深度学习(4)—— Pytorch快速上手!从零搭建神经网络
1.什么是Pytorch?
PyTorch 是一个开源的深度学习框架,主要用于构建和训练机器学习(尤其是深度学习)模型,由 Meta(原 Facebook)的人工智能研究实验室(FAIR)开发并维护。它以灵活性、易用性和强大的功能被广泛应用于学术研究和工业界。其核心特点如下图所示:

1.1 动态计算图
动态计算图(Dynamic Computational Graph)是深度学习框架中用于表示和执行计算流程的一种机制,其核心特点是计算图的构建与代码执行同步进行—— 即代码运行时,计算图会 “动态” 地随每一步操作实时生成、修改,而非像静态图那样需要先完整定义图结构再执行。

| 特性 | 动态计算图(如 PyTorch) | 静态计算图(如 TensorFlow 1.x) |
|---|---|---|
| 图构建时机 | 代码运行时实时构建 | 代码定义阶段预先构建(不执行计算) |
| 控制流支持 | 自然支持 if-else、for 等(图随路径动态调整) | 需要特殊 API(如 tf.cond、tf.loop)预先定义所有可能路径 |
| 调试便利性 | 可实时打印中间变量,像普通 Python 代码一样调试 | 需通过会话运行后才能查看结果,调试困难 |
| 灵活性 | 高(适合快速修改、探索新算法) | 较低(适合固定流程的生产部署) |
1.2 其它深度学习框架
| 框架名称 | 开发者 / 维护者 | 核心特点 | 适用场景 | 备注 |
|---|---|---|---|---|
| TensorFlow | Google(开源社区维护) | 1. 支持动态图(2.x 默认)和静态图,兼顾灵活性与生产优化;2. 强大的部署生态(TensorRT、TFLite、TF.js 等);3. 丰富的高阶 API(Keras 集成)。 | 工业级生产部署、大规模分布式训练、跨平台部署(服务器 / 移动端 / 浏览器)。 | 早期 1.x 以静态图为主,2.x 后向动态图靠拢,生态最完善之一。 |
| Keras | François Chollet(现集成于 TensorFlow) | 1. 极简高层 API,封装底层框架(默认基于 TensorFlow,也可对接 MXNet 等);2. 代码简洁,专注模型逻辑而非工程细节。 | 快速原型开发、教学入门、中小规模模型实验。 | 本身是 “接口层”,依赖底层框架执行计算,2019 年起成为 TensorFlow 官方高阶 API。 |
| MXNet | 亚马逊(Apache 基金会托管) | 1. 支持 “混合编程模型”(动态图 + 静态图切换);2. 内存效率高,分布式训练支持好;3. 多语言接口(Python/R/Scala 等)。 | 大规模分布式训练、对内存敏感的场景、多语言开发需求。 | 曾是亚马逊 AWS 官方推荐框架,灵活性和性能平衡较好。 |
| Caffe/Caffe2 | Berkeley AI Research(Caffe);Facebook(Caffe2) | 1. Caffe:基于配置文件的静态图,适合固定结构网络(如 CNN);2. Caffe2:轻量灵活,支持动态计算和移动端部署。 | Caffe 适合传统计算机视觉任务(如图像分类);Caffe2 适合轻量部署。 | Caffe2 已停止独立更新,部分功能并入 PyTorch Mobile。 |
| MindSpore | 华为 | 1. 支持自动微分、自动并行,简化分布式训练;2. 动态图(PyNative)与静态图(Graph)统一;3. 内置隐私计算、联邦学习支持。 | 端边云协同场景、大规模分布式训练、需要隐私保护的行业应用(如医疗、金融)。 | 国产化框架,对昇腾芯片优化好,文档支持中文。 |
| JAX | Google Brain | 1. 基于 NumPy 扩展,融合自动微分(Autograd)和高性能编译(XLA);2. 支持函数式编程,易于实现复杂算法;3. 极致计算性能(尤其 GPU/TPU)。 | 学术研究(如强化学习、数值优化)、需要高性能计算的场景。 | 更偏向 “计算库” 而非完整框架,适合熟悉 NumPy 和函数式编程的开发者。 |
| PaddlePaddle | 百度 | 1. 中文生态完善,文档和教程本地化;2. 产业级工具链(如 PaddleDetection、PaddleNLP);3. 支持动态图,部署工具链成熟(PaddleLite)。 | 国内产业应用(如 AI 质检、自然语言处理)、中文场景开发、教学入门。 | 国产化框架,在工业界应用广泛,对中文 NLP 任务优化较好。 |
2.安装Pytorch
下面这篇文章,已经详细讲解了如何安装环境 ,本文不再做过多叙述。
CPU与GPU版本的Pytorch安装
3. 张量(Tensor)
在 PyTorch 中,张量(Tensor) 是进行深度学习和数值计算的核心数据结构。从数学角度看,张量是标量、向量、矩阵的推广:
-
0阶张量:标量(单个数值,如
3.14) -
1阶张量:向量(一维数组,如
[1, 2, 3]) -
2阶张量:矩阵(二维数组,如
[[1,2],[3,4]]) -
n阶张量:n维数组(如图像数据、视频数据等)
从编程角度看,张量类似于 NumPy 的 ndarray,但提供了更多深度学习所需的特性。
所以,我们为什么要用张量这一数据结构,而不使用ndarry或者list的结构来进行深度学习训练?
