python自学笔记
一、打印
print()
print("hello world")
print("hello","my","friend")
输出:
二、变量命名

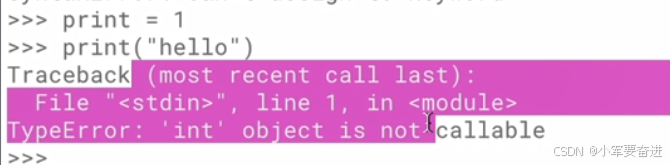
不要用print当作变量名,否则当使用print函数时就会发生报错:
python特有的变量命名方式:

交换变量的值,python特有的写法,完全符合阅读习惯:

变量的回收,python一般不需要手动销毁或者回收某个变量,因为会自动被回收,这里了解一下:
python里边特有的关键字del,可以回收某个变量:

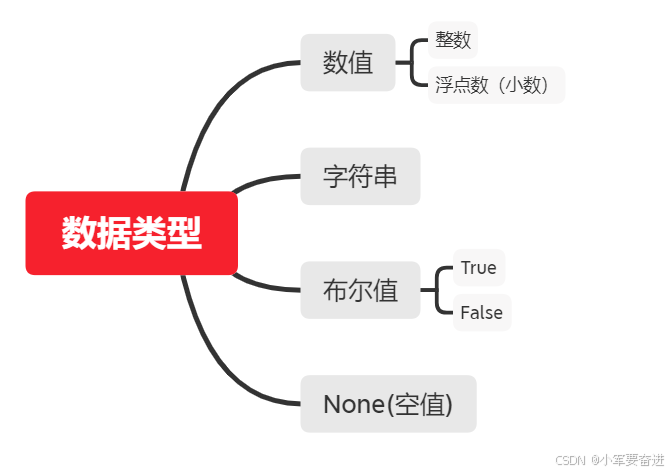
三、数据类型
1、浮点数
任何与浮点数相加都等于浮点数。

2、字符串
通常用双引号、单引号、或者三个神双引号。
①双引号表示的字符串:

\ 斜杠(回车键的上方)是转义符,表示原样输出后面的东西。
②单引号表示的字符串

或者:

③三引号表示的字符串

一般用在定义一个很长的字符串,而且它们之间也有换行。如下:

或者:

3、None
当定义一个变量时,如果还没有想好赋什么值,也没有想好什么类型的值。可以先给这个变量赋值为None

四、数据类型的转换
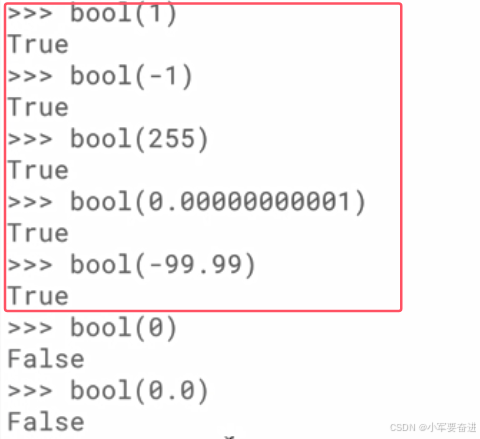
1、数值转为布尔值
除了0以外,其他都是True
隐式类型转换:

2、字符串转布尔值
只有空字符串才会返回False,其他字符串都是返回True

特别要注意一下,含有空格的字符串返回的是True

还有经常转换的有None值:

3、字符串转数值
①转为整数
用int()

②转为浮点数
用float()

③整型和浮点型相互转换
转为整型时小数点后面都会被截断不要。

如果想四舍五入,需要用到round()

五、算数运算符
1、除号
这里要注意的一点是做除法时,打印出来的是浮点数的:
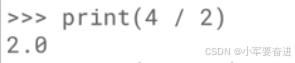
想要整除可以换另外一个运算符://

计算机在进行浮点数运算的时候,它的精度是有问题的,如:
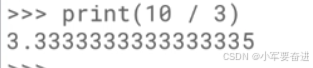
2、取模
也叫取余数。

当两个数中有负数时,结果可能会跟我们预料的不同,记住这个公式就行了 :a % b 就相当于a - (a // b) * b
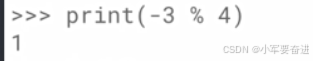
0不能用来做除数,也不能用来做取模运算:

字符串在python中也是可以运算的:
字符串只支持加法和乘法的操作:

六、比较运算符
只有当值和类型都相等的时候,返回的才是True

在整数和浮点数的比较中要注意:数学上相等的返回就是True

七、逻辑运算符
NOT

在and中,只要有一个False的,结果返回的就是False的。
在or中,只要有一个True的,结果返回的就是True的。

八、条件判断

九、字符串格式化
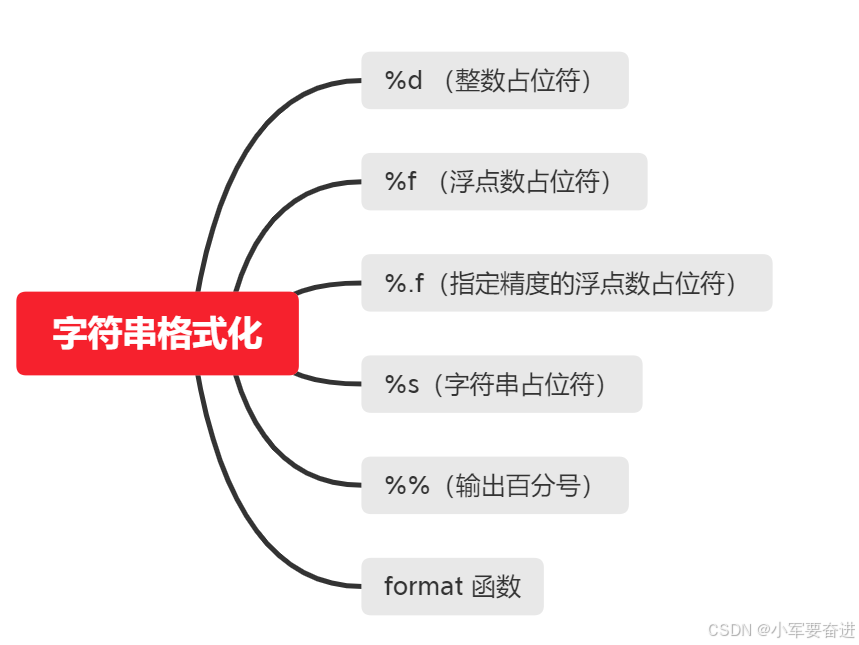
示例1:

输出:

示例2:
字符串格式化函数:format函数
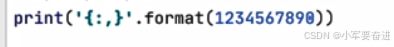
示例3:
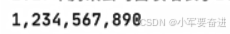
还有如:

输出:
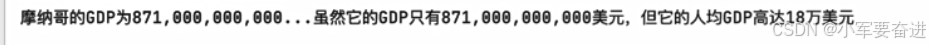
十、字符串索引(下标)与切片
1、索引访问字符串序列
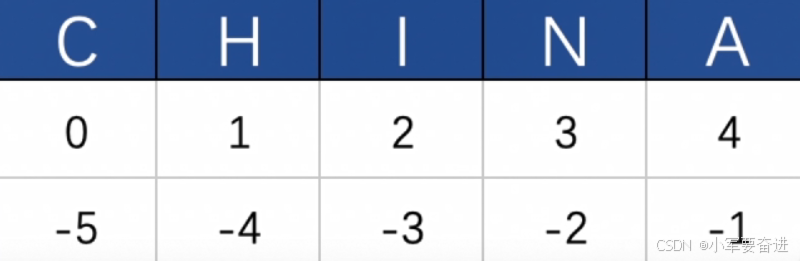
注意倒序访问时,索引是从-1开始的。

2、切片访问字符串序列(python特有的)

示例1:

示例2:
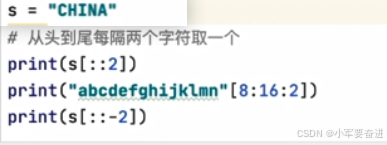
输出:

十一、字符串函数
1、去除空白字符
- strip() 去除字符串的首尾空白字符、换行符。(处理用户输入的时候经常用)
- lstrip() 只去除字符串的首空白字符、换行符。
- rstrip() 只去除字符串的尾空白字符、换行符。

2、大小写
- upper() 让字符串的所有字符变成大写。
- lower() 让字符串的所有字符变成小写。
- capitalize() 让字符串的首字符变成大写。
- title() 让每个单词的首字符变成大写。

输出:

3、字符串判断
- islower() 判断字符串中的所有字符是否全是小写。
- isupper() 判断字符串中的所有字符是否全是大写。
- isdigit() 判断字符串中的所有字符是否全是数字。
- startswith() 判断字符串的前部分。
- endswith() 判断字符串中的尾部分。

输出:

4、找字符串的索引
find() 返回的是索引。如果返回的是-1,那么要找的字符串不存在。

还有和find函数类似的有 index(),同样返回的也是索引,但是如果要找的字符串不存在,控制台会把报错暴露出来。
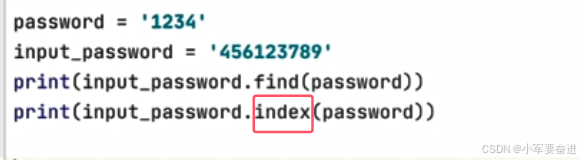

