Linux 重定向与Cookie
一.重定向
1.重谈状态码
由状态码表我们知道,3开头的状态码代表着重定向。
临时重定向——不改变任何信息,常用来做登录跳转
永久重定向——网站更换域名,旧网站不删除,做一个永久重定向的操作,会改变用户的信息。
简单来说,重定向的功能就是:例如我们访问老网站s1,此时s1会返回给我们一个response报文,其中Location报头显示新的s2地址,并且没有正文。
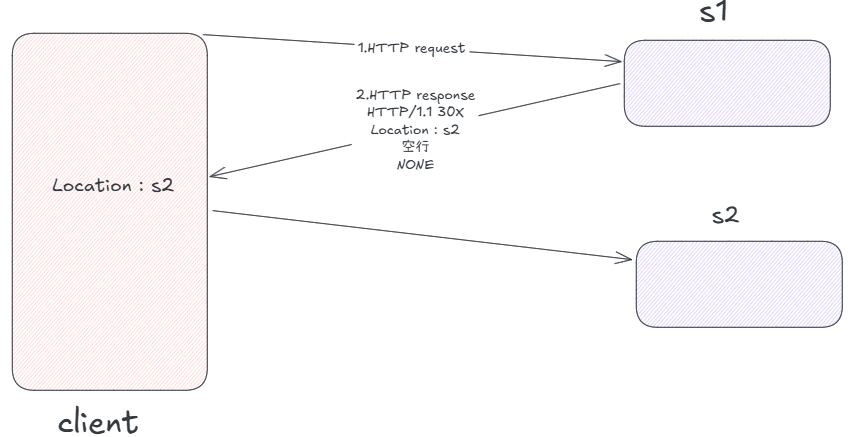
做一个简单的测试:比如当客户端访问该网址时,MakeResponse需要SetCode为30X,并且做重定向工作。
bool MakeResponse(){if (_targetfile == "./wwwroot/favicon.ico"){LOG(LogLevel::DEBUG) << "用户请求: " << _targetfile << "忽略它";return false;}if (_targetfile == "./wwwroot/redir_test"){SetCode(301);SetHeader("Location", "https://www.qq.com/");return true;}int filesize = 0;bool res = Util::ReadFileContent(_targetfile, &_text); if (!res){_text = "";LOG(LogLevel::WARNING) << "client want get : " << _targetfile << " but not found";SetCode(404);_targetfile = webroot + page_404;filesize = Util::FileSize(_targetfile);Util::ReadFileContent(_targetfile, &_text);std::string suffix = Uri2Suffix(_targetfile);SetHeader("Content-Type", suffix);SetHeader("Content-Length", std::to_string(filesize));// SetCode(302);// SetHeader("Location", "http://8.137.19.140:8080/404.html");// return true;}else{LOG(LogLevel::DEBUG) << "读取文件: " << _targetfile;SetCode(200);filesize = Util::FileSize(_targetfile);std::string suffix = Uri2Suffix(_targetfile);SetHeader("Conent-Type", suffix);SetHeader("Content-Length", std::to_string(filesize));SetHeader("Set-Cookie", "username=zhangsan;");// SetHeader("Set-Cookie", "passwd=123456;");}return true;}通过这个简单的例子,我们就可以调整对404错误的处理:重定向到我们的内部资源。
我们上面实现的,是短链接。在上网都用电脑的时代,最重要的软件就是浏览器,所有人想上网,都会打开浏览器。微软为了占据一部分市场,直接在windows系统中预装IE浏览器,在IE中内置自己的搜索引擎。对应的,谷歌直接开源了chrome浏览器。越来越多的浏览器以及浏览器技术,需要一个标准来统一。
2.HTTP的请求方法
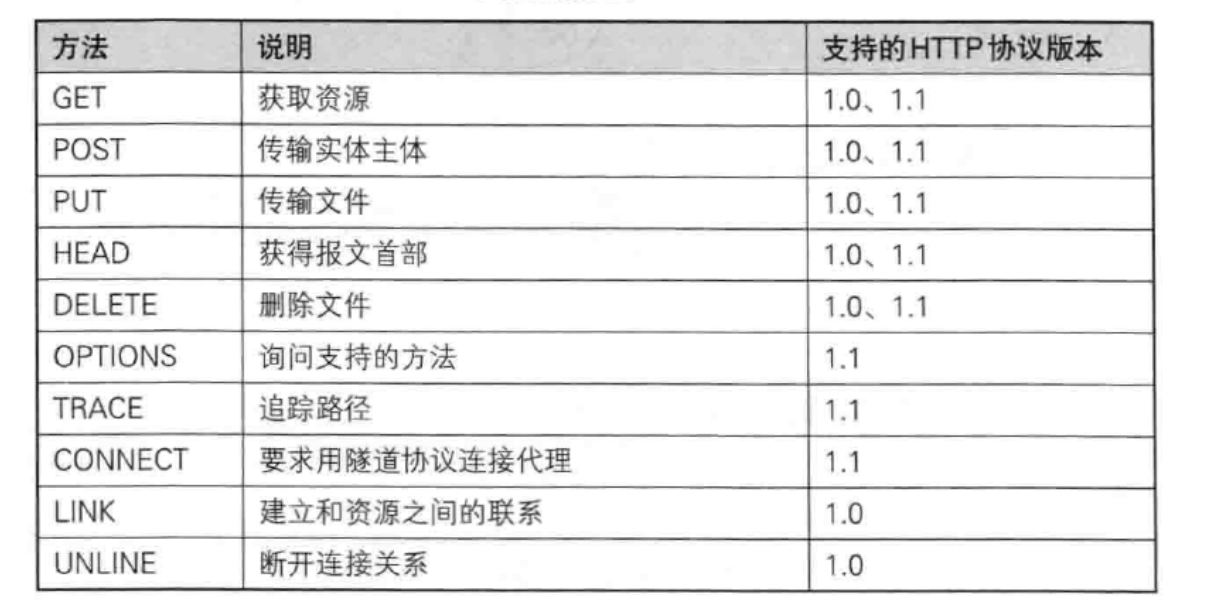
1.GET方法
获取资源(静态资源)
在request报文的请求方法中,包含这些字段。实际上也可以进行资源上传
2.POST方法
上传对应的数据。问题:怎么把数据上传?
最常见的就是上传登录数据——表单。这里用Login页面的表单为例:
<body><div class="login-container"><h2>Login</h2><form action="/login" method="GET"><div class="form-group"><label for="username">Username</label><input type="text" id="username" name="username" required></div><div class="form-group"><label for="password">Password</label><input type="password" id="password" name="password" required></div><div class="form-group"><input type="submit" value="Login"></div><a href="Register.html">Login</a> <!-- 跳转到登录页面 --><a href="index.html">Register</a> <!-- 跳转到注册页面 --></form></div>
