redis进阶 - 底层数据结构
通过上文我们知道,redis真正的数据结构是在底层,这是 redis 性能强悍的因素之一,本文目标是学习底层数据结构。
联系上文数据结构底层机制一起阅读,本文会非常通俗易懂。
引言
在对对象机制(redisObject)有了初步认识之后,我们便可以继续理解如下的底层数据结构部分:
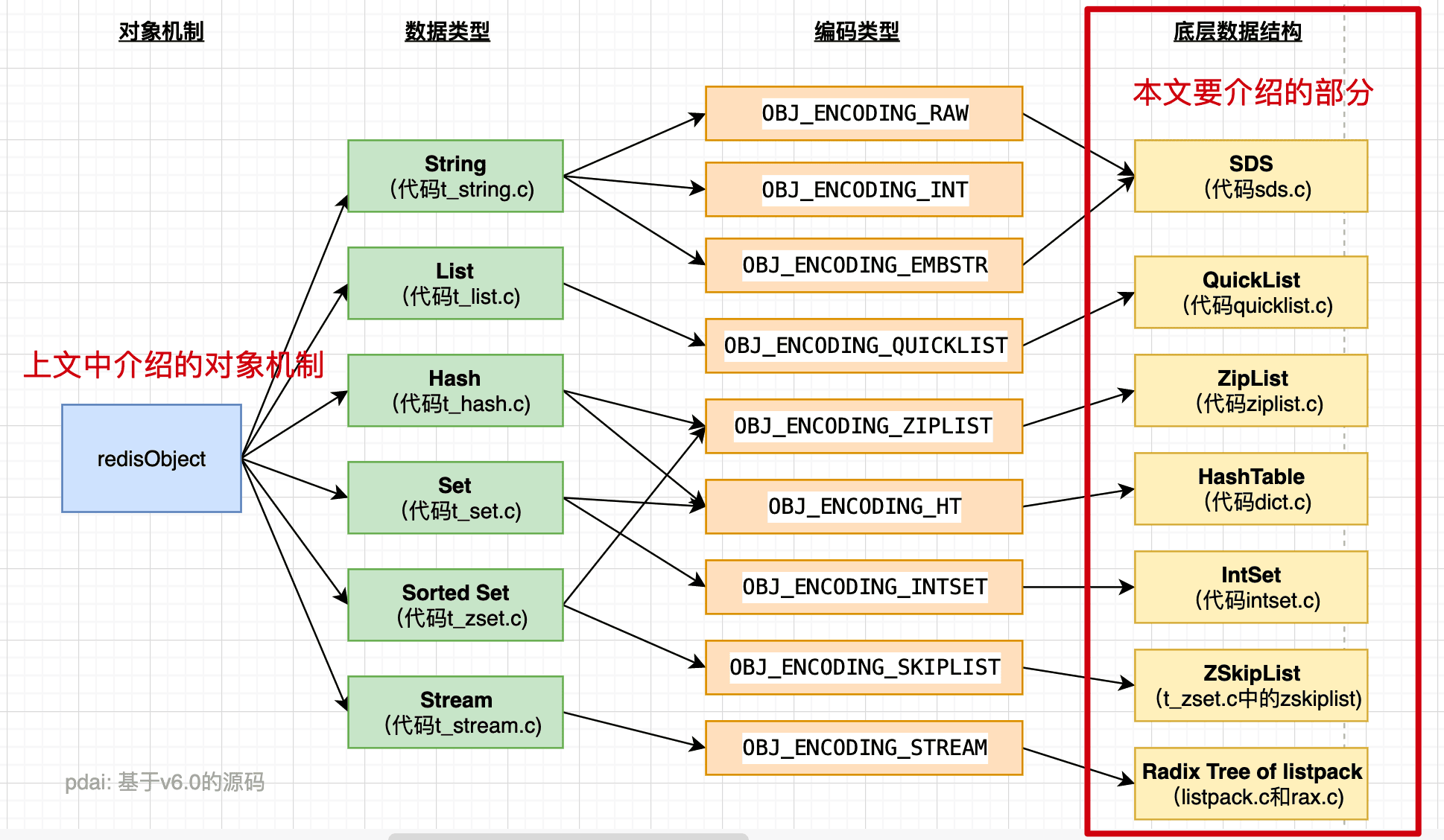
可以得知,我们接触最多的 String 、 List 等数据结构是 RedisObject 的一个type属性,本质上这不属于数据结构,真正的数据结构是在底层用 c 语言写的 SDS , quickList 等,到了这里还能再底层挖掘它的数据结构吗?再底层就是物理顺序了,比如:ZipList 底层是物理内存连续存放。
数据类型是给我们开发者用的,底层数据结构是给想了解redis为啥这么快和应对面试用的。
- 简单动态字符串 - sds
- 压缩列表 - ZipList
- 快表 - QuickList
- 字典/哈希表 - Dict
- 整数集 - IntSet
- 跳表 - ZSkipList
SDS - 简单动态字符串
SDS(Simple Dynamic String) 是 Redis 中用于存储字符串的底层数据结构,它是对 C 语言 char* 字符串的 增强实现。
Redis 的 key、value(无论是字符串、list、hash、set 等类型)中 字符串部分 都是用 SDS 实现的。
SDS 数据结构
结构:
struct sdshdr {int len; // 已使用的字节数(字符串长度)int alloc; // 总分配的空间(不含结构体本身)char flags; // 类型标识(不同长度对应不同结构)char buf[]; // 实际存储的字符串内容,以 '\0' 结尾
};
len 属性记录长度,以 O(1) 时间获取字符串长度,这比 C 原生遍历获取长度 O(n) 时间性能更由,一点空间换时间。
其中 flag 的概念比较偏理论,简单来说它的作用是 :SDS 有很多头部,根据字符串长度,选择合适的头部,也是一种性能优化,不过涉及到了 C 的一些知识,没深入学习。
重点学习核心机制,理解这个够用了
核心机制
- 动态扩容(空间预分配),当追加内容导致空间不足时:
-
- 如果字符串 < 1MB:新空间 = 旧长度 × 2
- 否则:每次扩容增加 1MB
扩容分配的空间足够多,那么就能减少扩容带来的性能损耗。
-
惰性释放: 当字符串被缩短时,不立刻释放多余内存,只更新
len,保留alloc以便下次复用。 也就是说总空间不变,避免字符串长度突增,反复扩容带来的性能损耗。 -
