融合尺度感知注意力、多模态提示学习与融合适配器的RGBT跟踪
融合尺度感知注意力、多模态提示学习与融合适配器的RGBT跟踪
Scale-Aware Attention and Multi-Modal Prompt Learning with Fusion Adapter for RGBT Tracking
作者: Xiang Liu, Haiyan Li, Victor Sheng, Yujun Ma, Xiaoguo Liang, and Guanbo Wang
发表期刊: IEEE TRANSACTIONS ON MULTIMEDIA
论文地址: https://ieeexplore.ieee.org/document/11207526
摘要—在计算机视觉领域,融合可见光(RGB)与热成像(T)图像进行RGBT跟踪已引起日益增长的关注。然而,如何提高跟踪器对目标尺度变化的鲁棒性、如何将视觉提示有效应用于多模态跟踪任务,以及如何增强多模态融合的有效性,仍然是RGBT跟踪领域亟待解决的挑战。为此,本文提出了一种名为MPANet的RGBT跟踪框架,该框架集成了尺度感知扩张注意力、多模态提示交互学习和交叉融合适配器。首先,提出了一种尺度感知扩张注意力(SADA)模块,它通过将具有不同扩张率的卷积嵌入到自注意力机制中,来增强跟踪器在目标尺度变化情况下的灵活性。随后,构建了一个多模态提示交互学习(MPIL)模块,该模块结合了全局令牌自适应注意力和空间注意力,以高效地从不同模态中学习视觉提示,并实现模态间的提示交互。最后,开发了一种交叉融合适配器(CFA),通过适配器机制促进网络在多模态信息融合过程中对不同模态的适应性。在GTOT、RGBT234、LasHeR和VTUAV等公开RGBT基准跟踪数据集上进行的大量实验表明,所提出的方法优于现有的先进跟踪器,并达到了最先进的性能。
索引术语—RGBT跟踪,尺度感知注意力,视觉提示学习,多模态融合。
I. 引言
目标跟踪的目标是在给定初始状态的情况下,准确、持续地预测物体在后续视频序列中的状态 [1], [2]。作为计算机视觉的下游任务之一,目标跟踪在自动驾驶 [3]、智能安防 [4] 和人机交互 [5] 等众多领域具有重大的研究意义和应用价值。基于可见光图像的现有跟踪器,其鲁棒性和准确性已取得了优异的成就,尤其是在深度神经网络 [6] 快速发展和推广的背景下。然而,在极端光照和恶劣天气条件下,可见光图像所包含的外观信息容易丢失。与可见光图像相比,热红外图像侧重于捕捉目标温度信息,对光照相对不敏感,但它也存在热交叉现象 [7]。因此,利用多传感器信息的互补优势,融合可见光与红外图像数据以执行鲁棒的多模态目标跟踪,已得到广泛研究,并且是当前目标跟踪领域的主要研究热点 [8]。
现有的RGBT跟踪器可分为两类:基于传统的方法和基于深度学习的方法 [9]。基于传统的方法 [10], [11], [12], [13] 利用相关滤波来计算相似度。然而,这类方法依赖于手工提取的特征,成本更高且准确性较低。随着强大的卷积神经网络和视觉Transformer [14] 的相继出现,基于深度学习的RGBT跟踪已成为当前最主流的跟踪范式。然而,这类方法需要大量数据进行训练以提高模型的鲁棒性,而现有的多模态数据集规模相对较小,无法真正满足多模态跟踪的需求。
近年来,视觉提示技术为解决此类问题提供了新的思路。受自然语言处理(NLP)领域提示微调 [15] 的启发,研究人员开始将视觉提示应用于目标跟踪,这为多模态跟踪开创了一个新颖的视角。ProTrack [16] 通过提示范式将多模态输入转换为单模态,以适配先进的RGB跟踪器。然而,它缺乏有效融合模块的构建,导致多模态信息未能有效融合。ViPT [17] 通过冻结基础模型并学习特定于模态的视觉提示来完成模态自适应,同时引入辅助模态输入,在提示调整过程中学习不同模态之间的相关性。然而,用相同的主干网络处理不同模态的方式,使得模态间具有互补属性的模态差异未能得到充分挖掘。
尽管视觉提示已使RGBT跟踪器取得了显著的性能提升,但现有方法仍面临三个关键挑战。首先,这些方法通常采用视觉Transformer(ViT)[14] 作为特征提取器。然而,其固有的架构特性导致其缺乏建模多尺度信息的能力,并且在处理不同尺度和形状的目标时不够灵活。其次,现有的视觉提示学习要么局限于模型的输入端,要么在特征提取过程中缺乏深度的交互和增强机制,从而导致不同模态的视觉提示之间缺乏有效的信息交互。第三,单一ViT主干网络的特征提取和学习方法导致未能有效学习不同模态间的差异性。同时,广泛采用的多模态融合策略,如直接拼接、简单相加或基本的交叉注意力,往往忽略了不同模态数据的内在特性,未能充分利用模态间的互补信息,导致对不同模态的适应性较差。这些问题亟待在多模态跟踪领域得到解决。
为系统地解决上述挑战,我们提出了一种融合尺度感知扩张注意力(SADA)、多模态提示交互学习(MPIL)和交叉融合适配器(CFA)的RGBT跟踪方法。具体来说,我们提出了尺度感知扩张注意力模块,该模块通过在多头自注意力中结合具有不同扩张率的扩张卷积来提取多尺度信息,以提高跟踪器对不同尺度目标的鲁棒性。其次,我们在由ViT组成的双分支主干网络的每一层Transformer编码器之间嵌入了我们提出的多模态提示交互学习模块,该模块结合了全局令牌自适应注意力和空间注意力,主要设计用于学习不同模态的提示并实现模态间的提示交互。此后,我们开发了模态交叉融合适配器,将其引入现有的交叉注意力融合方法中,以增加网络在多模态信息交叉融合过程中对不同模态的适应性。
最终,我们在包括GTOT [18]、RGBT234 [19]、LasHeR [20] 和VTUAV [21] 在内的多个RGBT基准公开数据集上对所提出的方法进行了综合评估,并与几种现有的最先进的RGBT跟踪方法进行了比较。评估和比较结果清楚地表明,我们的方法在所有数据集上都取得了最先进的跟踪性能。此外,在LasHeR数据集上,我们提出的MPANet实现了29 FPS的跟踪速度,这不仅满足了实际应用的需求,也揭示了其在多模态跟踪领域的巨大潜力,如图1所示。此外,我们进一步在LasHeR训练集上验证了每个提出模块的有效性,消融实验的结果表明,每个提出的模块都能有效提升跟踪性能。
本文的主要贡献总结如下:
(1)我们提出了一个尺度感知扩张注意力(SADA)模块,以提高跟踪器对不同尺度目标的鲁棒性。
(2)我们设计了一个多模态提示交互学习(MPIL)模块,以实现模态间的视觉提示交互,同时在该模块中结合了我们提出的全局令牌自适应注意力和空间注意力,以学习和增强特定模态的提示。
(3)我们构建了一个交叉融合适配器(CFA),以解决现有交叉注意力融合方案中对不同模态适应性较差的问题。
(4)在多个基准公开RGBT跟踪数据集上的实验评估结果清楚地表明,与现有的先进RGBT跟踪方法相比,所提出的方法取得了最先进的性能,证明了所提方法的有效性和鲁棒性。
II. 相关工作
本节重点回顾和概述与本工作相关的几项研究成果:RGBT跟踪、视觉提示学习和多模态融合。
A. RGBT跟踪
深度学习和神经网络的兴起推动了目标检测 [22] 和视觉目标跟踪 [23] 领域的快速发展,特别是Transformer架构、全面微调和提示学习等技术的引入,进一步加速了这一进程并带来了显著的性能提升。UniTrack [24] 甚至通过设计一个与任务无关的外观建模框架,成功地将单目标跟踪(SOT)和多目标跟踪(MOT)等多种跟踪任务整合到单一系统中,并取得了与特定任务方法相媲美的结果。然而,仅依赖可见光图像的单模态方法易受不可控环境因素的影响,其跟踪能力受到限制。考虑到可见光和红外图像之间显著的信息互补性,在多样化应用需求的推动下,RGBT多模态跟踪作为一项重要的视觉跟踪下游任务,近年来获得了广泛关注。
