GPU 发展简史:图形处理到通用计算的蜕变
引言
图形处理单元(GPU)最初作为专门的图形渲染硬件出现,如今已发展成为强大的通用并行处理器。这场技术革命不仅改变了计算机图形学领域,更深刻影响了科学计算、人工智能和数据分析等多个学科。本文将系统梳理GPU从专用图形处理器到通用计算引擎的演变历程。
早期阶段:专用图形处理器(1990年代)
图形加速器的诞生
1990年代初期,随着3D游戏和图形应用的需求增长,专门的图形处理硬件开始出现。这些早期GPU专注于图形管线的固定功能:
// 早期的固定功能图形管线示例
void fixed_function_pipeline(Vertex* vertices, int count) {for (int i = 0; i < count; i++) {// 变换和光照(T&L)阶段transform_vertex(&vertices[i]);apply_lighting(&vertices[i]);// 裁剪和投影clip_and_project(&vertices[i]);// 光栅化rasterize_triangle(&vertices[i]);}
}
关键技术突破
| 年代 | 代表性产品 | 主要特性 | 计算能力 |
|---|---|---|---|
| 1999 | NVIDIA GeForce 256 | 首次提出GPU概念,集成T&L引擎 | 无法通用计算 |
| 2001 | NVIDIA GeForce 3 | 可编程顶点着色器 | 有限的程序mability |
| 2002 | ATI Radeon 9700 | 支持像素着色器2.0 | 初步并行处理能力 |
可编程着色器时代(2000年代初期)
着色器模型的演进
随着DirectX 8.0和OpenGL 1.4的推出,GPU开始支持可编程着色器。这一转变标志着GPU从固定功能管线向可编程处理器的过渡。
// HLSL顶点着色器示例(DirectX 8)
VS_OUTPUT vs_main(float4 position : POSITION, float2 texcoord : TEXCOORD0) {VS_OUTPUT output;// 顶点变换output.position = mul(position, world_view_proj_matrix);output.texcoord = texcoord;return output;
}
统一着色器架构
2006年,微软推出DirectX 10,引入了统一着色器架构。这一创新彻底改变了GPU的设计哲学:
// 统一着色器架构概念示例
class UnifiedShader {
public:void execute(Thread* threads, int thread_count) {// 所有线程执行相同的指令流for (int i = 0; i < thread_count; i++) {process_thread(&threads[i]);}}private:virtual void process_thread(Thread* thread) = 0;
};
GPGPU的兴起:通用GPU计算
早期GPGPU技术
在专用通用计算API出现之前,研究人员已经发现可以利用图形API进行通用计算:
// 使用OpenGL进行通用计算的示例(2003年左右)
void gpgpu_matrix_multiply(GLuint textureA, GLuint textureB, GLuint textureResult, int size) {// 将矩阵数据存储在纹理中// 使用片段着色器执行矩阵乘法glUseProgram(matrix_multiply_shader);// 设置输入纹理glActiveTexture(GL_TEXTURE0);glBindTexture(GL_TEXTURE_2D, textureA);glActiveTexture(GL_TEXTURE1);glBindTexture(GL_TEXTURE_2D, textureB);// 渲染到输出纹理glBindFramebuffer(GL_FRAMEBUFFER, fbo);glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D, textureResult, 0);// 执行计算glDrawArrays(GL_QUADS, 0, 4);
}
CUDA的突破
2006年,NVIDIA推出CUDA(Compute Unified Device Architecture),这是第一个完整的通用并行计算架构:
// 简单的CUDA矩阵乘法示例