二进制安全:这是相对于c语言来说,c语言字符串用
\0表示结束,如果一个图像二进制合法包含了\0会被当做结束符断开。而SDS的做法是不靠\0判断结束,而是靠len属性,len再次发挥作用,上大分。
简单总结一下为啥SDS比 C 原生字符类串型更好
- len 的空间换时间,性能优化
- len 判断结束,二进制安全
- 动态扩容和惰性释放减少内存重新分配的次数,c 的字符串没有这个机制。
ZipList - 压缩链表
ZipList(压缩列表) 是 Redis 早期版本(< Redis 7)中,为了节省内存而设计的一种 连续内存块结构,用来存储一组小的字符串或整数元素。
它是一种 紧凑型的线性数据结构,本质上就是:
一个连续的字节数组,里面顺序存放多个元素,每个元素都有自己描述字段(前后偏移、长度等),不需要额外的指针。
ZipList设计目的是在小场景下, 节省内存,提升访问效率 。 ZipList 是申请连续内存空间的数据结构,数据量大了反而不好用。
Redis 会自动选择使用 ZipList,当数据量或元素大小比较小时。
ZipList 数据结构
ZipList 数据结构:
┌──────────────────────────────────────────────┐
│ zlbytes (4B) | zltail (4B) | zllen (2B) │ ← Header (头部)
├──────────────────────────────────────────────┤
│ entry1 | entry2 | entry3 | ... | entryN │ ← Data entries (元素区)
├──────────────────────────────────────────────┤
│ zlend (1B, 0xFF) │ ← End mark (结尾标志)
└──────────────────────────────────────────────┘
zlbytes存储的是整个ziplist所占用的内存的字节数,用于 realloc(重新分配内存)zltail它指的是ziplist中最后一个entry的偏移量. 用于快速定位最后一个entry, 以快速完成pop等操作zllen当前entry的数量,最多 65535 个。zlend是一个终止字节, 表示压缩链表的结束,要是找entry找到这里,那就结束没找到。
理解entry结构:
┌─────────────────────────────────────────────────────────────┐
│ prevlen | encoding | content │