目前,RGBT跟踪研究分为两大类:基于传统算法的方法和基于深度学习的方法 [9],后者因其前沿性和高效率已成为研究的焦点。传统的RGBT跟踪方法 [10], [11], [25], [13] 通常依赖相关滤波和稀疏表示来衡量目标之间的相似性,然而,由于它们高度依赖手工设计的特征,不仅成本高,而且特征表示能力弱,难以适应复杂多变的真实世界环境。相比之下,基于深度学习的方法凭借卷积神经网络和Transformer架构强大的特征提取能力,展现出更强的竞争力。例如,一些研究已将经典VGG网络 [26] 的变体与一个由区域提议网络(RPN)组成的多域网络应用于RGBT跟踪任务,并通过优化跨模态数据融合策略,取得了超越传统方法的性能。MANet [27] 通过引入多种类型的适配器,提取了共享的目标表示、模态特定信息和目标特定线索。MANet++ [28] 在此基础上通过融合各个模态的先前特征来增强跟踪性能。DMCNet [29] 通过设计门控机制和相互调节模块来促进模态融合。然而,所有这些方法都通过简单的拼接方式实现模态融合,忽略了每个模态相对重要性的潜在差异。为了提升跟踪性能,M5L [30] 设计了边缘结构损失和质量感知聚合模块,MaCNet [31] 设计了模态感知注意力网络和竞争性学习策略,DRGCNet [32] 提出了模态差异强化和全局挖掘协同网络。然而,这些方法都没有对聚合后的特征进行进一步学习和增强,未能充分挖掘深度语义特征的细节和丰富性。此外,一些工作试图通过考虑数据集中标签的特定属性和挑战来提高跟踪性能。例如,CAT [33] 提出了挑战感知网络,以分别处理模态共享和模态特定的挑战,而ADRNet [34] 设计了属性驱动的残差分支和属性集成网络,以适应与属性无关的跟踪。然而,每个模态特征的独立提取和直接拼接未能充分促进模态间的信息交互,也未能最大化多模态融合的优势。APFNet [35] 设计了五个特定于属性的融合分支和一个自适应聚合模块来应对不同的挑战,并在Transformer中采用编码和解码结构进行特征的融合与增强。然而,该方法在处理具有挑战属性的数据集时效果不佳,同时泛化能力有限,单向融合策略限制了某些模态的特征表示能力。
最近,视觉提示学习的引入为多种视觉任务带来了性能上的飞跃。受此启发,ProTrack [16]、ViPT [17] 和 OneTracker [36] 将视觉提示学习应用于RGBT跟踪任务,并展示了显著的性能提升。然而,ProTrack将多模态输入转换为单模态虽然简化了跟踪过程,但也在一定程度上牺牲了模态特性。另一方面,ViPT设计了模态补充提示来整合辅助模态信息,以期提高跟踪精度。然而,ViPT中的不同模态共享同一个单一主干网络,这限制了模态间互补特征的充分学习。此外,ViPT缺乏多尺度信息处理模块,使其难以适应目标尺度。再者,OneTracker [36] 通过将红外、事件和深度等模态作为提示,实现了跨RGB-T、RGB-E和RGB-D的多模态跟踪的统一。然而,这种通用性可能会限制对特定模态提示的更深层次挖掘和学习,同时忽略了目标尺度的变化,导致当目标快速接近或远离相机时出现不准确的预测或目标丢失。在此基础上,SUTrack [37] 通过设计具有统一输入表示的单一模型架构,解决了由异构数据特性引起的模型碎片化问题,同时集成了任务识别训练策略和软令牌类型嵌入技术,显著增强了跟踪器的整体性能。
为了解决上述瓶颈,我们提出了一种新颖的双流框架,该框架扩展了主干网络以分别提取不同模态的特征。同时,我们提出了尺度感知扩张注意力来提取不同尺度的目标信息,随后我们创新性地引入了一个多模态提示交互学习模块来支持双向视觉提示学习。最后,我们设计了一个交叉融合适配器,在完成模态融合的同时,提高模型对不同模态的适应性。基于这些设计,我们实现了更准确、更鲁棒的RGBT跟踪。
B. 用于跟踪的视觉提示学习
提示学习起源于自然语言处理领域,通过设计或附加特定的提示来帮助预训练模型更好地适应特定的下游任务 [38],并且在少样本或零样本的情况下表现出显著优势。近年来,这一思想被引入计算机视觉领域,并发展成为视觉提示技术。VPT [39] 作为早期探索视觉领域提示学习的尝试之一,通过冻结主干网络参数并在输入空间中引入少量可学习参数,在下游任务中取得了与完全微调相当的结果。
在目标跟踪领域,研究人员已开始探索视觉提示的应用潜力。HIPTrack [40] 提出了一个历史提示网络,利用历史前景掩码和历史视觉特征为Siamese跟踪器提供全面而准确的提示信息。与此同时,EVPTrack [41] 引入了一个显式视觉提示跟踪框架,该框架通过时空令牌生成显式的光学视觉提示,以辅助当前帧的推断,并通过将多尺度信息呈现为显式视觉提示来提供多尺度模板特征,从而增强了跟踪器适应目标尺度变化的能力。然而,受限于单模态输入的固有局限性,这些方法在低光照、严重遮挡和强背景干扰等复杂环境中难以保证稳定的跟踪性能。
为解决单模态跟踪的瓶颈,研究人员开始探索视觉提示在RGBT跟踪中的应用。ProTrack [16] 开创性地将视觉提示引入RGBT跟踪。然而,其提示形式固定,未能发挥提示学习的优势。相比之下,ViPT [17] 在其主干模型中嵌入了一个模态互补提示器,以学习模态间的互补信息。尽管如此,其视觉提示学习过程是单向的,且仅限于计算像素权重,未能充分利用多模态视觉提示的潜力。TATrack [42] 通过模态补充提示器和注意力机制实现了跨模态特征交互,并结合时空信息来增强目标定位精度。BAT [43] 将视觉提示设计为用于多模态跟踪的可学习双向适配器。为了有效适应下游多模态跟踪任务,OneTracker [36] 提出了一个跨模态跟踪提示器(CMT),通过整合多模态信息的语义表示并将其与基础跟踪器的结果融合,来提升跨模态跟踪性能。然而,该提示器设计旨在完成简单的融合任务,没有对多模态提示进行进一步增强,从而限制了其实际的改进效果。
针对上述差距并最大化多模态视觉提示的潜力,我们提出的MPANet在每个Transformer编码器中嵌入了一个多模态提示交互学习模块。该模块通过全局令牌自适应注意力和空间注意力的协同作用,从多个维度强化提示信息,同时促进深度的模态间交互。这种设计不仅提高了模态特征的互补性,丰富了模态视觉提示信息,还促进了模态间的提示交互,从而实现了更准确、更鲁棒的RGBT跟踪。
C. 多模态融合
多模态融合技术旨在全面整合来自各种模态的数据,克服单模态信息不足或噪声严重等问题,从而获得全面、准确的数据处理结果。根据融合阶段的不同,多模态融合可分为三种主要类型:像素级融合、决策级融合和特征级融合。像素级融合是最基本的形式,它在数据的最基础层面,即像素级别,直接融合不同模态的原始信息。虽然这种方法直观且易于实现,但由于不同模态的图像可能存在重复信息或在分辨率、视角和光照条件上存在差异,直接融合可能会引入伪影、导致信息冗余或产生其他负面影响。另一方面,决策级融合是在各个模态独立做出决策后将其结果进行组合。这种后融合方法的问题在于,每个模态的特征提取和决策过程相互独立,缺乏必要的协同作用,这限制了模态间的互补优势。例如,DFAT [44] 提出了一种端到端的自适应决策级融合策略,但该方法仅使用RGB序列对跟踪网络进行离线训练,未能充分利用红外信息,影响了在低光照条件下的跟踪效果。
