asm磁盘组扩容加错磁盘
一、现象
1、某次磁盘组扩容的时候,执行命令如下:
SQL> alter diskgroup DATA add disk '/dev/mapper/asm_disk2' rebalance power 5
2、随即磁盘组出现异常
NOTE: GroupBlock outside rolling migration privileged region
NOTE: Assigning number (2,8) to disk (/dev/mapper/asm_disk2)
NOTE: requesting all-instance membership refresh for group=2
NOTE: initializing header on grp 2 disk DATA_0008 --将其命名为DATA_008磁盘
NOTE: requesting all-instance disk validation for group=2
Wed Sep 21 22:51:21 2022
NOTE: skipping rediscovery for group 2/0xf3a0ef0 (DATA) on local instance.
NOTE: requesting all-instance disk validation for group=2
NOTE: skipping rediscovery for group 2/0xf3a0ef0 (DATA) on local instance.
NOTE: initiating PST update: grp = 2
Wed Sep 21 22:51:26 2022
GMON updating group 2 at 16 for pid 36, osid 15491
NOTE: PST update grp = 2 completed successfully
NOTE: membership refresh pending for group 2/0xf3a0ef0 (DATA)
GMON querying group 2 at 17 for pid 18, osid 29435
NOTE: cache opening disk 8 of grp 2: DATA_0008 path:/dev/mapper/asm_disk2
Wed Sep 21 22:51:29 2022
Received dirty detach msg from inst 2 for dom 2
Wed Sep 21 22:51:29 2022
List of instances:
1 2
Dirty detach reconfiguration started (new ddet inc 1, cluster inc 108) ----发现磁盘头信息是脏的,需要清理,并重新配置
Global Resource Directory partially frozen for dirty detach
* dirty detach - domain 2 invalid = TRUE
2266 GCS resources traversed, 0 cancelled
Dirty Detach Reconfiguration complete
Wed Sep 21 22:51:35 2022
NOTE: SMON starting instance recovery for group DATA domain 2 (mounted)
NOTE: F1X0 found on disk 0 au 2 fcn 0.109291829
NOTE: SMON skipping disk 1 - no header
NOTE: cache initiating offline of disk 1 group DATA
NOTE: process _smon_+asm1 (29433) initiating offline of disk 1.3916103235 (DATA_0001) with mask 0x7e in group 2
WARNING: Disk 1 (DATA_0001) in group 2 in mode 0x7f is now being taken offline on ASM inst 1 --将DATA_001磁盘offline
NOTE: initiating PST update: grp = 2, dsk = 1/0xe96afe43, mask = 0x6a, op = clear
GMON updating disk modes for group 2 at 18 for pid 17, osid 29433
ERROR: Disk 1 cannot be offlined, since diskgroup has external redundancy.
ERROR: too many offline disks in PST (grp 2)
Wed Sep 21 22:51:35 2022
NOTE: cache dismounting (not clean) group 2/0x0F3A0EF0 (DATA)
WARNING: Offline of disk 1 (DATA_0001) in group 2 and mode 0x7f failed on ASM inst 1
Wed Sep 21 22:51:35 2022
NOTE: halting all I/Os to diskgroup 2 (DATA)
ERROR: No disks with F1X0 found on disk group DATA
NOTE: aborting instance recovery of domain 2 due to diskgroup dismount
NOTE: SMON skipping lock domain (2) validation because diskgroup being dismounted
Abort recovery for domain 2
NOTE: messaging CKPT to quiesce pins Unix process pid: 16940, image: oracle@ccmsdb01 (B000)
Wed Sep 21 22:51:35 2022
NOTE: LGWR doing non-clean dismount of group 2 (DATA)
NOTE: LGWR sync ABA=6319.4496 last written ABA 6319.4496
kjbdomdet send to inst 2
detach from dom 2, sending detach message to inst 2