Reason:👇
特性 PyTorch 张量 NumPy 数组 Python List 数据类型 同质(单一类型) 同质(单一类型) 异质(混合类型) 维度支持 n维 n维 1维(可嵌套模拟多维) 计算速度 极快(C++/CUDA) 快(C语言) 慢(Python原生) GPU 加速 ✅ 原生支持 ❌ 仅支持 CPU ❌ 仅支持 CPU 自动求导 ✅ 支持 autograd ❌ 需手动实现 ❌ 需手动实现 内存占用 极小(连续内存) 小(连续内存) 大(对象指针) 内存共享 可与 NumPy 零拷贝共享 可与 PyTorch 零拷贝共享 无法共享 广播机制 ✅ 支持 ✅ 支持 ❌ 不支持 深度学习 ✅ 原生支持 ⚠️ 需配合其他框架 ❌ 不适用
- 深度学习涉及大规模矩阵运算,GPU 的并行计算能力可带来 10-100倍 的性能提升。Python List 和 NumPy 无法原生利用 GPU。
- 深度学习依赖反向传播算法,需要自动计算梯度。张量的 requires_grad=True 属性启动了完整的自动求导引擎。
- 张量在内存中以连续块存储,利用 CPU/GPU 的向量化指令集,而 Python List 是指针数组,存在巨大开销。
- 张量支持 分布式训练、量化、ONNX 导出 等生产级特性,这些是 NumPy 和 List 无法提供的。
PS.广播机制(Broadcasting) 是一种自动处理形状不同的数组(或张量)之间元素级运算的规则。它的核心作用是:在不实际复制数据的前提下,逻辑上扩展数组的形状,使原本形状不匹配的数组能够进行元素级运算,从而简化代码并减少内存开销。
----------------------------------------------三种类型的性能比较实验--------------------------------------------------
import time
import torch
import numpy as np# 测试数据:10000x10000 矩阵
size = 10000
pytorch_tensor = torch.randn(size, size)
numpy_array = np.random.randn(size, size)
python_list = [[1.0]*size for _ in range(size)]# 1. Python List 计算(极慢)
start = time.time()
result_list = [[python_list[i][j]*2 for j in range(size)] for i in range(size)]
print(f"Python List 耗时:{time.time() - start:.4f} 秒")# 2. NumPy 计算
start = time.time()
result_numpy = numpy_array * 2
print(f"NumPy 耗时:{time.time() - start:.4f} 秒")# 3. PyTorch CPU 计算
start = time.time()
result_pytorch_cpu = pytorch_tensor * 2
print(f"PyTorch CPU 耗时:{time.time() - start:.4f} 秒")# 4. PyTorch GPU 计算(如可用)
if torch.cuda.is_available():pytorch_tensor_gpu = pytorch_tensor.cuda()start = time.time()result_pytorch_gpu = pytorch_tensor_gpu * 2torch.cuda.synchronize() # 等待 GPU 完成print(f"PyTorch GPU 耗时:{time.time() - start:.4f} 秒")结果如下:
Python List 耗时:11.3184 秒
NumPy 耗时:0.4494 秒
PyTorch CPU 耗时:0.2315 秒
PyTorch GPU 耗时:0.1563 秒3.1 创建张量
方法1:从现有数据创建
import torch
import numpy as np# 从 Python 列表/元组
tensor1 = torch.tensor([1, 2, 3])
tensor2 = torch.tensor([[1, 2], [3, 4]])# 从 NumPy 数组
np_array = np.array([5, 6, 7])
tensor3 = torch.from_numpy(np_array)方法2:使用工厂函数创建特殊张量
# 创建全 0/1 张量
zeros = torch.zeros(3, 4) # 3x4 的全0矩阵
ones = torch.ones(2, 3) # 2x3 的全1矩阵# 创建随机张量
rand = torch.rand(3, 3) # 0-1 均匀分布
randn = torch.randn(3, 3) # 标准正态分布 N(0,1)
randint = torch.randint(0, 10, (3, 3)) # 0-10 之间的整数# 创建未初始化张量(速度快但值不确定)
empty = torch.empty(3, 3)# 创建单位矩阵
eye = torch.eye(3)# 创建等差数列
arange = torch.arange(0, 10, 2) # [0, 2, 4, 6, 8]
linspace = torch.linspace(0, 1, 5) # [0.0, 0.25, 0.5, 0.75, 1.0]方法3:从其他张量复制形状
# 创建与现有张量形状相同的新张量
existing_tensor = torch.tensor([[1, 2], [3, 4]])# 相同形状的全0/全1张量
zeros_like = torch.zeros_like(existing_tensor)
ones_like = torch.ones_like(existing_tensor)# 相同形状的随机张量
rand_like = torch.rand_like(existing_tensor, dtype=torch.float32)方法4:创建稀疏张量
# 创建稀疏张量(仅存储非零元素)
indices = torch.tensor([[0, 1, 2], [0, 1, 2]]) # 非零元素的坐标
values = torch.tensor([1.0, 2.0, 3.0]) # 非零元素的值
sparse_tensor = torch.sparse_coo_tensor(indices, values, size=(3, 3))print(sparse_tensor)
print(sparse_tensor.to_dense()) # 转为稠密矩阵3.2 张量常用属性
| 属性 | 含义 | 示例 |
|---|---|---|
x.shape / x.size() | 形状 | [batch_size, feature_dim] |
x.dtype | 数据类型 | torch.float32、torch.int64 |
x.device | 所在设备 | cpu 或 cuda:0 等 |
x.ndim | 维度数 | 0 标量、1 向量、2 矩阵、3+ 高维张量 |
3.3 张量的数据类型
浮点类型:
torch.float32(默认):32位浮点数,平衡精度与速度
torch.float64:64位双精度浮点数
torch.float16:16位半精度,适合 GPU 推理
torch.bfloat16:16位脑浮点数,特定硬件加速整数类型:
torch.int8,torch.uint8:8位整数
torch.int16,torch.int32,torch.int64:16/32/64位整数其他类型:
torch.bool:布尔类型
torch.complex64,torch.complex128:复数类型
3.4 张量基本计算
基本运算(逐元素计算)
a = torch.tensor([1.0, 2.0, 3.0])
b = torch.tensor([4.0, 5.0, 6.0])# 逐元素运算
c = a + b # 加法
c = torch.add(a, b) # 等效
c = a - b # 减法
c = a * b # 逐元素乘法(Hadamard积)
c = a / b # 除法
c = a ** 2 # 幂运算
矩阵乘法
# 2D张量
m1 = torch.randn(3, 4)
m2 = torch.randn(4, 5)# 矩阵乘法
result = torch.matmul(m1, m2) # 推荐
result = m1 @ m2 # Python 3.5+语法# 批量矩阵乘法