└─────────────────────────────────────────────────────────────┘
prelen : 前一个 entry 的长度 , 当前 entry 的起始地址 减去 前一个 entry 的长度 = 前一个 entry 的起始位置 , 因此这个属性的作用是反向遍历。
**那正向遍历呢?**这是连续内存,所以正向遍历根据第一个entry的起始位置往下找。
encoding : 当前 entry 内容的类型和长度 , 决定 content 是字符串类型还是整数类型,整数会更节省空间,所以这里做出区分,也是一种性能优化。
content : 如果是字符串,按原样存储; 如果是整数:直接存储二进制整数,不转字符串。
核心机制
双向遍历
- 每个 entry 记录上一个 entry 的长度(
prevlen), - 所以可以从头或从尾遍历。
紧凑存储
- 所有 entry 连续存储,没有空洞;
- 当一个 entry 扩容或缩短,可能引发级联更新(cascade update),因为后续节点的
prevlen也要改。
类型自适应
- 如果内容是整数,用最小字节数存储(如 1B、2B、4B、8B);
- 如果是短字符串,也会用压缩编码。
QuickList - 快表
QuickList 是 Redis 列表(list)底层的数据结构。它是 “双向链表(linked list) + 压缩列表(ziplist)” 的结合体。
- 每个节点是一个 ziplist(压缩列表)
- 所有节点通过 双向指针 链接起来
“一串压缩列表” 构成一个快速的、节省内存的链表。
QuickList 数据结构
最外层 QuickList :
struct quicklist {quicklistNode *head; // 头节点quicklistNode *tail; // 尾节点unsigned long count; // 所有 entry 的总数量unsigned long len; // quicklistNode 节点数量
}
count : 整个 QuickList 是第三层的 entry 数量汇总
len : 整个 QuickList 第二层的 QuickListNode 数量汇总
中间层 QuickListNode:
struct quicklistNode {struct quicklistNode *prev; // 前节点struct quicklistNode *next; // 后节点unsigned char *zl; // 指向 ziplistunsigned int sz; // ziplist 的字节长度unsigned int count; // ziplist 内 entry 数
