数据智能开发三 数据架构设计
在当今数字化时代,数据已成为企业的核心战略资源。用数据说话、用数据决策、用数据管理、用数据创新已成为企业经营管理者的普遍共识。然而,“企业都有哪些数据、这些数据都在哪里”成为企业数字化转型的首要问题
。本文将系统阐述数据架构设计的原理、方法和实践,为企业构建高效的数据架构提供完整指南。
数据架构的设计原则
业务驱动原则:数据架构必须以业务需求为导向,确保技术决策与业务目标一致。数据架构设计需要业务架构的业务流程作为输入,识别和理解业务活动环节中输入和输出的数据
全局视角规划:从企业全局视角定义数据架构,建立数据标准,形成数据共同语言。参考业界实践和商业软件包,兼顾企业现状与前瞻性
数据分类管理:基于数据特性划分数据类别,如结构化数据(基础数据、主数据、事务数据等)和非结构化数据,针对不同类别制定相应的管理策略
可扩展性与解耦:现代数据架构应设计为松耦合,使服务能够独立执行最少的任务。数据架构利用数据服务和API,将来自原有系统、数据湖、数据仓库、SQL数据库和应用程序的数据汇集在一起。
数据架构的核心组成组件
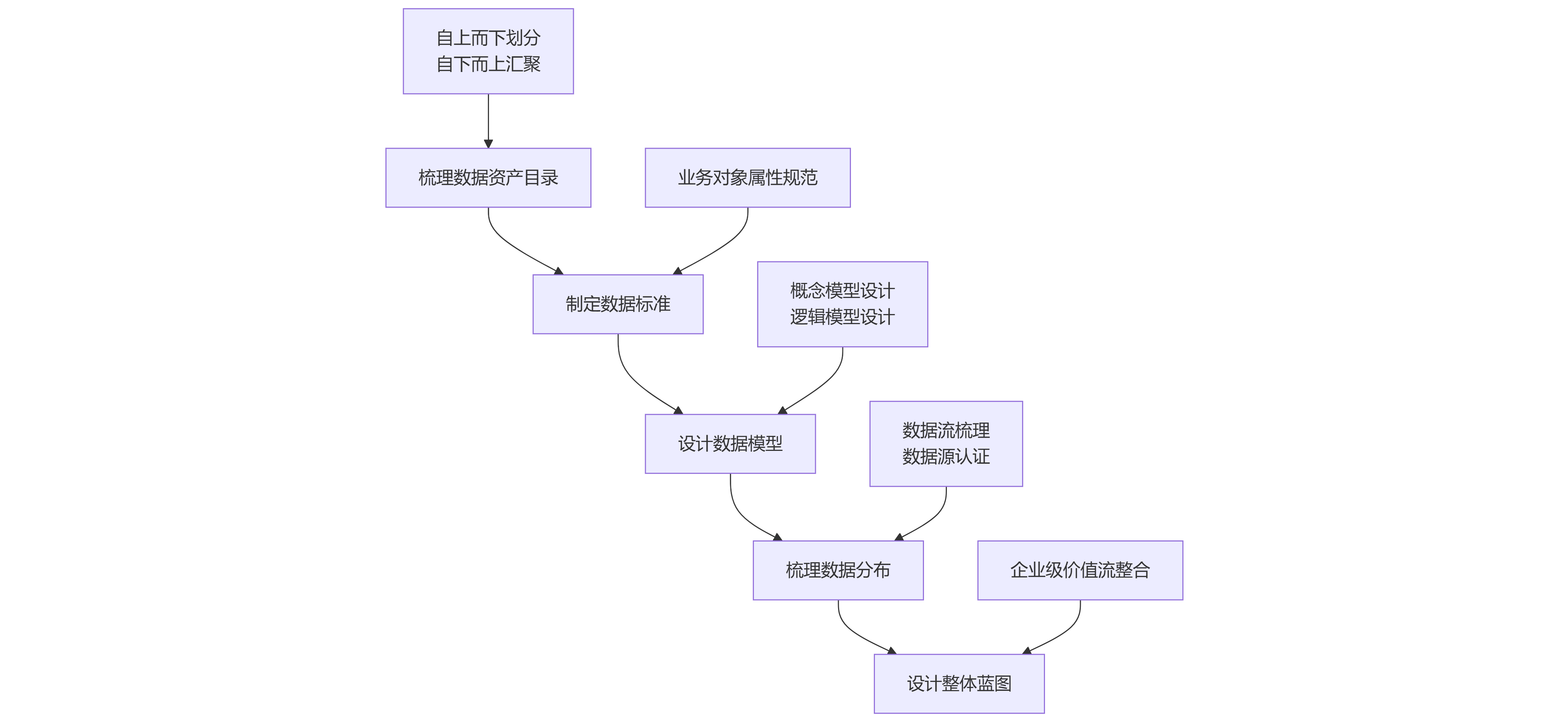
完整的数据架构包含三个关键组件,共同构成了企业数据管理的蓝图。
1 数据资产目录
数据资产目录按照关联关系进行逐层汇聚,形成分层框架
。其层级结构包括:
数据域:顶层数据分类,与L1级流程类保持一致
数据主题:数据域下的主题划分
业务对象:具体的业务数据对象
逻辑实体:业务对象的逻辑特征
属性:实体的具体属性
数据资产目录回答了“企业有哪些数据,谁来负责”的问题,是数据治理的基础
2 数据模型
数据模型是数据架构的核心技术组件,通常分为三个层次:
概念模型:对现实世界数据的抽象描述,使用ER图表示实体及其关系
逻辑模型:概念模型的细化,定义数据之间的关系和约束条件,需遵循数据库规范化理论
物理模型:逻辑模型的具体实现,描述数据在数据库中的存储方式。
3 数据分布与流向
数据分布是数据在业务流程和IT系统中流动的全景视图,有助于识别数据的“来龙去脉”
。包括:
数据流:数据在IT系统间的传递和集成(CRUD操作)
信息链:数据在业务流程中的流动(可选)
数据源:概念实体在IT系统中的源头分布
数据架构设计的流程
数据架构设计是一个系统化过程,需要遵循科学的步骤和方法。以下是基于业界实践的设计流程:
步骤一:需求分析
需求分析是数据架构设计的基础环节,需要与利益相关者沟通,了解他们对数据的需求,包括数据存储、数据类型等
。关键任务包括:
确定数据来源,识别企业内部和外部的数据来源
理解业务流程,分析与数据相关的业务流程
收集数据使用需求,了解利益相关者对数据的具体需求和期望
步骤二:概念设计