相比之下,特征级融合已成为当前多模态融合研究中最流行的方法。它通过在特征提取阶段融合不同模态的特征,使得模态间特征在融合过程中能够相互作用,形成更有效的协同效应,从而在决策前更好地结合各模态的优势,提高融合的整体性能。基于特征级融合的思想,近年来涌现了多种融合方法。例如,AMNet [45] 通过多模态特征对齐和信息匹配融合两个子模块实现了RGB和TIR特征的融合。ADRNet [34] 和 APFNet [35] 通过简单的特征拼接来融合可见光和TIR特征。SiamCDA [46] 首先通过加权跨模态残差拼接增强单模态特征,然后通过简单的级联和卷积获得融合特征。然而,这些基于拼接或相加等线性操作的方法无法充分捕捉不同模态特征之间复杂的关联和交互。为了弥补这一差距,DRGCNet [32] 通过引入一个基于交叉注意力的全局挖掘协作模块来融合RGB和TIR特征。TBSI [47] 提出了一个模板桥接搜索区域交互模块,该模块利用模板作为媒介,实现联合特征提取和跨模态交互。
总的来说,这些方法在多模态融合方面表现出三大局限性:1)对模态特性缺乏深入理解和自适应处理能力;2)融合策略过于简化,无法有效处理复杂的模态间关系;3)模态间交互机制不足,无法充分利用互补信息。为了解决这些问题,我们提出了两个关键模块:一个多模态提示交互学习(MPIL)模块和一个交叉融合适配器(CFA)。MPIL通过全局令牌自适应注意力和空间注意力的协同作用,实现了模态提示之间的深度交互和增强。同时,CFA在保持交叉注意力在特征融合中优势的同时,通过引入适配器来加强对不同模态特征的自适应处理能力。具体来说,适配器通过学习特定于模态的映射关系,提高了模型对不同模态特征的表达和理解,从而实现更精确的特征融合。这种设计不仅提升了模型对不同模态的适应性,也提高了融合特征的表示能力,从而提高了整个跟踪系统的鲁棒性和准确性。
III. 方法论
A. 架构概述
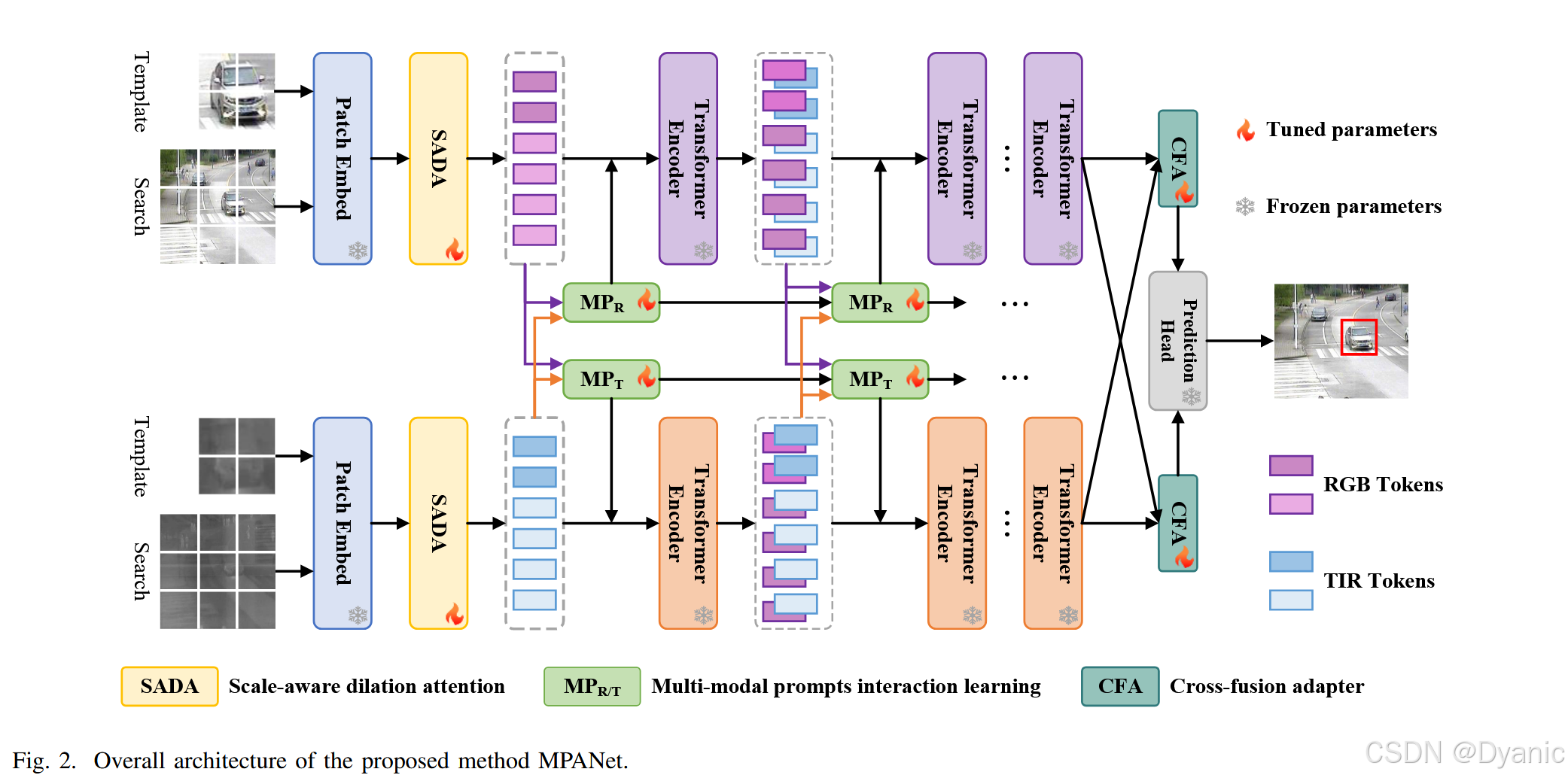
在本节中,我们将详细描述我们为RGBT跟踪任务所提出的MPANet架构。其技术流程如图2所示。具体而言,我们的框架由以下关键组件构成:用于特征提取的双流主干网络、用于捕捉多尺度目标信息的尺度感知扩张注意力、用于增强和交互不同模态间提示信息的多模态提示交互学习模块,以及用于融合从不同分支提取的模态特征的交叉融合适配器。最后,融合后的特征图通过预测头网络进行目标分类和回归。
首先,我们采用ViT并将其扩展为双流结构作为我们的主干网络,从而能够独立地从RGB和TIR图像中提取特征。MPANet的输入包括RGB和TIR模板图像,表示为 tr,tt∈RHt×Wt×3t_r, t_t \in \mathbb{R}^{H_t \times W_t \times 3}tr,tt∈RHt×Wt×3,以及搜索区域图像,表示为 sr,st∈RHs×Ws×3s_r, s_t \in \mathbb{R}^{H_s \times W_s \times 3}sr,st∈RHs×Ws×3,其中 HtH_tHt 和 WtW_tWt 表示模板图像的高度和宽度,HsH_sHs 和 WsW_sWs 代表搜索区域图像的高度和宽度。这些图像随后通过块嵌入(patch embedding)映射为令牌(token),其中 zr,zt∈RNz×Dz_r, z_t \in \mathbb{R}^{N_z \times D}zr,zt∈RNz×D 表示RGB和TIR模板令牌,xr,xt∈RNx×Dx_r, x_t \in \mathbb{R}^{N_x \times D}xr,xt∈RNx×D 表示RGB和TIR搜索区域令牌,其中 Nz=HtWt/p2N_z = H_t W_t / p^2Nz=HtWt/p2, Nx=HsWs/p2N_x = H_s W_s / p^2Nx=HsWs/p2,DDD 表示令牌维度,ppp 是块大小。
在块嵌入之后,我们引入了一个尺度感知扩张注意力模块,该模块在多头自注意力中融合了具有不同扩张率的扩张卷积,以有效捕捉来自每个模态的多尺度目标信息,从而增强跟踪器对目标尺度变化的鲁棒性。为了进一步促进模态间的提示学习,我们在每个Transformer编码器之后嵌入了一个多模态提示交互学习模块。该模块不仅提升了每个模态提示的表示能力,还促进了模态间的交互学习,从而提升了模态协同作用。随后,我们开发了一个交叉融合适配器来整合RGB和TIR特征,充分利用两种模态之间的互补信息。最后,融合后的特征图由一个结合了分类和回归功能的边界框预测网络处理,以生成最终的目标预测结果。这种设计确保了跟踪的准确性和预测的鲁棒性。
值得注意的是,在我们的方法中,多模态提示交互学习(MPIL)模块和交叉融合适配器(CFA)涉及不同层级的特征融合。MPIL模块旨在通过全局令牌自适应注意力(GTAA)和空间注意力(SA)实现多模态视觉提示的交互与增强,其中GTAA捕捉全局模态相关性,SA维持并增强空间上下文信息。这种设计使得来自RGB和TIR模态的视觉提示信息能够进行彻底的交互,从而提升每个模态提示的表示能力。另一方面,CFA模块融合了通过ViT从RGB和TIR分支提取的特征,通过适配器加强了对不同分支特征的自适应处理,同时通过交叉注意力机制实现有效的特征融合,促进了RGB和TIR模态特征之间的互补性。这种分层融合策略使得能够在不同阶段为不同目的实现特征融合,充分考虑了多模态跟踪任务的特点,并有效利用了来自不同模态的互补信息。
在接下来的章节中,我们将详细描述每个关键模块的设计,包括尺度感知扩张注意力、多模态提示交互学习模块、交叉融合适配器和边界框预测网络。通过这种方法,我们提出的方法在RGBT跟踪任务中的效率和鲁棒性得到了保证。每个组件都旨在解决特定的技术挑战,共同构成一个全面的解决方案。
B. 尺度感知扩张注意力

在RGBT场景中,目标经常表现出显著的尺度变化,而现有的基于ViT的跟踪器由于其固定的感受野限制,难以有效适应这一挑战。为解决此问题,我们创新性地提出了一个尺度感知扩张注意力(SADA)模块,该模块集成在双流框架的块嵌入层之后。如图3所示,该模块通过融合具有多尺度感受野的特征表示,提升了对目标尺度变化的适应性。
具体来说,以RGB搜索区域图像为例,从嵌入层输出的令牌 xr∈RNx×Dx_r \in \mathbb{R}^{N_x \times D}xr∈RNx×D 被重塑为 Frgb∈RHx×Wx×DF_{rgb} \in \mathbb{R}^{H_x \times W_x \times D}Frgb∈RHx×Wx×D,作为SADA的输入,其中 HxWx=NxH_x W_x = N_xHxWx=Nx 且 Hx=WxH_x = W_xHx=Wx。首先,特征图通过线性层映射以生成查询(Query)Q、键(Key)K和值(Value)V。考虑到RGBT跟踪中目标尺度变化的动态性,设计了具有三种不同扩张率 r=1,2,3r = 1, 2, 3r=1,2,3 的扩张卷积核来处理K和V,从而获得具有不同感受野的键 KrK_rKr 和值 VrV_rVr:
Q,K,V=Linear(Frgb)(1) Q, K, V = \text{Linear}(F_{rgb}) \quad (1) Q,K,V=Linear(Frgb)(1)