</body>input标签和password标签会被解释成输入框,submit会被解释称提交按钮。
关键:action中显式/login,他表示将表单提交给后端的那个服务,而method为POST——数据提交
表单的信息会被拼接,比如用户名和密码。
101.34.228.219:8080/login?username=zs&password=123456
login及之前的字段代表目标地址和目标服务,问好之后的字段就代表form表单提交的信息。
对于GET方法:也可以进行数据提交,不过需要通过URI提交。
我们在Main.cc代码中添加服务Login
void Login(HttpRequest &req, HttpResponse &resp)
{// req.Args();LOG(LogLevel::DEBUG) << req.Args() << ", 我们成功进入到了处理数据的逻辑";std::string text = "hello: " + req.Args(); // username=zhangsan&passwd=123456// 登录认证resp.SetCode(200);resp.SetHeader("Content-Type","text/plain");resp.SetHeader("Content-Length", std::to_string(text.size()));resp.SetText(text);
}std::unique_ptr<Http> httpsvr = std::make_unique<Http>(port);httpsvr->RegisterService("/login", Login);此时request报文中的uri,会有请求的资源。我们需要在request中修改
是普通的请求资源,还是处理上传数据?我们只要从请求报文中根据"?"提取URI进行分析即可。如果报文中不含"?",说明只是简单的资源请求,而不是上传数据。
const std::string temp = "?";auto pos = _uri.find(temp);if (pos == std::string::npos){return true;}// _uri: ./wwwroot/login// username=zhangsan&password=123456_args = _uri.substr(pos + temp.size());_uri = _uri.substr(0, pos);_is_interact = true;注册处理函数
void RegisterService(const std::string name, http_func_t h){std::string key = webroot + name; // ./wwwroot/loginauto iter = _route.find(key);if (iter == _route.end()){_route.insert(std::make_pair(key, h));}}//而这个_route,是一个string,func类型的map,存储名字为string的函数处理方法std::unordered_map<std::string, http_func_t> _route;因此在处理request,我们来判断是否需要交互:如果需要交互,就根据登录请求调用响应方法(方法存在),如果不需要交互,就是普通的资源请求。
HttpRequest req;HttpResponse resp;req.Deserialize(httpreqstr);if (req.isInteract()){// _uri: ./wwwroot/loginif (_route.find(req.Uri()) == _route.end()){// SetCode(302)}else{_route[req.Uri()](req, resp);std::string response_str = resp.Serialize();sock->Send(response_str);}}else{resp.SetTargetFile(req.Uri());if (resp.MakeResponse()){std::string response_str = resp.Serialize();sock->Send(response_str);}}同样地,我们可以注册更多处理方法,来受理客户端发来的请求。
以上的操作,就类似用http为用户提供了微服务接口。
POST提交和GET提交有什么区别?