概念设计阶段创建高层次的数据模型,如ER图(实体-关系图),来展示数据之间的关系
。主要任务包括:
识别业务中的核心实体及其关系
定义实体间的关联关系(如一對多、多對多等)
建立概念模型,作为业务与IT之间的沟通桥梁
步骤三:逻辑设计
逻辑设计阶段将概念模型转化为具体的数据库结构,定义表、字段、数据类型和关系
。关键活动包括:
表结构设计,将实体转换为表格,设计字段和数据类型
规范化设计,遵循数据库规范化原则(如第三范式)
关系定义,明确定义主键、外键和约束条件
步骤四:物理设计
物理设计阶段关注数据在存储介质上的具体实现方式
。主要内容包括:
选择DBMS,根据需求选择合适的数据库管理系统
索引设计,为提高查询性能设计合适的索引策略
分区策略,对大型表进行分区,提高查询效率
步骤五:数据分布与流向设计
这一阶段关注数据在系统中的动态流动,是数据架构的“生命线”。需要明确:
数据分布:确定数据的“单一事实来源”,识别数据源和数据使用方
数据流向:描述数据在系统间和业务流程中的移动路径,包括数据流和信息链
集成机制:设计数据集成与共享机制,制定接口标准,选择集成模式
步骤六:实施与测试
实施阶段将设计转化为实际的数据库系统,测试阶段确保系统符合设计和性能要求
。关键活动包括:
数据库创建,执行DDL语句创建数据库、表和索引
数据迁移,将现有数据迁移到新数据库
功能测试和性能测试,验证系统在高负载下的表现
步骤七:维护与优化
数据架构是一个持续演进的过程,需要定期维护和优化以适应业务变化
。主要任务包括:
性能监控,持续监控数据库性能,识别瓶颈
查询优化,分析慢查询,优化SQL语句和索引策略
容量规划,预测数据增长,提前规划存储资源
重点流程一:数据建模方法及适用场景
数据建模是数据架构设计的核心环节,不同的业务场景需要采用不同的建模方法。
1 范式建模(规范化模型)
适用场景:OLTP系统(如ERP、CRM、银行核心系统)等需要强一致性的业务系统。
特点:
数据高度规范化,避免冗余
通过主外键连接形成结构复杂的模型
插入/更新操作效率高
2 维度建模
适用场景:数据仓库、BI报表分析、运营分析等OLAP场景。
特点:
以“事实表+维度表”的结构设计
强调数据可读性和分析便利性
查询性能高(配合预聚合)
3 Data Vault建模
适用场景:跨系统数据整合、企业级数据仓库建设、数据湖仓融合项目。
特点:
将数据拆分为Hub(主键)、Link(关系)、Satellite(属性)三类表
支持历史追踪(变化记录)
强调可扩展性与灵活性
重点流程二:数据分布与数据流
之前阶段主要定义了数据的“住所”(存储于何处)和“结构”(如何存放)。而数据分布与数据流则要回答数据的“旅程”:数据在何处产生、如何流动、被谁使用、最终流向何方。这一动态过程确保了数据能够在整个组织内高效、一致地支撑业务运作