{Kr=DiConv(K,r),r=1,2,3Vr=DiConv(V,r),r=1,2,3(2) \begin{cases} K_r = \text{DiConv}(K, r), & r = 1, 2, 3 \\ V_r = \text{DiConv}(V, r), & r = 1, 2, 3 \end{cases} \quad (2) {Kr=DiConv(K,r),Vr=DiConv(V,r),r=1,2,3r=1,2,3(2)
这种设计使得SADA能够同时关注局部细节(r=1r=1r=1)、中等范围的上下文(r=2r=2r=2)和大规模的语义信息(r=3r=3r=3),从而有效应对目标尺度的变化。随后,通过尺度点积注意力机制,计算查询Q与扩张后的 KrK_rKr 及 VrV_rVr 之间的匹配度,以生成在不同感受野下增强的注意力特征 FAtt,rF_{Att,r}FAtt,r。这个过程可以表示为:
FAtt,r=Softmax(Q⋅KrTd)⋅Vr,r=1,2,3(3) F_{Att,r} = \text{Softmax}\left(\frac{Q \cdot K_r^T}{\sqrt{d}}\right) \cdot V_r, \quad r = 1, 2, 3 \quad (3) FAtt,r=Softmax(dQ⋅KrT)⋅Vr,r=1,2,3(3)
其中,Linear代表线性层,DiConv表示扩张卷积,rrr表示扩张率,TTT表示转置操作,ddd是KKK的维度,⋅·⋅代表矩阵乘法。这种多尺度注意力计算方法使模型能够自适应地选择最相关的尺度特征,尤其是在处理跟踪任务中目标外观变化显著的情况时。
为了充分利用不同尺度的特征信息,我们将来自不同扩张率的增强注意力特征 FAtt,rF_{Att,r}FAtt,r 进行拼接,并通过一个线性层进行映射,以获得单一的注意力增强特征 FAttF_{Att}FAtt。随后,该特征与原始输入特征 FrgbF_{rgb}Frgb 进行逐元素相加,并通过层归一化进行处理。之后,一个前馈网络对归一化后的特征进行非线性变换,接着进行另一次相加和归一化操作,以生成SADA的最终输出特征 Frgb,out∈RHx×Wx×DF_{rgb,out} \in \mathbb{R}^{H_x \times W_x \times D}Frgb,out∈RHx×Wx×D。整个过程可以形式化为:
FAtt=Linear(cat[FAtt,1,FAtt,2,FAtt,3])(4) F_{Att} = \text{Linear}(\text{cat}[F_{Att,1}, F_{Att,2}, F_{Att,3}]) \quad (4) FAtt=Linear(cat[FAtt,1,FAtt,2,FAtt,3])(4)
Frgb=LN(Frgb+FAtt)(5) F_{rgb} = \text{LN}(F_{rgb} + F_{Att}) \quad (5) Frgb=LN(Frgb+FAtt)(5)
Frgb,out=LN(Frgb+FFN(Frgb))(6) F_{rgb,out} = \text{LN}(F_{rgb} + \text{FFN}(F_{rgb})) \quad (6) Frgb,out=LN(Frgb+FFN(Frgb))(6)
其中,cat表示拼接操作,LN表示层归一化,FFN表示前馈网络。最后,我们将 Frgb,out∈RHx×Wx×DF_{rgb,out} \in \mathbb{R}^{H_x \times W_x \times D}Frgb,out∈RHx×Wx×D 特征重塑为与 xr∈RNx×Dx_r \in \mathbb{R}^{N_x \times D}xr∈RNx×D 相同的形状,以满足下一阶段的输入要求。
通过引入SADA模块,我们显著提升了对多尺度目标的跟踪鲁棒性,特别是在处理尺度变化和复杂背景干扰方面。SADA模块在RGB和TIR分支内独立运行,其中多尺度特征提取加强了每个模态内的特征表示。这种设计使得跟踪系统即使在动态目标条件下也能保持精确的跟踪性能。此外,这种新颖的架构为在挑战性场景下的RGBT跟踪任务提供了更好的适应性和准确性。
C. 多模态提示交互学习
在RGBT跟踪任务中,RGB和红外模态分别提供了关于目标外观和热辐射特征的互补信息。这种互补性使得有效利用来自两种模态的视觉线索以增强跟踪性能至关重要。虽然有效的视觉线索学习对于提高跟踪精度至关重要,但现有方法通常采用简单的融合方法,未能充分利用这些视觉线索的潜力。特别是在光照变化或部分遮挡等挑战性场景中,来自单一模态的线索可能会变得不可靠,需要深度的跨模态交互来进行相互增强和补充。
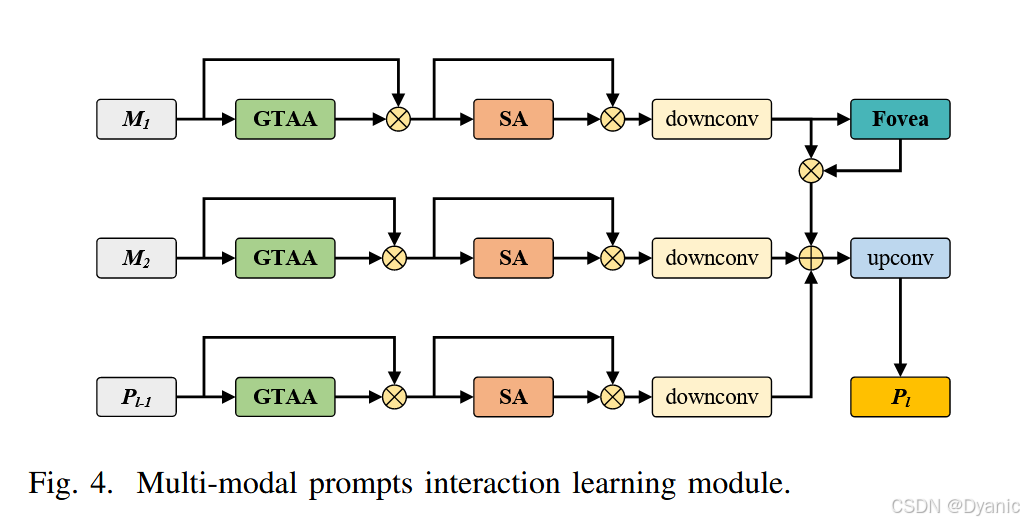
为了解决这一局限性,我们创新性地提出了一个嵌入在ViT框架内的多模态提示交互学习(MPIL)模块,实现了视觉提示的逐层学习、增强和交互,如图4所示。以第 lll 个MPIL层为例,令 M1∈RD×H1×W1M_1 \in \mathbb{R}^{D \times H_1 \times W_1}M1∈RD×H1×W1 和 M2∈RD×H2×W2M_2 \in \mathbb{R}^{D \times H_2 \times W_2}M2∈RD×H2×W2 表示从输入双模态令牌重塑后的特征,而 Pl−1∈RD×Hp×WpP_{l-1} \in \mathbb{R}^{D \times H_p \times W_p}Pl−1∈RD×Hp×Wp 表示从前一个MPIL层重塑后的提示。考虑到目标在不同模态下可能表现出不同的显著特征,不仅需要提高特定模态提示的表示能力,还需要促进有效的跨模态交互。因此,我们设计了三个并行分支,每个分支包含一个全局令牌自适应注意力(GTAA)模块和一个空间注意力(SA)模块,以独立处理这三个特征,如公式7和8所示。
{M1=M1⊙GTAA(M1)M2=M2⊙GTAA(M2)Pl−1=Pl−1⊙GTAA(Pl−1)(7) \begin{cases} M_1 = M_1 \odot \text{GTAA}(M_1) \\ M_2 = M_2 \odot \text{GTAA}(M_2) \\ P_{l-1} = P_{l-1} \odot \text{GTAA}(P_{l-1}) \end{cases} \quad (7) ⎩⎨⎧M1=M1⊙GTAA(M1)M2=M2⊙GTAA(M2)Pl−1=Pl−1⊙GTAA(Pl−1)(7)
{M1=downconv{M1⊙SA(M1)}M2=downconv{M2⊙SA(M2)}Pl−1=downconv{Pl−1⊙SA(Pl−1)}(8) \begin{cases} M_1 = \text{downconv}\{M_1 \odot \text{SA}(M_1)\} \\ M_2 = \text{downconv}\{M_2 \odot \text{SA}(M_2)\} \\ P_{l-1} = \text{downconv}\{P_{l-1} \odot \text{SA}(P_{l-1})\} \end{cases} \quad (8) ⎩⎨⎧M1=downconv{M1⊙SA(M1)}M2=downconv{M2⊙SA(M2)}Pl−1=downconv{Pl−1⊙SA(Pl−1)}(8)