POST提交的报文,参数在正文中。
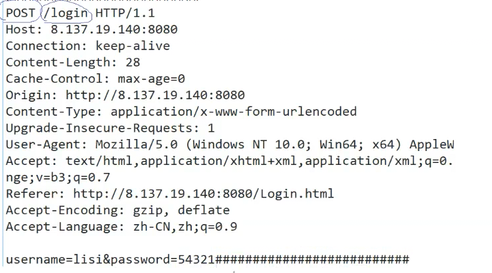
而不是GET的URI中。
注意:GET会在地址栏回显,也就意味着POST会更加私密(注意,并不代表着安全!)。POST提交的参数在正文中,相较于GET提交在URI中,更适合传入长参数。
为什么不安全?例如一个抓包工具fiddler:
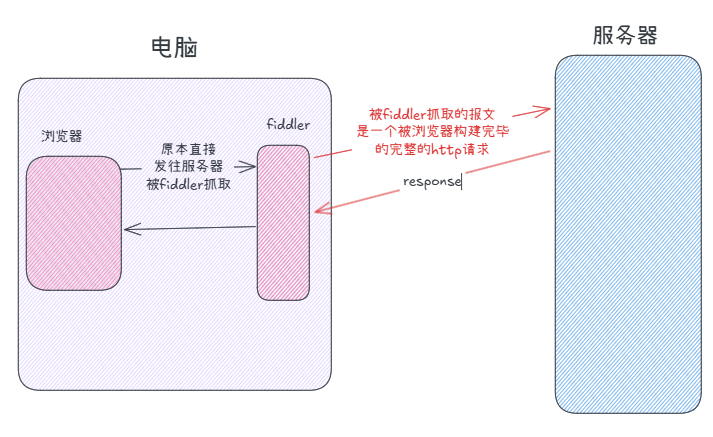
所以我们要对报文进行加密:https协议。
3.长连接connection
常见其他选项:put,delete不常用,head主要用于测试,不包含正文
option方法:可以用nginx测试,如果当前服务器支持,在响应报头中会有allow字段。
HTTP/1.1 200 OK
Allow: GET, HEAD, POST, OPTIONS Content-Type: text/plain Content-Length: 0 Server: nginx/1.18.0 (Ubuntu) Date: Sun, 16 Jun 2024 09:04:44 GMT Access-Control-Allow-Origin: *Access-Control-Allow-Methods: GET, POST, OPTIONS Access-Control-Allow-Headers: Content-Type, Authorization
connection报头:我们当前的服务器模式,只受理一个请求一个应答就关闭。这种特点是http 1.0的主要工作方式,因为在这个标准所处的时代,网络资源规模比较小。
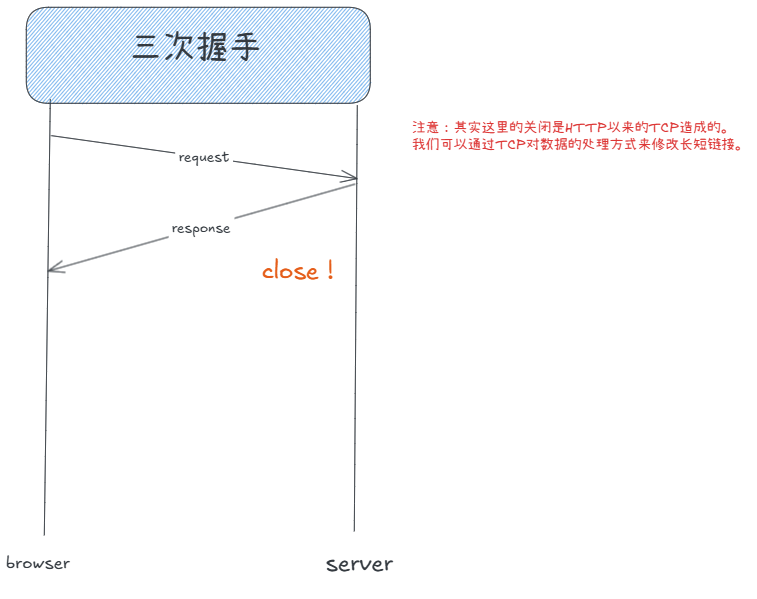
在现实中,当我们创立一个网页,其中有各种文本,尤其会有大量的音视频,每一种资源若都通过一个http请求和响应获取,是十分浪费服务器性能的。于是有了长连接——基于一个连接发起多个HTTP request请求,服务器就可以根据请求顺序构建对应的多个response应答。