__global__ void matrixMultiply(float* A, float* B, float* C, int width, int height) {int row = blockIdx.y * blockDim.y + threadIdx.y;int col = blockIdx.x * blockDim.x + threadIdx.x;if (row < height && col < width) {float sum = 0.0f;for (int k = 0; k < width; k++) {sum += A[row * width + k] * B[k * width + col];}C[row * width + col] = sum;}
}// 主机代码调用内核
void host_matrix_multiply(float* h_A, float* h_B, float* h_C, int width, int height) {float *d_A, *d_B, *d_C;// 分配设备内存cudaMalloc(&d_A, width * height * sizeof(float));cudaMalloc(&d_B, width * height * sizeof(float));cudaMalloc(&d_C, width * height * sizeof(float));// 拷贝数据到设备cudaMemcpy(d_A, h_A, width * height * sizeof(float), cudaMemcpyHostToDevice);cudaMemcpy(d_B, h_B, width * height * sizeof(float), cudaMemcpyHostToDevice);// 配置并启动内核dim3 blockSize(16, 16);dim3 gridSize((width + blockSize.x - 1) / blockSize.x,(height + blockSize.y - 1) / blockSize.y);matrixMultiply<<<gridSize, blockSize>>>(d_A, d_B, d_C, width, height);// 拷贝结果回主机cudaMemcpy(h_C, d_C, width * height * sizeof(float), cudaMemcpyDeviceToHost);// 释放设备内存cudaFree(d_A);cudaFree(d_B);cudaFree(d_C);
}
OpenCL的标准化
2008年,Khronos Group发布OpenCL(Open Computing Language),为跨平台异构计算提供了开放标准:
// OpenCL矩阵乘法内核
__kernel void matrixMultiply(__global float* A, __global float* B, __global float* C,int width) {int row = get_global_id(1);int col = get_global_id(0);float sum = 0.0f;for (int k = 0; k < width; k++) {sum += A[row * width + k] * B[k * width + col];}C[row * width + col] = sum;
}
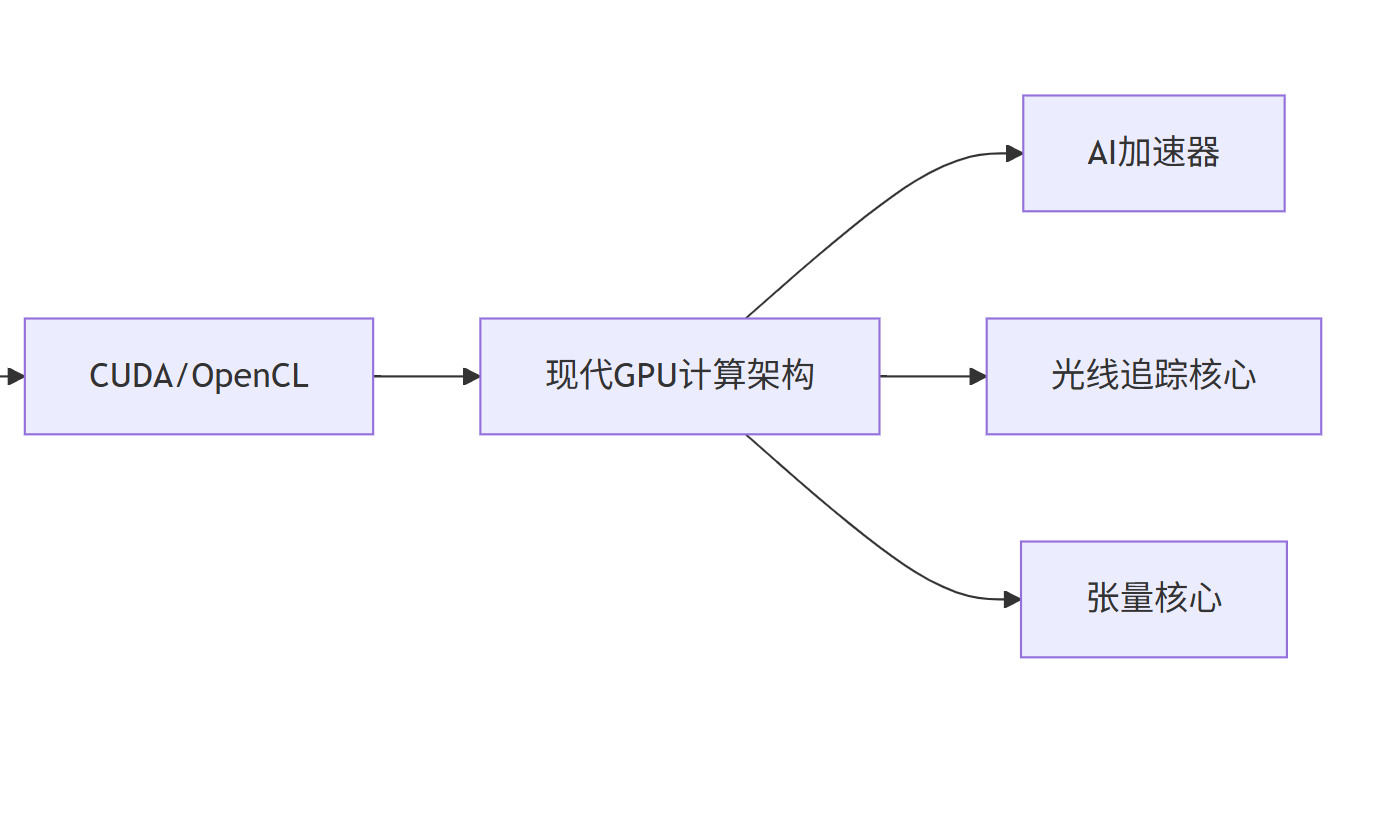
现代GPU计算架构
GPU架构演进流程图
现代GPU计算特性对比
| 架构特性 | NVIDIA Volta | AMD CDNA | Intel Xe-HPC |
|---|---|---|---|
| 张量核心 | 有 | 矩阵核心 | 暂无 |
| 光线追踪 | Turing开始 | RDNA2开始 | 支持 |
| 内存层次 | 统一内存 | HBM2E | HBM |
| 计算能力 | 7-14 TFLOPS | 12-48 TFLOPS | 竞争性性能 |
应用领域的扩展
科学计算
GPU在高性能计算领域的应用日益广泛,特别是在以下领域:
// CFD计算中的Jacobi迭代求解器示例
__global__ void jacobi_iteration(float* u_new, float* u_old, float* f, int nx, int ny) {int i = blockIdx.x * blockDim.x + threadIdx.x;int j = blockIdx.y * blockDim.y + threadIdx.y;if (i > 0 && i < nx-1 && j > 0 && j < ny-1) {u_new[j * nx + i] = 0.25f * (u_old[j * nx + (i-1)] + u_old[j * nx + (i+1)] +u_old[(j-1) * nx + i] + u_old[(j+1) * nx + i] -f[j * nx + i]);}
}