batch1 = torch.randn(10, 3, 4)
batch2 = torch.randn(10, 4, 5)
result = torch.bmm(batch1, batch2) # 形状: (10, 3, 5)归约计算
x = torch.tensor([[1, 2, 3], [4, 5, 6]], dtype=torch.float32)sum_all = x.sum() # 全部元素求和
sum_dim0 = x.sum(dim=0) # 按第0维求和: [5, 7, 9]
sum_dim1 = x.sum(dim=1) # 按第1维求和: [6, 15]mean = x.mean() # 平均值
max_val, max_idx = x.max(dim=0) # 最大值及索引
std = x.std() # 标准差
norm = x.norm() # 欧几里得范数索引与切片
x = torch.arange(12).reshape(3, 4)# 基本索引
print(x[0, 1]) # 标量: 1
print(x[0]) # 第0行: tensor([0, 1, 2, 3])# 切片
print(x[:2, 1:3]) # 前两行,第1-2列# 高级索引
indices = torch.tensor([0, 2])
print(x[indices]) # 取第0行和第2行# 布尔掩码
mask = x > 5
print(x[mask]) # 所有大于5的元素# gather操作
index = torch.tensor([[0, 1], [2, 3]])
result = torch.gather(x, 1, index) # 按dim=1收集形状操作
x = torch.arange(12)# reshape
x_reshape = x.reshape(3, 4) # 推荐,可能返回视图
x_view = x.view(3, 4) # 要求内存连续# 转置
x_t = x_reshape.t() # 2D转置
x_transpose = x_reshape.transpose(0, 1) # 交换维度
x_perm = x_reshape.permute(1, 0) # 多维转置# 压缩/扩展
x_squeeze = torch.randn(1, 3, 1, 4).squeeze() # 移除尺寸为1的维度
x_unsqueeze = x.unsqueeze(0) # 增加维度# 拼接与拆分
a = torch.randn(2, 3)
b = torch.randn(2, 3)
cat = torch.cat([a, b], dim=0) # 在第0维拼接,形状(4, 3)stack = torch.stack([a, b], dim=0) # 新维度堆叠,形状(2, 2, 3)# 拆分
chunks = torch.chunk(cat, 2, dim=0) # 均分为2份
splits = torch.split(cat, [1, 3], dim=0) # 按大小[1,3]拆分广播机制
# 规则:从右向左对齐维度,尺寸为1或缺失的维度可扩展
a = torch.randn(3, 1, 5)
b = torch.randn( 4, 5) # 自动视为 (1, 4, 5)# 广播后形状: (3, 4, 5)
c = a + b# 实际应用
vec = torch.randn(3)
matrix = torch.randn(10, 3)
result = matrix + vec # vec自动扩展为(10, 3)3.5 把张量丢到 GPU 上
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")x = torch.rand(3, 3, device=device) # 直接在 GPU 上创建
y = torch.rand(3, 3).to(device) # 把 CPU 张量搬到 GPUz = x + y # 自动在 GPU 上计算
----------------------------------- 小tip:模型和数据必须在同一个 device 上 --------------------------------
3.6 自动求导机制
import torch# requires_grad=True 表示需要对这个张量求导
x = torch.tensor([2.0], requires_grad=True)y = x ** 2 + 3 * x + 1 # y = x^2 + 3x + 1y.backward() # 对 y 求 x 的梯度 dy/dxprint(x.grad) # tensor([7.]) => 2*2 + 3- requires_grad=True:告诉 PyTorch「以后我要对你求导」;
- 正向传播时会自动搭建计算图;
- backward() 会沿着图往回传播,算出所有需要梯度的张量的 grad
4. 使用Pytorch进行神经网络训练
要使用Pytorch进行深度学习任务,基本上都遵循如下的流程顺序:

4.1 数据集
准备数据集(两种方式)
1.直接使用Pytorch当中已经封装好的数据集,主要常见的数据集如下:
| 任务领域 | 数据集名称 | 详细介绍 | 所属库 |
|---|---|---|---|
| 🎯图像分类 | MNIST | 内容:最经典的手写数字识别数据集,包含0-9共10个类别。 数据量:60,000张训练图像,10,000张测试图像。 数据格式:28x28像素的灰度图像。 | torchvision.datasets |
| 🎯图像分类 | CIFAR-10/100 | 内容:CIFAR-10包含10个类别(如飞机、汽车、鸟等)的彩色图像;CIFAR-100则在100个更细粒度的类别上进行分类。 数据量:两者均为50,000张训练图像,10,000张测试图像。 数据格式:32x32像素的彩色(RGB)图像。 | torchvision.datasets |
| 🎯图像分类 | Fashion-MNIST | 内容:为替代MNIST而创建,包含10个类别的时尚单品(如T恤、裤子、靴子等)。 数据量:60,000张训练图像,10,000张测试图像。 数据格式:28x28像素的灰度图像。 | torchvision.datasets |
| 🎯图像分类 | ImageNet | 内容:大规模视觉识别挑战赛(ILSVRC)所使用的数据集,包含超过1,000个物体类别。 数据量:约130万张训练图像,5万张验证图像。 数据格式:彩色图像,尺寸可变,通常会被预处理为固定的分辨率(如224x224)。 | torchvision.datasets |
| 🎯目标检测与分割 | COCO | 内容:微软发布的大型、复杂数据集,支持目标检测、实例分割和图像描述生成。 数据量:约12万张训练图像,5千张验证图像,包含80个物体类别。 数据格式:图像尺寸不一,标注文件为JSON格式。 | torchvision.datasets |
| 📝文本分类 | IMDB | 内容:电影评论情感二分类数据集,任务是判断评论的情感是正面还是负面。 数据量:25,000条训练电影评论,25,000条测试评论。 | torchtext.datasets |
| 📝机器翻译 | IWSLT | 内容:国际口语翻译研讨会提供的口语翻译数据集,包含多种语言之间的互译,常用的是英语-德语和英语-法语。 数据量:数据量随年份和语言对而变化,例如IWSLT'2017德英翻译约20万条平行句对。 | torchtext.datasets |
| 🎵音频识别 | VoxCeleb1 | 内容:包含1,251位名人说话的音频片段,常用于说话人验证和识别任务。 数据量:超过150,000个片段,源自真实的访谈视频。 数据格式:原始视频中提取的音频。 | torchaudio.datasets |
| 🎵音频识别 | LibriSpeech | 内容:包含约1,000小时英语朗读语音的大规模语料库,源自有声读物,常用于训练自动语音识别系统。 数据量:约960小时的训练语音数据。 数据格式:16kHz的音频及对应的转录文本。 | torchaudio.datasets |
2. 从官网上下载或自定义的数据集
Kaggle数据集
HuggingFace 数据集
UCI Machine Learning Repository 最经典、最老牌的 ML 数据集仓库
- 各大科研竞赛平台:如天池、DataFountain、KDD Cup 等。
- 各顶会附带的开源数据集(CVPR、NeurIPS、ACL 等论文附带链接)。
- GitHub 里的仓库(搜索 pytorch dataset + 任务名)。
导入数据集
不管什么任务,基本上都是【三步走】👇

什么是Dataset,DataLoader ?