response与request中的Connection报头:如果当前的主机支持长连接,Connection报头会显示keep-alive。
如果Connection均为keep-alive,就会默认采用长连接方式进行通信。
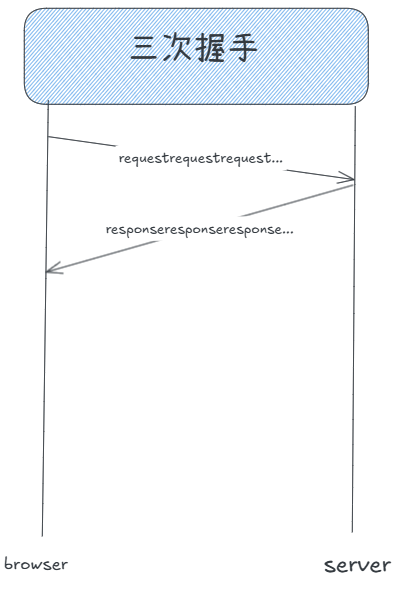
而我们在自己实现的TCP中,默认是只读一个请求的。
//执行一次callback就close
else if (id == 0){// 子进程 -> listensock_listensockptr->Close();if (fork() > 0)exit(OK);// 孙子进程在执行任务,已经是孤儿了callback(sock, client);sock->Close();exit(OK);}我们要连续读到多个完整的request。我们写的网络计算器,就是长连接的,当时是如何做到的?TCP的接收缓冲区中,while循环逐次解析每个完整的请求报文!
二.cookie与session
1.回顾HTTP
HTTP,即超文本传输协议,因为它请求访问的是web根目录下的资源,其中包括音视频等等,不再局限于文本;
HTTP是一个无连接无状态的协议。
问题:刚刚不是说,HTTP有长连接吗?
指的是让TCP保持长连接,而HTTP其实无关链接概念,只跟request和response强相关。链接的长短,都是TCP底层去进行维护的。
那么无状态,是什么意思?指的是对于服务器,它不关心你历史上是否请求过这一资源,只要你请求就会返回,服务器不会保存客户端的状态信息。
这种无状态,实际上会给用户造成困扰:每访问一次资源,都是一次新的http请求;如果要求我们以登录状态(客户端状态)访问服务器,登录之后返回给用户网页页面,用户挑选要访问的资源(例如一个电影),就需要再一次进行登录认证。HTTP为了解决这个问题,引入了cookie。
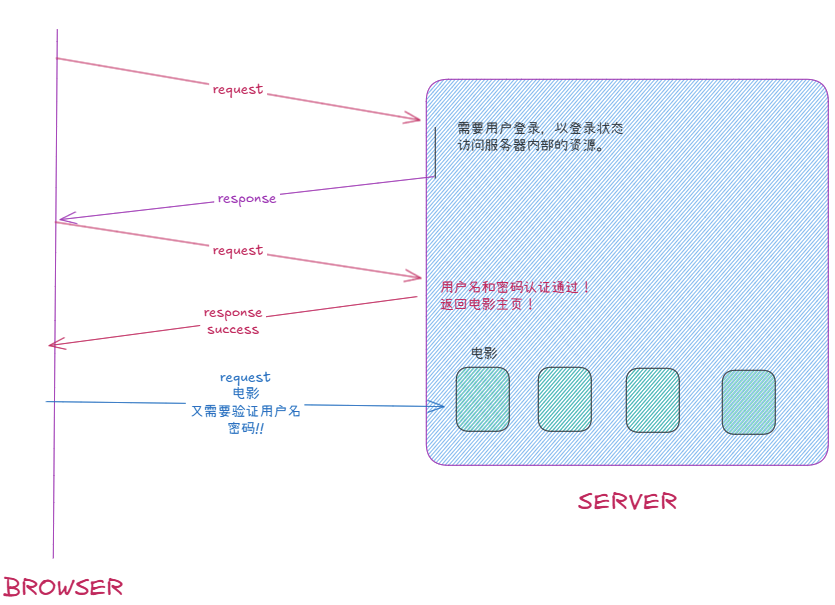
2.cookie与session
cookie的工作流程:其实麻烦的不是认证本身,而是这个工作需要人手动完成。而cookie就解决了这个问题。