}
*zl 是一个指针,指向的是 ZipList , 所以还有第三层:
+-------------+-------------+-------------+-------------+-------------+
| zlbytes | zltail | zllen | entry1 ... entryN | zlend |
+-------------+-------------+-------------+-------------+-------------+
整体图:
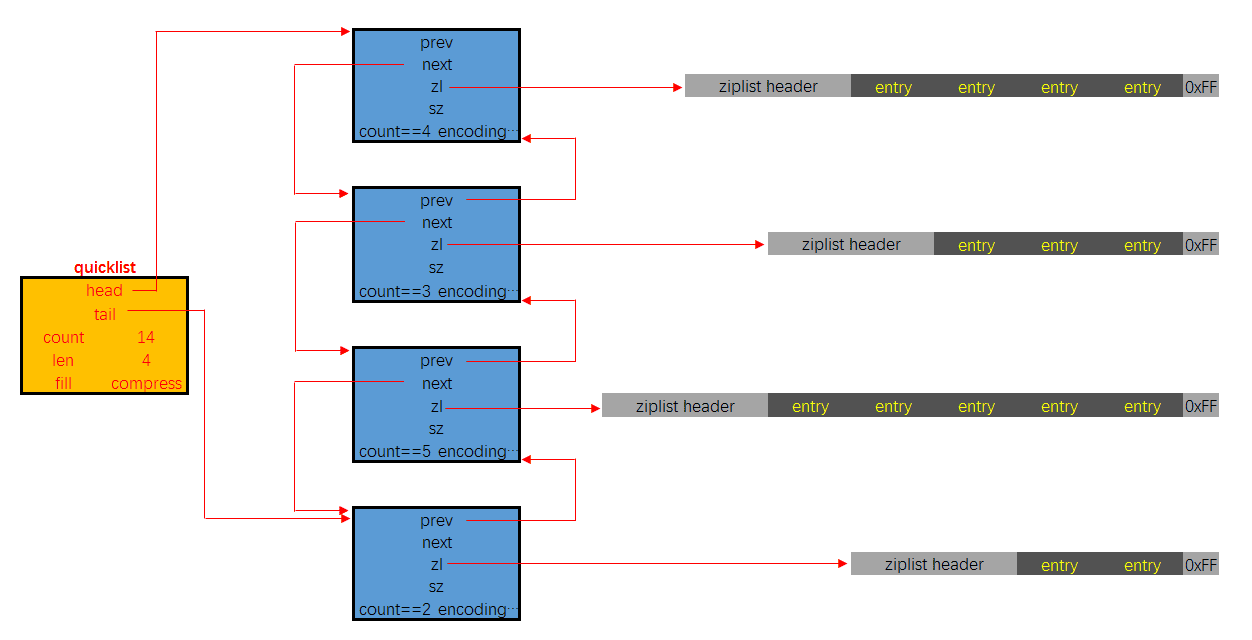
这样的结构比传统的双向链表优势在于:
- 双向链表要存大量指针 , ZipList 内部entry是连续的,外部QuickList 存少量指针,存储空间优化。
- CPU cache 命中率提高(连续内存易缓存)
- 兼容了双向链表结构,quickListNode 级别的插入和删除是O(1)
- 有了 ZipList 连续存储的特性,entry 之间连续存储,查找速度快。
遍历:
理解成二维数组遍历,先找到QuickListNode , 遍历内部的entry,然后通过指针找下一个QuickListNode , 遍历内部entry …
Dict - 字典/哈希表
Redis 字典(dict)是 Redis 内部实现 **hash**、**set**、**zset** 等类型的核心底层数据结构之一,本质上是一个 哈希表。
Dict 数据结构
作为开发者,我们使用 hash 结构到了一定大的量时,会从 ZipList 转变为 Dict 结构,条件为:
-
- field/value 对总数 >=
hash-max-ziplist-entries(默认 512) - field/value 长度 >=
hash-max-ziplist-value(默认 64 字节)
- field/value 对总数 >=
都满足,则变成hash , 此时我们存储的 key : hash 中的 hash 存储结构如下:
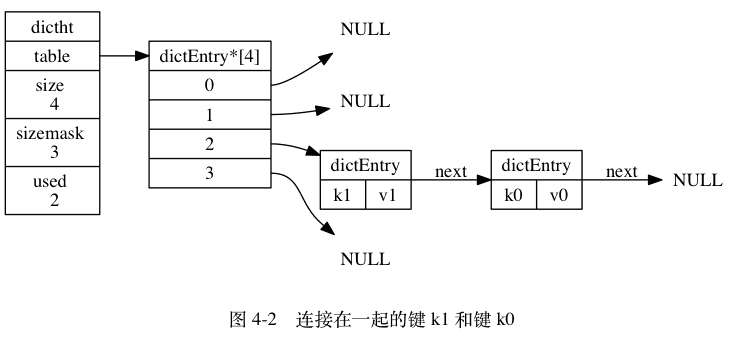
dictht 的 table 只有一个,肯定会进来dictentry , 然后根据 key 计算哈希值,找到存储桶,每个存储桶是链表结构,解决哈希冲突。
如果是小hash 用ziplist存储,结构如下:
│ Entry 0: field_1 │
│ Entry 1: value_1 │
│ Entry 2: field_2 │
│ Entry 3: value_2 │
│ Entry 4: field_3 │