5、找字符串出现的次数
count()

6、字符串替换
replace()

输出:

7、获取字符串的长度
len() 这不只是字符串的函数了,这是python的内置函数。所以使用的时候不是用字符串去调用它了。

输出:

十二、列表基本操作
空列表的布尔值是False

1、创建列表

2、列表的访问
同样和字符串、元组那样支持索引和切片访问。

输出:
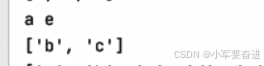
可见,通过切片访问列表得到的也是一个列表。
回顾一下,
通过切片访问字符串得到的也是一个字符串。
通过切片访问元组得到的也是一个元组。
3、插入元素
和元组(元组是不可变序列)不同的是,列表是可变序列。
① append()
从列表后面添加。
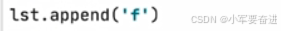
② insert()
在某个索引的前面插入元素。

输出:
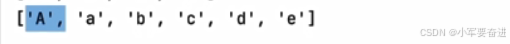
③ extend()
和append()不同的是,extend()可以一次性往列表里边添加多个元素。
示例:
lst = [‘a’]

输出:

4、查看长度
查看可迭代对象(如字符串、元组、列表)长度,通用的方法是len()。
5、修改元素
可通过索引修改指定位置元素的值。

6、删除元素
① del
通过关键字del 删除指定位置的元素。

② pop()
这个函数也可以从列表里面删除元素。
有两种删除元素的方式。
第一种:
删除列表的最后一位。和上面del不同的是,pop()函数可以把被删除的元素返回回来,也就是说可以用变量接收pop()删除的元素。

第二种:
也可以删除列表里边指定位置的元素。

输出:
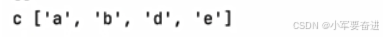
③ remove()
可以删除指定的值。

只能删除列表里边的一个,输出:
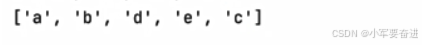
④ clear()
删除列表里边的所有元素。(清空列表)

7、反转列表
如:
lst = [‘a’,‘b’,‘c’,‘d’]

输出:
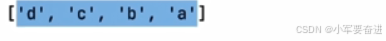
8、列表排序
sort()
这个函数可以按照一定的规则将列表里边的元素重新排序。
注意这个排序是在原有列表上进行的,只是改变原有列表的原有顺序,并没有产生新的列表对象。
① 列表元素全是数字的情况
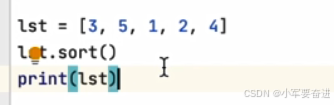
默认是从小到大的顺序进行排序。输出:
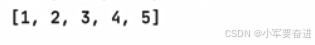
如果想要从大到小进行排序,可以先排序再反转,也可以这样写:

最后输出:
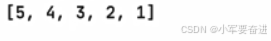
② 列表元素全是字符串的情况
会根据ASCII值进行排序。
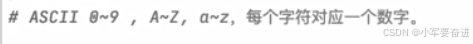
可以使用内置函数 ord() 来把字符转成ASCII编码的值。如下图:


相反, 可以通过 char() 函数来把ASCII值转为对应的字符:
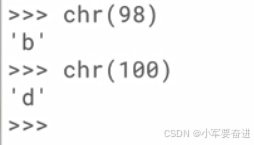
回归正题,当列表里面的元素是字符串时,会按照首字母的值来排序,如果首字母相同,那么就看第二个字母的值。如下图:

排序后输出:

③ 列表元素是元组的情况
示例:根据收入降序进行排序:

如果直接输出,如下图可以看到只是按照元组的第一个字符进行排序。也就是根据3、2、1的ASCII值进行排序。

所以正确的做法是使用key参数来指定排序的依据,key参数接收的是一个匿名函数:

输出:
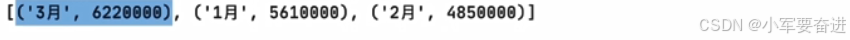
9、复制列表
这里说一下对象引用的概念。注意这并不是复制列表。

输出:
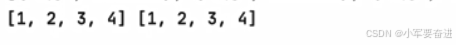
可以见到,只是为lst1末尾添加一个元素,而lst2也跟着添加了,这里涉及对象引用的问题,也就是说lst2和lst1引用的是同一个对象,这里的对象就是 [1,2,3] 列表。
真正的复制列表是通过 copy(),如下图:
lst1 = [ 1,2,3 ]

输出:

可见,把lst1的元素赋值给lst3后,在往lst1添加元素,并不会影响到lst3
10、列表函数
和字符串、元组一样,都可以使用 count() 和 index() 函数:
如a在列表中出现了几次:

a在列表中的位置:
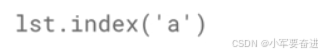
十三、列表表达式
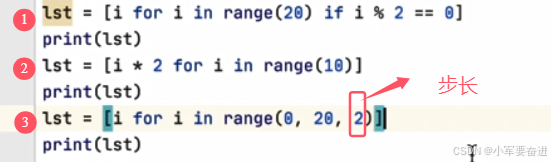
输出的都是:
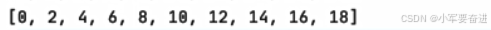
例子:
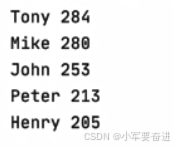
根据销售员的总成绩进行从高到低的顺序进行排序。
# 根据销售员的总成绩进行从高到低的顺序进行排序。
sales = (
("Peter", (78, 70, 65)),
("John", (88, 80, 85)),
("Tony", (90, 99, 95)),
("Henry", (80, 70, 55)),
("Mike", (95, 90, 95)),
)
# 第一种写法:
sale_list=[]
for name,scores in sales:
sale_list.append((name,sum(scores)))
sale_list.sort(reverse=True, key=lambda x: x[1])
print(sale_list) #输出:[('Tony', 284), ('Mike', 280), ('John', 253), ('Peter', 213), ('Henry', 205)]
# 第二种写法:
sale_list=list((sale[0],sum(sale[1])) for sale in sales)
sale_list.sort(reverse=True, key=lambda x: x[1])
print(sale_list) #输出: [('Tony', 284), ('Mike', 280), ('John', 253), ('Peter', 213), ('Henry', 205)]
# 第三种,列表表达式写法:
sale_list=[(name,sum(scores)) for name,scores in sales]
sale_list.sort(reverse=True, key=lambda x: x[1])
print(sale_list) # 输出: [('Tony', 284), ('Mike', 280), ('John', 253), ('Peter', 213), ('Henry', 205)]
为什么要放入列表再排序?
因为元组是不可变序列。
十四、字典基本操作
1、定义字典
字典的值可以不唯一,但是key必须是唯一的。
两种定义字典的方式:

输出:

2、字典的访问
通过key进行访问,注意key是字符串时,key是区分大小写的。
访问的key不存在时,会报错。

输出:

3、插入元素
sales字典里面原本是没有mike这个key的,然后可以直接设置字典里面mike这个key的值,这样就可以插入1个元素了。

4、修改元素
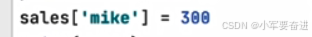
5、删除元素
用 del 关键词来删除指定的元素。

十五、字典的遍历
现在有sales字典:

如果直接遍历:

只会输出所有的key,如下图:

如果使用了字典函数 items()

那么就会输出字典里面每一个元组:

如果在for循环中循环出的是元组,那么可以用两个变量去命名:

输出:
十六、字典的函数
1、get()
当访问字典里面不存在的key时如 sales[‘mike’] ,会报错,如果不想报错,可以使用get(),这样控制台就不会报错,返回一个None

如果想返回一个默认值,可以自定义返回的值:

如上图和如下图功能一致,用 in 判断字典中是否包含某个key:

2、keys() 和values()

输出:

十七、集合基本操作
是无序的、不重复的序列。
也可以说集合里面的元素是无序的、不重复的。
1、定义集合
两种方式。
第一种:

输出:
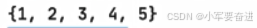
第二种:
列表、元组可以放在set()里面转成一个集合。

输出:
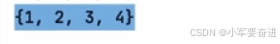
从输出中可见集合可以去除列表里面重复的元素。
通常用这种方式去除列表、元组中重复的元素。

输出:
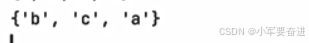
可见,元组转为集合后,里面的重复元素被删除了。
集合也可以转成列表或者元组
假设nums是一个集合

2、查看集合长度
len()

判断集合里面是否包含某个元素:

3、插入元素
add()

4、删除元素
已经加入集合中的元素是不能修改的,只能删除。
① remove()
括号里面是集合中的元素。
② discard()
如果删除集合里面不存在的元素,会报错。如果不想报错可以使用 discard()

③ pop()
如果删除的同时返回这个元素,可以使用pop(),列表里面也可以使用这个函数来删除元素。

如果空集合还pop的话会报错:

控制台:

所以while循环条件限制一下:

十八、集合的遍历
和遍历元组、列表写法一样。

十九、集合的函数
1、求交集
intersection()

输出:
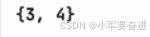
注意返回的是一个集合。
2、求并集
union()

输出:
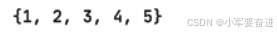
3、判断子集和父集
issubset()
issuperset()