其中 ⊙\odot⊙ 表示逐元素乘法,downconv\text{downconv}downconv表示下采样卷积操作。这种设计能够全面学习和增强来自每个模态的提示特征,同时通过特征交互来弥补它们各自的局限性。具体来说,我们对处理后的 M1M_1M1 应用与ViPT [17] 中相同的空间中央凹(spatial fovea)操作来计算中心注视注意力,这是一种类似于人类视觉系统的机制,有助于聚焦于目标的核心区域。随后,我们通过将处理后的 M2M_2M2 和 Pl−1P_{l-1}Pl−1 相加得到 PlP_lPl,然后将其转换为令牌表示,作为第 lll 层的模态提示。GTAA和SA模块的详细架构和实现过程将在以下部分详细阐述。
Pl=upconv{fovea(M1)+M2+Pl−1}(9) P_l = \text{upconv}\{\text{fovea}(M_1) + M_2 + P_{l-1}\} \quad (9) Pl=upconv{fovea(M1)+M2+Pl−1}(9)
其中upconv\text{upconv}upconv表示上采样卷积操作。
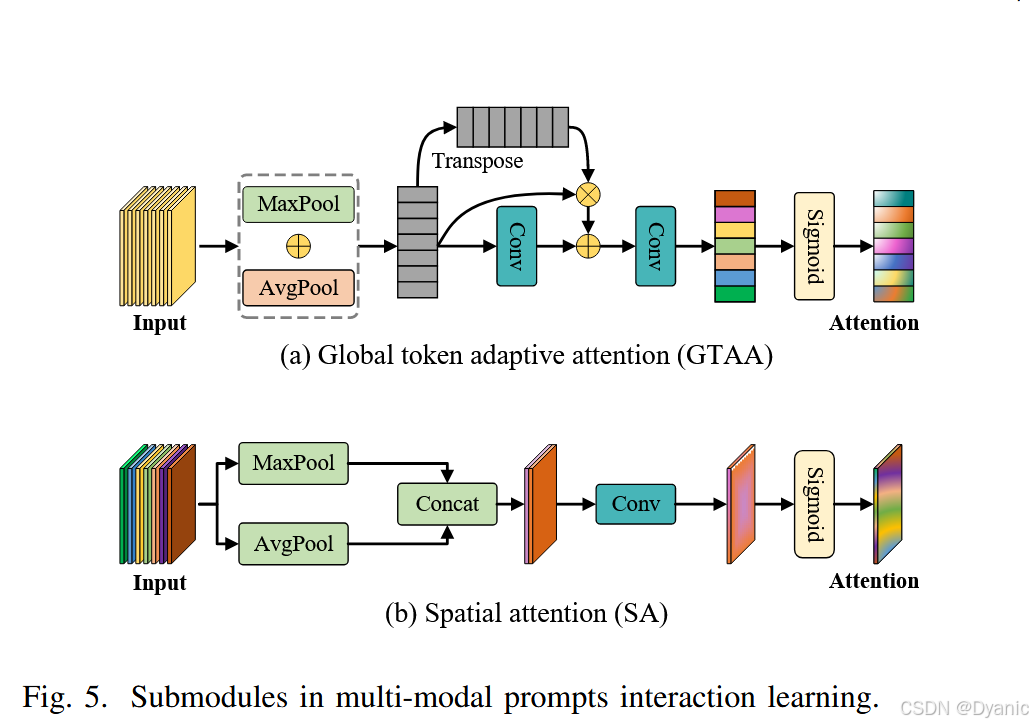
为了更好地处理RGBT跟踪中的全局语义信息,GTAA模块采用了如图5(a)所示的专门结构设计。给定一个输入特征 x∈RD×H1×W1x \in \mathbb{R}^{D \times H_1 \times W_1}x∈RD×H1×W1,我们首先对其进行平均池化和最大池化操作,并将其输出结合起来生成特征 xa∈RD×1x_a \in \mathbb{R}^{D \times 1}xa∈RD×1。为了捕捉全局信息,转置后的 xaT∈R1×Dx_a^T \in \mathbb{R}^{1 \times D}xaT∈R1×D 与 xa∈RD×1x_a \in \mathbb{R}^{D \times 1}xa∈RD×1 相乘得到特征 xa1∈R1×1x_{a1} \in \mathbb{R}^{1 \times 1}xa1∈R1×1,同时通过一个1D卷积处理 xax_axa 生成特征 xa2∈R1×Dx_{a2} \in \mathbb{R}^{1 \times D}xa2∈R1×D。随后,特征 xa1x_{a1}xa1 和 xa2x_{a2}xa2 相加,并通过一个1D卷积和Sigmoid函数处理,产生形状为 RD×1×1\mathbb{R}^{D \times 1 \times 1}RD×1×1 的GTAA输出。整个过程可形式化如下:
xa=maxpool(x)+avgpool(x)(10) x_a = \text{maxpool}(x) + \text{avgpool}(x) \quad (10) xa=maxpool(x)+avgpool(x)(10)
{xa1=xaT⋅xaxa2=conv1d(xa)(11) \begin{cases} x_{a1} = x_a^T \cdot x_a \\ x_{a2} = \text{conv1d}(x_a) \end{cases} \quad (11) {xa1=xaT⋅xaxa2=conv1d(xa)(11)
GTAA(x)=Sigmoid(conv1d(xa1+xa2))(12) \text{GTAA}(x) = \text{Sigmoid}(\text{conv1d}(x_{a1} + x_{a2})) \quad (12) GTAA(x)=Sigmoid(conv1d(xa1+xa2))(12)
其中 maxpool\text{maxpool}maxpool 表示最大池化操作,avgpool\text{avgpool}avgpool 表示平均池化操作,TTT 是转置操作,conv1d\text{conv1d}conv1d 表示一维卷积,· 表示矩阵乘法。
SA模块的结构如图5(b)所示,它设计了一个类似于CBAM [48] 的空间注意力机制。在RGBT跟踪中,局部空间信息对于精确定位目标同样至关重要。因此,我们同时对输入特征y进行最大池化和平均池化操作,将其结果拼接起来生成特征 ymay_{ma}yma。随后,通过7×7卷积核处理并用Sigmoid函数调整权重,得到空间注意力。
yma=cat[maxpool(y),avgpool(y)](13) y_{ma} = \text{cat}[\text{maxpool}(y), \text{avgpool}(y)] \quad (13) yma=cat[maxpool(y),avgpool(y)](13)
SA(y)=Sigmoid(conv(yma))(14) \text{SA}(y) = \text{Sigmoid}(\text{conv}(y_{ma})) \quad (14) SA(y)=Sigmoid(conv(yma))(14)
这种经典的空间注意力设计已在视觉跟踪任务中证明了其有效性,使模型能够广泛关注目标的空间位置信息。MPIL模块的引入实现了有效的多模态提示交互,同时加强了跟踪器对跨模态数据的适应性。该模块在处理具有异构视觉提示的场景时,在跟踪精度和稳定性方面表现出显著的改进。
D. 交叉融合适配器

在RGBT跟踪中,有效融合来自RGB和TIR模态的互补信息仍然是一个关键挑战。现有方法通常采用简单的拼接、相加或交叉注意力,难以完全适应不同场景下的特征差异。为了弥补这一差距,我们提出了一种新颖的交叉融合适配器,它将适配器结构引入到交叉注意力机制中。这种设计增强了多模态融合对不同输入模态的适应性,从而能够更有效地整合RGB和TIR模态特征,如图6所示。
以某个CFA实例为例,假设从RGB分支和TIR分支输出的特征分别为 Xq∈RN×DX_q \in \mathbb{R}^{N \times D}Xq∈RN×D 和 Xkv∈RN×DX_{kv} \in \mathbb{R}^{N \times D}Xkv∈RN×D。考虑到RGB和TIR模态在不同场景下的贡献不同,XqX_qXq 和 XkvX_{kv}Xkv 通过线性层映射以生成查询向量 q1q_1q1、键向量 k2k_2k2 和值向量 v2v_2v2,如公式15所示。
{q1=Linear(Xq)k2,v2=Linear(Xkv)(15) \begin{cases} q_1 = \text{Linear}(X_q) \\ k_2, v_2 = \text{Linear}(X_{kv}) \end{cases} \quad (15) {q1=Linear(Xq)k2,v2=Linear(Xkv)(15)
由于在变化的环境条件下,目标外观在不同模态下会发生动态变化,我们创新性地为查询向量 q1q_1q1 引入了一个适配器,同时进一步提升了模型的适应性。该适配器由一个1×1的降维卷积层、一个GeLU激活函数和一个1×1的升维卷积层组成,生成调整后的特征,表示为 adpt1adpt_1adpt1。随后,q1q_1q1 与 adpt1adpt_1adpt1、k2k_2k2 和 v2v_2v2 一起通过多头交叉注意力机制处理,生成特征 Fout1F_{out1}Fout1,如公式16和17所示。
adpt1=upconv{GeLU(downconv(q1))}(16) adpt_1 = \text{upconv}\{\text{GeLU}(\text{downconv}(q_1))\} \quad (16) adpt1=upconv{GeLU(downconv(q1))}(16)