Dataset 实际上是一个抽象类,用于管好数据的 “库存”,负责单个数据的存储和提取(“仓库管理员”);主要包括三个方法,方便对我们的数据集进行读取。

而在模型训练时,通常不是一张一张处理数据(太慢),而是 “一批一批” 处理(比如一次处理 32 张)数据,还需要打乱顺序(避免模型 “死记硬背” 顺序)。
DataLoader 相当于一个 “智能搬运工”:
-
它从
DataSet这个仓库里,按照你指定的 “批量大小”(比如一次搬 32 个),把数据打包成 “批次”; -
可以帮你 “打乱顺序”(
shuffle=True),让每次训练时数据顺序不同,避免模型学歪; -
还能启动 “多线程”(
num_workers)并行同时搬运,加快速度(比如仓库很大,一个人搬一批货物太慢,派 5 个人一起搬同一批货物)。
简单说,DataLoader 负责 “批量取数据、打乱顺序、并行加速”,让数据能高效喂给模型训练。

而在pytorch中,DataLoader结构如下:
DataLoader(dataset,batch_size=1,shuffle=False,sampler=None,batch_sampler=None,num_workers=0,collate_fn=None,pin_memory=False,drop_last=False,timeout=0,worker_init_fn=None,multiprocessing_context=None,
)主要参数意义如下:
1.
dataset
你要迭代的数据集对象(必须实现
__len__和__getitem__)。通常就是
Dataset子类实例,或TensorDataset等。2.
batch_size
含义:每个 mini-batch 的样本数。
影响:
太大:GPU 显存爆炸 / OOM。
太小:梯度估计噪声大,训练不稳定,吞吐也下降。
经验:
CV 小图(CIFAR10 级别):64 ~ 256 常见。
大图(ImageNet 224×224):16 ~ 128,根据显存调整。
NLP 变长文本:batch_size 和最大序列长度一起决定显存,常在 16 ~ 64。
调参策略:先用你 GPU 能承受的最大 batch_size,训练不稳定时再适当减小。
3.
shuffle
True:每个 epoch 里随机打乱样本顺序;
False:按原始顺序遍历。经验:
训练集:必须 True(除非你使用自定义
Sampler)。验证 / 测试集:False 即可。
注意:如果你指定了
sampler,就不能再设shuffle=True。4.
num_workers
含义:用多少个子进程并行加载数据。
0:数据在主进程加载(最简单,但往往速度慢)。推荐设置:
Windows 新手:先用
0或2,处理多进程容易出坑。Linux / WSL / 容器:可以设为
CPU 核心数的 1/2 ~ 1 倍,比如 8 核 CPU 用 4~8。现象:
如果训练时 GPU 经常空闲,可能需要把
num_workers调大。如果因为内存或 IO 太慢而卡死,可以适当调小。
5.
pin_memory
作用:将 batch 放到固定内存(pinned memory)中,配合
.to(device, non_blocking=True)加速从 CPU 到 GPU 的拷贝。推荐:
如果你在 GPU 上训练:设成 True(几乎总是收益)。
CPU 训练:无所谓,默认 False。
6.
drop_last
True:如果最后一个 batch 样本数不足batch_size,就丢弃。
False:保留最后一个小 batch。推荐:
训练集 + 有 BatchNorm / 需要固定 batch_size 的情况:可以 True。
验证 / 测试:一般 False,保留所有样本。
7.