二十、函数定义与参数
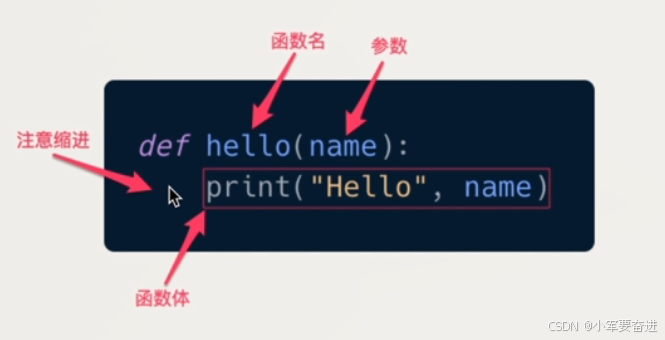
示例:

调用方式有以下2种,可以使用 参数名=参数值 的形式:

定义函数时可以设置默认的值:

二十一、函数返回值
定义一个函数时,如果没有return,那么它的返回值是None

输出None,如下图:

如果一个函数里面只写一个return,那么这个函数就结束了,这个函数里面后面的代码不会被执行:

如果一个函数里面有多个返回值:

那么它返回的是一个元组:

因为定义元组的时候,加不加括号,打印出来的都是元组:

当然也可以返回一个列表,只需在return后用上中括号括起来:

二十二、匿名函数
当逻辑比较简单的函数,可以定义为一个匿名函数。

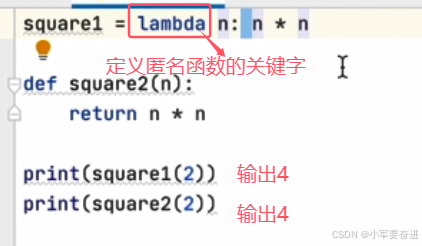
匿名函数可以定义多个参数:

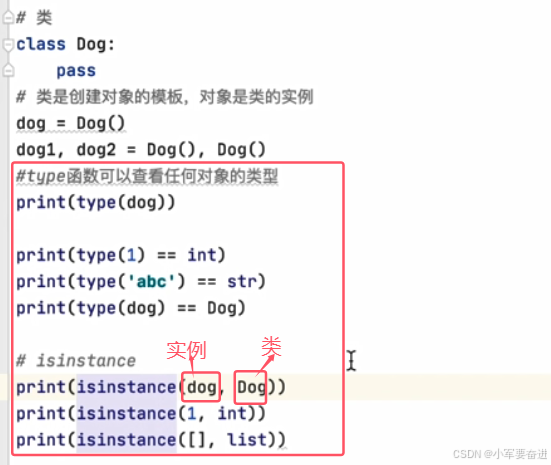
二十三、面向对象-----类和实例
类:创建对象的模版。是抽象的。
对象是类的实例。
通过类创建对象:

可通过 type() 查看一个对象的类型。
可通过 isinstance() 判断对象的类型。
二十四、面向对象-----对象属性和方法
创建一个Dog类:
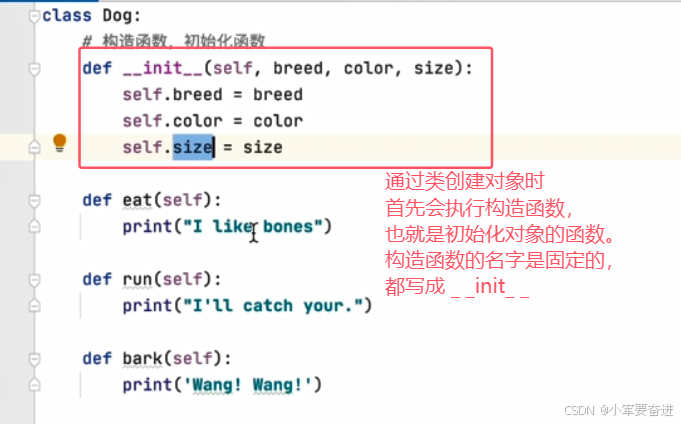
1、构造函数与对象的属性
构造函数包含有将来通过类创建对象的属性。有了构造函数,我们创建对象的同时直接就可以给对象赋值了:
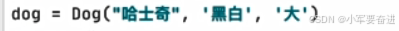
不用另外一个个属性去赋值了:

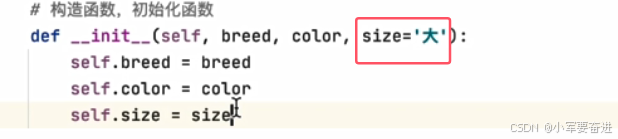
构造函数中也可以设置初始值:
2、对象的方法
在对象的方法中使用对象的属性,是通过self去使用的。self不是代表类,而是代表通过类创建的那个对象。

上面提到的是 对象的属性 和 对象的方法 ,那什么是 类属性 和 类方法 呢?
二十五、面向对象-----类属性和类方法
1、类属性
类属性是所有对象所公有的。
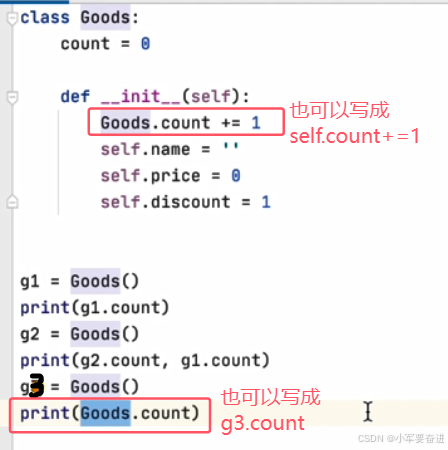
创建一个Goods类:
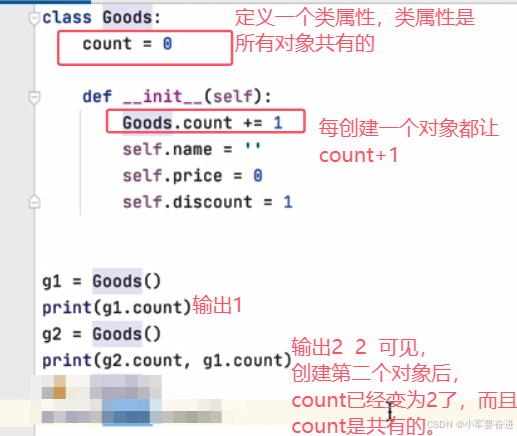
类属性的使用:
可以通过类名去使用,也可以通过对象去使用。下图框选部分都是用类名去使用的:
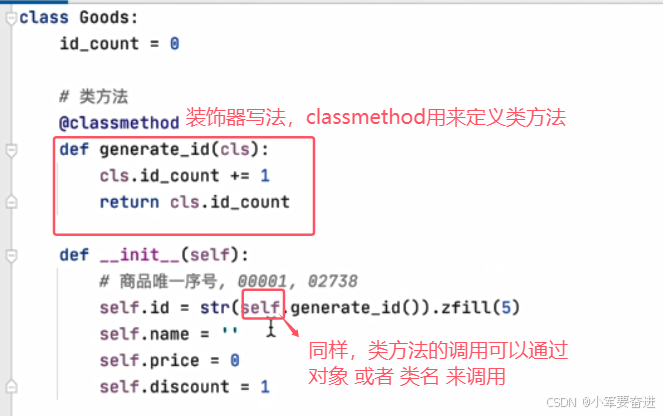
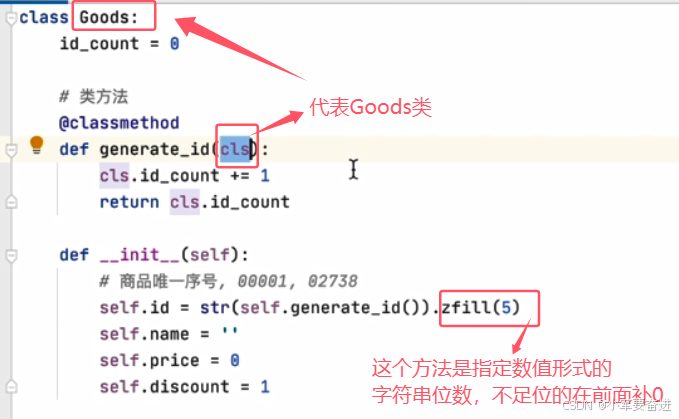
2、类方法
类方法的使用:
同样可以通过类名去使用,也可以通过对象去使用。
二十六、面向对象-----一切皆对象
通过dir() 可以查看一个对象所有的属性和方法。

通过 type() 可以查看对象的类型。
通过 help() 可以查看对象方法的帮助文档。
平时怎么给一个方法写帮助文档?
只需在写定义对象方法的时候,在方法的上面或者下面用三个双引号引起来即可。

对“一切皆对象” 加深理解:

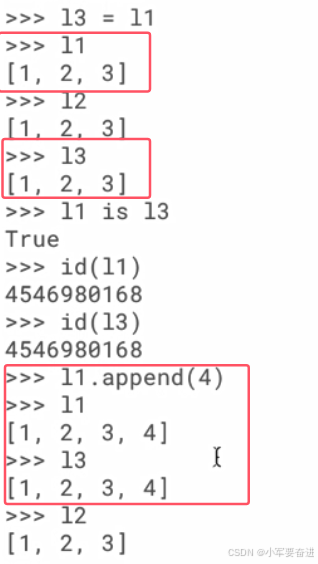
如果两个对象的值相等,并不意味着它们是同一个对象:

只有内存地址一样的对象才是同一个对象。可以通过 id() 这个函数来查看对象在内存里边的地址:

那怎么样做才能让两个对象是同一个对象呢?
可以这样:
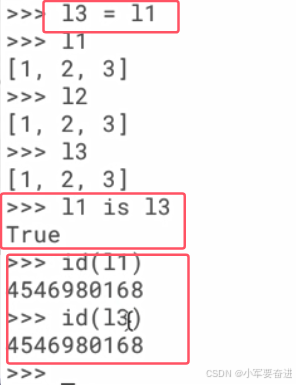
内存地址一样的两个对象,只要对其中一个对象的任何修改,也会体现到另外一个对象身上。如下图:往l1里面添加一个元素,l2也自动添加了同一个元素。
二十七、模块导入
导入语句写在文档的最前面。import后面可以紧跟着类名、方法名或者属性名。

导入模块也可以用as定义别名:

还可以导入多个函数,用逗号分隔开:

1、自定义模块
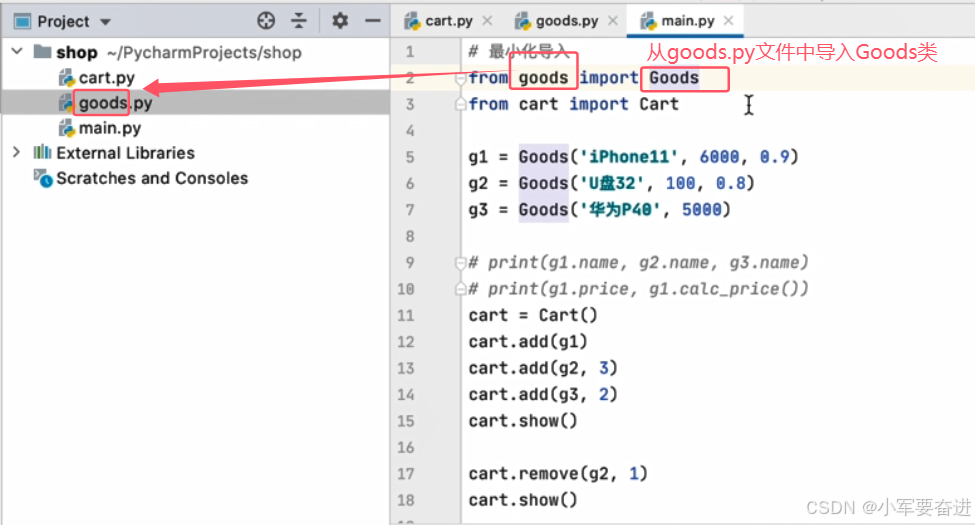
2、package包
创建方式:
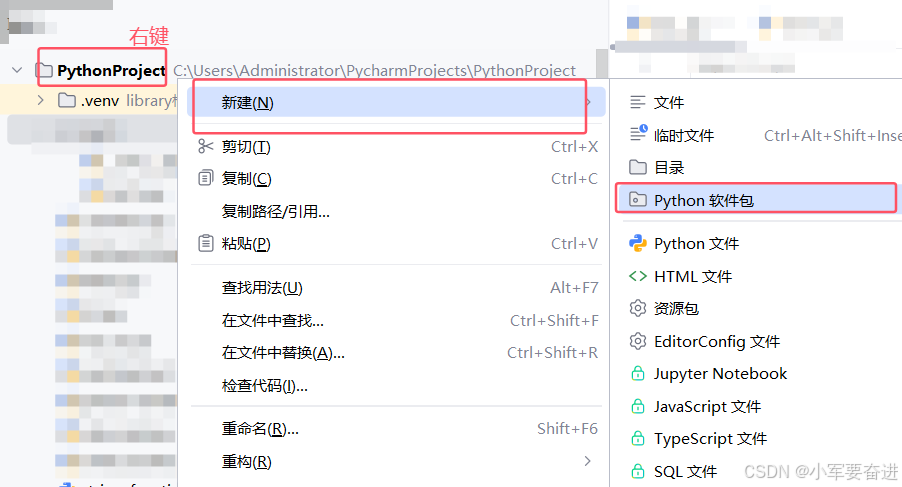
这里创建了test1这个包:
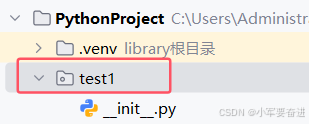
包里面自动创建了_ _ init _ _.py文件,代表这个包是pathon包。
我又在test1包里面创建了一个people.py文件,里面写 name=‘abc’ 。
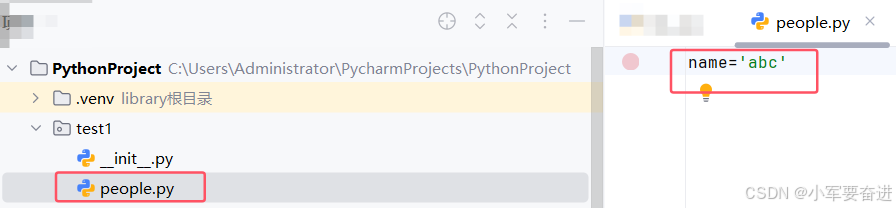
然后我又在test1包外面创建了sys _.py文件。
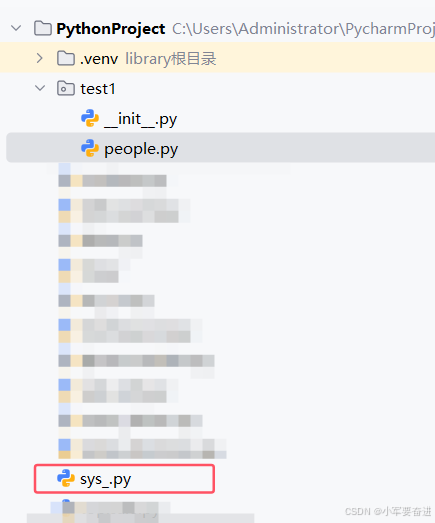
如果我想在sys _.py文件下访问test1包people.py文件下的name,那么可以这样写:
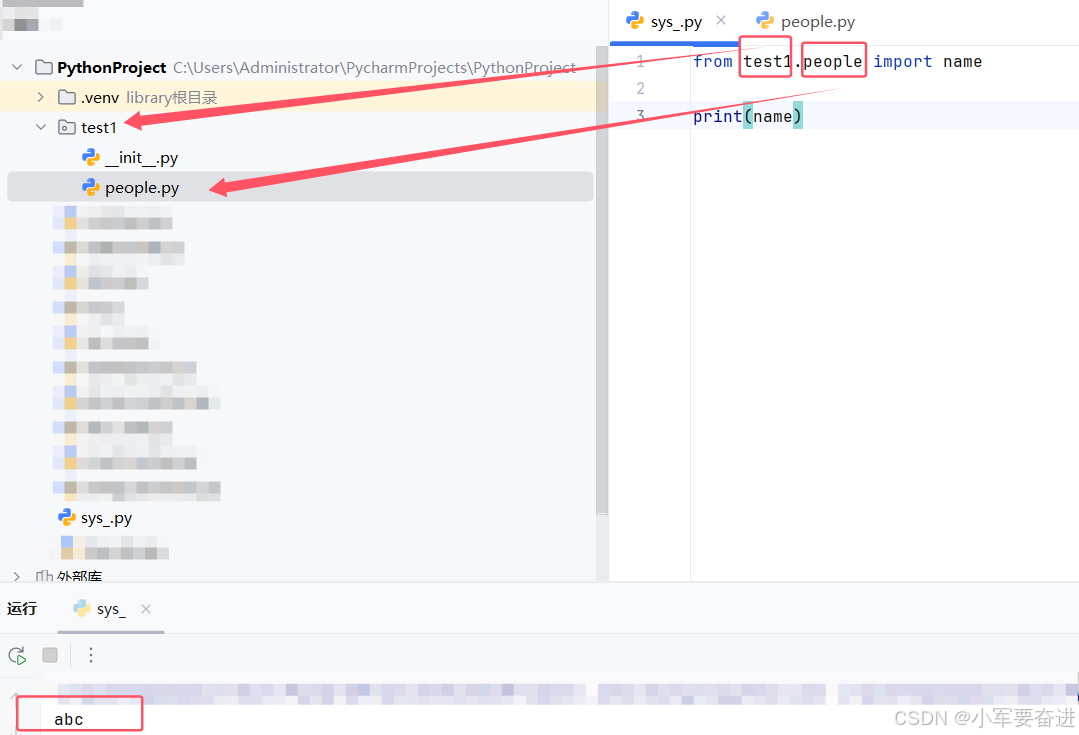
3、_ _ name _ _ 变量
表示 当前模块(写 _ _ name _ _的模块) 所在的名称。
_ _ name _ _ 有一个特点,只有在哪个文件右键点击运行时,它的值才会等于 _ _ main _ _
如下图,在main.py文件中右键点击运行,这时打印了 _ _ main _ _
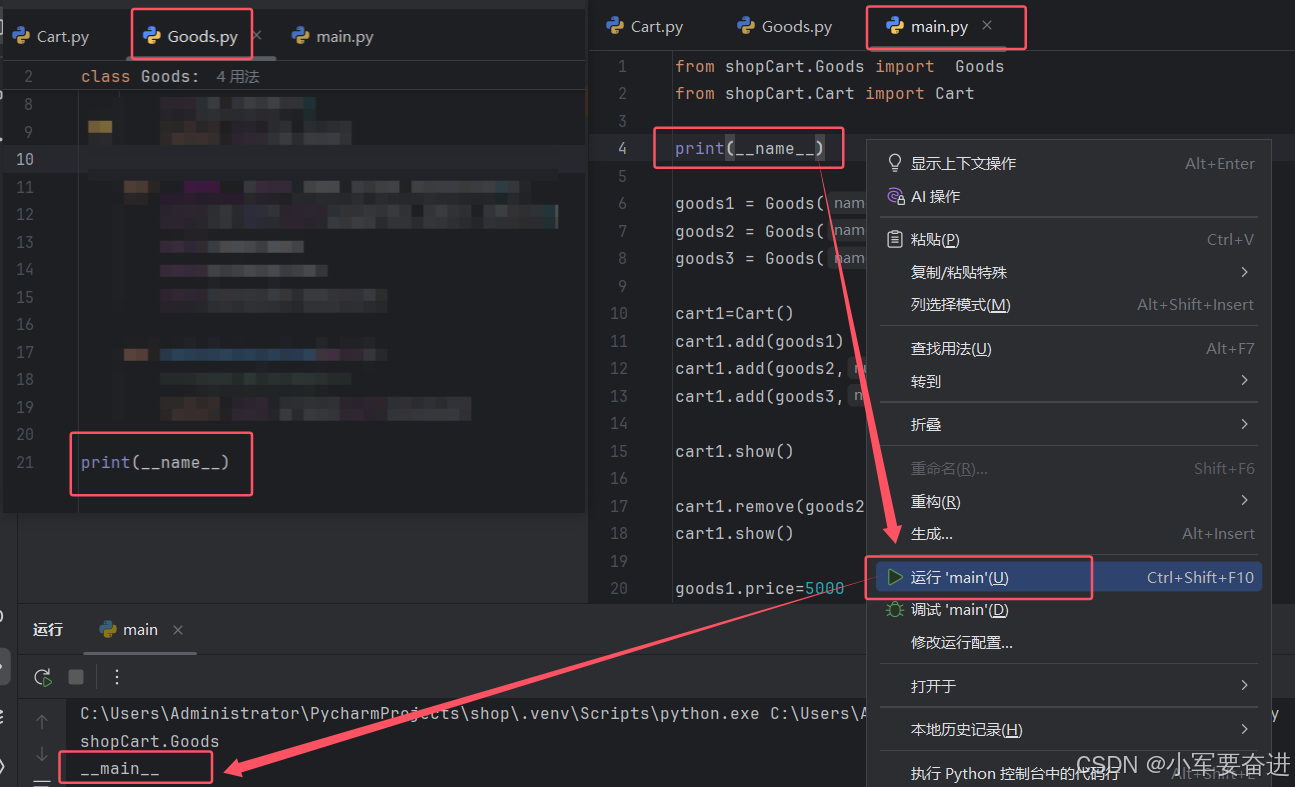
而我也在Goods.py 文件中也写了print(_ _ name _ _),但是它的值不等于 _ _ main _ _,而是等于模块名:shopCart.Goods,因为我不是在Goods.py 文件下右键点击运行的。如果我直接在Goods.py文件下右键点击运行,就可以正常打印出 _ _ main _ _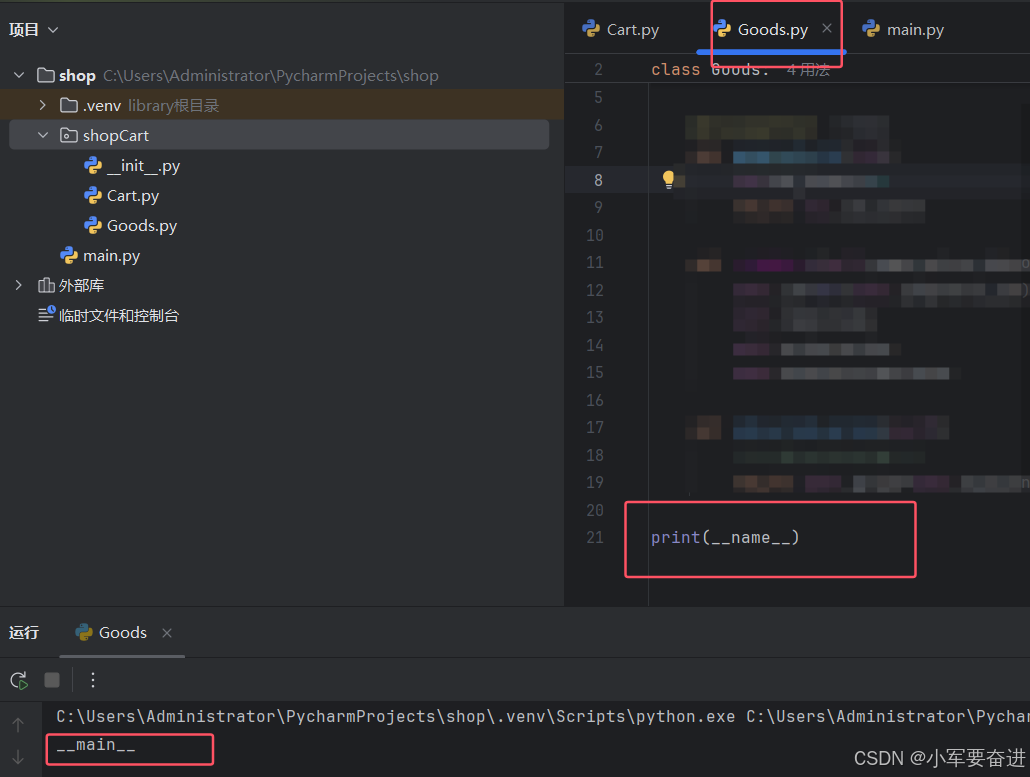
有什么应用呢?
比如平时自己定义了A类,想在A类下写测试性的代码,只有A类下运行才会被执行。而其他类导入A类后并在其他类右键点击运行时 这些A类的测试代码不想被执行。
所以,平时可以通过if条件,通过判断 _ _name _ _ 的值来决定其他类导入A类时是否执行A类的某些代码。如下图:
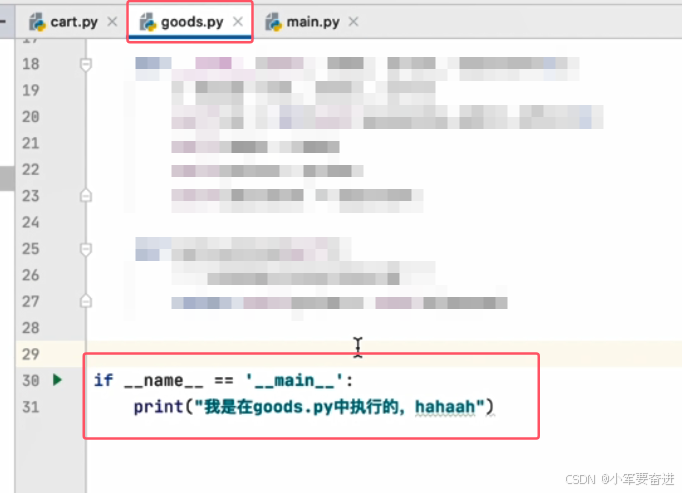
这样写后,在main.py这个入口文件中通过模块导入后,并右键运行时,上图中Goods类中if的条件不会被满足,所以if里面的代码就不会被执行。
二十八、日期时间模块
1、datetime对象
now=datetime.now()
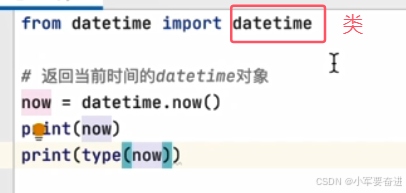
输出:

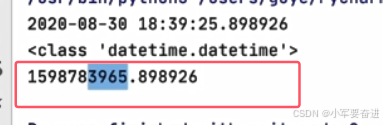
2、时间戳
now.timestamp()
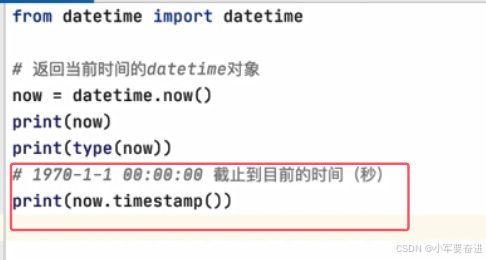
输出:
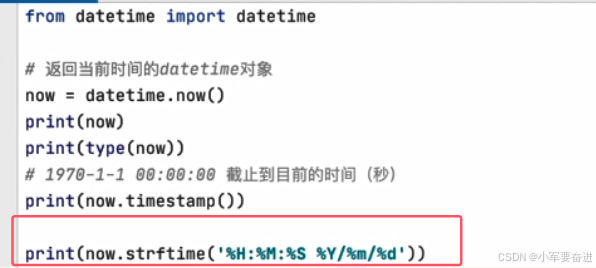
3、日期格式化
把日期格式化为字符串。
now.strftime()
输出:
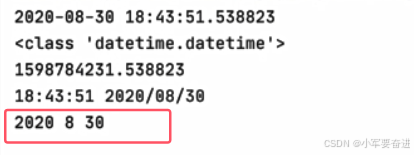
4、获取年月日
now.year
now.month
now.day
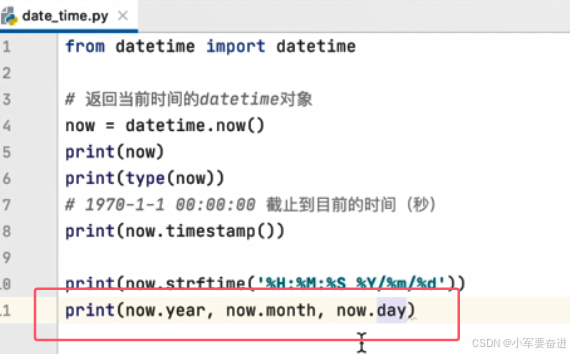
输出:
5、指定年份
now.replace(year=)