Fout1=Softmax((q1+adpt1)⋅k2Td)⋅v2(17) F_{out1} = \text{Softmax}\left(\frac{(q_1 + adpt_1) \cdot k_2^T}{\sqrt{d}}\right) \cdot v_2 \quad (17) Fout1=Softmax(d(q1+adpt1)⋅k2T)⋅v2(17)
其中 downconv\text{downconv}downconv 表示降维卷积,GeLU 表示GeLU激活函数,upconv 表示升维卷积。随后,通过将 Fout1F_{out1}Fout1 与原始特征 XqX_qXq 相加并由层归一化进行归一化,生成更新后的特征 Fout1F_{out1}Fout1。之后,将相同的适配器结构再次应用于 Fout1F_{out1}Fout1 以生成特征 adpt2adpt_2adpt2,如公式18所示。
Fout1=LN(Fout1+Xq)(18) F_{out1} = \text{LN}(F_{out1} + X_q) \quad (18) Fout1=LN(Fout1+Xq)(18)
最后,Fout1F_{out1}Fout1、经前馈神经网络处理的特征与 adpt2adpt_2adpt2 相加,并通过层归一化得到最终的输出特征,如公式19和20所示。
adpt2=upconv{GeLU(downconv(Fout1))}(19) adpt_2 = \text{upconv}\{\text{GeLU}(\text{downconv}(F_{out1}))\} \quad (19) adpt2=upconv{GeLU(downconv(Fout1))}(19)
Fout=LN{Fout1+FFN(Fout1)+adpt2}(20) F_{out} = \text{LN}\{F_{out1} + \text{FFN}(F_{out1}) + adpt_2\} \quad (20) Fout=LN{Fout1+FFN(Fout1)+adpt2}(20)
通过在交叉注意力中引入适配器结构,CFA能够高效地适应不同模态间的特征差异。这种设计不仅增强了模型对单个模态特征的适应性,还提高了融合特征的表示能力和稳定性,从而实现了RGB和TIR模态互补信息的有效整合。
E. 边界框预测头
最后,由交叉融合适配器处理的多模态融合特征被送入预测头,该预测头由一个分类头和一个回归头组成,用于预测目标的类别。分类头负责输出目标的类别概率,而回归头则生成目标边界框的具体位置和大小。我们的方法在此基础上,采用了与ViPT相同的预测结构和损失设计,以确保分类和回归任务的稳定性和准确性。
具体来说,整个模型的损失函数如公式21所示,包含三个主要部分:分类损失、边界框回归损失和正则化项。
L=Lcls+λ1Liou+λ2L1(21) L = L_{cls} + \lambda_1 L_{iou} + \lambda_2 L_1 \quad (21) L=Lcls+λ1Liou+λ2L1(21)
其中,LclsL_{cls}Lcls 是用于分类的加权焦点损失,LiouL_{iou}Liou 和 L1L_1L1 分别是IoU损失和L1损失,它们被分配用于优化边界框的精度,并确保模型能够准确预测不同尺度下目标的位置和大小。此外,λ1\lambda_1λ1 和 λ2\lambda_2λ2 代表正则化参数。损失函数的设置与ViPT保持一致,以确保我们提出的方法在优化过程中能够有效融合多模态信息并提高跟踪精度。
IV. 实验
本节详细描述了我们所提方法的实验细节,并展示了在三个跟踪基准数据集上的评估结果。该方法不仅从定量和定性的角度与现有的最先进RGBT跟踪器进行了比较,还通过消融实验验证了所提方法中各个组件的有效性。
A. 评估设置
数据集。 我们的研究在四个主要的RGBT跟踪数据集上进行评估,它们是GTOT、RGBT234、LasHeR和VTUAV。
GTOT 是RGB-T跟踪领域的第一个标准数据集,包含50个视频序列,每个序列都由同步的可见光和热红外视频组成。这些视频覆盖了室内环境、室外街道等多种场景,并涉及行人、车辆等多种目标类型。该数据集中的目标具有七个挑战性属性,包括遮挡(OCC)、大尺寸变化(LSV)、快速移动(FM)、低光照(LI)、热交叉(TC)、小目标(SO)和形变(DEF)。
RGBT234 是一个大规模的RGBT数据集,包含234组RGBT视频序列,总计超过234,000帧,最长视频达到4,000帧。该数据集不仅包含广泛的场景和目标类型,还特别标注了12个挑战属性,包括无遮挡(NO)、部分遮挡(PO)、严重遮挡(HO)、低光照(LI)、低分辨率(LR)、热交叉(TC)、形变(DEF)、快速运动(FM)、尺度变化(SV)、运动模糊(MB)、相机移动(CM)和背景杂乱(BC)。
LasHeR 是第二大的RGB-T跟踪数据集,由1224个视频序列组成,总计超过73万帧对,并提供了更丰富的属性标注,如相似外观和长宽比变化。同时,为了满足训练和测试的需求,该数据集被分为两部分:包含979对视频序列的训练集和包含245对视频序列的测试集。
VTUAV 数据集是迄今为止最大的RGBT跟踪基准数据集,它是使用无人机搭载的双模态相机系统在多种天气条件下采集的。该数据集包含500个高质量视频序列,约有170万对高分辨率图像,覆盖了包括行人、车辆和动物在内的13个跟踪对象类别。该数据集被均匀地划分为训练集和测试集,每个集合包含250个序列。训练集包括207个短期序列和43个长期序列,而测试集包括176个短期序列和74个长期序列,从而能够全面评估算法在不同场景下的性能。
评估指标。 在本研究中,我们遵循先前的工作,并采用一次性评估(OPEs)中两种广泛使用的关键指标,即精确率(PR)和成功率(SR),来定量评估所提方法在RGBT基准数据集上的跟踪性能。具体来说,PR定义为预测框中心与真值中心之间的距离低于特定阈值的所有帧的比例,在RGBT234和LasHeR上该阈值设为20像素,而在GTOT上考虑到目标尺寸普遍较小,调整为5像素。SR表示预测框与实际框之间的重叠率超过预设阈值的帧的比例,SR的代表值通过计算曲线下面积来确定。
实现细节。 我们采用PyTorch框架构建模型,并在配备16G显存GPU的服务器上进行训练。实验环境的具体配置参数如表I所示。我们采用训练好的OSTrack作为预训练模型,并保持损失函数结构和参数设置与ViPT相同。在LasHeR数据集上训练时,我们将搜索区域和模板的输入图像尺寸分别调整为和。详细的训练参数设置,如批量大小、优化器、学习率和权重衰减因子,呈现在表I的右侧部分。
B. 与最先进方法的比较
1) 比较方法: 为了验证所提方法的先进性,我们系统地收集并总结了近年来发表的21个主流RGBT跟踪器在GTOT [18]、RGBT234 [19]和LasHeR [20]数据集上的整体性能评估结果,涵盖了PR和SR等关键指标。具体比较的跟踪器包括MANet [27]、DAPNet [50]、CAT [33]、MANet++ [28]、ADRNet [34]、JMMAC [51]、DMCNet [29]、M5L [30]、APFNet [35]、SiamCDA [46]、TFNet [12]、TBSI [47]、DRGCNet [32]、CMD [52]、ViPT [17]、SiamMLAA [53]、QueryTrack [54]、LMINet [55]、VLCTrack [56]、BAT [43]和OneTracker [36]。在此基础上,我们对所提出的MPANet进行了全面评估,并与上述方法进行了详细比较,具体的评估和比较结果列于表II。