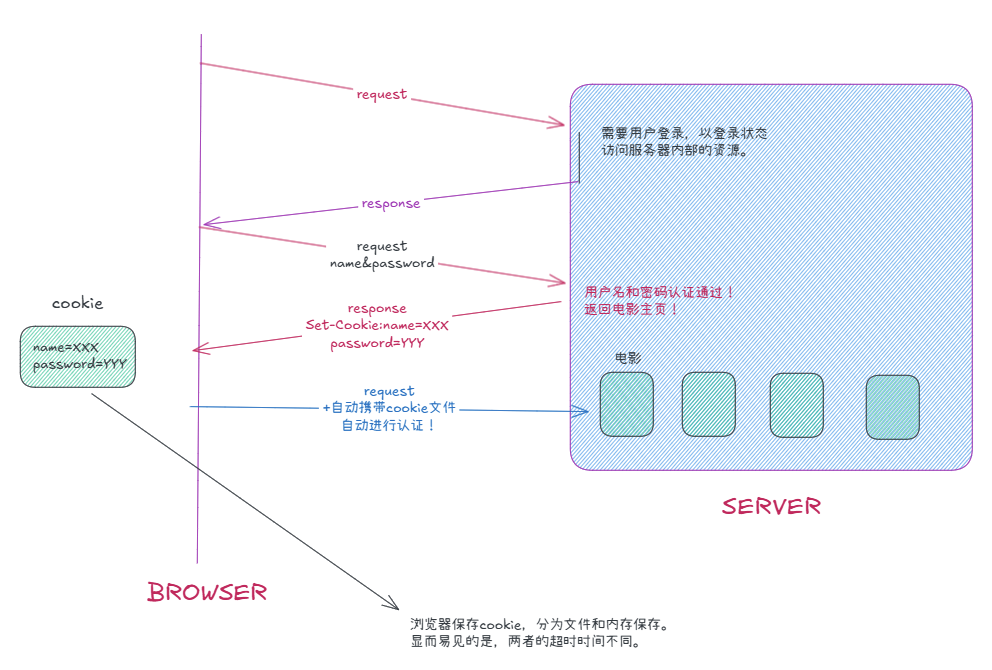
我们可以做一个简单的例子:bilibili的登录,就会使用cookie。
于是我们根据之前写的HTTP,为MakeResponse的同时构建cookie信息。
cookie有其特定的数据格式:
Set-Cookie: username=peter; expires=Thu, 18 Dec 2024 12:00:00 UTC; path=/; domain=.example.com; secure; HttpOnly
◦ Tue: 星期⼆(星期⼏的缩写)
◦ ,: 逗号分隔符
◦ 01: ⽇期(两位数表⽰)
◦ Jan: ⼀⽉(⽉份的缩写)
◦ 2030: 年份(四位数)
◦ 12:34:56: 时间(⼩时、分钟、秒)
◦ GMT: 格林威治标准时间(时区缩写)
我们先进行最简单的测试:(后续,我们可能需要用一个额外的容器存储cookie对象)
else{LOG(LogLevel::DEBUG) << "读取文件: " << _targetfile;SetCode(200);filesize = Util::FileSize(_targetfile);std::string suffix = Uri2Suffix(_targetfile);SetHeader("Conent-Type", suffix);SetHeader("Content-Length", std::to_string(filesize));SetHeader("Set-Cookie", "username=zhangsan;");// SetHeader("Set-Cookie", "passwd=123456;");}然后客户端再发起请求时,就应该携带这个Set-Cookie。
当前这个cookie的问题:
内存级cookie,会随着浏览器关闭而失效
当用户请求服务器资源时,有黑客拦截请求,获取其中的cookie字段,并且拷贝到自己浏览器的某个位置中,这样黑客也向浏览器发起请求,就获取了你本该获取的资源!