输出:

6、时间间隔计算
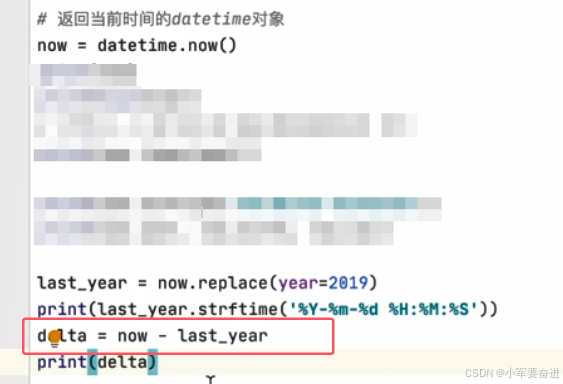
这个时间间隔是timedelta对象:

输出:

有了timedelta对象后,可以查看间隔的天数、秒数等等:

datetime对象还可以和timedelta对象相加,得到一个新的timedelta对象。如下图。这里是 当前时间 加上 时间间隔 。
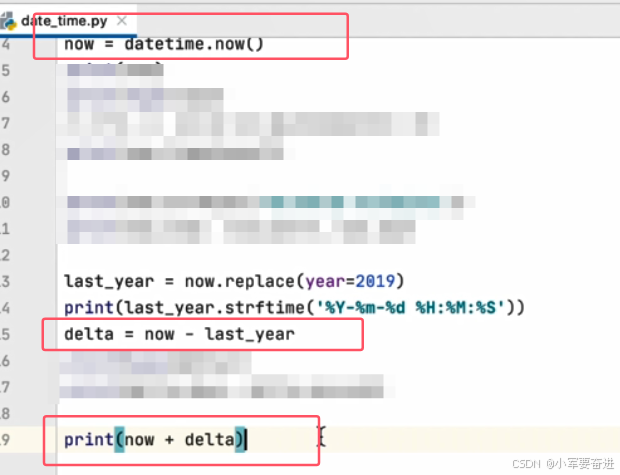
输出:

这个时间间隔还可以指定多少天。如下图,当前时间 加上 20天:
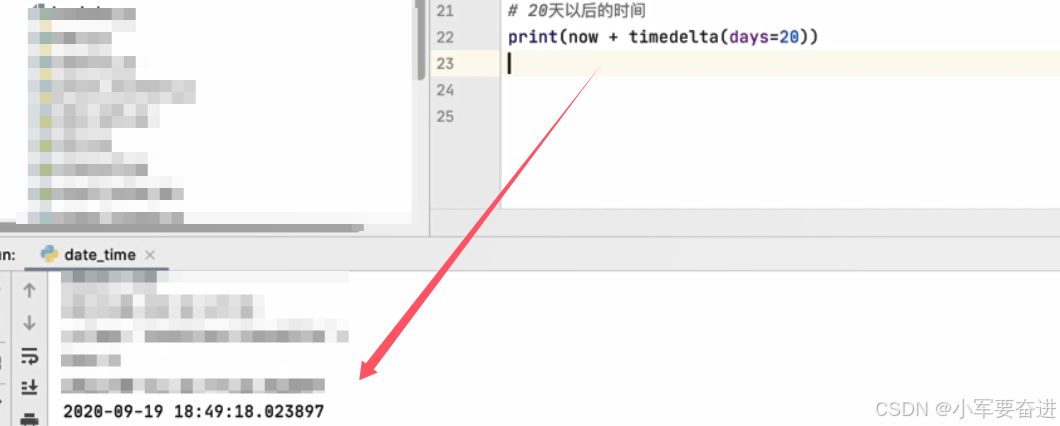
上图,用timedelta()创建了一个timedelta对象,注意需要先导入timedelta类:

这个时间间隔还可以指定多少小时多少分钟:
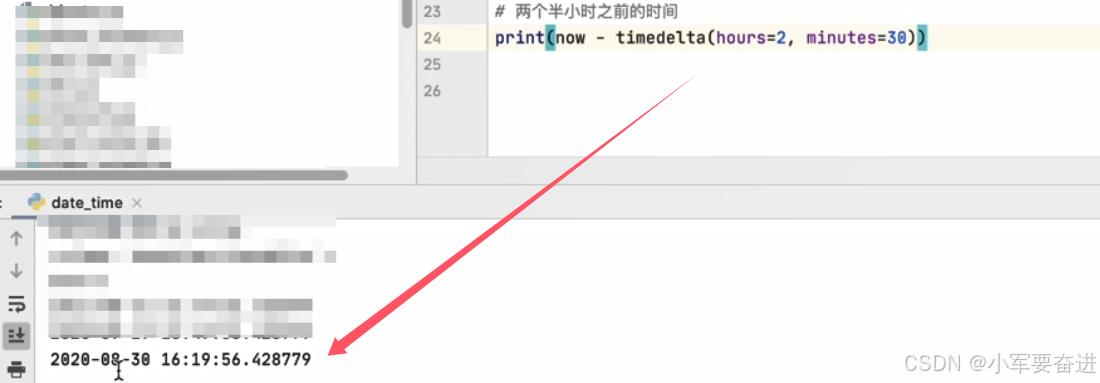
7、time模块
先倒入time模块:

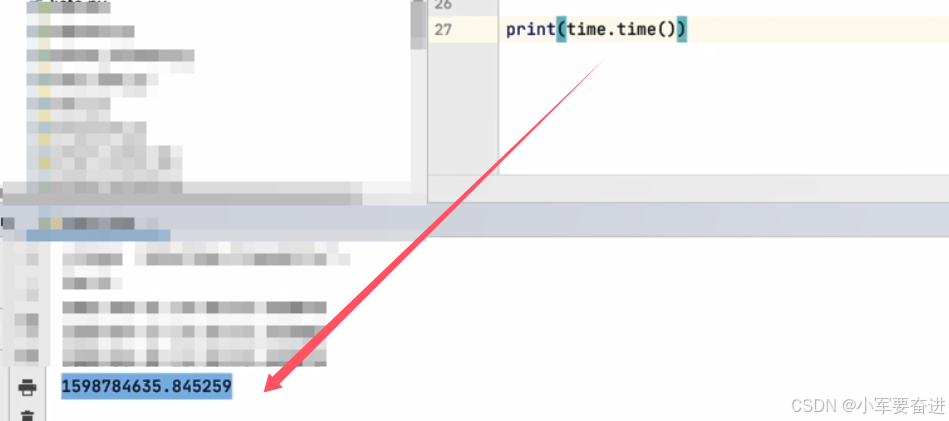
① 时间戳
同样可以返回当前的时间戳。time.time()
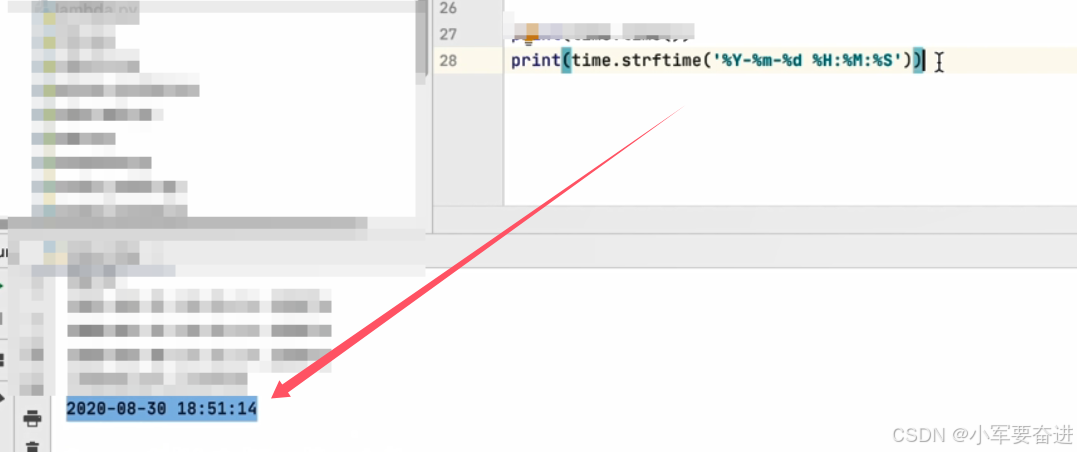
② 日期格式化
同样也可以格式化时间形成字符串。time.strftime()
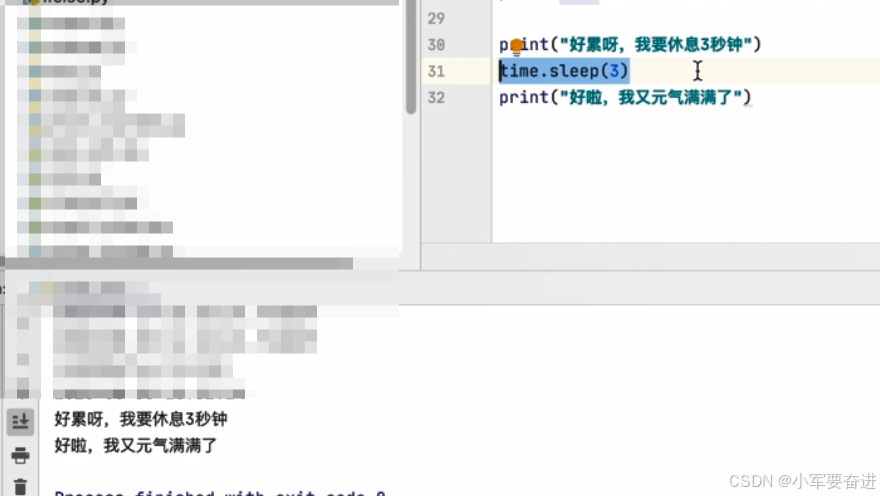
③ 暂停
暂停程序的运行。涉及到了线程的问题。
time.sleep(),括号内写需要暂停的秒数。
二十九、随机数
导入模块:

示例1:
生成0-1之间的浮点数(不包含1)。使用random()

示例2:
生成指定范围的整数。如想生成1-10之间的整数(包含1和100)。使用randint()

示例3:
生成含有26个字母的列表:
az=[ chr(i) for i in range( 65 , 65+26 ) ]

如果想从一个az列表中随机抽取出一个字母。使用 choice() ,注意这个列表不能是空的,否则会报错。

如果想一次随机抽取多个字母,可以用 choices(),使用k来指定抽取多少个。如下图:

注意抽出来形成的是一个列表。如果想转成字符串,可以使用 join(),如下图:

join前面的引号指定用什么拼接。
注意 random.choices() 从列表中抽取出来的有可能是重复的:

如果不想重复,可以使用 random.sample()。如下图:
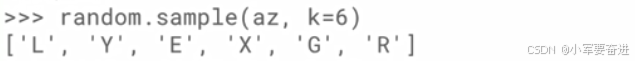
示例4:
如果想打乱列表中的元素。可以使用 random.shuffle(),括号里面放可变的迭代序列,所以不能是元组,通常是放列表。

三十、os模块
首先认识一下绝对路径和相对路径。

目录分隔符在不同的系统中是不一样的。如在Mac和Linux下用的是 / ,而在windows系统下是 \
查看自己系统的目录分隔符:
import os
print(os.sep)
1、os.getcwd()
获取当前项目的工作目录。

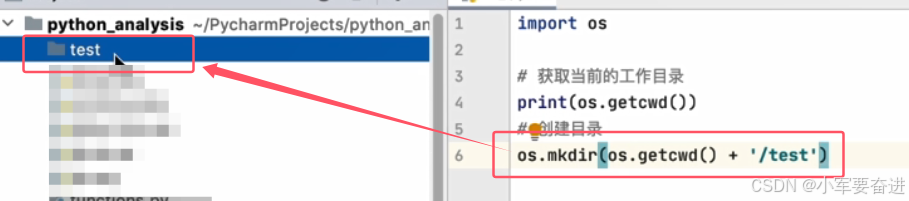
2、os.mkdir()
创建一层目录。
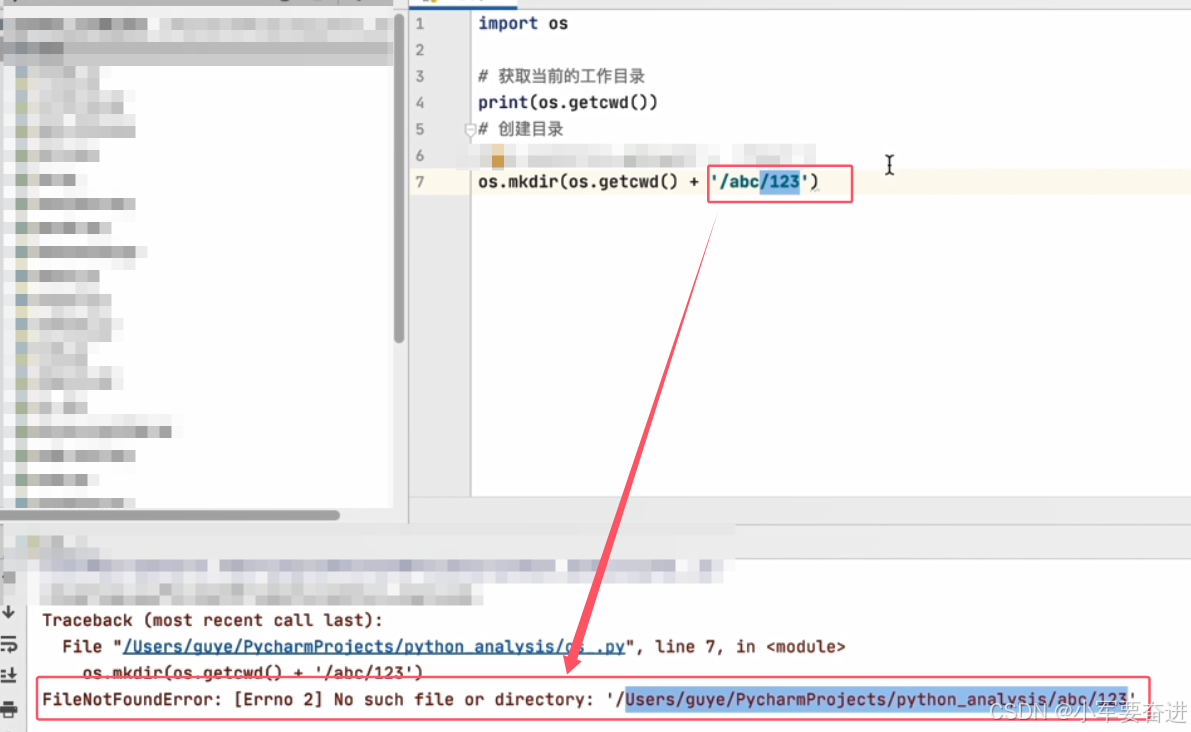
这个函数只能创建一层目录。所以,如下图,如果abc目录不存在的情况下创建123目录会报错。
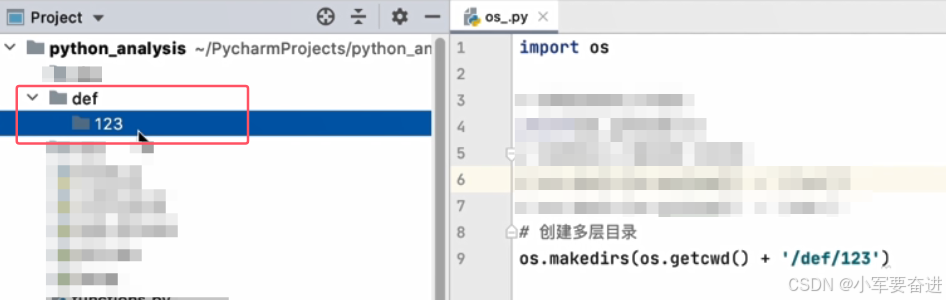
3、os.mkidrs()
可以创建多层目录。
4、os.listdir()
列出指定目录下的所有文件或者文件夹名称。
如下图,列出当前项目目录下的所有文件和文件夹的名称。
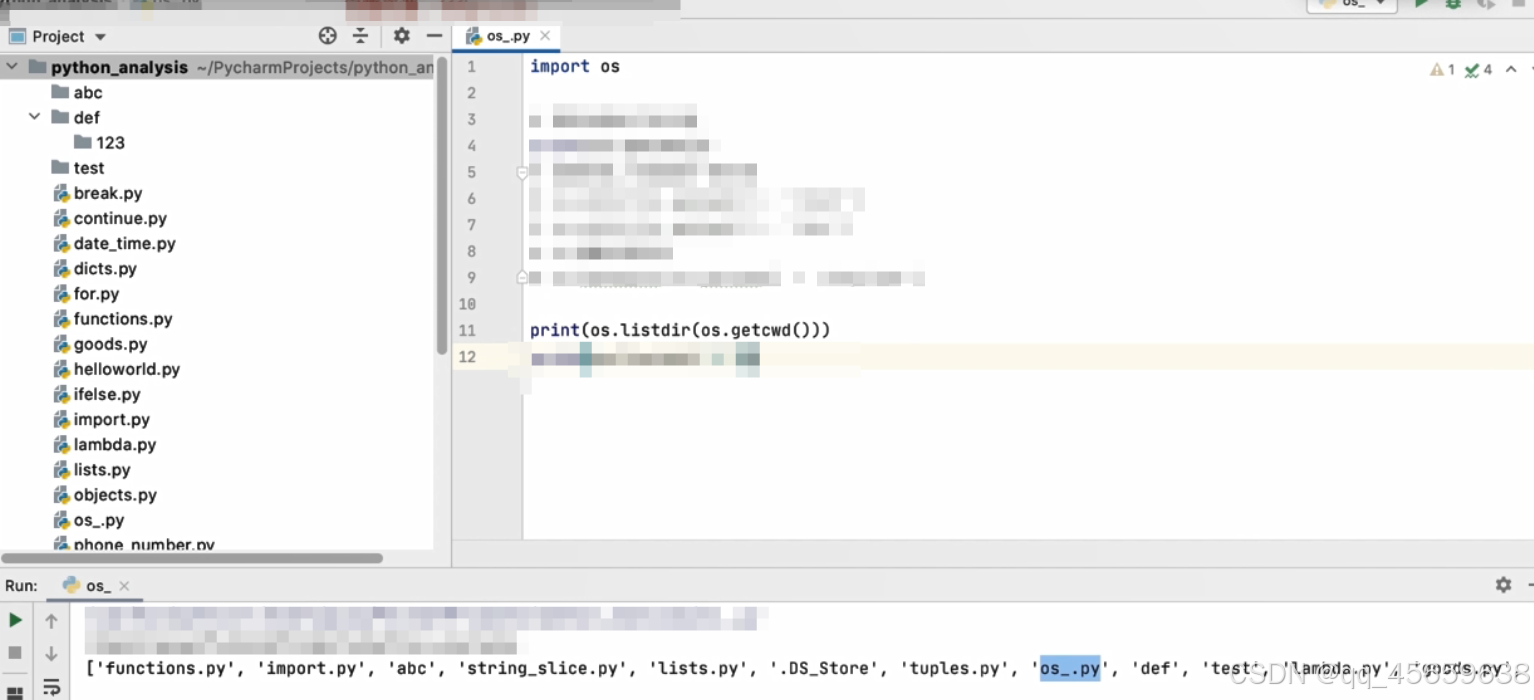
列出根目录下的所有文件和文件夹:

三十一、os.path模块
1、os.path.abspath()
获取绝对路径。
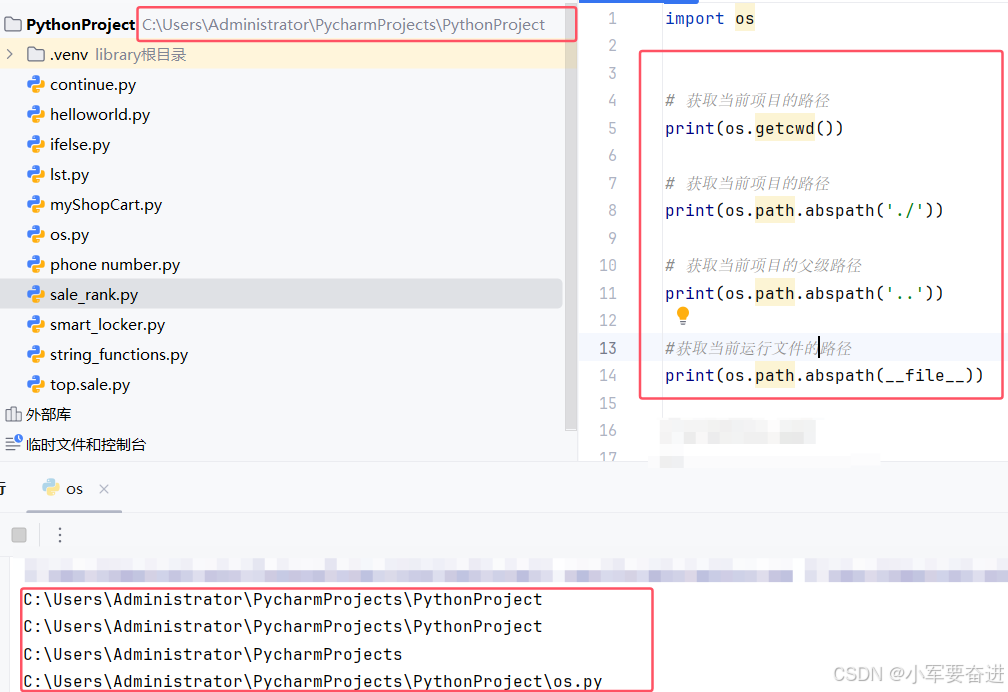
2、os.path.isfile()
判断一个文件是否存在。
括号内写文件的目录。
返回值是布尔值。
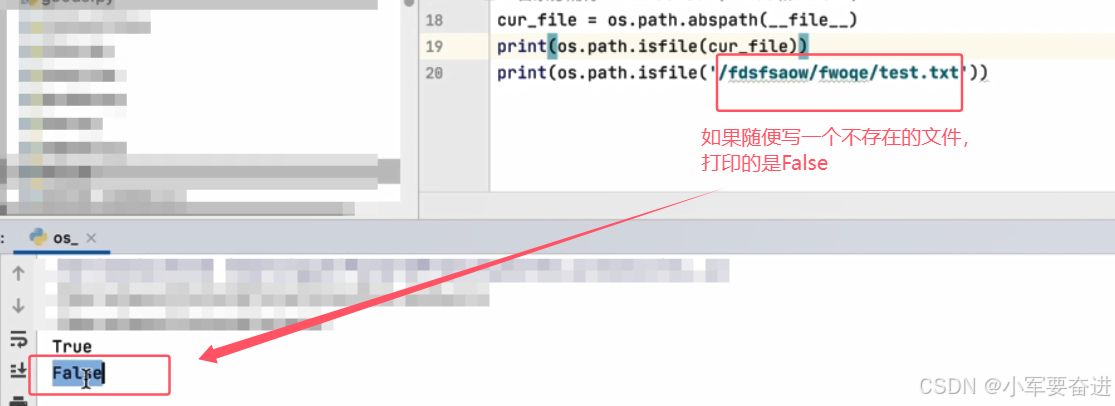
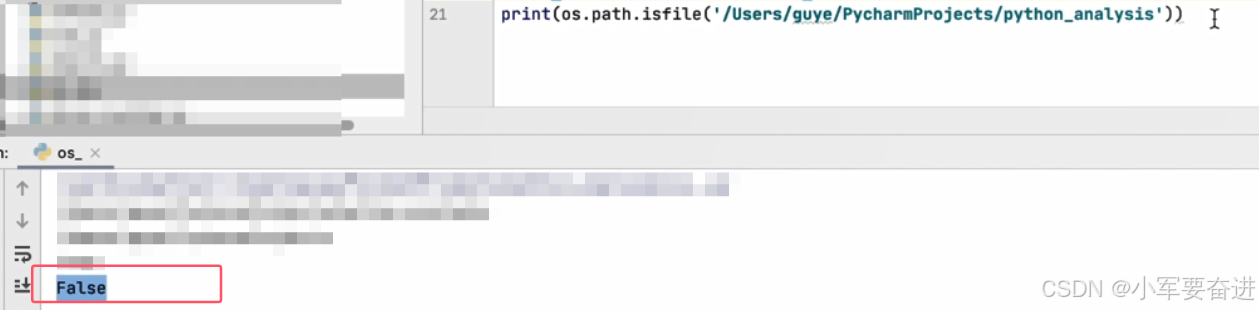
isfile()只能判断文件是否存在,不能判断目录是否存在(即使这个目录真的存在。)
3、os.path.join()
拼接多个字符串,或者说多个路径。
print(os.path.join(os.getcwd(),"a","1"))
4、os.path.dirname() 和 os.path.basename()
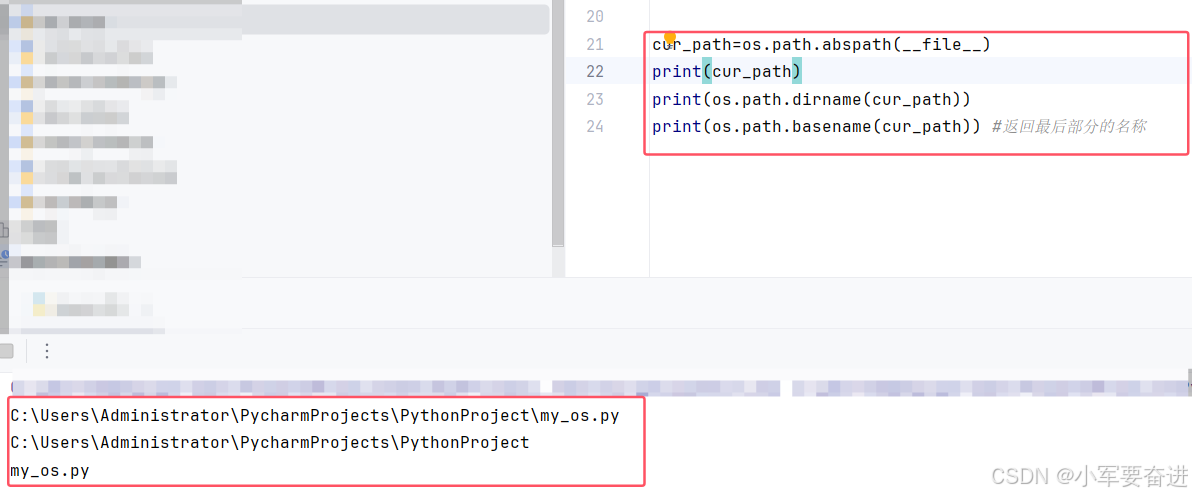
三十二、sys模块
sys.path
sys.argv
略