collate_fn
作用:告诉 DataLoader「如何把
__getitem__得到的一份份样本,组合成一个 batch」。默认行为:
对于
(tensor, tensor)这类简单结构,会在第 0 维堆叠,例如[C,H,W]->[B,C,H,W]。你需要自定义的情形:
文本长度不同,需要自己 pad;
一张图片对应多个框 / 多个目标;
想对某些字段做特殊处理(如打包成 dict,或过滤某些样本)。
至此,我们可以整理出一份通用的,用于深度学习的导入数据集代码:
from torch.utils.data import Dataset, DataLoader# 1. 准备 Dataset(官方的 / 自定义的都行)
dataset = MyDataset(...)# 2. (可选)切分训练 / 验证
train_set, val_set = torch.utils.data.random_split(dataset, [num_train, num_val])# 3. 用 DataLoader 包装
train_loader = DataLoader(train_set,batch_size=64,shuffle=True,num_workers=4)
val_loader = DataLoader(val_set,batch_size=64,shuffle=False,num_workers=4)
示例,以视觉数据集CIFAR10为例子:
import torch
from torch.utils.data import DataLoader
from torchvision import datasets, transforms# 1. 定义预处理
transform = transforms.Compose([transforms.ToTensor(), # HWC -> CHW & [0, 255] -> [0, 1]transforms.Normalize((0.5,), (0.5,)) # 简单归一化
])# 2. 加载训练集和测试集
train_dataset = datasets.CIFAR10(root="data/cifar10",train=True,transform=transform,download=True
)
test_dataset = datasets.CIFAR10(root="data/cifar10",train=False,transform=transform,download=True
)# 3. 用 DataLoader 包一层(后面详细讲)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
如果采取的是自定义的数据集,就只能自行根据数据的结构,定义出Dataset抽象类,再配合DataLoader使用,这里给出一个用于自定义数据集的通用模板,可根据实际需要进行调配:
import os
from torch.utils.data import Datasetclass MyDataset(Dataset):def __init__(self, data_list, labels, transform=None):"""data_list: 可以是文件路径列表 / 事先处理好的数据列表labels: 与 data_list 同长的标签列表transform: 对样本的预处理函数"""self.data_list = data_listself.labels = labelsself.transform = transformdef __len__(self):return len(self.data_list)def __getitem__(self, idx):# 1. 读取原始样本x_path = self.data_list[idx]y = self.labels[idx]# 举例:如果是图片,可以用 PIL / OpenCV 读取from PIL import Imagex = Image.open(x_path).convert("RGB")# 2. 预处理if self.transform is not None:x = self.transform(x)return x, y
在配合DataLoader使用即可
dataset = MyDataset(image_paths, labels, transform=transform)
loader = DataLoader(dataset, batch_size=32, shuffle=True, num_workers=4)
4.2 构建模型架构
神经网络训练过程
不太了解神经网络过程的uu,可以看看我的前一篇文章👆
在 PyTorch 里,网络 = 一堆 nn.Module 积木 + 一个 forward 函数 + 你自己对数据形状的把握。
搭建的网络架构,代码都遵循以下格式:
import torch
import torch.nn as nnclass MyNet(nn.Module):def __init__(self):super().__init__() # 固定写法# 在这里堆积木self.fc1 = nn.Linear(784, 256)self.act = nn.ReLU()self.fc2 = nn.Linear(256, 10)def forward(self, x):# x: [batch_size, 784]x = self.fc1(x)x = self.act(x)x = self.fc2(x)return xnet = MyNet()
- __init__ 里定义网络结构(层、子网络)。
- forward 里规定数据怎么流过这些层。
PyTorch 已经封装好的“积木”
常用模块速查表
| 类型 | 模块 | 说明 |
|---|---|---|
| 全连接 | nn.Linear | MLP、分类头 |
| 卷积 | nn.Conv2d | 图像任务核心 |
| 池化 | nn.MaxPool2d, nn.AvgPool2d | 降采样 |
| 归一化 | nn.BatchNorm1d/2d, LayerNorm | 稳定训练 |
| 正则 | nn.Dropout | 防止过拟合 |