2) 在GTOT数据集上的评估: 如表II所示,所提出的MPANet在GTOT数据集上表现出卓越的性能,取得了92.3%的PR和76.8%的SR分数。这一性能优势主要源于模型在不同视觉提示下的鲁棒适应性和特征表示能力。与排名第二的QueryTrack相比,MPANet的SR提升了0.9%。相对于排名第三的方法SiamMLAA(91.3%, 75.1%),MPANet分别实现了1.0%和1.7%的提升。此外,与MANet(89.4%/72.4%)、APFNet(90.4%, 73.5%)和ADRNet(90.4%/73.9%)等知名跟踪器相比,MPANet分别展示了2.9%/4.4%、1.9%/3.3%和1.9%/2.9%的显著提升。整体评估和比较结果验证了我们提出的多模态视觉提示跟踪框架的巨大优势。此外,针对GTOT数据集中的七个不同挑战属性,如图7所示,我们呈现了雷达图,以比较MPANet与其他七个跟踪器之间的PR和SR分数。图表直观地展示了在各种属性下的性能。可以观察到,MPANet在包括OCC、LSV、FM、LI和TC在内的挑战性属性上持续优于其他比较方法,尤其是在SR分数上优势显著。这证明了模型在处理复杂视觉场景时的鲁棒性,特别是在多模态信息互补的场景中表现出色。
3) 在RGBT234数据集上的评估: 根据表II,我们的MPANet在RGBT234数据集上以87.4%的PR和64.6%的SR取得了最先进的性能。这一优越性能主要得益于所设计的多层次视觉提示学习与交互策略,使得能够有效整合不同模态间的互补信息并增强特征表示。特别地,MPANet在PR和SR上分别超过了排名第二的TBSI 0.3%和0.9%,同时优于排名第三的BAT 0.6%和0.5%。实验结果显示,与早期的MANet方法相比,我们的方法在PR和SR上分别有9.7%和10.7%的显著提升。值得注意的是,与同样采用提示学习的ViPT相比,MPANet在PR和SR上分别实现了3.9%和2.9%的提升。与统一的多模态跟踪器OneTracker [36]相比,也取得了1.7%和0.4%的提升。这些优异的结果全面验证了我们设计的多模态视觉提示学习与融合策略的有效性。
为了深入分析在RGBT234数据集上12个不同挑战属性的性能,表III和表IV总结了MPANet与其他10个跟踪器的PR和SR。表III展示了不同属性下的PR分数,显示MPANet在包括NO、HO、DEF、FM和BC在内的属性上优于比较方法。同样,表IV显示了SR分数,其中MPANet在NO、HO、LI、DEF、FM、CM和BC等属性上达到了领先性能。值得注意的是,MPANet和TBSI在不同属性上表现出交替的优势,这为未来的改进指明了潜在方向。这些在不同属性上的性能差异反映了模型在处理多样化视觉挑战时的适应性。
此外,我们的MPANet在PR和SR分数上均显著超过了专门为不同数据集属性设计的APFNet和ADRNet。这些方法相比的巨大优势进一步验证了我们的MPANet在复杂跟踪场景中的泛化能力。
4) 在LasHeR数据集上的评估: 在更具挑战性的LasHeR数据集上,MPANet的卓越性能主要源于三个关键的设计模块。首先,SADA模块通过自适应特征聚合增强了模型对目标外观变化的适应性。其次,MPIL模块通过多层次的提示交互学习提高了RGB和TIR模态特征之间的互补性。第三,CFA模块通过自适应融合机制动态调整不同场景下的特征权重。
根据表II,这些创新设计使MPANet取得了72.1%的PR和57.3%的SR,显著优于所有比较方法。为了直观可视化,图8展示了MPANet与其他八个跟踪器在LasHeR上的PR和SR评估曲线。表II和图8的定量结果表明,我们的MPANet在PR和SR上分别超过BAT 1.9%和1.0%,超过TBSI 2.9%和1.7%。与结合了CNN和Transformer架构的APFNet相比,PR和SR分别取得了22.1%和21.1%的提升。值得注意的是,与基于提示的ViPT相比,MPANet在PR和SR上分别展示了7.0%和4.8%的提升。与采用提示学习的统一多模态跟踪器OneTracker相比,PR和SR的提升分别达到了4.9%和3.5%。
这些比较结果全面验证了我们提出的多模态视觉提示交互学习策略的有效性。在面对极其复杂和多样的场景时,这些结果不仅表明我们的跟踪器具有更强的泛化能力,也为其鲁棒性和高精度提供了坚实的支持,进一步验证了我们的方法在挑战性场景中的有效性和可靠性。
5) 在VTUAV数据集上的评估: 在VTUAV数据集上,评估结果呈现在表V中。我们的MPANet在短期跟踪子集上获得了76.6%的PR和63.7%的SR,与表现第二好的方法HMFT相比,分别提升了0.8%和1.0%。相对于DAFNet和ADRNet,MPANet展现出更显著的跟踪性能增益。这些结果表明MPANet有效应对了短期跟踪场景中的各种挑战。在更具挑战性的长期跟踪子集上,MPANet展现出更为显著的优势,达到了64.6%的PR和49.2%的SR。与排名第二、PR为41.4%、SR为35.5%的HMFT相比,MPANet分别展示了23.2%和13.7%的惊人提升。这种在长期跟踪任务中的卓越性能主要得益于模型对目标特征的持续学习和动态适应能力。通过维持稳定的特征表示和动态调整模态融合策略,MPANet有效处理了长期跟踪中的各种复杂场景。
总的来说,跨不同数据集的评估结果表明,MPANet在各种跟踪场景中都表现出卓越的性能。这种一致性验证了我们提出的模块在解决RGBT跟踪中各种挑战方面的有效性和鲁棒性。特别是,通过多尺度特征学习、多层次多模态视觉提示学习以及自适应模态融合机制,我们的方法为有效整合RGB和TIR模态信息提供了新颖的解决方案。
6) 每秒帧数: 帧率比较揭示了RGBT跟踪中不同跟踪器之间的显著差异,其中每秒帧数(FPS)是一个至关重要的性能指标。如表II所示,MANet和APFNet的运行速度分别仅为2.1和1.9 FPS,远未达到实时应用的要求。相比之下,TBSI和ViPT实现了36.2和38.5 FPS的更高处理速度,略高于我们MPANet 29.0 FPS的运行速度。尽管MPANet的速度与某些竞争方法相比略低,但它在表现顶尖的跟踪器中保持了有竞争力的地位。更重要的是,MPANet在保持稳健处理速度的同时,取得了最高的PR和SR,展示了出色的实时处理能力和计算效率。
C. 定性评估
为了验证所提方法在不同挑战场景下的有效性,我们进行了详细的定性分析。图9和图10展示了所提方法与其他跟踪器在典型复杂场景下的跟踪结果比较。
具体来说,图9展示了在RGBT234数据集的car和elecbikewithlight1序列上的跟踪结果。在car序列中,目标车辆从停车位倒车时经历了显著的尺度变化。得益于SADA模块的多尺度感知能力,所提方法有效适应了动态的尺度变化,全程保持了准确的目标定位和形状预测。相比之下,BAT和ViPT在第182帧和第295帧出现了跟踪漂移,错误地将邻近车辆识别为目标。而其他方法虽然大致估计了目标位置,但难以准确预测目标形状。在elecbikewithlight1序列中,随着电动自行车靠近,同时出现了尺度变化和相似目标干扰,所提方法通过MPIL和CFA模块的协同作用,准确捕捉了具有辨识度的目标特征,而像ViPT这样的跟踪器则错误地将周围的行人识别为目标。
