个命名实体识别的示例:
from transformers import pipeline# 创建命名实体识别管道
ner = pipeline('ner')
# 内部步骤:
# 1. 自动选择默认模型
# 2. 加载对应的 tokenizer
# 3. 加载对应的模型
# 4. 设置任务特定的后处理器# 对文本进行命名实体识别
result = ner('Hugging Face is a company based in New York.')
for entity in result:print(entity)运行输出:
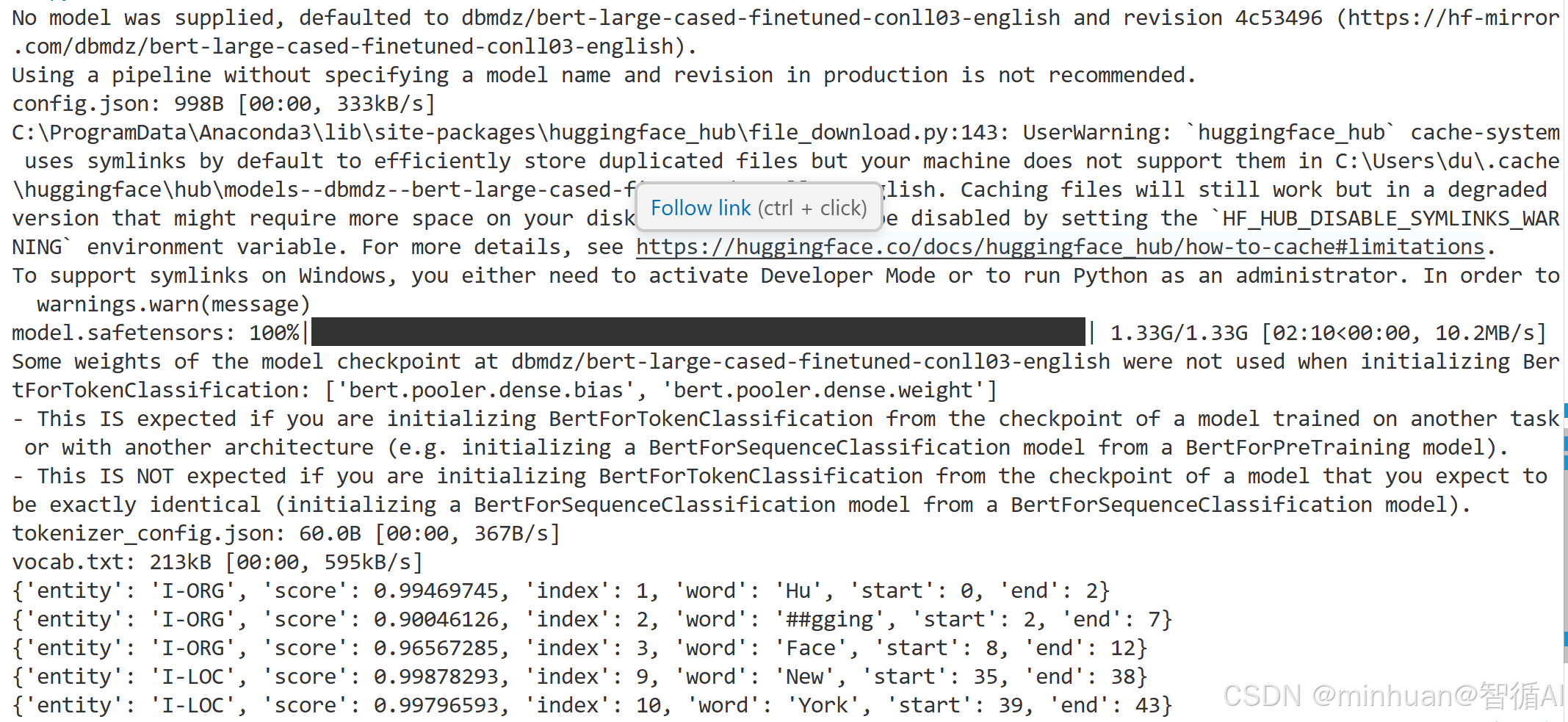
详细分析输出内容可知,在没有指定模型的情况下,会自动匹配一个与类型相关的默认模型,先进行下载后加载再执行指定任务。
3.1.3 Pipeline支持的常见任务:
Transformers库的Pipeline支持多种任务,包括但不限于:
- 文本分类(Text Classification):例如情感分析。
- 文本生成(Text Generation):根据提示生成文本。
- 命名实体识别(Named Entity Recognition, NER):识别文本中的实体(如人名、地点等)。
- 问答(Question Answering):给定问题和上下文,提取答案。
- 摘要(Summarization):生成文本的摘要。
- 翻译(Translation):将一种语言翻译成另一种语言。
- 特征提取(Feature Extraction):获取文本的向量表示。
- 掩码语言模型(Masked Language Modeling):填充文本中的掩码词。
3.1.4 创建Pipeline的两种方式:
- 1. 使用任务名称:如上例中的pipeline("ner"),库会自动选择一个默认的模型。
- 2. 指定模型和任务:用户可以指定一个具体的模型和任务,例如:
classifier = pipeline("text-classification", model="模型名称")3.1.5 Pipeline参数说明
基础任务参数:
from transformers import pipeline# 最基本的初始化
classifier = pipeline(task="sentiment-analysis", # 必需:任务类型model="distilbert-base-uncased-finetuned-sst-2-english", # 可选:模型名称tokenizer=None, # 可选:分词器(默认使用模型的)framework=None, # 可选:框架 "pt" 或 "tf"device=None, # 可选:设备 -1(CPU), 0(GPU0), 1(GPU1)device_map="auto", # 可选:多GPU设备映射
)模型与设备参数:
# 设备管理参数
pipe = pipeline("text-generation",device=0, # 使用第一个GPU,-1表示CPUdevice_map="auto", # 自动在多GPU间分配模型层# device_map="balanced" # 平衡分配到所有GPU# device_map={"transformer.h.0": 0, "transformer.h.1": 1} # 手动指定层到设备
)# 模型精度与内存优化
pipe = pipeline("text2text-generation",model="t5-base",torch_dtype=torch.float16, # 半精度,减少内存使用# torch_dtype=torch.bfloat16, # Brain Float 16,在某些硬件上性能更好low_cpu_mem_usage=True, # 减少模型加载时的CPU内存占用trust_remote_code=True, # 信任自定义模型代码
)批次与性能参数:
pipe = pipeline("feature-extraction",batch_size=32, # 批次大小,影响内存使用和速度model_kwargs={ # 传递给模型初始化的参数"output_attentions": True,"output_hidden_states": True}