| 组合 | nn.Sequential | 顺序拼接 |
1. 容器型(用来组合模块)
1)nn.Sequential:按顺序堆积木
backbone = nn.Sequential(nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.MaxPool2d(2),nn.Conv2d(16, 32, 3, 1, 1),nn.ReLU(),nn.MaxPool2d(2)
)
特点:简单,适合“串起来”的网络。
2)nn.ModuleList:存一列模块,自定义顺序
self.layers = nn.ModuleList([nn.Linear(128, 128),nn.Linear(128, 128),nn.Linear(128, 128),
])def forward(self, x):for layer in self.layers:x = torch.relu(layer(x))return x
适合:循环结构、动态层数、可变深度。
3)nn.ModuleDict:字典形式存模块
self.blocks = nn.ModuleDict({"down1": nn.Conv2d(3, 64, 3, 1, 1),"down2": nn.Conv2d(64, 128, 3, 1, 1)
})
适合:根据 key 选择不同子网络的情况(多任务、多分支)。
2. 基础层:全连接、卷积、循环网络等
(1)全连接层 / MLP
-
nn.Linear(in_features, out_features) -
常用于:表格数据、图像最终分类 head、Transformer 中的 FFN 等。
相当于对每一个样本做一次线性变换:![]()
- in_features:输入特征维度(最后一维)
- out_features:输出特征维度(最后一维)
- 输入 x 的形状:[..., in_features] ;输出 y 的形状:[..., out_features]
(中间的 batch/time 维度都保留,只有最后一维变)
fc = nn.Linear(128, 64)
x = torch.randn(32, 128) # [batch=32, 128]
y = fc(x) # [32, 64]fc = nn.Linear(128, 64) # [B, 128] -> [B, 64]
(2)卷积层
- Conv1d(一维卷积核):序列(1D 信号、语音、部分时间序列)
- Conv2d(二维卷积核):图片(最常用)
- Conv3d(三维卷积核):视频、体数据(CT、MRI)
以二维卷积为例子:
nn.Conv2d(in_channels, # 输入通道数,例如 RGB 图像是 3out_channels, # 卷积核个数 = 输出通道数kernel_size, # 卷积核大小,int 或 tuple,如 3 / (3,3)stride=1, padding=0,dilation=1,groups=1,bias=True
)
这里的kernel_size为卷积核的大小,stride为步长,padding为填充,关于卷积神经网络以及接下来的循环神经网络等架构的具体内容,将会在后续章节更新~
输入:[B, C_in, H_in, W_in]
输出:[B, C_out, H_out, W_out]
常见的坑:
忘记
padding=1导致尺寸快速缩小或不匹配。
in_channels写错:比如上一层输出是 64,你却写 Conv2d(32, 64, ...),会报 shape 错。与全连接层的衔接:
输出是[B, C, H, W],需要x.view(x.size(0), -1)展平成[B, C*H*W]再接 Linear。
(3)循环网络 / 序列模型
-
nn.RNN,nn.LSTM,nn.GRU -
nn.Transformer,nn.TransformerEncoder,nn.MultiheadAttention
处理序列数据(文本、时间序列等)。
核心思想:当前时刻的输出依赖于当前输入 + 上一时刻的隐藏状态。
以LSTM为例:
nn.LSTM(input_size,hidden_size,num_layers=1,bias=True,batch_first=False,dropout=0.0,bidirectional=False
)
- input_size:每个时间步的输入向量维度(比如 embedding_dim)
- hidden_size:隐藏状态维度(可以理解为“记忆容量”)
- num_layers:堆叠 LSTM 的层数
- batch_first:True:输入 x 形状 [B, T, input_size];False:[T, B, input_size](默认为 False)
- bidirectional:双向 LSTM 时为 True(输出 hidden_size×2)
输入 x:
- 若 batch_first=True:[B, T, D]
输出:
- output:每个时间步的输出,形状 [B, T, hidden_size * num_directions]
- (h_n, c_n):每层最后一个时间步的隐藏态/细胞态
3.各种常见“辅助积木”
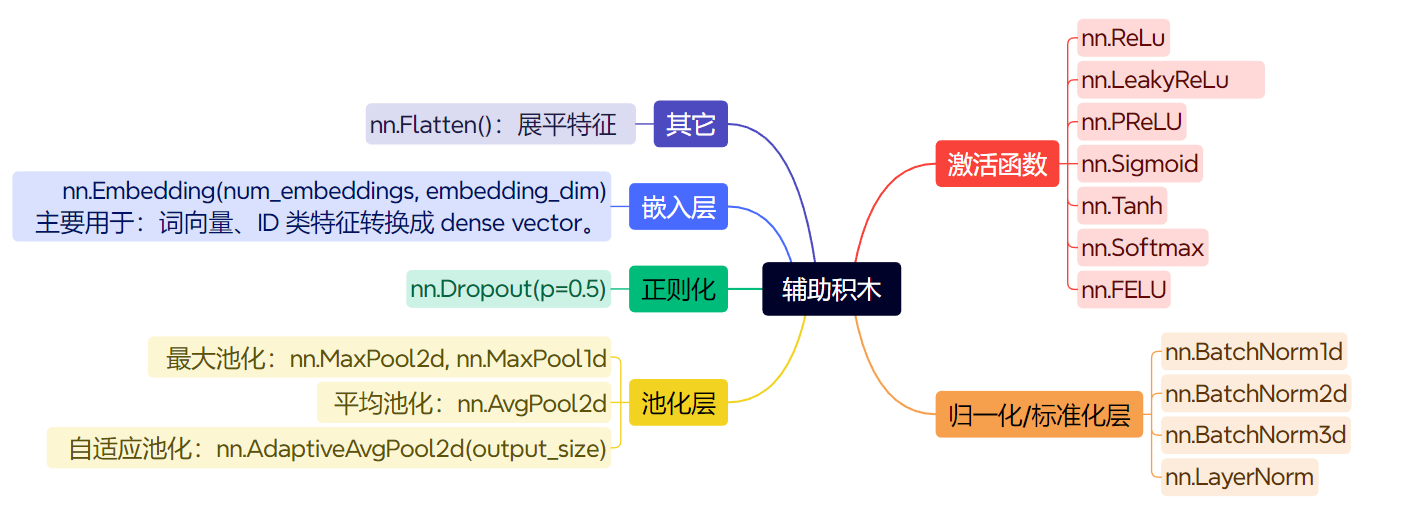
之后用到了,在具体说明这些辅助积木。
一些常见的问题:
如何“针对任务”设计网络?
答:可以记一个通用框架:输入 → 特征抽取模块(backbone) → 特征聚合(pooling / attention) → 任务 head(分类/回归/检测/分割等)
图像:Conv 堆叠 + 下采样 + GAP + Linear。
文本:Embedding + RNN/Transformer + pooling + Linear。
表格:MLP。
想偷懒,可以直接拿 ResNet、VGG、Transformer 这类成熟架构做迁移学习。
PyTorch 会不会自动帮我推导维度,然后把 Linear 的 in_features 也帮我设置好?
答: 不会,Linear 的输入/输出维度需要你自己一致地设置。forward那我是不是要手动算每一层卷积/池化之后的 H、W?