List of instances:
1 2
Dirty detach reconfiguration started (new ddet inc 2, cluster inc 108)
Global Resource Directory partially frozen for dirty detach
* dirty detach - domain 2 invalid = TRUE
2140 GCS resources traversed, 0 cancelled
Dirty Detach Reconfiguration complete
freeing rdom 2
Wed Sep 21 22:51:36 2022
WARNING: dirty detached from domain 2
NOTE: cache dismounted group 2/0x0F3A0EF0 (DATA)
SQL> alter diskgroup DATA dismount force /* ASM SERVER */ --强制dismount
Wed Sep 21 22:51:36 2022
NOTE: Attempting voting file refresh on diskgroup DATA
Wed Sep 21 22:51:36 2022
GMON querying group 2 at 19 for pid 18, osid 29435
SUCCESS: refreshed membership for 2/0xf3a0ef0 (DATA)
Wed Sep 21 22:51:36 2022
NOTE: cache deleting context for group DATA 2/0x0f3a0ef0
ERROR: ORA-15130 thrown in RBAL for group number 2 --平衡数据失败
SUCCESS: alter diskgroup DATA add disk '/dev/mapper/asm_disk2' rebalance power 5 --添加asm_disk2 成功
Errors in file /u01/app/grid/diag/asm/+asm/+ASM1/trace/+ASM1_rbal_29435.trc:
ORA-15130: diskgroup "" is being dismounted
NOTE: starting rebalance of group 2/0xf3a0ef0 (DATA) at power 5
ERROR: ORA-15130 thrown in RBAL for group number 2
Errors in file /u01/app/grid/diag/asm/+asm/+ASM1/trace/+ASM1_rbal_29435.trc:
ORA-15130: diskgroup "" is being dismounted
Errors in file /u01/app/grid/diag/asm/+asm/+ASM1/trace/+ASM1_rbal_29435.trc:
ORA-15130: diskgroup "" is being dismounted --DATA磁盘组dismount二、分析处置
1、查看目前主机上的磁盘
kfod disks=all status=true
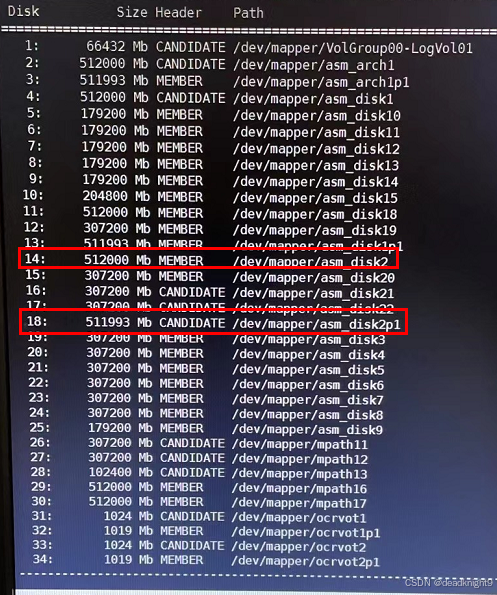
2、分析
经分析,asm_disk2是本次新加的磁盘,对应的是DATA_008;
asm_disk2p1对应的是DATA_001。
而asm_disk2 是使用fdisk做了主分区,其主分区为asm_disk2p1,前期已经对其加入了磁盘组。
本次再次将asm_disk2加入磁盘组,在加入磁盘组的过程中会将磁盘头信息重新写,造成本次异常。
3、使用kfed repair 修复磁盘头
# ./kfed repair /dev/mapper/asm_disk2p1
ASM磁盘头丢失在以前是十分麻烦的一件事情,10年前,修复DISK HEAD的费用可能高达数万元甚至十多万元。因为那时候只有少数对ASM DISKHEAD比较了解的工程师才能通过kfed工具手工修复磁盘头。到目前位置,用kfed使用常规方法修复磁盘头还是一件十分困难的事情。直到Oracle10.2.0.5开始,Oracle也意识到了asm的这个问题,在asm metadata中保留了一个备份块,这样使用 kfed的一个隐含功能就可以实现asm磁盘头的一键修复了。Kfed repair功能可以一键修复磁盘头,哪怕你对磁盘头一无所知,只要会使用这个命令就可以了。
4、使用dd命令对头文件进行备份
dd if=/dev/mapper/asm_disk2p1 of=/home/grid/disk2p1_header bs=4096 count=1
5、对新加的磁盘头信息进行重写
dd if=/dev/zero of=/dev/mapper/asm_disk2 bs=4096 count=1
6、使用备份的头文件恢复
dd if=/home/grid/disk2p1_header of=/dev/mapper/asm_disk2p1 bs=4096 count=1
7、按道理这样就能恢复,使用强制mount(未完成测试)
alter diskgroup DATA mount;
或者
alter diskgroup DATA mount force;
8、设置事件和停止平衡后,再次mount恢复正常。
su - grid
sqlplus / as sysasm
alter system set events '15195 trace name context forever, level 604' ;
alter system set asm_power_limit = 0 scopy=spfile ;
重启集群后,恢复正常。
9、mount磁盘组和拉起数据库实例后,立即开展一次数据库rman或者expdp的备份。并将业务数据迁移到新的数据库。
三、经验总结
1、asm磁盘组扩容的前建议首先备份磁盘的头文件。
dd if=/dev/mapper/asm_disk2p1 of=/home/grid/disk2p1_header bs=4096 count=1
四、相关知识
Problem Statement:
There was corruption found in one of the diskgroup and the diskgroup was dismounting as soon as the mounting is complete.