│ Entry 5: value_3 │
hash 的key 和 value 用两个 entry 连续存储
这样的结构特点是:
- 快速查找:哈希表的平均查找复杂度是 O(1)。
- 支持动态扩容:
dict可以随着数据增长动态调整大小。 - 灵活存储:支持不同类型的 value,如字符串、hash、set 等。
如何实现
哈希表结构:
- 使用数组(
table[])存储桶,每个桶是一个链表(冲突处理)。
哈希函数:
- 使用
dictHashFunction(通常是 MurmurHash 或 SipHash)计算 key 的 hash 值。
动态扩容:
- 有两个哈希表
ht[0]和ht[1],通过 渐进式 rehash 避免一次性扩容导致阻塞。
操作流程:
- 查找 key → 计算 hash → 定位桶 → 遍历链表/红黑树找到 value。
渐进式rehash : 当hash扩容时,需要迁移hash元素到新的hash表,渐进式hash的做法是不要一次性迁移, 而是 把 rehash 工作分散到每次操作里。
- 每次对哈希表进行操作(读/写),顺便搬一部分元素。
- 扩容过程是 非阻塞的,不会一次性卡住服务器。
- rehashidx :记录 rehash 进度
ZSkipList - 跳表
ZSkipList 是 Redis 用于实现 大 ZSet 的核心数据结构之一, 它是一种 跳表(Skip List),按 score(分数) 排序存储元素。
每个节点包含:
- member(成员)
- score(排序分数)
- forward 指针数组(多级索引,支持快速跳跃查找)
Redis 结合 dict + ZSkipList:
- dict → 快速通过 member 找到节点
- ZSkipList → 支持按 score 排序和范围查找
内部结构图
ZADD myzset 100 Alice
ZSet "myZSet"
┌─────────────────────────────┐
│ dict<member, zskiplistNode> │
│ ┌───────────┐ │
│ │ "Alice" │ ──────────┐ │
│ │ "Bob" │ ──────────┤──> 指向 ZSkipList 节点
│ │ "Carol" │ ──────────┘ │
└─────────────────────────────┘▲│ O(1) 查找 member│
┌─────────────────────────────┐
│ ZSkipList (按 score 排序) │
│ level3 → level2 → level1 │