答:早期确实很多人用公式算,现在常见做法是:“写大致结构 → 用一张假数据跑一次 forward → 打印 shape → 再把 Linear 的 in_features 写死”。
4.3 损失函数
这里给出了pytorch中封装好的几类损失函数,可自查使用;而对于每个损失函数具体的公式定义,以及数学原理,因篇幅有限,不在这里做赘述。
| 任务类型 | 推荐损失函数 | 说明 |
|---|---|---|
| 标准多分类(单标签) | nn.CrossEntropyLoss | 输入 logits,target 是类别索引,最常用 |
| 单输出二分类 | nn.BCEWithLogitsLoss 或 2 类 CrossEntropyLoss | 建议首选 BCEWithLogits(输出 1 维) |
| 多标签分类 | nn.BCEWithLogitsLoss | 每个类别独立二分类,target 是 0/1 向量 |
| 标准回归(连续值) | nn.MSELoss | 默认选择,简单有效 |
| 噪声多的回归/鲁棒 | nn.L1Loss / nn.SmoothL1Loss | 对离群点更稳定 |
| 目标检测框回归 | nn.SmoothL1Loss / 自定义 IoU/GIoU Loss | 检测库里常见 |
| 语音/序列对齐 | nn.CTCLoss | 解决对齐问题的特殊损失 |
| 知识蒸馏/分布拟合 | nn.KLDivLoss | 需要 log_prob + prob 处理 |
| 度量学习/相似度 | nn.CosineEmbeddingLoss, nn.TripletMarginLoss | 学习 embedding 空间结构 |
4.4 优化器
在深度学习中,优化器(Optimizer) 是模型训练的 “核心引擎”,它的作用是:根据模型预测的误差(损失函数),自动调整模型参数(如权重、偏置),让模型逐渐 “学会” 正确的规律(即最小化损失函数)。
简单说,模型训练的本质是 “找一组最优参数”,让损失函数(预测值与真实值的差距)尽可能小。这个过程类似 “下山”:损失函数的曲面像一座山,参数是坐标,优化器就是 “找到下山最快路径” 的方法 —— 它根据当前位置的 “坡度”(损失函数的梯度),决定下一步往哪个方向走、走多远(参数更新的方向和幅度)。
PyTorch 的 torch.optim 模块提供了多种优化器,核心区别在于 “如何利用梯度更新参数”,适用于不同场景。以下是最常用的几种:
1. SGD(随机梯度下降,Stochastic Gradient Descent)
- 核心逻辑:最基础的优化器,参数更新公式为:
参数 = 参数 - 学习率 × 梯度(“随机” 指每次用一个 batch 的梯度近似整体梯度,而非全量数据,提高效率)。- 优点:简单、计算量小,适合大规模数据和简单模型,泛化性较好(不容易过拟合)。
- 缺点:收敛速度慢(可能在局部最优附近震荡),对学习率敏感(需要手动调参)。
- 变种:SGD + Momentum(动量)加入 “动量”(模拟物理中的惯性),减少震荡,加速收敛。公式为:
动量 = 动量因子 × 上一次动量 + 梯度参数 = 参数 - 学习率 × 动量(动量因子通常取 0.9,相当于 “记住” 之前的更新方向,避免来回摇摆)。2. Adam(Adaptive Moment Estimation)
- 核心逻辑:结合了 “动量”(加速收敛)和 “自适应学习率”(不同参数用不同学习率)的优点,是目前最常用的优化器之一。
- 自适应学习率:对更新频繁的参数(如高频特征)用小学习率,对更新少的参数(如低频特征)用大学习率,避免 “一刀切”。
- 动量:保留之前的更新方向,减少震荡。
- 优点:收敛速度快,对学习率不敏感(调参简单),适用于大多数场景(尤其是复杂模型,如 Transformer、CNN)。
- 缺点:在某些简单任务上可能泛化性略差于 SGD+Momentum;训练后期可能在最优值附近震荡。
3. RMSprop(Root Mean Square Propagation)
- 核心逻辑:解决 Adagrad 学习率随迭代次数单调递减的问题,通过 “指数移动平均” 调整学习率(只关注近期梯度的平方)。
- 优点:收敛稳定,适合处理非平稳目标(如递归神经网络 RNN)。
- 缺点:需要手动调整动量参数(可选),适用场景比 Adam 略窄。
4. Adagrad(Adaptive Gradient Algorithm)
- 核心逻辑:为每个参数维护一个 “累计梯度平方和”,学习率随累计值增大而减小(即 “越常更新的参数,学习率越小”)。
- 优点:适合处理稀疏数据(如文本,大部分特征出现频率低),无需手动调学习率。
- 缺点:学习率会逐渐趋近于 0,导致训练后期无法更新参数,实际中较少单独使用。
5. Adadelta
- 核心逻辑:改进 Adagrad 的 “学习率衰减至 0” 问题,用 “参数更新量的移动平均” 代替 “累计梯度平方和”,甚至可以省去手动设置学习率。
- 优点:训练稳定,适合长周期任务。
- 缺点:收敛速度略慢于 Adam,适用场景有限。
6. AdamW
- 核心逻辑:Adam 的改进版,将 “权重衰减(Weight Decay)” 从梯度更新中分离出来,更严格地实现 L2 正则化,避免 Adam 原生权重衰减的偏差。
- 优点:在需要强正则化的场景(如 Transformer)中表现更稳定,泛化性优于 Adam。
- 缺点:计算量略大于 Adam,简单任务优势不明显。
如何选择优化器?
优化器的选择没有 “绝对正确” 的答案,需结合模型类型、数据特点、训练目标综合判断。以下是一些个人看法:
1. 优先尝试 “开箱即用” 的优化器
- 新手 / 快速实验:首选 Adam 或 AdamW。它们对学习率不敏感(默认学习率 1e-3 通常可用),收敛快,适合大多数模型(CNN、Transformer、MLP 等)。
- 追求泛化性 / 稳定训练:选 SGD + Momentum(动量 0.9)。尤其在简单模型(如 LeNet)或数据量极大的场景中,泛化性可能优于 Adam。
2. 根据数据特点选择
- 稀疏数据(如文本、推荐系统):可尝试 Adagrad 或 RMSprop(但 Adam 通常也能应对)。
- 非平稳数据(如时序数据、RNN):RMSprop 或 Adam 更稳定(避免梯度剧烈波动)。
3. 根据模型复杂度选择
- 复杂模型(如 Transformer、大 CNN):优先 AdamW(强正则化,避免过拟合)。
- 简单模型(如线性回归、小 CNN):SGD + Momentum 足够,且计算成本更低。
4. 特殊场景
- 训练不稳定(损失波动大):检查学习率,或换用 Adam(自适应学习率更稳定)。
- 需长周期训练:Adadelta 或 RMSprop(避免学习率衰减过快)。
4.5 循环训练
这里先区分,理解一下一些基本概念batch,epoch,Iteration。
我们以做作业为例子:

1. epoch(“轮次”)
假设你要训练模型,手里有 1000 道 “习题”(即 1000 个训练数据)。epoch 就是 “把这 1000 道题完整做一遍” 的过程。
比如:
- 第 1 个 epoch:从头到尾做完 1000 道题;
- 第 2 个 epoch:再从头到尾做完 1000 道题(相当于复习第二遍)。
模型训练通常需要多个 epoch(比如 10 轮、50 轮),因为只做一遍题(1 个 epoch)模型学不扎实,多做几遍才能记住规律。
2. batch(“批次”)
做 1000 道题时,你不会一次性全做完(太累,相当于模型一次性处理所有数据会占满内存),而是分 “批次” 做。batch 就是 “每次做的一小堆题”,比如每次做 32 道,这 32 道题就是 1 个 batch(批次大小 = 32)。
为什么要分 batch?