图10进一步展示了所提方法在LasHeR数据集中更具挑战性场景下的优势。在ab blkskirtgirl序列中,目标因相机移动而经历了严重的树木遮挡和运动模糊,所提方法通过MPIL模块实现的有效RGB-TIR模态信息融合,保持了稳定的跟踪。这使得能够同时利用RGB图像的外观特征和TIR图像的热信息。相比之下,其他跟踪器在遮挡和运动模糊条件下表现出显著的漂移。在carlightcome2序列中,一辆车在夜间低光照条件下行驶,所提方法不仅准确地定位了目标位置,还预测了紧密贴合的边界框,而其他跟踪器仅能粗略估计目标位置和尺度。
这些定性结果清晰地展示了所提模块在处理包括尺度变化、遮挡、运动模糊和低光照在内的特定挑战时的有效性。特别是,通过多模态信息的协同使用,在复杂场景中跟踪的鲁棒性和精度得到了显著增强。
为了全面评估我们MPANet的性能,我们分析了LasHeR数据集上的典型失败案例,如图11所示。在3rdfatboy序列中,尽管MPANet成功定位了目标位置,但预测的边界框与真值标注之间存在显著差异,这主要是由于周围相似物体的干扰影响了准确的尺度估计。在3rdgrouplastboy序列中,目标附近的多个高度相似的干扰物导致跟踪器锁定了错误的对象,从而在后续帧中导致跟踪失败。这些案例表明,我们的跟踪器在存在多个相似物体的场景中仍面临挑战。
D. 参数量与浮点运算数
表VI详细比较了所提出的MPANet与其他先进跟踪算法在模型规模和计算效率方面的差异。在参数数量方面,MPANet包含123.42M个参数,低于TBSI(186.59M),但略高于ViPT(89.41M)和BAT(82.36M)。在计算复杂度方面,MPANet的浮点运算数(FLOPS)为68.18G,处于中等水平,比TBSI(82.28G)有显著优势,但高于ViPT(29.47G)。MPANet的模型大小保持在0.48G的中等水平。
为了深入分析每个模块的计算开销,我们统计了不含(w/o)SADA、MPIL和CFA模块的MPANet的参数和计算效率。具体来说,SADA模块贡献了约27.03M参数和4.54G FLOPs,虽然引入了额外的计算负担,但它使PR和SR均提高了0.5%。MPIL模块使用了约7.21M参数和2.23G FLOPs,带来了2.5%的PR和1.6%的SR的显著性能增益。CFA模块增加了约7.33M参数和2.77G FLOPs,通过这些适度的计算成本实现了1.3%的PR和0.9%的SR的提升。模块级别的分析表明,每个组件都以合理的计算开销带来了可观的性能提升。
值得注意的是,尽管MPANet在参数数量和计算复杂度上未达到最优,但它在LasHeR数据集上展现了卓越的跟踪性能,分别达到了72.1%的PR和57.3%的SR。这些结果表明,所提出的架构在模型复杂度和跟踪性能之间取得了有效的平衡,充分展示了模型设计的效率。
E. 消融研究
为了全面验证所提方法中每个组件的有效性及其对跟踪性能的影响,我们首先构建了一个基线模型(Baseline)。基线模型采用共享的双流ViT作为主干网络,并使用OSTrack [59]的预训练参数进行初始化。我们在LasHeR数据集上进行了一系列深入的消融实验,重点分析三个核心组件的贡献:尺度感知扩张注意力模块(SADA)、多模态提示交互学习模块(MPIL)和交叉融合适配器(CFA)。表VII展示了不同组件配置下的PR、SR和FPS的详细比较结果。
消融研究结果表明,基线模型在LasHeR数据集上取得了68.9%的PR和55.0%的SR,处理速度为33.1 FPS。通过对每个模块贡献的单独分析,我们观察到:加入SADA模块将PR和SR分别提高到69.1%和55.1%,验证了尺度感知扩张注意力机制在增强多尺度目标建模能力方面的有效性;集成MPIL模块进一步将性能提升至70.4%和56.1%,凸显了多模态提示交互学习在视觉提示学习中的关键作用;引入CFA模块实现了69.3%的PR和55.2%的SR,证实了交叉融合适配器在优化多模态特征融合方面的积极贡献。
更重要的是,当这些模块协同工作时,模型的性能表现出更显著的提升。特别是,在完全集成所有三个模块后,MPANet以72.1%的PR和57.3%的SR达到了最佳性能,与基线模型相比分别提升了3.2%和2.3%。值得注意的是,尽管引入多个功能模块会产生一定的计算开销,但完整模型的处理速度仍保持在29.0 FPS,完全满足实际应用需求。这些实验结果不仅确凿地验证了每个模块的独立效用,也展示了通过它们的协同效应带来的显著性能增益,从而彻底验证了所提方法的有效性。
此外,为了验证MPIL中全局令牌自适应注意力和空间注意力组件的效果,我们进行了相应的消融实验,结果如表VIII所示。具体来说,当从MPIL中移除GTAA组件时,得到的模型MPIL-GTAA的PR和SR分别为70.4%和56.2%,与完整的MPIL模型相比分别低了1.7%和1.1%。这一差异证明了GTAA在学习多模态提示的全局信息方面的显著作用。另一方面,移除了SA组件的MPIL-SA版本的PR和SR分别为70.7%和56.3%,而完整的MPIL则分别高出1.4%和1.0%,这表明在提示学习中引入空间注意力可以增强对视觉提示的学习。总之,这些实验结果证明了GTAA和SA在多模态视觉提示学习中的重要性和价值,也凸显了将它们结合使用的必要性。
为了验证所提出的CFA模块的有效性,我们设计了关于双分支特征不同融合策略的对比实验,结果呈现在表IX中。具体来说,我们检验了四种不同的融合方法:直接拼接、直接相加、交叉注意力和我们提出的CFA。实验结果表明,简单的特征拼接和相加操作在PR和SR指标上表现相对较弱,这表明线性融合策略难以有效利用模态间的互补信息。在引入交叉注意力机制后,模型性能得到改善,PR和SR值分别达到71.4%和56.7%,证实了自适应融合的重要性。随着我们提出的CFA模块的实施,跟踪性能进一步提升,PR达到72.1%,SR达到57.3%,与基线方法相比有显著提高。这些结果验证了我们的CFA模块在处理双分支特征融合方面的优越性,其中经适配器增强的交叉注意力机制有效地整合了来自不同模态的互补信息。
V. 结论
在本文中,我们创新性地提出了一种基于多模态视觉提示的RGBT跟踪器,即MPANet,旨在解决多模态跟踪中的挑战。通过引入我们提出的SADA、MPIL和CFA,跟踪器在处理多模态数据时的鲁棒性和准确性得到了有效提升。具体而言,首先设计了SADA模块以增强跟踪器对不同尺度目标的适应性。然后,将MPIL模块嵌入到双分支ViT主干网络中,该模块结合了GTAA和SA,以有效学习和交互多模态视觉提示信息,并显著提升跟踪性能。最后,开发了CFA模块,该模块通过适配器机制增强了多模态信息在交叉融合过程中的适应性。大量的实验结果表明,我们的MPANet在三个主流RGBT数据集上取得了最先进的性能,这充分证明了该方法在鲁棒性和准确性方面的卓越表现。
基于这些研究发现,MPANet不仅在RGBT跟踪中展现出有前景的性能,也为智能安防和自动驾驶系统等实际应用提供了新的见解和视角。然而,为了进一步提升系统性能,有几个潜在的研究方向需要深入探索。例如,通过改进判别性特征学习来增强在存在多个相似物体场景下的鲁棒性,同时优化计算效率,将是另一个重要的研究方向。此外,将语言信息与视觉-热红外特征相结合以提供更丰富的语义理解,也是未来发展的一个关键课题。