)3.1.6 Pipeline 任务类型示例
from transformers import pipeline# 1. 文本分类 Pipeline
print("=== 文本分类 ===")
classifier = pipeline("text-classification", model="bert-base-chinese")
result = classifier("这部电影的剧情非常精彩,演员表演出色!")
print(f"情感分析结果: {result}")# 2. 文本生成 Pipeline
print("\n=== 文本生成 ===")
generator = pipeline("text-generation", model="gpt2",tokenizer="gpt2")
result = generator("人工智能的未来发展", max_length=50,num_return_sequences=1)
print(f"生成文本: {result[0]['generated_text']}")# 3. 命名实体识别 Pipeline
print("\n=== 命名实体识别 ===")
ner = pipeline("ner",model="dslim/bert-base-NER",aggregation_strategy="simple")
result = ner("马云在杭州创办了阿里巴巴集团。")
print("识别到的实体:")
for entity in result:print(f"- {entity['word']} ({entity['entity_group']}) - 置信度: {entity['score']:.3f}")# 4. 问答系统 Pipeline
print("\n=== 问答系统 ===")
qa = pipeline("question-answering",model="bert-large-uncased-whole-word-masking-finetuned-squad")
context = """
华为技术有限公司成立于1987年,总部位于中国深圳市。
创始人任正非最初投资了2.1万元人民币创建了这家公司。
华为是全球领先的信息与通信技术解决方案提供商。
"""
question = "华为公司是哪一年成立的?"
result = qa(question=question, context=context)
print(f"问题: {question}")
print(f"答案: {result['answer']}")
print(f"置信度: {result['score']:.3f}")# 5. 文本摘要 Pipeline
print("\n=== 文本摘要 ===")
summarizer = pipeline("summarization",model="facebook/bart-large-cnn")
long_text = """
人工智能是计算机科学的一个分支,它企图了解智能的实质,
并生产出一种新的能以人类智能相似的方式做出反应的智能机器,
该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。
人工智能从诞生以来,理论和技术日益成熟,应用领域也不断扩大,
可以设想,未来人工智能带来的科技产品,将会是人类智慧的容器。
"""
result = summarizer(long_text, max_length=50, min_length=25,do_sample=False)
print(f"原文长度: {len(long_text)} 字符")
print(f"摘要结果: {result[0]['summary_text']}")# 6. 翻译 Pipeline
print("\n=== 机器翻译 ===")
# 英译中
translator = pipeline("translation", model="Helsinki-NLP/opus-mt-en-zh")
result = translator("Hello, how are you today? I hope you're doing well.")
print(f"英文原文: Hello, how are you today?")