Error stack in ASM alertlog file is as below:
SQL> alter diskgroup dg02 mount
NOTE: cache registered group DG02 number=2 incarn=0xf823add8
NOTE: cache began mount (first) of group DG02 number=2 incarn=0xf823add8
NOTE: Assigning number (2,5) to disk (/dev/mapper/mpathaf)
NOTE: Assigning number (2,4) to disk (/dev/mapper/mpathae)
NOTE: Assigning number (2,1) to disk (/dev/mapper/mpathg)
NOTE: Assigning number (2,3) to disk (/dev/mapper/mpathi)
NOTE: Assigning number (2,2) to disk (/dev/mapper/mpathj)
NOTE: Assigning number (2,0) to disk (/dev/mapper/mpathh)
Thu May 15 17:41:20 2014
NOTE: GMON heartbeating for grp 2
GMON querying group 2 at 29 for pid 17, osid 10489
NOTE: cache opening disk 0 of grp 2: DG02_0000 path:/dev/mapper/mpathh
NOTE: F1X0 found on disk 0 au 2 fcn 0.721138
NOTE: cache opening disk 1 of grp 2: DG02_0001 path:/dev/mapper/mpathg
NOTE: cache opening disk 2 of grp 2: DG02_0002 path:/dev/mapper/mpathj
NOTE: cache opening disk 3 of grp 2: DG02_0003 path:/dev/mapper/mpathi
NOTE: cache opening disk 4 of grp 2: DG02_0004 path:/dev/mapper/mpathae
NOTE: cache opening disk 5 of grp 2: DG02_0005 path:/dev/mapper/mpathaf
NOTE: cache mounting (first) external redundancy group 2/0xF823ADD8 (DG02)
NOTE: starting recovery of thread=1 ckpt=62.9314 group=2 (DG02)
NOTE: advancing ckpt for group 2 (DG02) thread=1 ckpt=62.9315
NOTE: cache recovered group 2 to fcn 0.1335038
NOTE: redo buffer size is 256 blocks (1053184 bytes)
Thu May 15 17:41:20 2014
NOTE: LGWR attempting to mount thread 1 for diskgroup 2 (DG02)
NOTE: LGWR found thread 1 closed at ABA 62.9314
NOTE: LGWR mounted thread 1 for diskgroup 2 (DG02)
NOTE: LGWR opening thread 1 at fcn 0.1335038 ABA 63.9315
NOTE: cache mounting group 2/0xF823ADD8 (DG02) succeeded
NOTE: cache ending mount (success) of group DG02 number=2 incarn=0xf823add8
GMON querying group 2 at 30 for pid 13, osid 10429
Thu May 15 17:41:20 2014
NOTE: Instance updated compatible.asm to 11.2.0.0.0 for grp 2
SUCCESS: diskgroup DG02 was mounted
SUCCESS: alter diskgroup dg02 mount
The diskgroup is mounting properly. But its getting dismounted soon after. Even disabling rebalancing did not helped.
WARNING: cache read a corrupt block: group=2(DG02) dsk=0 blk=1 disk=0 (DG02_0000) incarn=3719519623 au=0 blk=1 count=1
Errors in file /grid_home/app/gridhome/diag/diag/asm/+asm/+ASM/trace/+ASM_rbal_10429.trc:
ORA-15196: invalid ASM block header [kfc.c:26076] [endian_kfbh] [2147483648] [1] [32 != 1]
NOTE: a corrupted block from group DG02 was dumped to /grid_home/app/gridhome/diag/diag/asm/+asm/+ASM/trace/+ASM_rbal_10429.trc
WARNING: cache read (retry) a corrupt block: group=2(DG02) dsk=0 blk=1 disk=0 (DG02_0000) incarn=3719519623 au=0 blk=1 count=1
Errors in file /grid_home/app/gridhome/diag/diag/asm/+asm/+ASM/trace/+ASM_rbal_10429.trc:
ORA-15196: invalid ASM block header [kfc.c:26076] [endian_kfbh] [2147483648] [1] [32 != 1]
ORA-15196: invalid ASM block header [kfc.c:26076] [endian_kfbh] [2147483648] [1] [32 != 1]
ERROR: cache failed to read group=2(DG02) dsk=0 blk=1 from disk(s): 0(DG02_0000)
ORA-15196: invalid ASM block header [kfc.c:26076] [endian_kfbh] [2147483648] [1] [32 != 1]
ORA-15196: invalid ASM block header [kfc.c:26076] [endian_kfbh] [2147483648] [1] [32 != 1]
NOTE: cache initiating offline of disk 0 group DG02
NOTE: process _rbal_+asm (10429) initiating offline of disk 0.3719519623 (DG02_0000) with mask 0x7e in group 2
WARNING: Disk 0 (DG02_0000) in group 2 in mode 0x7f is now being taken offline on ASM inst 1
NOTE: initiating PST update: grp = 2, dsk = 0/0xddb35d87, mask = 0x6a, op = clear
GMON updating disk modes for group 2 at 33 for pid 13, osid 10429
ERROR: Disk 0 cannot be offlined, since diskgroup has external redundancy.
ERROR: too many offline disks in PST (grp 2)
Solution:
1. Set event 15195 and disable rebalance in ASM instance.
SQL> alter system set events '15195 trace name context forever, level 604';
SQL> alter system set asm_power_limit = 0;
Outcome:
The diskgroup was mounted properly and stop getting dismounted. This gave us time to take a backup and restore the database / affected datafiles to a different diskgroup.
Disclaimer:
This method is not supported by oracle support unless recommended by them Oracle. The above way is not officially way and guaranteed 100%