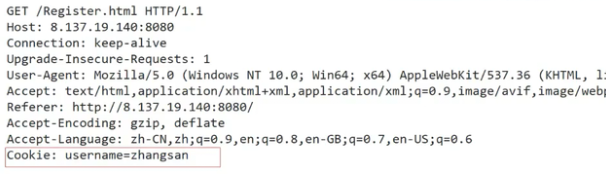
用户名的密码,用户名,浏览痕迹等等若都再cookie中,私密信息和账号密码就全部泄漏了。
为了 一定成都上解决安全问题,就引入了session。
每一个session都有标识其唯一性的sessionID,用户的私密信息就在其中。set-Cookie依然存在,只不过其中的字段变成了当前用户的sessionID。
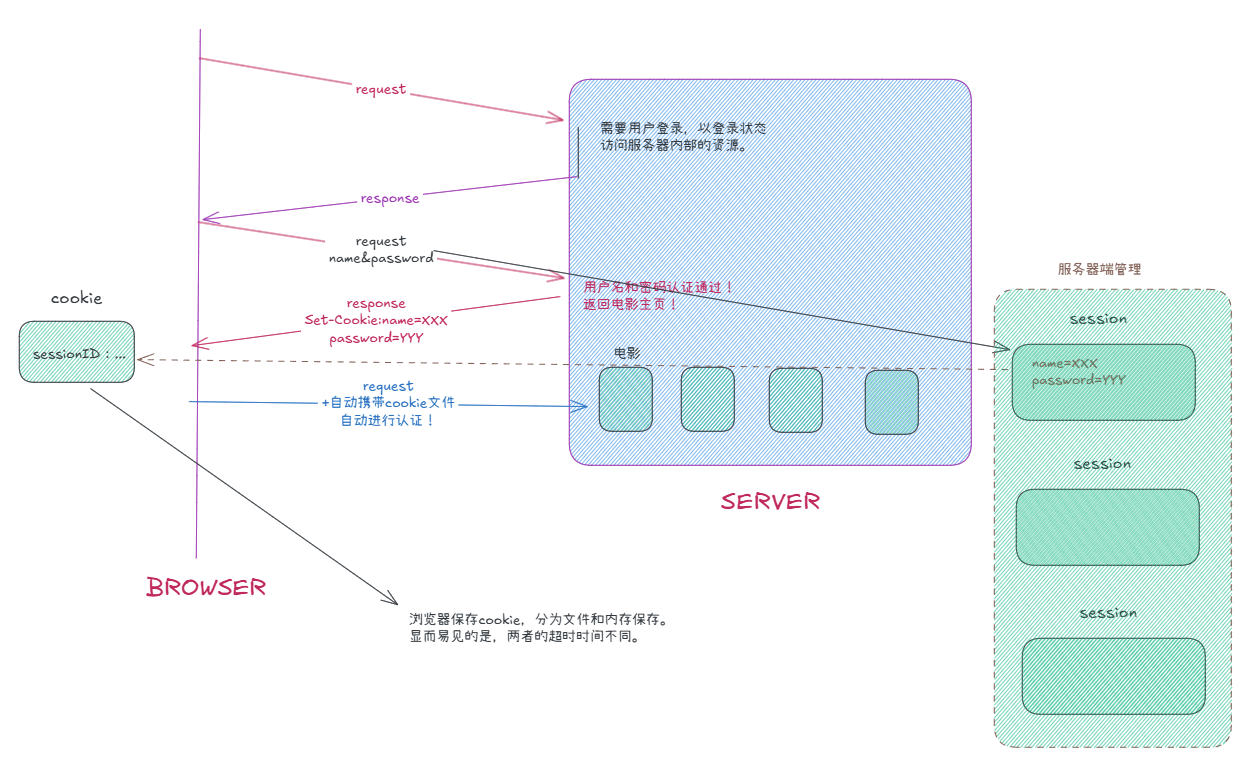
session实际上是一种类。问题是,session是如何真正做到安全性的?虽然黑客以用户身份进行访问,但是用户的私密信息已经再服务端保存了。一个方案是很难做到面面俱到的防护的,所以往往还会搭配其他的辅助手段,例如ip溯源,地址变更等等free掉session,强行让用户重新登录达到防护。
因此会话管理与会话保持的技术就通过:cookie+session实现。