print(f"中文翻译: {result[0]['translation_text']}")# 7. 特征提取 Pipeline
print("\n=== 文本特征提取 ===")
feature_extractor = pipeline("feature-extraction",model="bert-base-uncased")
result = feature_extractor("这是一个示例文本")
print(f"特征形状: {np.array(result).shape}") # [序列长度, 隐藏维度]3.2 使用AutoClass
AutoClass是一个智能的类,可以根据模型名称自动推断出正确的模型架构和分词器,它是 Hugging Face Transformers 库中一系列自动配置类的统称,它们的设计初衷是为了让用户能够通过模型名称(或路径)自动加载对应的预训练模型、分词器、配置等,而无需显式指定模型架构。
在 Transformers 库中,每个模型架构都有对应的模型类(如 BertForSequenceClassification)和分词器类(如 BertTokenizer)。然而,随着模型数量的增加,手动管理这些类变得繁琐。AutoClass 通过一个统一的接口,根据模型标识符自动推断并返回正确的类。
3.2.1 AutoClass的优势:
假设我们有三个不同的模型,分别基于 BERT、RoBERTa 和 DistilBERT,它们都适用于序列分类任务。如果没有 AutoClass,我们需要根据模型类型分别加载:
from transformers import BertTokenizer, BertForSequenceClassification
from transformers import RobertaTokenizer, RobertaForSequenceClassification
from transformers import DistilBertTokenizer, DistilBertForSequenceClassificationmodel_name = "bert-base-uncased" # 可能是 "roberta-base" 或 "distilbert-base-uncased"if "bert" in model_name:tokenizer = BertTokenizer.from_pretrained(model_name)model = BertForSequenceClassification.from_pretrained(model_name)
elif "roberta" in model_name:tokenizer = RobertaTokenizer.from_pretrained(model_name)model = RobertaForSequenceClassification.from_pretrained(model_name)
elif "distilbert" in model_name:tokenizer = DistilBertTokenizer.from_pretrained(model_name)model = DistilBertForSequenceClassification.from_pretrained(model_name)这样的代码不仅冗长,而且难以维护。使用 AutoClass,我们可以简化为:
from transformers import AutoTokenizer, AutoModelForSequenceClassificationmodel_name = "bert-base-uncased" # 也可以是 "roberta-base" 或 "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)3.2.2 常用的 AutoClass:
AutoTokenizer:分词器负责将原始文本转换为模型可以理解的 token ID,并通常处理填充、截断和注意力掩码。
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
text = "Hello, world!"
encoded_input = tokenizer(text, padding=True, truncation=True, return_tensors="pt")AutoConfig:配置类用于加载模型的配置信息,包括隐藏层维度、注意力头数等。有时我们只需要模型的配置,而不需要加载整个模型。
from transformers import AutoConfigconfig = AutoConfig.from_pretrained("bert-base-uncased")
print(config)输出内容:
BertConfig {
"_name_or_path": "bert-base-uncased",
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"transformers_version": "4.46.3",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 30522
}
AutoModel:用于加载模型,但不包含特定的任务头。它返回模型的基类,通常用于特征提取或当你想自定义任务头时。
from transformers import AutoModelmodel = AutoModel.from_pretrained("bert-base-uncased")3.2.3 任务特定的 AutoModel
对于下游任务,我们通常使用带有任务头的模型。以下是一些常见的任务特定 AutoModel:
3.2.3.1 AutoModelForSequenceClassification:用于文本分类
from transformers import AutoModelForSequenceClassification# 加载分类模型
model = AutoModelForSequenceClassification.from_pretrained("uer/roberta-base-finetuned-dianping-chinese"
)# 推理示例
inputs = tokenizer("今天的天气特别晴朗!", return_tensors="pt")
outputs = model(**inputs)# 输出是 logits,需要 softmax 转换为概率
logits = outputs.logits
probabilities = torch.softmax(logits, dim=-1)
print(f"分类概率: {probabilities}")3.2.3.2 AutoModelForTokenClassification:用于命名实体识别(NER)等 token 级别的分类
from transformers import AutoModelForTokenClassification# 加载 NER 模型
model = AutoModelForTokenClassification.from_pretrained("uer/roberta-base-finetuned-dianping-chinese"
)# NER 推理
text = "今天天气晴好,我们去爬山."
inputs = tokenizer(text, return_tensors="pt")
outputs = model(**inputs)predictions = torch.argmax(outputs.logits, dim=-1)
tokens = tokenizer.convert_ids_to_tokens(inputs["input_ids"][0])print("Token 级别预测:")
for token, pred in zip(tokens, predictions[0]):print(f"{token:15} -> {model.config.id2label[pred.item()]}")3.2.3.3 AutoModelForQuestionAnswering:用于问答任务
from transformers import AutoModelForQuestionAnswering
from transformers import AutoTokenizer
import torch# 基本用法
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")# 加载 QA 模型
model = AutoModelForQuestionAnswering.from_pretrained("distilbert-base-cased-distilled-squad"
)# 问答示例
question = "What is the capital of France?"
context = "Paris is the capital and most populous city of France."