- 内存有限:1000 张图片一次性塞给模型,电脑内存可能装不下;
- 训练更稳定:分批做能让模型每做一批就调整一次 “思路”(更新参数),避免一次性学太多导致 “记混”。
3. Iteration(“迭代”)
“迭代” 就是 “完成 1 个 batch 的动作”。比如 1000 道题,每次做 32 道(batch size=32):
- 第 1 次迭代:做第 1-32 题;
- 第 2 次迭代:做第 33-64 题;
- ...
- 第 32 次迭代:做最后剩下的 28 道题(1000÷32≈31.25,向上取整为 32 次)。
所以,1 个 epoch 里的迭代次数 = 总数据量 ÷ batch 大小(有余数则加 1)。
总结关系
- 1 个
epoch= 把所有数据完整过 1 遍; - 1 个
epoch包含 N 个Iteration(N = 总数据量 ÷ batch 大小); - 1 个
Iteration= 处理 1 个batch的数据。
记住:模型训练的过程,就是 “多轮(epoch)做题,每轮分批次(batch)做,每批做一次(Iteration)就调整一次思路”。
区分了上述概念,下面的模板代码基本上也能看懂了
for epoch in range(num_epochs):model.train() # 训练模式(启用 Dropout、BN 等)for batch_x, batch_y in train_loader:batch_x, batch_y = batch_x.to(device), batch_y.to(device)# 1. 清空梯度optimizer.zero_grad()# 2. 正向传播logits = model(batch_x)# 3. 计算损失loss = criterion(logits, batch_y)# 4. 反向传播loss.backward()# 5. 更新参数optimizer.step()
验证/测试循环模板
def evaluate(model, data_loader):model.eval() # 评估模式:关闭 dropout / BN 的训练行为correct = 0total = 0total_loss = 0.0with torch.no_grad(): # 不需要梯度for x, y in data_loader:x, y = x.to(device), y.to(device)logits = model(x)loss = criterion(logits, y)total_loss += loss.item() * x.size(0)pred = logits.argmax(dim=1)correct += (pred == y).sum().item()total += y.size(0)avg_loss = total_loss / totalacc = correct / totalreturn avg_loss, acc4.6 超参数优化
超参数 ≈ 你手动设定的“旋钮”,比如:
-
学习率
lr -
batch size
-
epoch 数
-
模型大小(层数、每层宽度)
-
正则化:
dropout、weight_decay -
优化器种类、激活函数种类
-
数据增强强度等等
一般可遵循如下的流程:
-
先跑通:
-
用一个非常小的数据集(例如 10% 数据),看能否过拟合(训练集精度接近 100%)。
-
如果 10% 训练集都过拟合不了,多半模型/代码有 bug 或 lr 太大/太小。
-
-
关注两条曲线:训练集 vs 验证集
-
训练 loss 一直不降:
-
可能 lr 太小 / 模型太弱 / 代码有问题。
-
-
训练 loss 降得很快但验证 loss 上升:
-
过拟合:增大正则(dropout、weight_decay),做数据增强或减小模型。
-
-
-
粗调 → 细调
-
粗调:用 {1e−1,1e−2,1e−3,1e−4}级别尝试 lr;
-
找到一个“可用”区间后再细调(比如在
3e-4,1e-3,3e-3之间试)。
-
-
记录实验 & 固定随机种子
import torch, random, numpy as npdef set_seed(seed=42):random.seed(seed)np.random.seed(seed)torch.manual_seed(seed)torch.cuda.manual_seed_all(seed)
当然你也可以使用一些高阶操作来进行超参数调优:
-
使用
Ray Tune,Optuna等工具做自动化搜索; -
使用 学习率搜索(LR finder) 来找到合适 lr 区间。
4.7 从零到一的完整 Demo:MNIST 手写数字分类
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader# 1. 设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("Using device:", device)# 2. 数据集(MNIST)
transform = transforms.Compose([transforms.ToTensor(), # [0,1]transforms.Normalize((0.1307,), (0.3081,)) # 标准化
])train_dataset = datasets.MNIST(root="./data", train=True, download=True, transform=transform
)
test_dataset = datasets.MNIST(root="./data", train=False, download=True, transform=transform
)train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=1000, shuffle=False)# 3. 定义模型(一个简单的 CNN)
class SimpleCNN(nn.Module):def __init__(self):super().__init__()self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1) # 1x28x28 -> 32x28x28self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1) # 32x28x28 -> 64x28x28self.pool = nn.MaxPool2d(2, 2) # H,W / 2self.fc1 = nn.Linear(64 * 7 * 7, 128)self.fc2 = nn.Linear(128, 10)def forward(self, x):x = torch.relu(self.conv1(x))x = self.pool(x) # 32x14x14x = torch.relu(self.conv2(x))x = self.pool(x) # 64x7x7x = x.view(x.size(0), -1) # 展平成 [batch, 64*7*7]x = torch.relu(self.fc1(x))x = self.fc2(x) # [batch, 10] logitsreturn xmodel = SimpleCNN().to(device)# 4. 损失 + 优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)# 5. 训练 + 测试函数
def train_one_epoch(epoch):model.train()total_loss = 0.0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()total_loss += loss.item()avg_loss = total_loss / len(train_loader)print(f"Epoch {epoch}: train loss = {avg_loss:.4f}")def evaluate():model.eval()correct = 0total = 0with torch.no_grad(): # 评估阶段不需要梯度for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)# 取每行最大值的下标作为预测类别pred = output.argmax(dim=1)correct += (pred == target).sum().item()total += target.size(0)acc = correct / totalprint(f"Test accuracy: {acc:.4f}")# 6. 训练若干轮并测试
for epoch in range(1, 4): # 跑 3 个 epoch 体验一下train_one_epoch(epoch)evaluate()
完结撒花*★,°*:.☆( ̄▽ ̄)/$:*.°★* 。