│ │
│ Node(score=100, member="Alice") │
│ Node(score=150, member="Bob") │
│ Node(score=200, member="Carol") │
└─────────────────────────────┘▲│ O(log N) 范围查询 / 排名查询
可以看出 ZSet 是由 dict + ZSkipList 实现,来看看 ZSkipList 的结构:
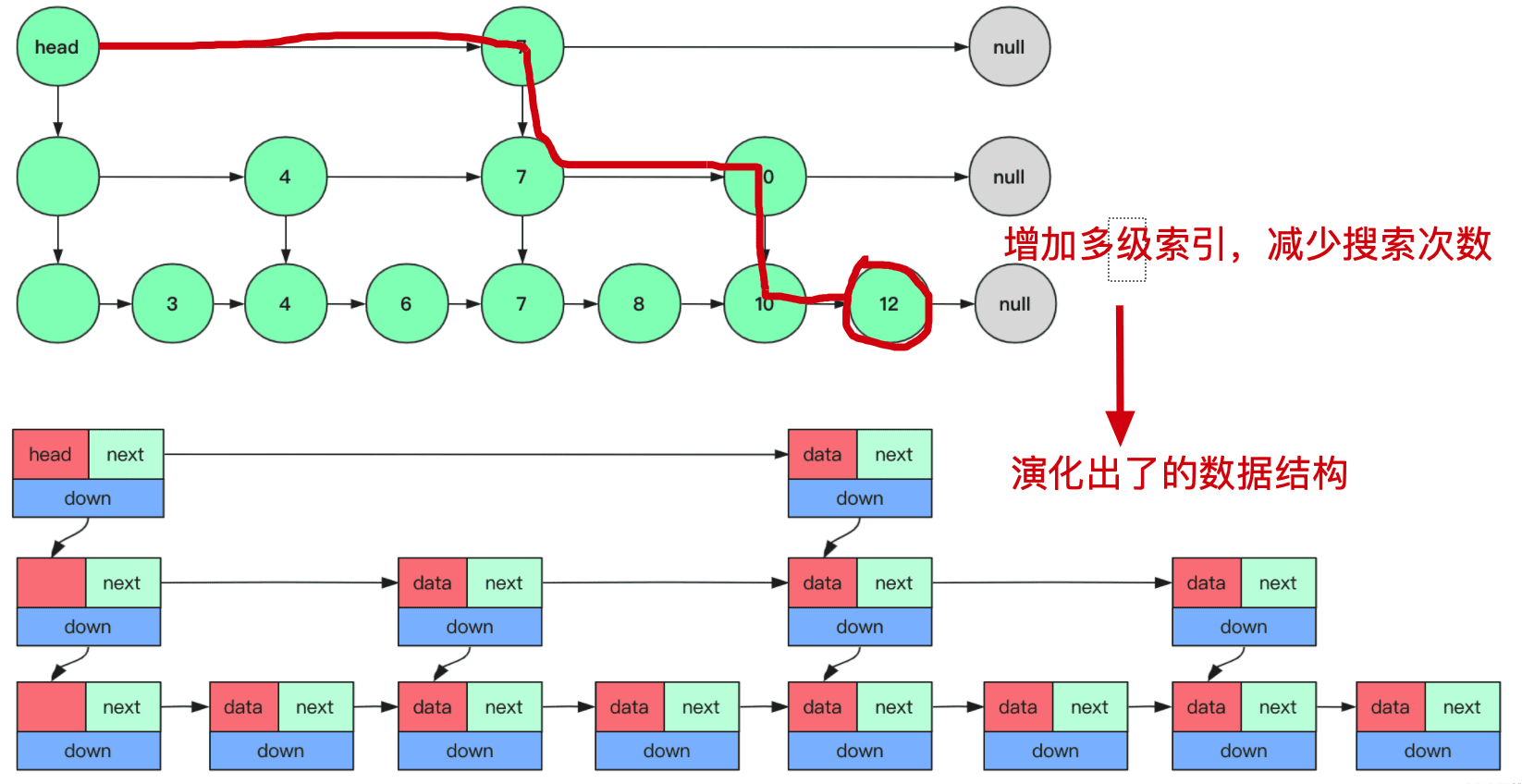
跳表是基于单链表演进过来的,增加了多级索引,便于跳跃快速查找。
从字段层面看看结构:
typedef struct zskiplist {struct zskiplistNode *header; // 跳表头节点(所有层都有指针)struct zskiplistNode *tail; // 跳表尾节点(方便反向遍历)unsigned long length; // 节点总数int level; // 跳表最高层数(当前最大层)
} zskiplist;
typedef struct zskiplistNode {sds ele; // 元素 member(字符串)double score; // 排序分数struct zskiplistNode *backward; // 后退指针(底层链表前驱)struct zskiplistLevel {struct zskiplistNode *forward; // 指向下一节点(同一层)unsigned int span; // 两个节点之间的跨度(用于计算排名)} level[]; // 节点的多级索引数组
} zskiplistNode;
level 是跳表的核心, 每个节点可以有多层 index(level) ,level[i].forward → 指向 同一层 的下一个节点 。
- 顶层索引(level 3)跳过更多节点,快速逼近目标
- 底层索引(level 1)包含所有节点 → 精确定位
- 查询时:从顶层开始向右跳(forward),跳不到就向下一层下降
水平跳跃 依靠 forward 指针
垂直跳跃/下降到下一层 依靠 level[] 数组自然决定的层级
- 没有显式字段存上下层指针,因为 node 自己就有多层
level[],查找时用数组索引遍历即可
跳表的优点
- 高效支持 按 score 排序操作
- span 字段支持 快速范围查询和排名计算
- 配合 dict → 兼顾 O(1 查找和排序能力)
Dict + ZSkipList 实现了跳表,让 redis 具有高性能处理排行榜场景的能力。