inputs = tokenizer(question, context, return_tensors="pt")outputs = model(**inputs)
start_scores = outputs.start_logits
end_scores = outputs.end_logits# 找到答案的起始和结束位置
start_idx = torch.argmax(start_scores)
end_idx = torch.argmax(end_scores) + 1answer_tokens = inputs["input_ids"][0][start_idx:end_idx]
answer = tokenizer.decode(answer_tokens)
print(f"问题: {question}")
print(f"答案: {answer}")3.2.3.4 AutoModelForCausalLM:用于因果语言建模
from transformers import AutoModelForCausalLM
from transformers import AutoTokenizer
import torch# 基本用法
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")# 加载文本生成模型
model = AutoModelForCausalLM.from_pretrained("gpt2")# 文本生成
input_text = "The future of artificial intelligence"
inputs = tokenizer(input_text, return_tensors="pt")# 生成文本
outputs = model.generate(inputs["input_ids"],max_length=100,num_return_sequences=1,temperature=0.7,do_sample=True
)generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"生成文本: {generated_text}")3.2.3.5 AutoModelForMaskedLM:用于掩码语言建模(如 BERT)
from transformers import AutoModelForCausalLM
from transformers import AutoTokenizer
import torch# 基本用法
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")# 加载文本生成模型
model = AutoModelForCausalLM.from_pretrained("gpt2")# 文本生成
input_text = "The future of artificial intelligence"
inputs = tokenizer(input_text, return_tensors="pt")# 生成文本
outputs = model.generate(inputs["input_ids"],max_length=100,num_return_sequences=1,temperature=0.7,do_sample=True
)generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"生成文本: {generated_text}")3.2.3.6 AutoModelForSeq2SeqLM:用于序列到序列任务(如 T5、BART)
from transformers import AutoModelForSeq2SeqLM
from transformers import AutoTokenizer
import torch# 基本用法
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")# 加载序列到序列模型
model = AutoModelForSeq2SeqLM.from_pretrained("t5-small")# 摘要示例
text = """
The Hugging Face Transformers library provides thousands of pretrained models
to perform tasks on different modalities such as text, vision, and audio.
"""inputs = tokenizer("summarize: " + text, return_tensors="pt", max_length=512, truncation=True)
outputs = model.generate(inputs["input_ids"],max_length=150,min_length=40,length_penalty=2.0,num_beams=4,early_stopping=True
)summary = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"原文: {text}")
print(f"摘要: {summary}")3.2.4 AutoClass 的底层机制
AutoClass 的核心是 from_pretrained 方法,该方法执行以下步骤:
- 从 Hugging Face Hub 或本地路径获取模型配置。
- 根据配置中的 model_type 字段(例如 "bert"、"roberta")确定要实例化的具体类。
- 加载预训练权重并初始化模型。
例如,当使用 AutoModel.from_pretrained("bert-base-uncased") 时,库会检查配置中的 model_type 为 "bert",然后实际返回 BertModel 类的实例。
3.2.5 AutoClass 的实际应用场景
模型比较与基准测试:
from transformers import AutoModel, AutoTokenizer
import time
from typing import List, Dictclass ModelBenchmark:"""模型性能基准测试"""def __init__(self):self.results = {}def benchmark_models(self, model_names: List[str], text: str, num_runs: int = 10):"""对多个模型进行基准测试"""for model_name in model_names:print(f"\n🧪 测试模型: {model_name}")try:# 加载模型和分词器tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModel.from_pretrained(model_name)# 预热inputs = tokenizer(text, return_tensors="pt")_ = model(**inputs)# 计时推理start_time = time.time()for _ in range(num_runs):inputs = tokenizer(text, return_tensors="pt")outputs = model(**inputs)end_time = time.time()avg_time = (end_time - start_time) / num_runsself.results[model_name] = {'avg_time': avg_time,'throughput': 1 / avg_time,'success': True}print(f" 平均推理时间: {avg_time:.4f}s")print(f" 吞吐量: {1/avg_time:.2f} requests/s")except Exception as e:print(f" 测试失败: {e}")self.results[model_name] = {'success': False, 'error': str(e)}return self.results# 使用示例
benchmark = ModelBenchmark()
models = ["bert-base-uncased", "distilbert-base-uncased", "roberta-base"]
text = "This is a sample text for benchmarking transformer models."results = benchmark.benchmark_models(models, text)三、总结
Hugging Face 通过其 transformers 库和强大的生态系统,成功地统一并简化了现代 NLP 模型的访问和使用。从几行代码实现复杂任务的 pipeline,到允许深度定制的模块化组件,它满足了从初学者到资深研究者的不同需求。
- 从 pipeline 开始:快速验证想法和构建原型。
- 理解 Tokenizer 和 Model:当需要自定义处理逻辑时,这是必经之路。
- 善用 AutoClass:使你的代码与具体模型架构解耦,更具通用性。