1 明确数据分布:确定数据的“源头”与“归宿”
数据分布设计旨在明确数据资源的逻辑和物理分布,包括数据与业务流程、应用系统的对应关系
。其核心在于确定数据的“单一事实来源”(Single Source of Truth)。
识别数据源(Data Source):这是数据产生的起点,需要明确数据的业务责任人(数据主人)和技术系统(源头系统)。数据源头有责任保障数据质量,并参与数据标准的制定。确立数据源的唯一性是避免数据不一致、减少重复维护的关键。
分析数据使用方:明确数据的消费者,即哪些业务流程或IT系统需要读取、引用或进一步加工这些数据。这有助于规划数据的共享与服务化接口。
通过明确数据分布,可以绘制出一张企业数据地图,清晰展示关键数据资产的“户籍”信息,为数据治理和责任追溯提供基础。
2 梳理数据流与信息链:描绘数据的“运动轨迹”
如果说数据分布是静态的快照,那么数据流(Data Flow)和信息链就是动态的录像,它们精确描述了数据在系统间和业务流程中的移动路径
数据流(系统层面):重点关注数据在不同IT系统之间的传递与集成。通常以CRUD(创建、读取、更新、删除)矩阵或数据流图(DFD)来刻画数据在系统间的流转逻辑。例如,CRM系统“创建”客户主数据后,如何“同步”到ERP和数据分析平台。这套逻辑有助于进行数据质量根因分析,并指导系统集成方案的设计。
信息链(业务层面,可选但重要):当把数据流图中的IT系统节点替换为业务流程或业务活动时,就得到了信息链。它从业务视角展示了数据如何伴随一项业务活动的开展(如“从订单到收款”)在不同部门或角色间流转,从而直观揭示业务协同中的信息壁垒或断点。信息链的构建有助于打破部门墙,促进业务流程的顺畅与透明。
3 设计数据集成与共享机制:构建数据的“交通网络”
明确了数据的流动轨迹后,需要设计高效、可靠的“交通规则”和“运输方式”,即数据集成与共享机制。
制定接口标准:建立统一的跨部门信息接口标准,包括数据格式、通信协议等,以确保数据能够无缝对接。
选择集成模式:根据业务对实时性、一致性等要求,选择合适的集成模式,如通过企业服务总线(ESB)、API接口、数据仓库或数据湖等方式实现数据集成与共享。
推动数据服务化:倡导“数据即服务”(DaaS)理念,通过标准化的数据服务接口提供和获取数据,实现数据的同源共享,保证跨流程、跨系统的数据一致性。
结语
数据架构设计是企业数字化转型的核心基础。通过系统化的数据架构设计,企业可以厘清数据资产,落实数据责任,统一数据语言,消除理解歧义,为数据驱动业务奠定坚实基础。
优秀的数据架构不仅是技术的实现,更是业务与技术的完美结合。它应当像城市的规划一样,既满足当前需求,又为未来发展留出空间。随着数据技术的不断发展,数据架构设计也将持续演进,为企业创造更大的价值。