人工智能与深度学习
现代GPU专门为AI工作负载优化,特别是深度学习训练和推理:
// 简化的卷积层前向传播(概念性代码)
__global__ void conv_forward(float* input, float* weights, float* output, int batch_size,int input_channels, int output_channels,int input_height, int input_width,int kernel_size, int stride) {// 每个线程处理一个输出像素int oc = blockIdx.x; // 输出通道int h = threadIdx.y; // 输出高度int w = threadIdx.x; // 输出宽度int b = blockIdx.y; // 批次索引float sum = 0.0f;// 在输入通道上循环for (int ic = 0; ic < input_channels; ic++) {// 在卷积核上循环for (int kh = 0; kh < kernel_size; kh++) {for (int kw = 0; kw < kernel_size; kw++) {int inh = h * stride + kh;int inw = w * stride + kw;float input_val = input[b * input_channels * input_height * input_width +ic * input_height * input_width +inh * input_width + inw];float weight_val = weights[oc * input_channels * kernel_size * kernel_size +ic * kernel_size * kernel_size +kh * kernel_size + kw];sum += input_val * weight_val;}}}output[b * output_channels * output_height * output_width +oc * output_height * output_width +h * output_width + w] = sum;
}
未来发展趋势
异构计算集成
现代计算系统正朝着更紧密的CPU-GPU集成方向发展:
// C++ AMP示例展示CPU-GPU统一编程模型
#include <amp.h>
using namespace concurrency;void matrix_multiply_amp(std::vector<float>& A, std::vector<float>& B,std::vector<float>& C, int width) {array_view<const float, 2> a(width, width, A);array_view<const float, 2> b(width, width, B);array_view<float, 2> c(width, width, C);c.discard_data();parallel_for_each(c.extent, [=](index<2> idx) restrict(amp) {int row = idx[0];int col = idx[1];float sum = 0.0f;for (int k = 0; k < width; k++) {sum += a(row, k) * b(k, col);}c[idx] = sum;});c.synchronize();
}
专用加速器
除了通用计算能力,现代GPU还集成了多种专用加速器:
- 张量核心:专门用于矩阵运算,极大提升AI性能
- 光线追踪核心:硬件加速的光线追踪计算
- AI降噪器:实时降噪和图像重建
- 视频编解码器:硬件加速的视频处理
结论
GPU计算的发展历程是从专用图形处理器到通用并行计算平台的惊人转变。这一演变不仅推动了图形技术的进步,更重要的是开启了大规模并行计算的新时代。从早期的固定功能管线到现代高度并行的通用计算架构,GPU已经成为科学发现、人工智能和数据分析的关键推动力。